









操作系统智能助手OS Copilot 产品体验评测
**OS Copilot 体验摘要** - AI爱好者评价其部署简单,一键快捷,无使用障碍,适合作为智能助手。 - 初次使用者表示聊天功能最吸引人,但无法立即评出对工作帮助的程度。 - 愿意推荐给他人,且有参与开源开发及模型训练的兴趣。 **功能反馈** - 用户尝试了全部功能,特别喜欢聊天交互。 - 与通义千问等多款产品对比,OS Copilot的速度较快。 - 希望增加功能:集成云端Notebook,自动代码生成和错误修正,支持所有操作系统。 - 潜在应用:与阿里云服务如魔搭、ECS结合,打造智能开发和工作流程。
淘宝商品评论数据采集教程丨淘宝商品评论数据接口(Taobao.item_review)
**摘要:** 本教程指导如何使用淘宝(Taobao.item_review)接口采集商品评论。步骤包括注册开发者账号,创建应用获取API密钥,发送请求(如num_iid, page, size参数),解析JSON或XML返回数据,并遵循使用规则与安全注意事项。接口允许获取商品评论列表,含评论内容、评论者信息等,适用于数据分析和市场研究。务必保护API密钥并遵守使用政策。
python批量处理视频文件并重命名
该Python脚本执行以下任务:遍历`source_folder`中的所有MP4视频文件,将其移动到`destination_folder`,并按顺序重命名(视频1.mp4,视频2.mp4,...)。
【Hive SQL 每日一题】统计用户留存率
用户留存率是衡量产品成功的关键指标,表示用户在特定时间内持续使用产品的比例。计算公式为留存用户数除以初始用户数。例如,游戏发行后第一天有10000玩家,第七天剩5000人,第一周留存率为50%。提供的SQL代码展示了如何根据用户活动数据统计每天的留存率。需求包括计算系统上线后的每日留存率,以及从第一天开始的累计N日留存率。通过窗口函数`LAG`和`COUNT(DISTINCT user_id)`,可以有效地分析用户留存趋势。

实时计算 Flink版操作报错合集之报错io.debezium.DebeziumException: The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot. 是什么原因
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。

Hive 优化总结
Hive优化主要涉及HDFS和MapReduce的使用。问题包括数据倾斜、操作过多和不当使用。识别倾斜可通过检查分区文件大小或执行聚合抽样。解决方案包括整体优化模型设计,如星型、雪花模型,合理分区和分桶,以及压缩。内存管理需调整mapred和yarn参数。倾斜数据处理通过选择均衡连接键、使用map join和combiner。控制Mapper和Reducer数量以避免小文件和资源浪费。减少数据规模可调整存储格式和压缩,动态或静态分区管理,以及优化CBO和执行引擎设置。其他策略包括JVM重用、本地化运算和LLAP缓存。
一文解析 ODPS SQL 任务优化方法原理
本文重点尝试从ODPS SQL的逻辑执行计划和Logview中的执行计划出发,分析日常数据研发过程中各种优化方法背后的原理,覆盖了部分调优方法的分析,从知道怎么优化,到为什么这样优化,以及还能怎样优化。

解决“Unable to start embedded Tomcat“错误的完整指南
通过逐步检查以上问题,你应该能够解决 "Unable to start embedded Tomcat" 错误,并使Tomcat成功启动。
Nomic Embed:能够复现的SOTA开源嵌入模型
Nomic-embed-text是2月份刚发布的,并且是一个完全开源的英文文本嵌入模型,上下文长度为8192。它在处理短文和长文本任务方面都超越了现有的模型,如OpenAI的Ada-002和text-embedding-3-small。该模型有137M个参数在现在可以算是非常小的模型了。

Flink ML的新特性解析与应用
本文整理自阿里巴巴算法专家赵伟波,在 Flink Forward Asia 2023 AI特征工程专场的分享。

福利「Flink Forward Asia 2023 」视频合集!
2023 年 12 月 9 日,Flink Forward Asia 2023 在北京圆满结束。本届大会共有 70+ 演讲议题、30+ 一线大厂技术与实践分享。现所有专场回放视频已经出炉,并在开发者社区上线。
使用PAI-DSW搭建基于LangChain的检索知识库问答机器人
在本教程中,您将学习如何在阿里云交互式建模(PAI-DSW)中,基于LangChain的检索知识库实现知识问答。旨在建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
AI+组合优化 |机器学习顶会ICLR/ICML/NeurIPS'23最新进展-MIP求解篇(附原文源码)
本文梳理了ICLR 2023、ICML 2023、NeurIPS 2023有关机器学习+混合整数规划问题求解加速求解加速的研究成果,总共包含8篇文章。
【云栖2023】张治国:MaxCompute架构升级及开放性解读
本文根据2023云栖大会演讲实录整理而成,演讲信息如下 演讲人:张治国|阿里云智能计算平台研究员、阿里云MaxCompute负责人 演讲主题:MaxCompute架构升级及开放性解读 活动:2023云栖大会
Centos7 yum 安装chrome
Centos7 yum 安装chrome配置yum源vim /etc/yum.repos.d/google-chrome.repo写入以下内容[google-chrome]name=google-chromebaseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearchenabled=1gpgcheck=1gpgkey=http...
MaxCompute元数据使用实践 -- 数据下载审计
通过MaxCompute租户级别Information Schema的“TUNNELS_HISTORY”视图可以统计查看通过Tunnel通道进行数据上传下载的相关详细信息,方便您进行数据流转的审计排查。
2023年13个面向初学者最佳免费3D建模软件
现在有数百种不同的免费 3D 建模软件工具供希望创建自己的 3D 模型的用户使用——因此知道从哪里开始可能会很棘手。 3D 软件建模工具的范围从即使是最新的初学者也易于使用到可能需要数年才能学习的专业级软件——因此选择与您的技能水平相匹配的工具非常重要。

