💡 作者: 韩信子@ ShowMeAI
📘 机器学习实战系列: https://www.showmeai.tech/tutorials/41
📘 深度学习实战系列: https://www.showmeai.tech/tutorials/42
📘 本文地址: https://www.showmeai.tech/article-detail/396
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏 ShowMeAI查看更多精彩内容

📘BentoML 是一个用于机器学习模型服务的开源框架,设计初衷是让数据科学和 DevOps(software development and IT operations)之间的衔接更顺畅。数据科学家更多的时候聚焦在模型的效果优化上,而对于模型部署和管理等开发工作涉及不多。借助 BentoMl 可以轻松打包使用任何 ML 框架训练的模型,并重现该模型以用于生产。

BentoML有以下优点:
- 将 ML 模型转换为生产就绪的 API 非常简单
- 高性能模型服务,并且全部使用 Python
- 标准化模型打包和 ML 服务定义以简化部署
- 支持所有主流的机器学习训练框架
- 通过 Yatai 在 Kubernetes 上大规模部署和运行 ML 服务
在本篇内容中,ShowMeAI就带大家来详细了解一下 BentoML 和模型部署相关的知识和实践方法。
💡 训练模型之后的工作
算法工程师完成针对业务场景的建模与调优之后,我们就需要进行后续上线部署工作。
- 如果团队中的开发人员(例如后端或前端开发人员)想要使用它,他们需要需要封装好的服务接口 API 模式。
- 如果 DevOps 团队想要管理模型的部署,则需要处理模型环境和各种依赖项。
- 如果产品团队想要对模型进行压力测试或向客户展示它,那么 API 必须扩展到能支撑并发请求。
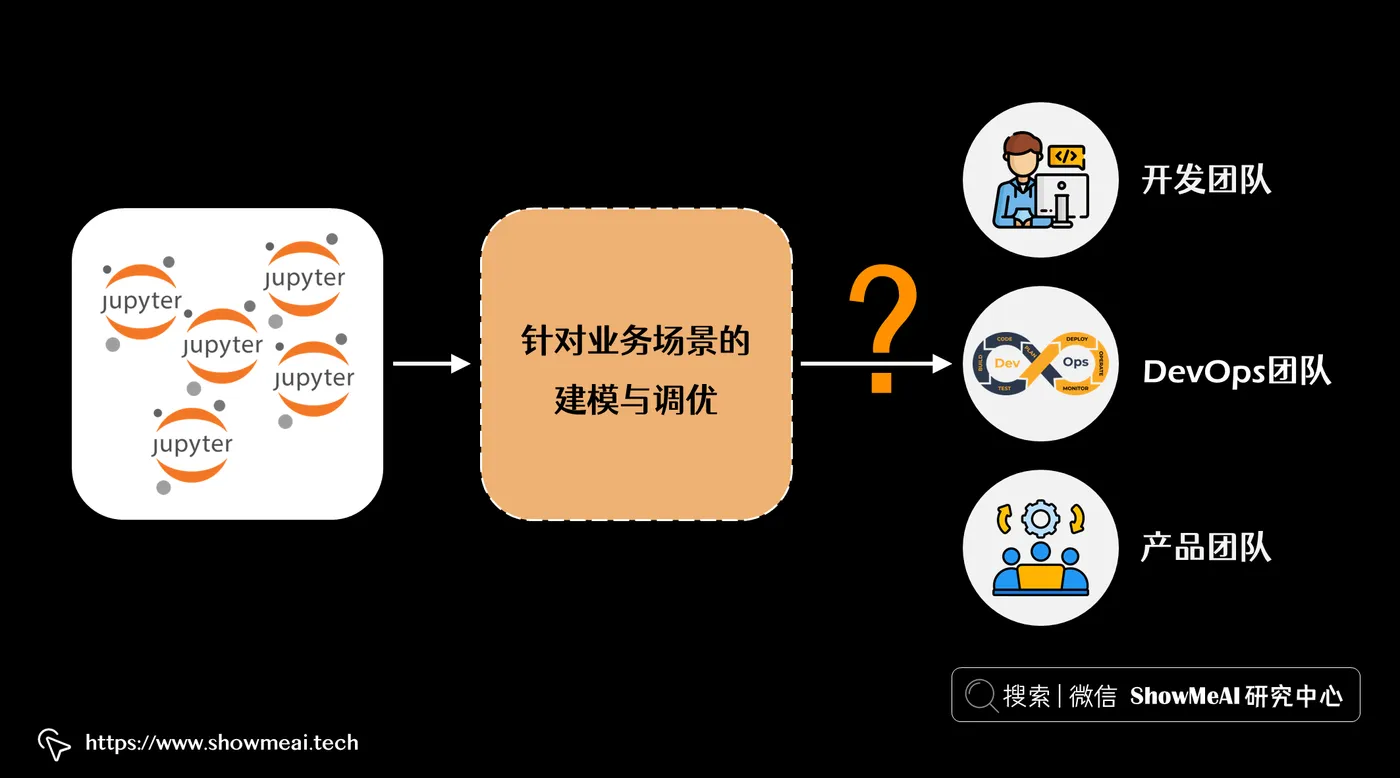
从构建 ML 模型到实际生产环境使用,有很多工作和注意点:
- 多个 ML 框架的使用和支持
- 创建 API 并以最低性能水平提供服务
