
本文作者:董国平 阿里云智能高级技术专家
公共云大数据平台在多租户的设计和实现方式上有所差异。本文主要介绍在公共云大数据平台的多租实现方案中需要考虑的问题和挑战,重点介绍了MaxCompute在计算和存储多租实现上的特点。期望通过这些介绍来让大家了解大数据云平台多租方案需要关注的技术点和MaxCompute在多租实现上的产品特色。
大数据平台多租户的常见形态
多租的概念大家可能有不同的理解,这里做个简单的分类,方便沟通。

第一种是租户独享一个数据库实例,支持基本的基于角色的访问控制,比如云上的传统数据库,通常就是这种模式。 在这种场景下从云平台的角度来看是支持多个租户的,但是每个租户购买的是独立的实例,在实例内部做角色划分,实例之间的数据是完全独立的。
第二种形态是控制平面多租,比如元数据和权限管控是多租的,但是计算资源是相对独立的。大数据的场景因为需要支持复杂的计算,通常会将计算资源单独拿出来管理。
第三种是更广泛意义上的多租,share everything。从管控、计算到存储使用的都是多租的资源,也可以称之为强多租。
随着多租程度的提升,从用户的角度来看,系统的可扩展性越好,可以很方便的进行资源的扩缩容,但是云平台自身的系统复杂度更高。我们知道系统复杂度越高,往往会带来更多的稳定性问题;由于不同用户的作业运行在一起,安全性上的要求也越高,特别是在公共云的场景。
今天的分享更多关注的是计算和存储的多租实现。关于管控方面,基于RBAC或者基于权限表的权限管理、行级列级权限也是大数据平台多租实现的一部分,但不是今天分享的重点。回到计算和存储的多租上,实现上会有不同的组合方式。
单租计算和开放存储
一种典型的形态是单租计算加开放存储的模式,比如AWS EMR和Databricks等。
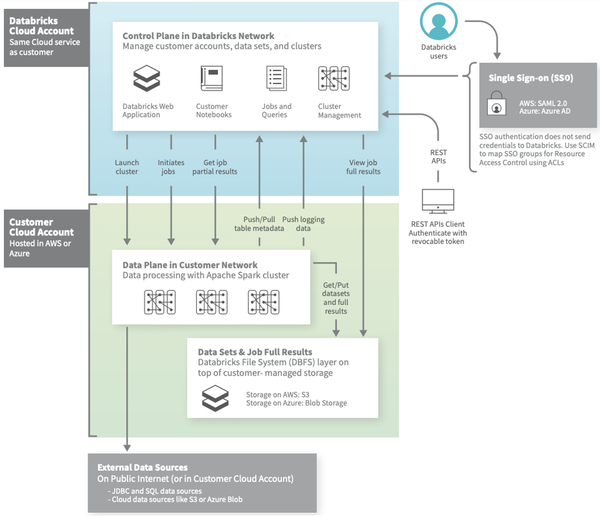
以上是Databricks的架构图,我们可以看到,管控平面是多租的,而不同用户的计算资源是单租的,存储则用的类似S3这样的开放存储。管控使用的是databricks的账号,而计算资源归属于用户自己的vpc。这种模式的优势在于,由于计算资源是单租的,所以可以支持复杂的UDF,而不用太考虑安全的问题。同时因为存储是开放的,可以很方便的将计算弹到其他云上,支持多云。面临的挑战在于资源的粒度是租户级别的,需要提前购买,弹性扩缩容完全依赖云平台的弹性。多租云存储的读写存在效率问题,计算与存储的物理位置相对较远,可能还要经过网关,有带宽的转发瓶颈,需要进行数据预取和缓存等;同时计算过程产生的中间数据因为性能的考虑,不能完全依赖云存储,需要考虑其他方式,比如内存或本地存储的方式。
多租计算和内部存储
像BigQuery和MaxCompute的实现比较类似,采用的是多租计算加内部存储的模式。