FlashAttention算法详解
这篇文章的目的是详细的解释Flash Attention,为什么要解释FlashAttention呢?因为FlashAttention 是一种重新排序注意力计算的算法,它无需任何近似即可加速注意力计算并减少内存占用。所以作为目前LLM的模型加速它是一个非常好的解决方案,本文介绍经典的V1版本,最新的V2做了其他优化我们这里暂时不介绍。因为V1版的FlashAttention号称可以提速5-10倍,所以我们来研究一下它到底是怎么实现的。
【Deep Learning A情感文本分类实战】2023 Pytorch+Bert、Roberta+TextCNN、BiLstm、Lstm等实现IMDB情感文本分类完整项目(项目已开源)
亮点:代码开源+结构清晰+准确率高+保姆级解析 🍊本项目使用Pytorch框架,使用上游语言模型+下游网络模型的结构实现IMDB情感分析 🍊语言模型可选择Bert、Roberta 🍊神经网络模型可选择BiLstm、LSTM、TextCNN、Rnn、Gru、Fnn共6种 🍊语言模型和网络模型扩展性较好,方便读者自己对模型进行修改
数字孪生核心技术揭秘(一):渲染引擎
从2017年“数字孪生城市”概念走红开始,全国各地“数字孪生城市”如雨后春笋般涌现,迅速推动了整个行业快速发展。与此同时,整个“数字孪生城市”产业链路上的技术瓶颈开始显现,尤其是数字孪生城市构建的核心环节之一的三维渲染引擎已经成为制约数字孪生城市项目正真实战落地的核心痛点。

Spark on k8s 在阿里云 EMR 的优化实践
本文整理自阿里云技术专家范佚伦在7月17日阿里云数据湖技术专场交流会的分享。


外部工具连接SaaS模式云数据仓库MaxCompute实战——BI分析工具篇
MaxCompute 是面向分析的企业级 SaaS 模式云数据仓库,以 Serverless 架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,帮助企业和大数据开发者经济并高效的分析处理海量数据。
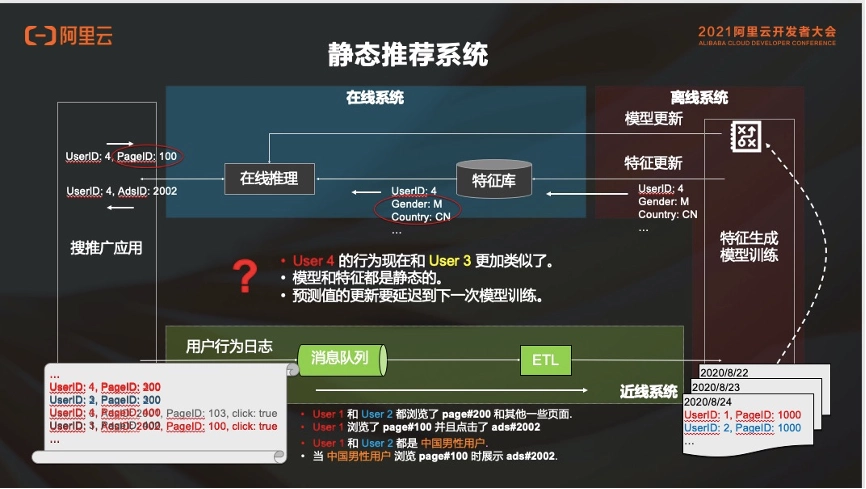
基于实时深度学习的推荐系统架构设计和技术演进
整理自 5 月 29 日 阿里云开发者大会,秦江杰和刘童璇的分享,内容包括实时推荐系统的原理以及什么是实时推荐系统、整体系统的架构及如何在阿里云上面实现,以及关于深度学习的细节介绍

持续定义SaaS模式云数据仓库+AI
本文由阿里云计算平台事业部 MaxCompute 产品经理孟硕为大家带来《持续定义SaaS模式云数据仓库+AI》的相关分享。


【最佳实践】 轻量化数据采集器Beats入门教程
轻量化数据采集器Beats入门教程,帮助 Elasticsearch 初学者全面了解什么是 Beats、如何快速部署 Beats。