- 再现性和依赖性管理
- API 文档
- 监控、日志记录、指标等
下面ShowMeAI带大家来看看 BentoML 是如何支持所有这些需求的。
💡 BentoML 简介&核心思想
BentoML 是用于模型服务和部署的端到端解决方案。BentoML 将 ML 项目中需要的一切打包成一种称为 bento(便当)的分发格式(便当最初是一种日本午餐盒,里面装着一份由主菜和一些配菜组成的单份餐点)。

更准确地说,bento 是一个文件存档,其中包含模型训练的所有源代码、定义的API 、保存的二进制模型、数据文件、Dockerfile、依赖项和其他配置 。我们可以将这里的“便当”视为用于 ML 的 Docker 映像。
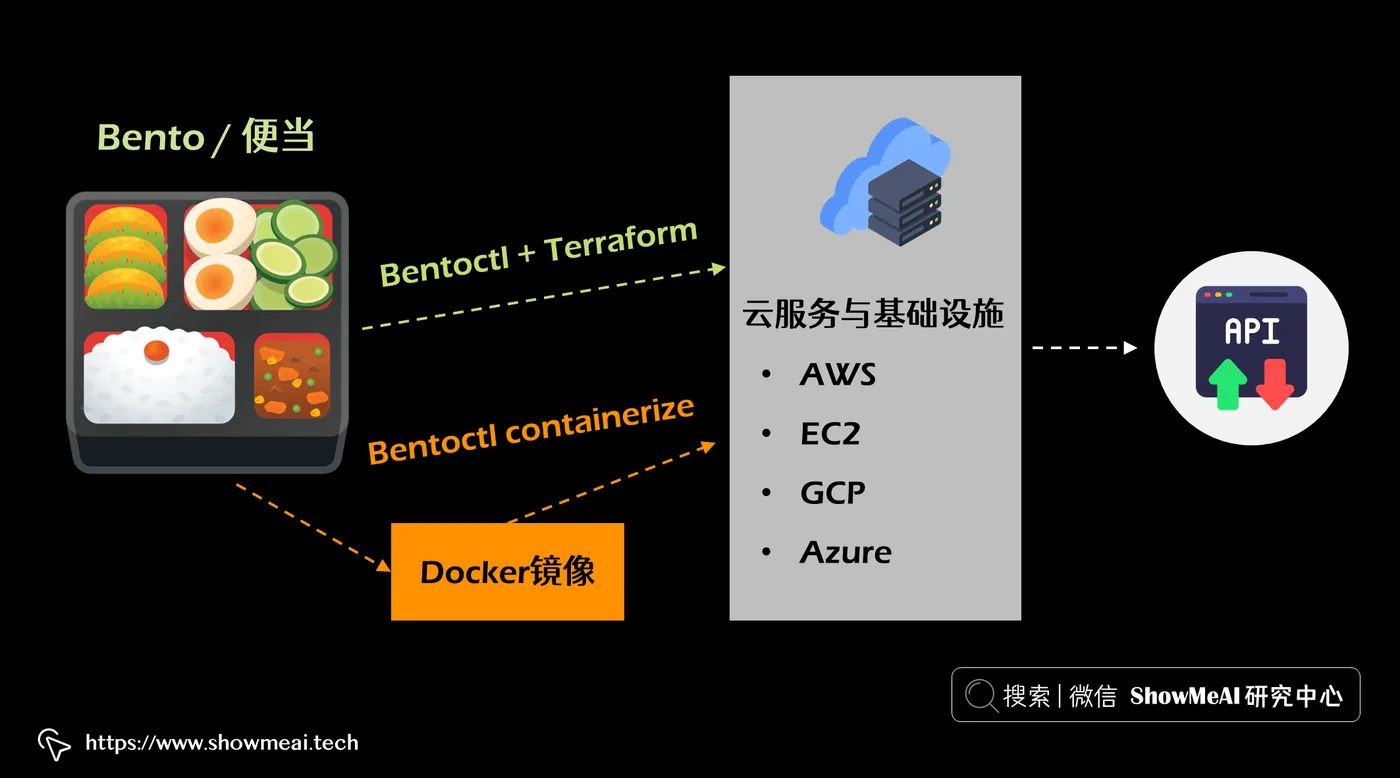
当 bento 构建完成后(下文会详细说明),你可以将它变成一个可以部署在云上的 Docker 镜像,或者使用 bentoctl(它依赖 Terraform) 将 bento 部署到任何云服务和基础设施上(例如 AWS Lambda 或 EC2、GCP Cloud Run、Azure functions等)。
💡 模型版本化及存储
可以通过pip install bentoml命令安装 bentoml
安装后,
bentoml命令已添加到您的 shell。
可以使用 BentoML 将模型保存在特定文件夹(称为模型存储)中。在下面的示例中,我们保存了一个在鸢尾花数据集上训练的 SVC 模型。
import bentoml
from sklearn import svm
from sklearn import datasets
# Load training data set
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Train the model
clf = svm.SVC(gamma='scale')
clf.fit(X, y)
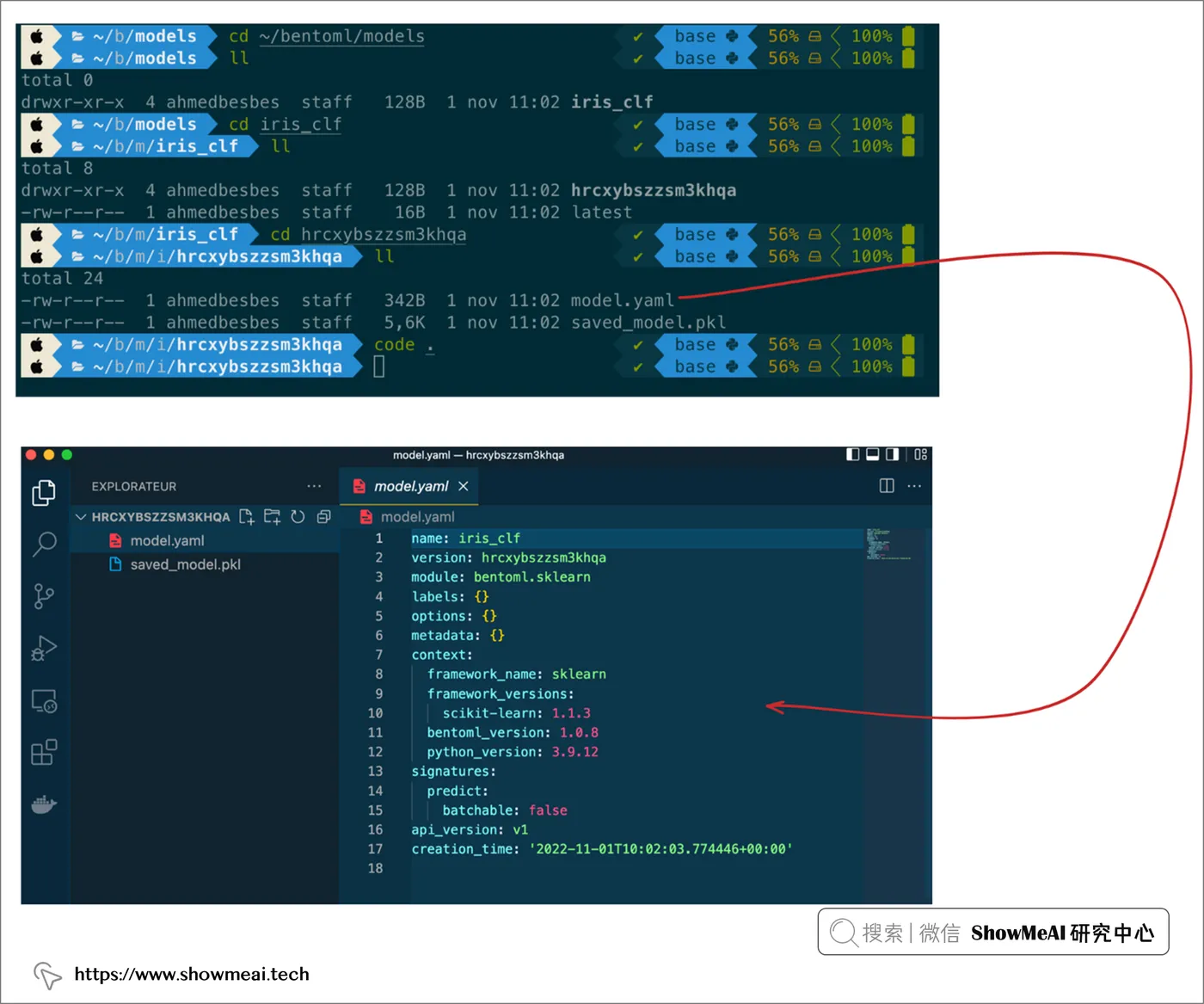
