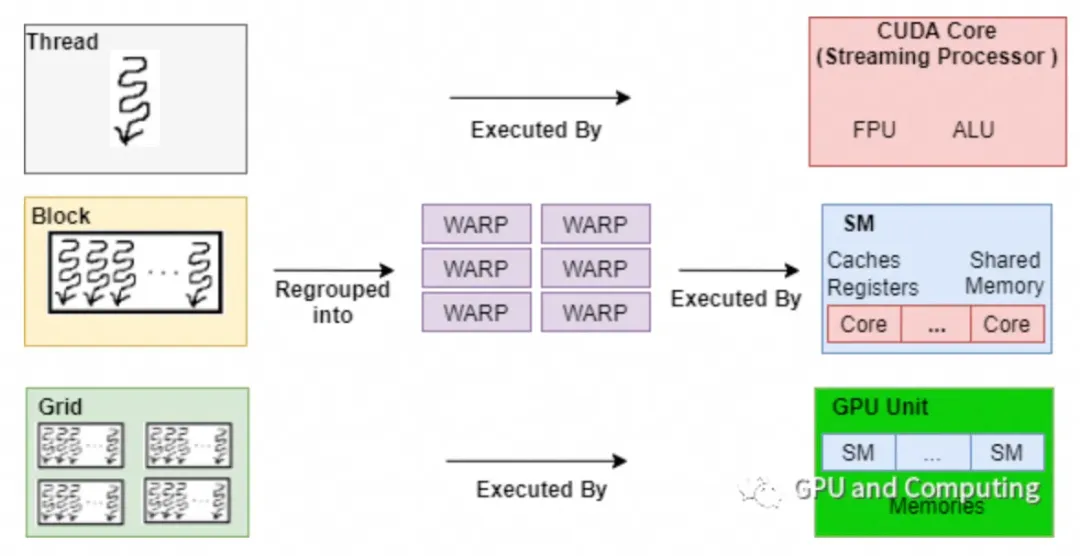
摘要
GPU(图形处理单元)因其并行计算能力而成为深度学习领域的重要组成部分。本文将介绍如何利用PyTorch来高效地利用GPU进行深度学习模型的训练,从而最大化训练速度。我们将讨论如何配置环境、选择合适的硬件、编写高效的代码以及利用高级特性来提高性能。
1. 引言
深度学习模型的训练过程通常需要大量的计算资源。GPU因其高度并行化的架构而成为加速这些计算的理想选择。PyTorch是一个强大的深度学习框架,它不仅易于使用,还提供了丰富的API来利用GPU进行高性能计算。
2. 硬件配置与选择
在开始之前,选择合适的硬件是至关重要的。以下是选择GPU的一些关键因素:
- CUDA Cores: 更多的CUDA核心意味着更强的计算能力。
- Memory Bandwidth: 高内存带宽可以减少数据传输的时间。
- Memory Size: 较大的显存可以容纳更大的模型和更多的数据。
3. 环境设置
确保安装了支持CUDA的PyTorch版本。此外,还需要安装CUDA驱动程序和工具包。
pip install torch torchvision
# 安装CUDA工具包(如果还没有安装)
# 这一步通常需要访问NVIDIA官方网站下载对应的驱动程序和CUDA工具包
4. 利用GPU进行训练
接下来,我们将展示如何在PyTorch中使用GPU来训练一个简单的卷积神经网络(CNN)。
代码示例
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import torchvision.transforms as transforms
import torchvision.datasets as datasets
# 创建简单的模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
# 检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 将模型移动到GPU
model = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 加载数据
transform = transforms.Compose([transforms.ToTensor()])
dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=100, shuffle=True)
# 训练模型
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(dataloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / (i + 1)}')
print('Finished Training')
5. 提升GPU性能的最佳实践
- 数据预加载:使用
DataLoader的num_workers参数来预加载数据。 - 混合精度训练:使用半精度浮点数(FP16)来减少内存占用和提高计算速度。
- 模型并行:将模型拆分成多个部分,部署在不同的GPU上。
- 梯度累积:通过多个小批次累积梯度来模拟大批次的效果。
混合精度训练示例
from torch.cuda.amp import GradScaler, autocast
scaler = GradScaler()
# 在训练循环中
for epoch in range(5):
running_loss = 0.0
for i, data in enumerate(dataloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
with autocast():
outputs = model(inputs)
loss = criterion(outputs, labels)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / (i + 1)}')
6. 结论
通过合理配置GPU和使用PyTorch提供的高级特性,我们可以显著提高深度学习模型的训练速度。随着硬件技术的发展,这些技术将继续演进,为开发者提供更多的可能性。