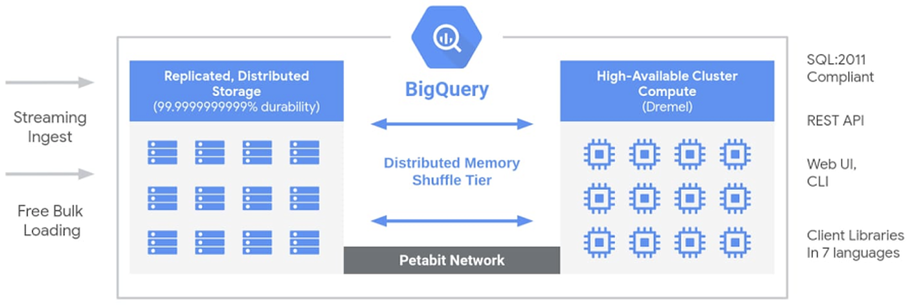
计算和存储的资源都是多租的,计算和存储可以位于同一个机房内,物理位置比较接近。优势在于极致弹性,用户可以在不持有物理资源的情况下,运行大规模的任务,并且可以按照用户作业实际使用的资源收费。而内部存储的实现,计算和存储之间可以有大容量的带宽,可以充分利用底层存储特性来做优化。而这种模式的挑战在于UDF的支持。UDF是大数据场景经常会提供的一个功能,利用自定义函数的形式来支持复杂的计算。我们需要避免一个恶意用户的代码威胁到平台或者其他租户的安全。这方面BigQuery和MaxCompute有不同的实现,BigQuery在UDF的实现上相对比较克制,提供了js的UDF,但是对能力做了一些裁剪,而MaxCompute则借助安全容器来支持了完整的UDF能力,这块在后面有介绍。不过在云平台上来实现安全容器会有二次虚拟化的限制,所以我们需要裸金属或者物理机这样的资源形态。
多租的优势和挑战
多租的优势在于开箱即用,无需创建独立的资源池。可以实现秒级扩容,极致弹性。单租资源池依赖云主机的话,从资源的购买到软件环境的准备,可能要到分钟级别,而在多租的平台上可能只是一个配置的参数变更。计费上多租可以做到按照实际计算的开销付费,而单租资源池的收费是按照资源池的规格来收费,不去管到底有没有使用。当然云平台可以根据资源使用的水位来进行动态的扩缩容,不过在资源售卖的粒度上还是有本质的差异。在成本方面,多租资源池通过不同租户作业之间的削峰填谷,可以带来更高的资源利用率,而云平台将这部分让利给用户,可以带来成本上的优势。
当然这里面也会带来了一些技术挑战,首先存储方面,云存储需要解决远程读写和中间文件存储的问题;而内部存储可以实现定制优化,但是存储的开放性是一个问题。在资源调度层面我们需要保证不同租户、不同类型的作业在平台上能够得到公平合理的调度,支持超大规模的计算节点;运行时上,针对UDF或者三方引擎的场景,需要实现运行时的隔离,保证租户之间不会出现数据的越权访问,或者单租户的恶意代码影响到平台和其他租户的安全;同时对于用户定制化的网络需求,也需要在租户层面实现打通,不能够做集群层面的打通。
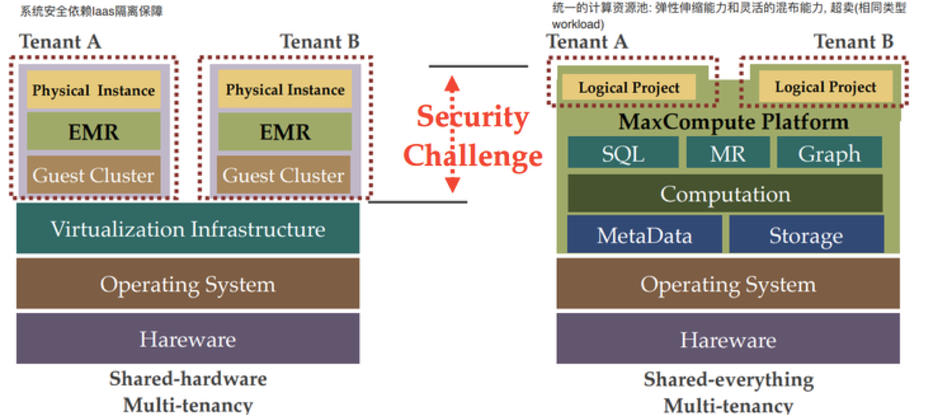
通过一张图来直观的看下单租和多租的差异,单租的资源池通过IAAS层的隔离来保障了多租户之间的安全,而多租则需要大数据平台自己来解决内部的安全问题。在这些挑战中,关于资源调度层主要关注的是大规模场景下的性能和可扩展性,而来自安全的挑战则是方案是否可行的关键。如果无法保障多租的安全,对云服务来说是不可接受的。
MaxCompute多租实现