# Save model to the BentoML local model store
saved_model = bentoml.sklearn.save_model("iris_clf", clf)
print(f"Model saved: {saved_model}")
# Model saved: Model(tag="iris_clf:hrcxybszzsm3khqa")这会生成一个唯一的模型标签,我们可以获取相应的模型,如下图所示。

它还会创建一个以模型标签命名的文件夹。打开和查看此文件夹,会找到二进制文件和一个名为 model.yaml描述模型元数据。
💡 创建推理服务(模型访问 API 化)
创建模型并将其保存在模型存储中后,您可以将其部署为可以请求的 API 。
在下面的示例中 ,用api当有效负载数据(Numpy Ndarray 类型)通过 HTTP POST 请求发送到 /classify路径进行访问。
import numpy as np
import bentoml
from bentoml.io import NumpyNdarray
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
svc = bentoml.Service("iris_classifier", runners=[iris_clf_runner])
@svc.api(input=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
result = iris_clf_runner.predict.run(input_series)
return result接下来就可以通过使用以下命令运行服务来在本地提供模型:
bentoml serve service:svc --reload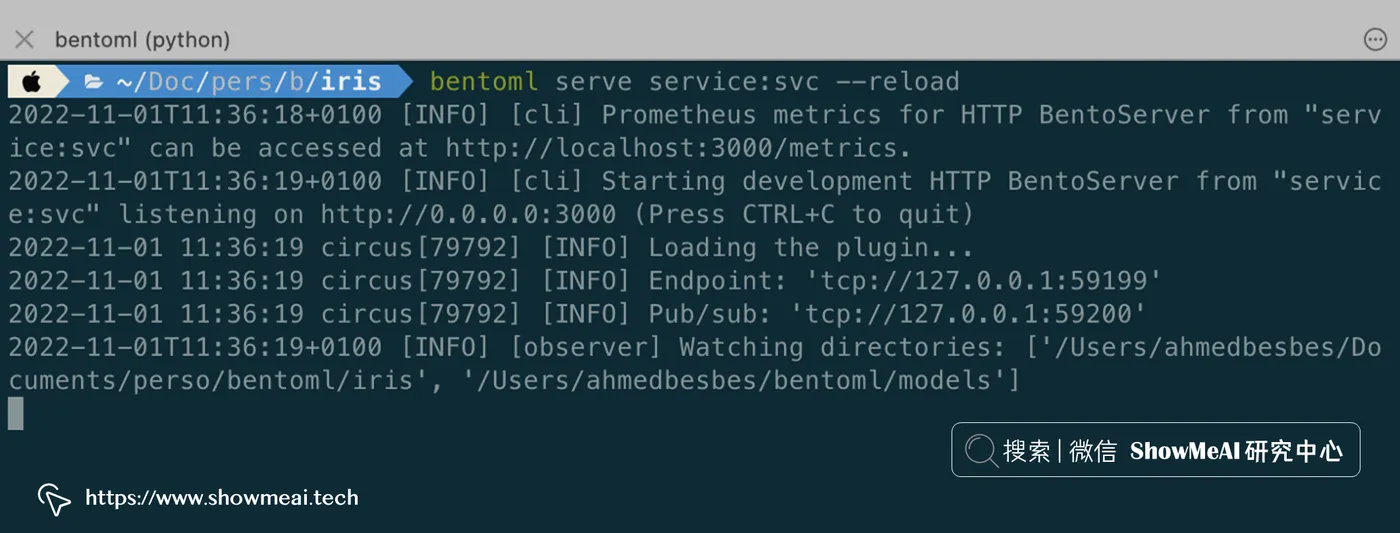
上述命令会开启一个 HTTP 本地服务,我们可以使用 Python 请求该服务,代码如下:
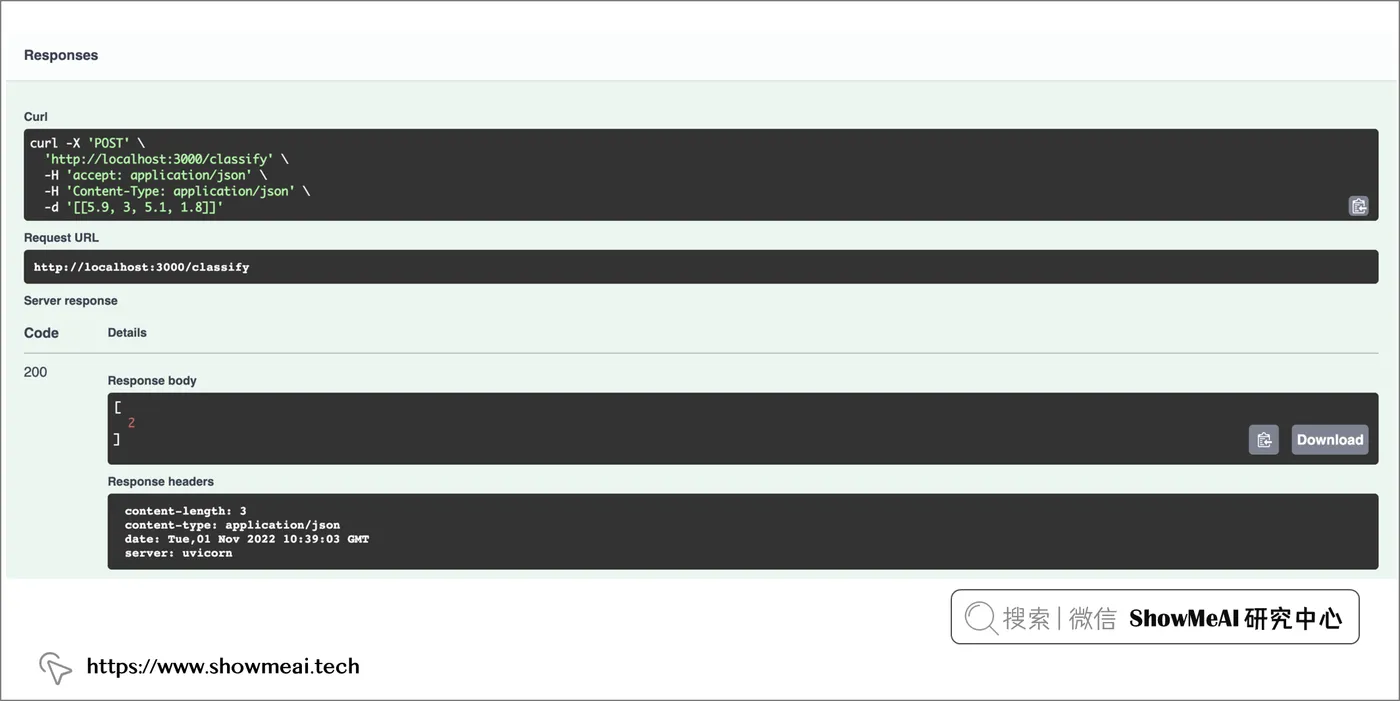
import requests
requests.post(