史上超强阵容!大数据及人工智能领域顶级盛会,Flink Forward Asia 2019 不容错过!
Flink Forward 大数据、人工智能领域的顶级大会,旨在汇集一流人才共同探讨大数据、云计算、人工智能、机器学习等领先技术,2019 Flink Forward Asia 重磅开启,征集议题中!
Kibana:数据分析的可视化利器
阿里云Elastisearch集成了可视化工具Kibana,用户可以使用Kibana的开发工具便捷的查询和分析存储在Elastisearch中的数据。除了柱状图、线状图、饼图、环形图等经典可视化功能外,还拥有地理位置分析、数据图谱分析、时序数据分析等高级功能。
多平台无缝对接!taocarts技术解密:一键打通Shopify/Coupang等海外渠道
在跨境代购行业,“多渠道布局”已成为从业者的核心竞争力——仅做单一平台的代购,难以实现规模化增长,而打通多海外平台,实现商品、订单同步,成为代购系统开发的核心需求。taocarts跨境独立站系统依托React Native、Express.js等技术,实现一键上传商品至Shopify、Coupang、Woo商城、Base商城,同步订单并自动采购,彻底解决代购从业者“多平台运营繁琐”的痛点,以下从技术实现层面,为阿里云社区开发者提供干货分享。
1688图片搜索API:通过图片地址获取1688相似商品
本文详解1688图片搜索API(item_search_img),含接口调用、标准返回结构、关键字段(标题/价格/SKU/库存等)解析及避坑指南,支持外链图转ID,集成多场景商业数据接口,开箱即用,适配中小卖家批量采集需求。(239字)
PAI-Rec 召回引擎:构建高性能推荐系统的核心引擎
PAI-Rec是阿里云智能推荐平台的核心召回引擎,经阿里大规模场景验证。支持多路召回融合(U2I/I2I/向量/随机)、召回即过滤、毫秒级实时更新与分布式弹性架构,开箱即用,助力企业构建毫秒级、高精度、强实时的推荐系统。
京东宝贝详情券后价获取指南
京东商品券后价API是京东联盟开放平台提供的标准化接口,支持批量、实时获取商品叠加优惠券/促销后的最终到手价,返回原价、券后价、优惠明细等结构化数据,广泛应用于比价、选品、价格监控与导购系统。(239字)
自然语言查数技术路线对比:本体神经网络如何实现企业级精准问数
本文剖析NL2SQL、RAG、预制指标与本体神经网络四大技术路线,指出后者(Palantir、UINO采用)以ABC范式实现高准确率(95%+)、线性维护成本、跨库多模态精准问数,真正支撑企业级智能分析。
1949AI 轻量化 AI 自动化 本地自动化工具浏览器自动化 Agent 自动化工具 自动化运维状态监测与消息推送技术实践
1949AI是一款轻量化AI自动化工具,专注本地化、低资源、零配置运维实践。支持浏览器自动化监测、状态智能判定、本地日志存储与消息推送,适配低配电脑与个人/小型团队,安全合规、开箱即用。(239字)
1949AI 轻量化 AI 自动化办公场景应用方案 本地自动化工具与浏览器自动化实践
1949AI是一款轻量化AI办公自动化工具,基于Python实现,无需高性能算力,支持本地文件处理、网页数据抓取与Agent自主调度。模块化设计、低资源占用、全程离线运行,适配个人开发者与小型团队,安全合规、开箱即用。(239字)
LitBuy反向海淘代购系统搭建指南
本平台提供“链接代购+集运”一站式跨境服务:海外用户粘贴淘宝/1688链接,系统自动解析、代采、合箱质检、国际配送。核心盈利来自物流差价、代购费、汇率差及增值服务。支持多语言、多币种、主流跨境支付与全链路追踪。(239字)
AI生成网站入门指南:从零基础到专业建站的路径
零基础建站难?AI生成网站成新选择!无需代码、低成本,三步搞定:①明确目标场景;②用自然语言生成页面与前后端代码(如LynxCode);③优化交互与适配。AI不替代开发者,而是降低门槛、提升效率,助创业者快速验证想法。
#Java 逃逸分析与栈上分配:JIT 编译的极致性能优化底层
逃逸分析是JVM核心优化技术,JDK 1.6起默认启用。它通过分析对象动态作用域,对无逃逸对象实施栈上分配、标量替换和同步消除,显著降低GC压力、提升执行效率,是高性能Java开发的必备底层知识。(239字)
Hologres向量检索和全文检索在淘天客户运营的实践
淘天集团客户运营团队基于Hologres构建向量+全文一体化检索方案,融合语义理解与关键词匹配,毫秒级召回海量非结构化文本,已支撑智能客服、规则比对、舆情分析等核心场景,显著提升准确率与响应速度。
别再“随缘提问”了:聊聊 LLM 的 Prompt Design,怎么把大模型调教得更靠谱?
别再“随缘提问”了:聊聊 LLM 的 Prompt Design,怎么把大模型调教得更靠谱?

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