MaxCompute是阿里云提供的用于大数据分析场景的、企业级的云数仓,提供的是全托管serverless的服务。而我们多租的实现是一个强多租的实现。我们支持了SQL、java 和python的UDF能力,支持基于机器学习平台PAI的算法组件实现对MaxCompute数据进行模型训练等操作,同时也支持开源spark的任务类型,而这些都是在统一的计算和存储资源上提供的。
内部存储
存储方面我们使用了飞天自研的存储引擎pangu,实现了基于capability的权限模型。在不直接对外开放访问的情况下,权限模型是可以简化的。由于是内部存储,我们可以实现分布式访问,避免中心化节点带来的性能瓶颈。同时对于作业运行过程中的临时数据,我们可以利用内部存储实现更好的local化和管理。
资源管控
一个多租的资源池离不开一个好的资源调度引擎。在资源管控的调度层面,我们实现一套高效可扩展的资源调度系统,在调度和资源管理的层面都提供了横向扩展的能力,可以支持大规模的计算节点;同时保证不同租户不同类型的任务在平台上能够得到相对公平的调度,做了完善的failover的处理。资源的形态上我们提供了预付费和后付费的资源形态,预付费资源能够得到更多的资源保障,后付费的用户则按照资源的需求规格和时间的先后顺序进行调度。
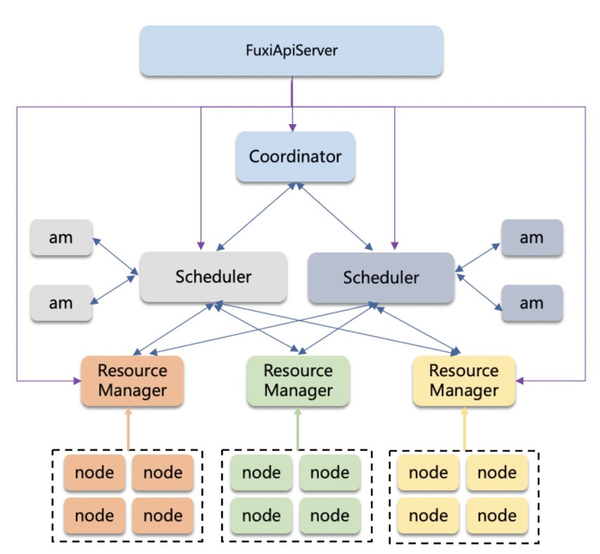
在资源管控的主机层面,我们通过cgroup的机制实现了作业级别的资源管控,来保证一个作业的异常不会影响到其他作业。支持作业的不同启动方式,进程方式或者容器方式,也可以同时管理cpu或者gpu的资源形态。
运行时隔离
基于灵活性和扩展性的考虑,MaxCompute在SQL语言里面支持了用户自定义函数即UDF的能力,方便用户对计算行为进行扩展,同时也引入了三方引擎,比如spark的支持。这些对平台来说是不可信代码,可能触发非预期的系统破坏,或者就是有恶意用户进行攻击。我们通过轻量级的安全容器(虚拟化容器),实现了进程级别的隔离。也就是说将不可信代码运行在安全容器内部。

考虑到MaxCompute的集群规模和大数据计算任务时间短的特点,对安全容器的稳定性和性能会有比较高的要求,我们也做了针对性的优化。首先在安全性上,我们对vm内核进行了裁剪,去掉了不必要的内核功能,减少攻击面,并提供必要的防护机。在网络上禁止了默认的外部网络访问。虽然我们是一个离线数据计算平台,用户对时延没有那么敏感,但是对整个链路上的优化也是我们一直努力的方向,所以对安全容器的启动速度做了很多优化。虚拟化的实现会有额外的资源占用,技术上需要降低vm的资源使用量,提高单机的计算密度,进而能够运行更多的任务。而计算数据的读写,则需要在安全容器内外建立高效的数据通道。
网络通信