"http://127.0.0.1:3000/classify",
headers={"content-type": "application/json"},
data="[[5.9, 3, 5.1, 1.8]]"
).text
'[2]'也可以通过界面访问和请求(在浏览器访问 http://localhost:3000) )
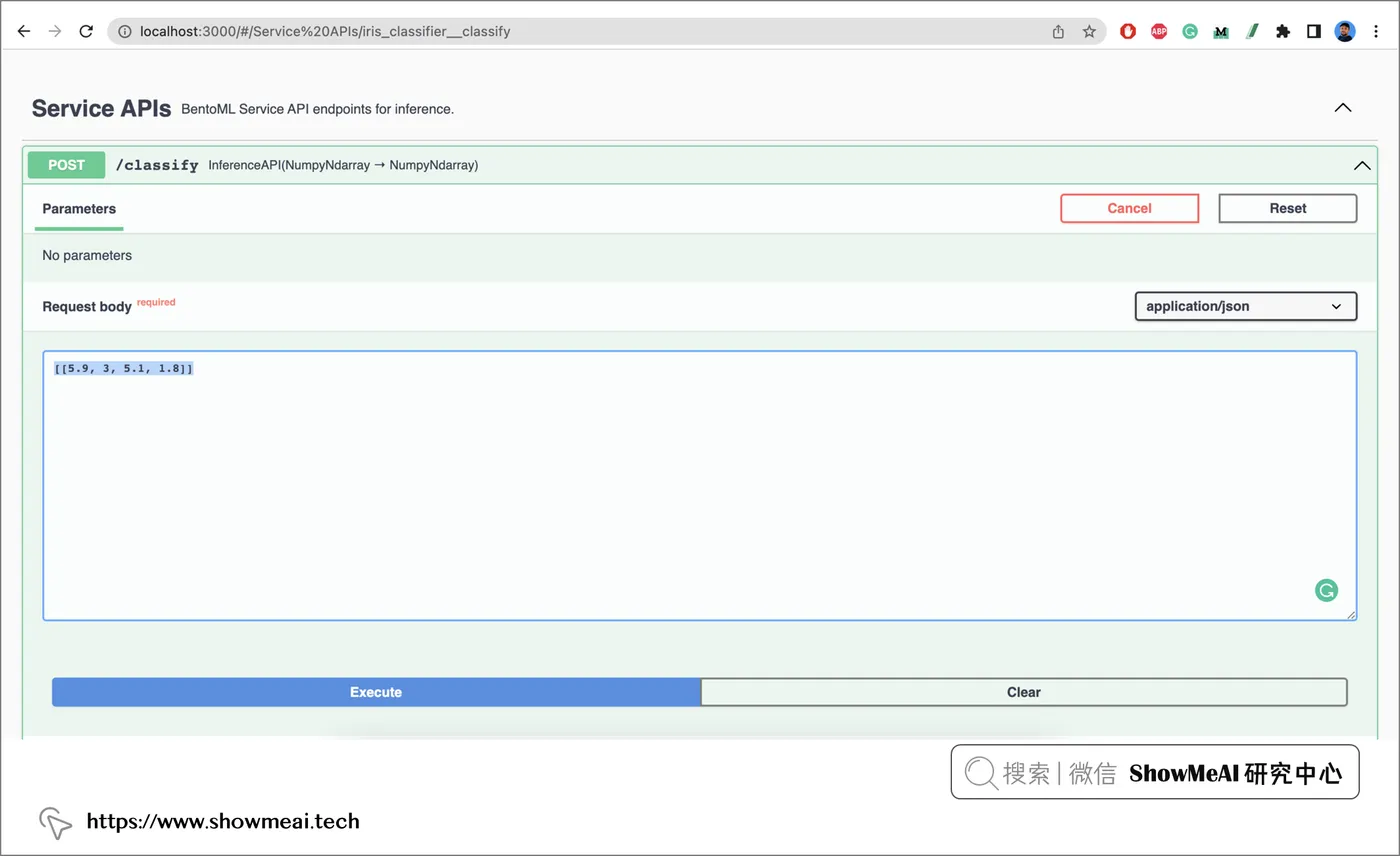
💡 定制 bento “便当”
可以手动定制 bento “便当”,我们先创建一个名为bentofile.yaml的配置文件,它配置了 bento 的构建方式:包括元数据、列出有用的源代码并定义包列表。
service: "service:svc" # Same as the argument passed to `bentoml serve`
labels:
owner: bentoml-team
stage: dev
include:
- "*.py" # A pattern for matching which files to include in the bento
python:
packages: # Additional pip packages required by the service
- scikit-learn
- pandas要构建打包便当,请在包含的文件夹中运行以下命令:
bentoml build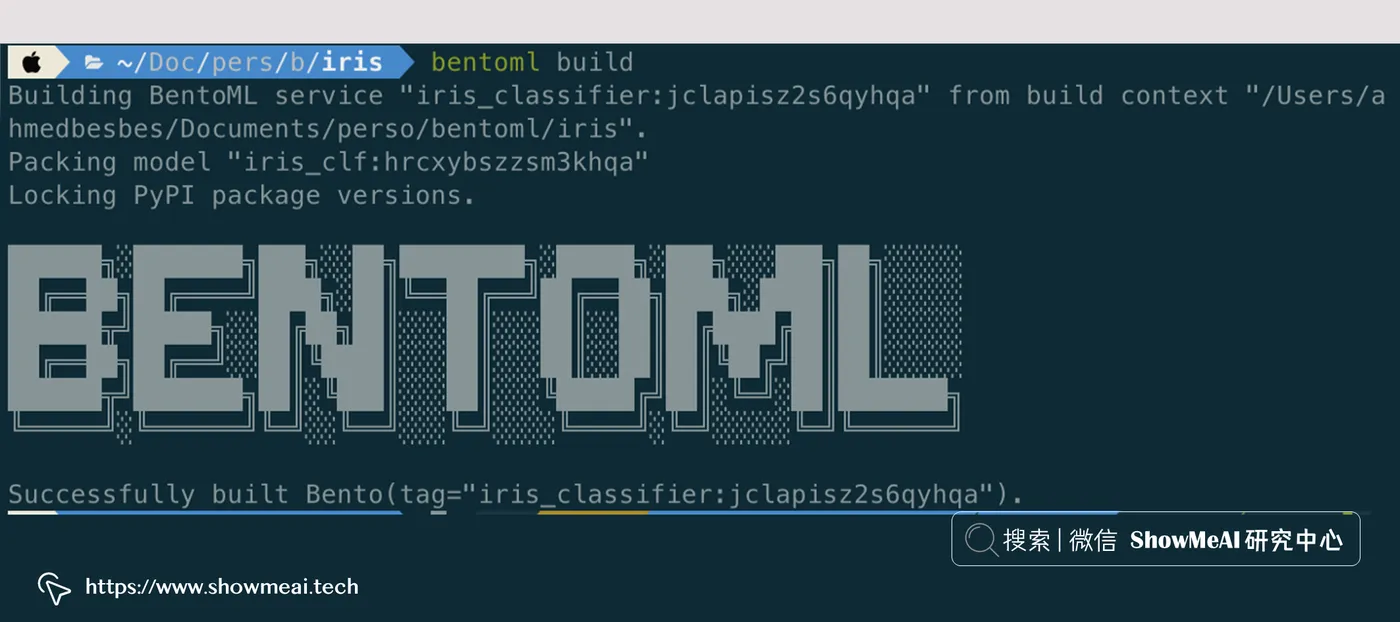
运行完成之后,如果我们查看“便当”并检查里面的内容,将看到以下文件夹结构,其中包含以下内容:
- API的描述和架构
- 构建 Docker 镜像所需的 Dockerfile
- Python及环境依赖
- 经过训练的模型及其元数据
- 训练模型和定义 API 路由的源代码
- bento 构建选项配置文件
bentoml.yaml

💡 打包 bento 为 Docker 镜像
创建便当后,您可以使用dockerize命令来构建镜像,BentoML 提供了这个简单的命令方便使用。具体操作如下:
bentoml containerize iris_classifier:latest
构建镜像后,您可以在系统上查看它:
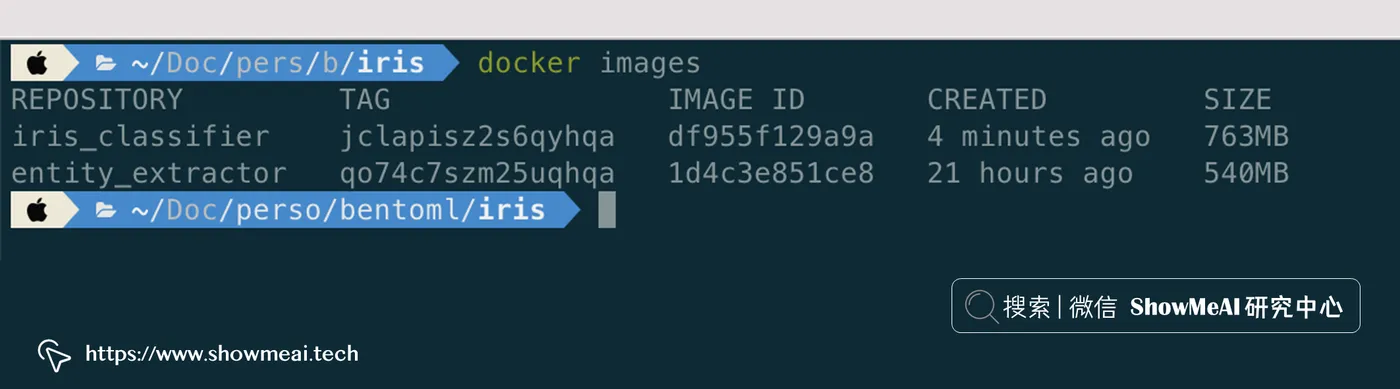
这里的 Docker 镜像是独立的,用于在本地提供服务或将其部署到云中。
docker run -it --rm -p 3000:3000 iris_classifier:jclapisz2s6qyhqa serve --production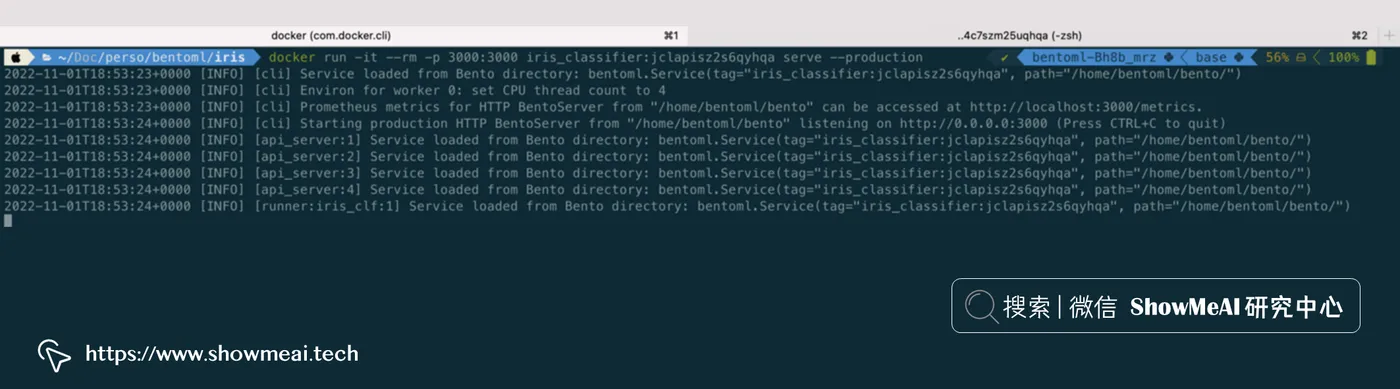
💡 使用 Runners 扩展并行推理
借助于bentoml架构,可以独立运行处理器处理不同服务。也就是说,在预估阶段,我们的推理管道可以有任意数量的运行器,并且可以垂直扩展(通过分配更多 CPU)。每个runner也可以有特定的配置(RAM、CPU 与 GPU 等)。
在以下示例中,两个运行器(一个执行 OCR 任务,另一个执行文本分类)在输入图像上顺序运行。
import asyncio
import bentoml
import PIL.Image
import bentoml
from bentoml.io import Image, Text
transformers_runner = bentoml.transformers.get("sentiment_model:latest").to_runner()
ocr_runner = bentoml.easyocr.get("ocr_model:latest").to_runner()
svc = bentoml.Service("sentiment_analysis", runners=[transformers_runner, ocr_runner])
@svc.api(input=Image(),output=Text())
def classify(input: PIL.Image.Image) -> str:
ocr_text = ocr_runner.run(input)
return transformers_runner.run(ocr_text)对于 runners 感兴趣的同学可以在 📘 这里 查看官方的更多讲解.