我们有了隔离的安全容器之后,针对类似spark的任务,节点之间需要互相通信,比如spark的driver和worker之间需要进行任务的分发和状态的监控之类。基于安全的考虑,这些通信无法构建在主机网络之上,所以我们基于安全容器构造了vxlan的虚拟网络。让同一个任务的所有节点运行在同一个虚拟网络中,虚拟网络中的节点通过私网IP进行通信,无法访问主机网络。而对于用户定制化的外部网络需求,比如访问公网上的一个接口或者vpc内部的其他数据服务,我们也做了任务级别的打通。用户在作业启动时声明需要访问的网络目标,在必要的权限检查后,在作业维度上实现网络的打通。

同样因为任务频繁启停和规模的问题,虚拟网络的构建和通信也会面临比较大的压力。我们知道云上vpc的创建通常也是基于vxlan的技术,但是vpc的创建是相对固定的,一个用户通常只有一个vpc,购买主机则是往vpc中添加节点,操作相对低频。而我们需要面对一个任务创建一个vpc,并且在短时间内拉起任务内的成百上千个节点,对性能上会有比较大的挑战。
通过以上的技术,我们在单一的资源池上实现了强多租,让更多的业务形态成为可能。基于以上安全容器和虚拟网络的隔离,我们在一个多租的集群上提供了强大的UDF的实现。相对于其他平台提供的UDF,我们在UDF的能力上限制更少,允许访问本地IO和网络的功能,能够访问用户vpc内部的数据。比如湖仓一体的场景中,我们可以通过创建networklink的方式打通对用户vpc的网络访问,在创建外部数据源的时候关联networklink后,就可以在MaxCompute内部通过SQL访问外部数据,目前这些在MaxCompute的平台上都已经做了产品化的实现。而任务级别的隔离,使得我们可以在单个集群内提供混合的计算形态,除了SQL和UDF的实现外,我们还支持了内部的PAI机器学习平台和开源的spark引擎等。
多租的思考和演进
多租的设计上,面向不同的业务场景、产品形态和基础设施时,会有不同的实现。回到设计的初衷,我们为什么要在统一的计算存储的资源上实现强多租?MaxCompute是一个内部孵化的产品,目前集团内部99%以上的离线数据都运行在Maxcompute的平台上。在业务形态上,我们期望兼容hive的udf生态和支持开源生态,而源于集团内部对于数据安全的要求,所以一早我们就是多租安全的实现。在面向公有云服务时,我们又期望在资源粒度、弹性和成本上为客户提供优势,促使我们最终坚持了强多租的形态。
而在未来的演进方向上,前面也说到我们使用的内部存储,我们期望在存储层面面对计算的场景进一步提升我们的开放性。多租的场景下,某个大客户临时突发的大规模资源消耗对平台来说相对是不友好的,可能会导致其他用户的作业产生排队,所以在面对这样的客户时提供单租的计算形态也是一个选择。而开放存储和单租计算将为后续多云形态提供支撑,方便用户有更多的选择,用不同的组合去满足用户个性化的需求。