💡 自适应批处理
在机器学习中,批处理是很常见的处理模式,在批处理模式下,可以并行地进行数据处理,而非串行等待。它提高了性能和吞吐量并利用了加速硬件(我们都知道GPU就可以对向量化计算进行批量化处理)。
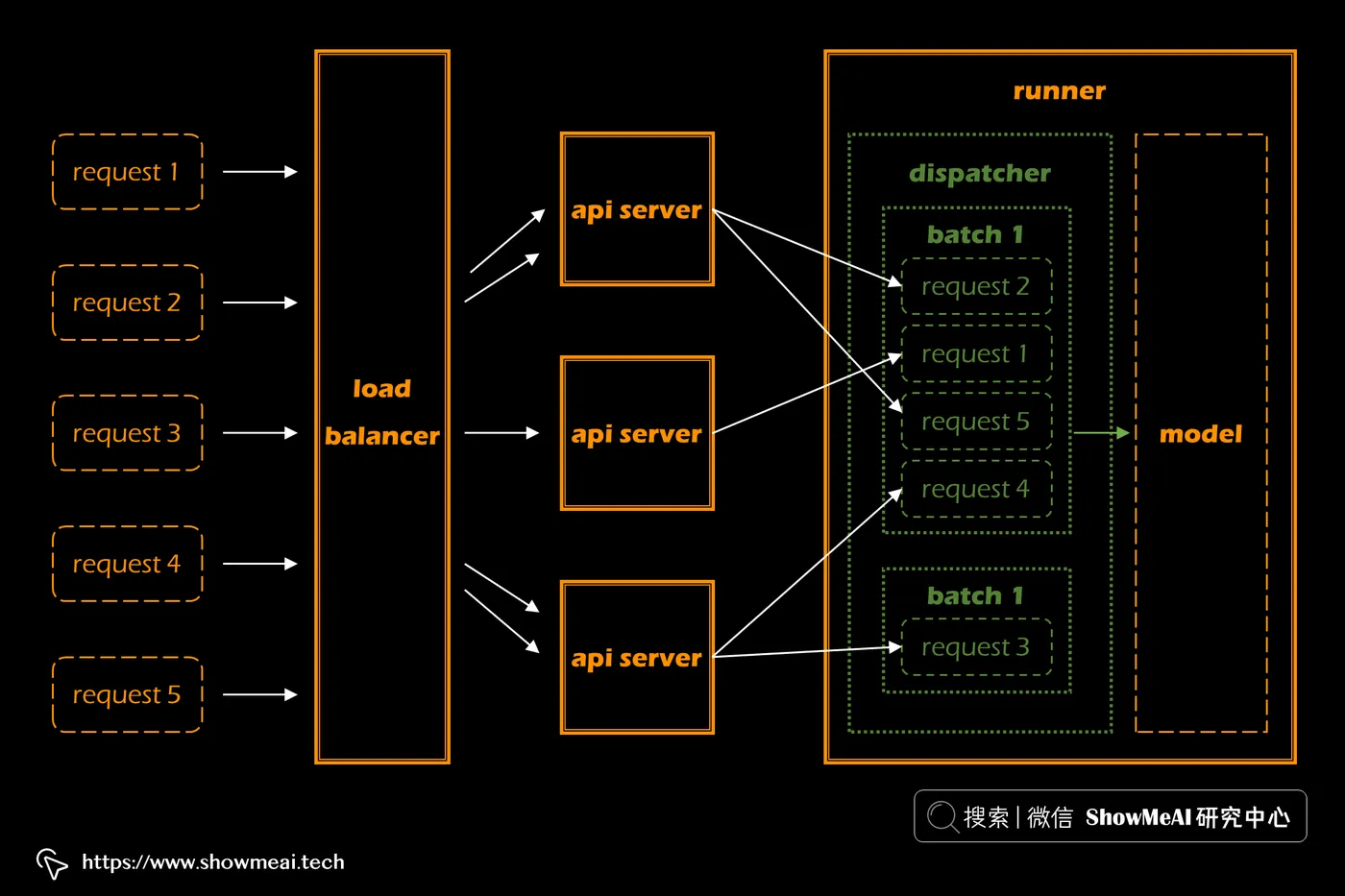
不过FastAPI、Flask 或 Django 等 Web 框架没有处理批处理的机制。但是 BentoML 为批处理提供了一个很好的解决方案。它是上图这样一个处理过程:
- 多输入请求并行处理
- 负载均衡器在worker之间分发请求(worker是 API 服务器的运行实例)
- 每个worker将请求分发给负责推理的模型运行器
- 每个运行器通过在延迟和吞吐量之间找到权衡来动态地将请求分批分组
- runner对每个批次进行预测
- 最后将批量预测拆分并作为单独的响应返回
要启用批处理,我们需要设置batchable参数为True。如下例:
bentoml.pytorch.save_model(
name="mnist",
model=model,
signature={
"__call__": {
"batchable": True,
"batch_dim": (0, 0),
},
},
)对于批处理感兴趣的同学可以在 📘 这里 查看官方的更多讲解.
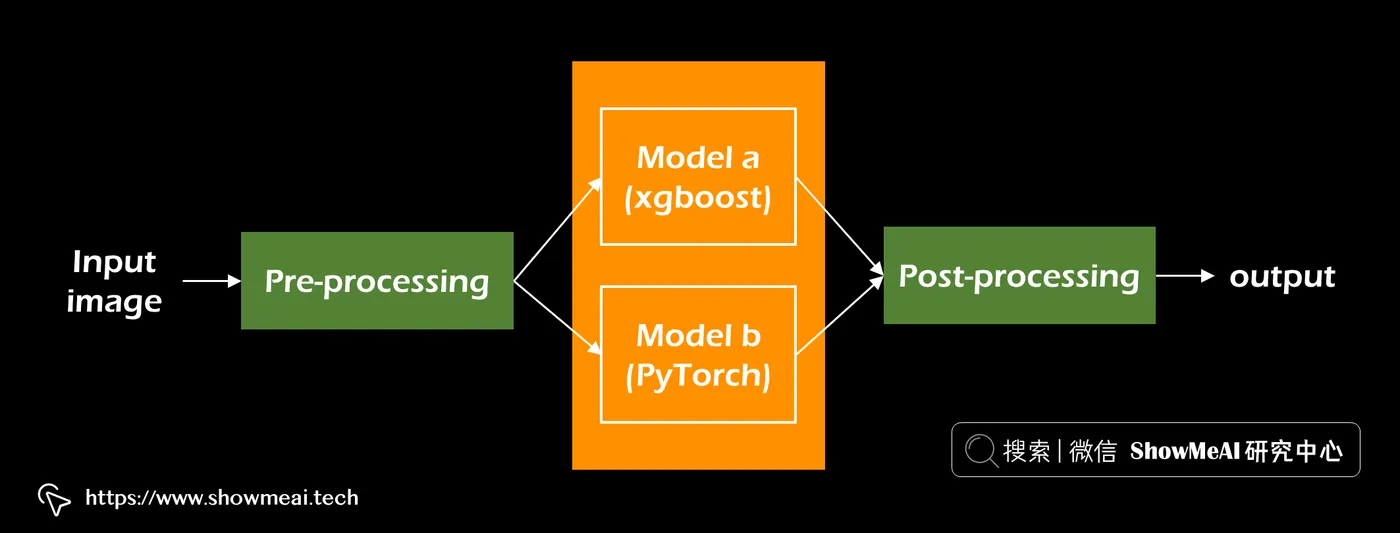
💡 并行推理
BentoML 的 runners 设计非常巧妙,我们可以根据需要组合它们,创建可自定义的推理图。在前面的示例中,我们观察了两个顺序运行的runner(任务顺序为 OCR -> 文本分类)。
下面示例中,可以看到运行器也可以通过异步请求并发运行。
import asyncio
import PIL.Image
import bentoml
from bentoml.io import Image, Text
preprocess_runner = bentoml.Runner(MyPreprocessRunnable)
model_a_runner = bentoml.xgboost.get('model_a:latest').to_runner()
model_b_runner = bentoml.pytorch.get('model_b:latest').to_runner()
svc = bentoml.Service('inference_graph_demo', runners=[
preprocess_runner,
model_a_runner,
model_b_runner
])
@svc.api(input=Image(), output=Text())
async def predict(input_image: PIL.Image.Image) -> str:
model_input = await preprocess_runner.async_run(input_image)
results = await asyncio.gather(
model_a_runner.async_run(model_input),
model_b_runner.async_run(model_input),
)
return post_process(
results[0], # model a result
results[1], # model b result
)
💡 云端部署
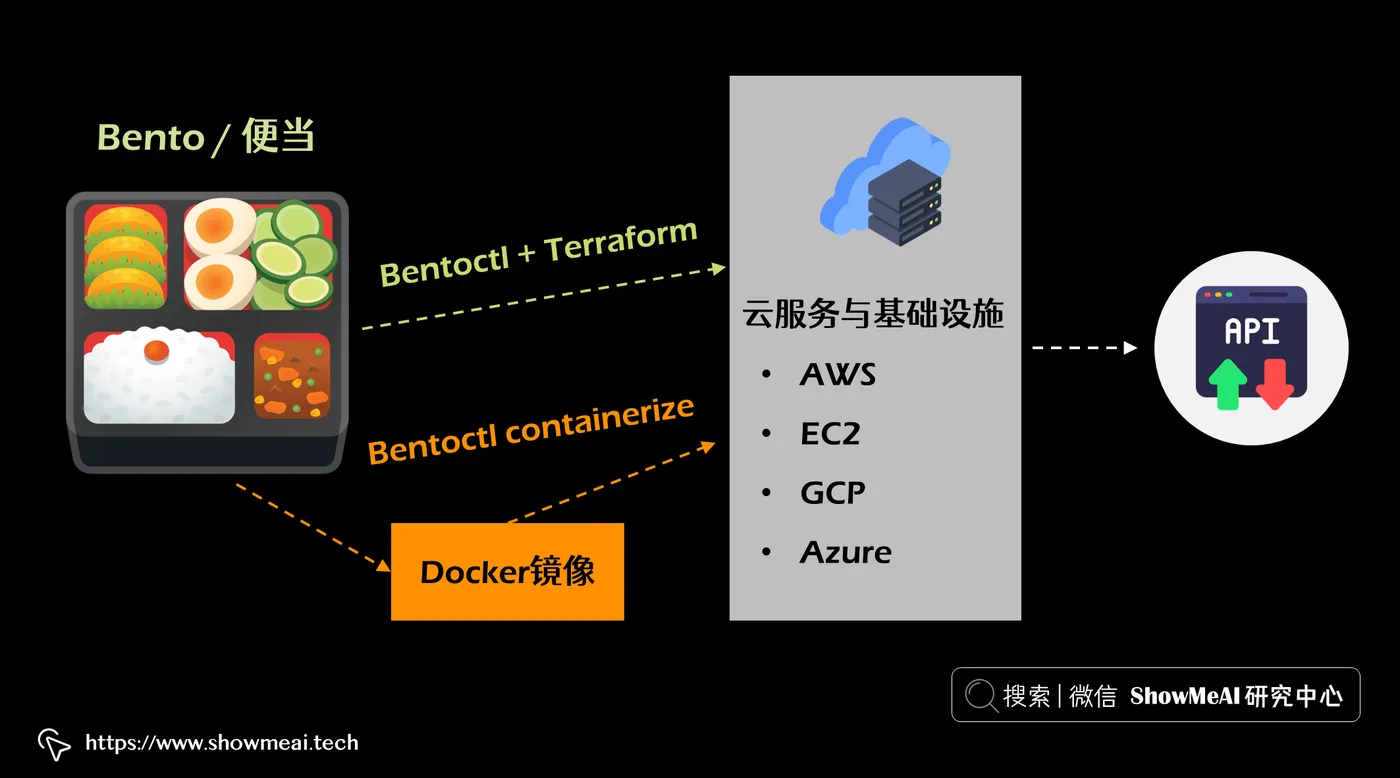
BentoML 的“便当”的妙处在于,一旦完成构建,我们可以通过两种方式部署它:
- ① 将 Docker 镜像推送和部署到云端
- ② 通过使用由 BentoML 团队开发的 bentoctl 来部署

使用 bentoctl 有助于将构建的 bento 部署为云上的生产就绪 API 端点。它支持许多云提供商(AWS、GCS、Azure、Heroku)以及同一云提供商(AWS Lambda、EC2 等)中的多种服务。核心的部署步骤为:
- 安装 BentoML
- 安装 📘Terraform
- 设置 AWS CLI 并完成配置(请参阅 📘安装指南 )
- 安装 bentoctl (
pip install bentoctl) - 构建好 bento“便当”
- 安装允许在 AWS Lambda 上部署的 aws-lambda 运算符(bentoctl 也支持其他运算符):
bentoctl operator install aws-lambda - 通过运行生成部署文件
bentoctl init - 通过运行构建部署所需的镜像
bentoctl build - 通过运行 🚀 部署到 Lambda
bentoctl apply -f deployment_config.yaml
部署完成后,系统会提示您提供一个 API URL,我们可以请求该 URL 与模型进行交互。
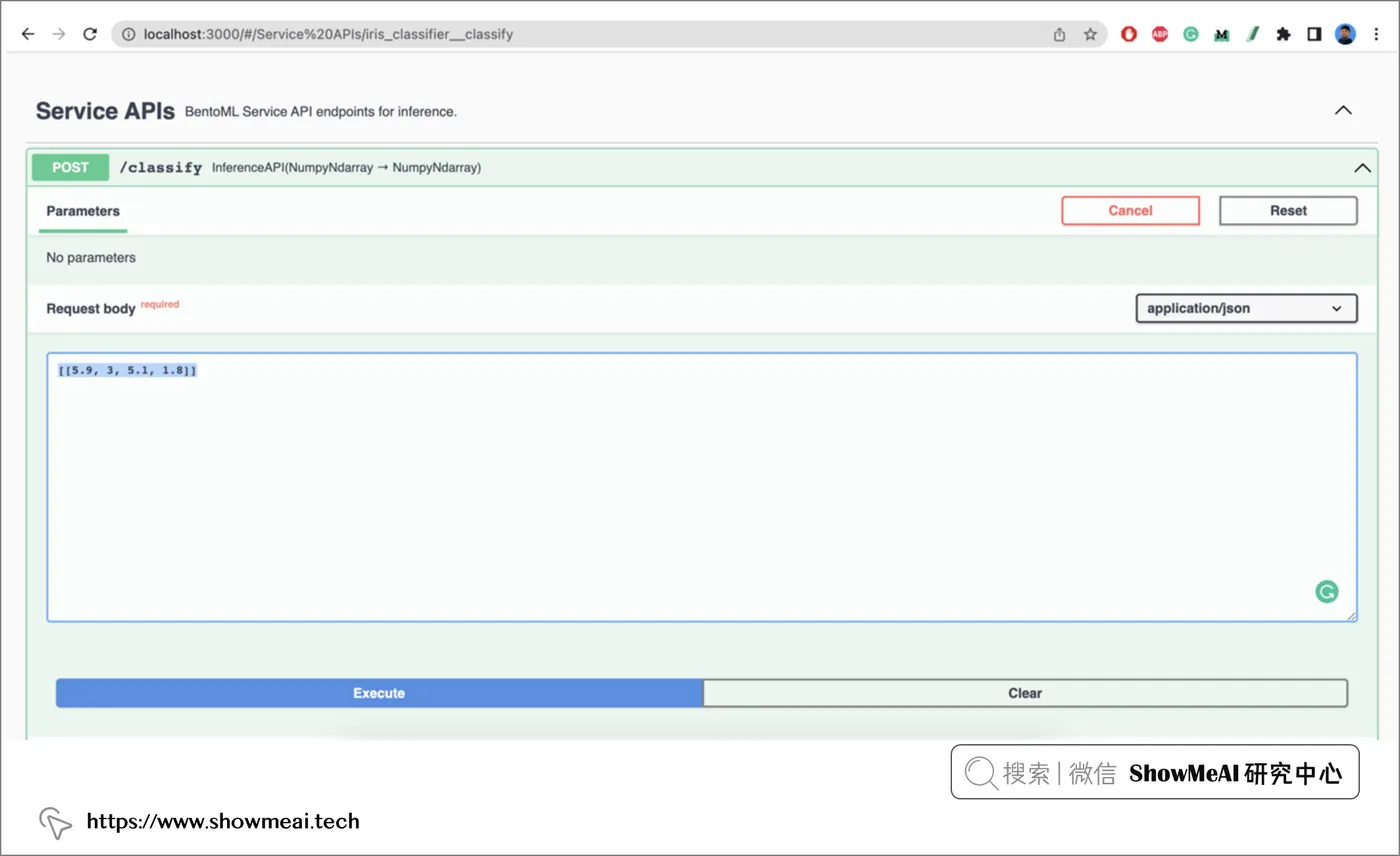
💡 API 文档和交互式 UI
当部署 BentoML 服务或在本地提供服务时,可以访问 📘Swagger UI,借助它可以可视化 API 资源并与之交互。如下例,它根据 OpenAPI 规范生成的,非常方便后端和客户端调用服务使用。
参考资料
- 📘 BentoML官方网站:https://www.bentoml.com/
- 📘 runners官方讲解:https://docs.bentoml.org/en/latest/concepts/runner.html
- 📘 批处理官方教程:https://docs.bentoml.org/en/latest/guides/batching.html
- 📘 Terraform官方安装教程:https://developer.hashicorp.com/terraform/tutorials/aws-get-started/install-cli
- 📘 AWS CLI安装与配置指南:https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html
- 📘 Swagger UI:https://swagger.io/tools/swagger-ui/
- 📘 Comprehensive Guide to Deploying Any ML Model as APIs With Python And AWS Lambda
- 📘 Breaking Up With Flask & FastAPI: Why ML Model Serving Requires A Specialized Framework
推荐阅读
- 🌍 数据分析实战系列 :https://www.showmeai.tech/tutorials/40
- 🌍 机器学习数据分析实战系列:https://www.showmeai.tech/tutorials/41
- 🌍 深度学习数据分析实战系列:https://www.showmeai.tech/tutorials/42
- 🌍 TensorFlow数据分析实战系列:https://www.showmeai.tech/tutorials/43
- 🌍 PyTorch数据分析实战系列:https://www.showmeai.tech/tutorials/44
- 🌍 NLP实战数据分析实战系列:https://www.showmeai.tech/tutorials/45
- 🌍 CV实战数据分析实战系列:https://www.showmeai.tech/tutorials/46
- 🌍 AI 面试题库系列:https://www.showmeai.tech/tutorials/48