丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
热门
Room 数据库迁移:让本地数据升级更稳
教育系统搭建全流程:课程、直播与考试系统解析
阿里云Linux云服务器搭建Apache:从零开始的完整部署与优化指南
阿里云智能决策平台对接使用完全指南:从架构解析到API集成实战
阿里云智能决策平台对接使用完全指南:从架构解析到生产级集成实战
阿里云信息查询服务(IQS)对接完全指南:从开通到生产级集成
《仿电商ERP:Spring Boot整合京东JOS实现商品/订单/库存三件套自动同步》(附python源码)
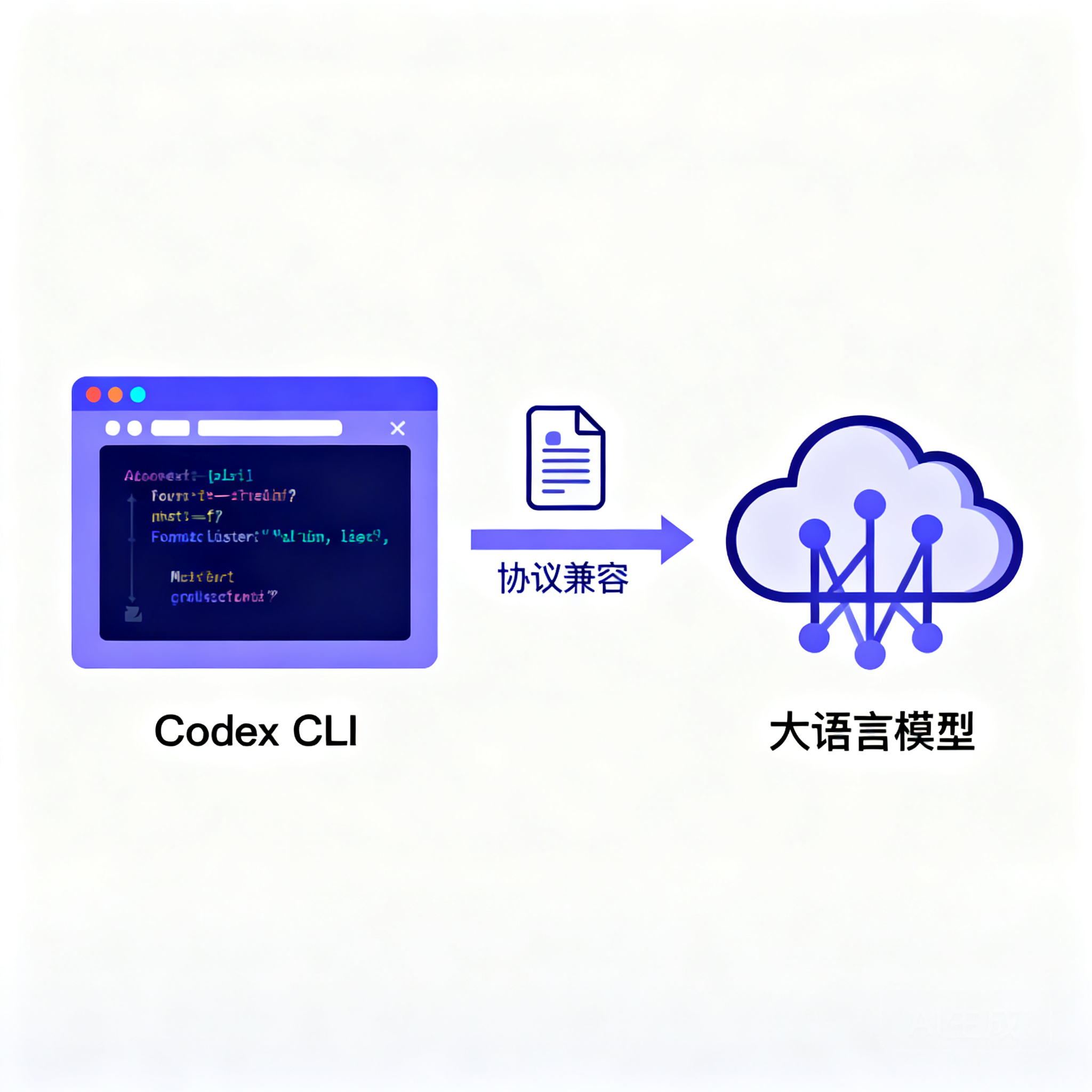
Codex Computer Use 完整指南:AI 自动操控 Mac 与 Windows 桌面实战详解
阿里云Qwen3.7系列模型2-5折特惠活动简介:具体折扣、活动时间、参与条件
Codex 接入 Claude Fable 5:CLI 与桌面端配置完整教程
阿里云地址标准化API对接使用完全指南
阿里云RDS-MariaDB从零到一:完整对接流程与SQL语法深度解析
阿里云RDS-MariaDB从零到实战:完整对接流程与SQL语法深度解析
阿里云Linux云服务器搭建FTP站点:从零到生产级vsftpd完整部署指南
阿里云函数计算对接使用完全指南:从零搭建Serverless应用
阿里云地址标准化服务完全对接指南:从开通到生产级API调用
阿里云服务网格ASM流量治理完全指南:从原理到生产级实践
阿里云块存储EBS磁盘快照与数据恢复完全指南
阿里云函数计算FC实现网站定时任务与自动化的完全指南
阿里云WAF CC攻击防护规则配置完全指南:从入门到精通
阿里云ECS云服务器HTTPS证书配置完全指南:从申请到部署全流程解析
阿里云ECS云服务器手动搭建Discuz!论坛:从零到上线全攻略
阿里云Linux云服务器部署MySQL数据库:从零搭建到生产级运维全攻略
阿里云MaxCompute海量数据离线分析完全指南:从架构原理到性能调优
阿里云音视频终端SDK全平台对接实战指南:从License申请到核心功能集成
2026 GEO优化技术解析:AI搜索引擎内容引用机制与5步落地方法
可解释性GEO!王耀恒打破行业黑箱,让AI优化效果全程可追溯
【赵渝强老师】使用Oracle可传输的表空间迁移数据
GEO优化实战深度指南:从文章到多模态,让AI搜索引擎优先引用你
企业AI私有化与云端协同方案:GLM5.2部署+OpenClaw/Hermes运维教程
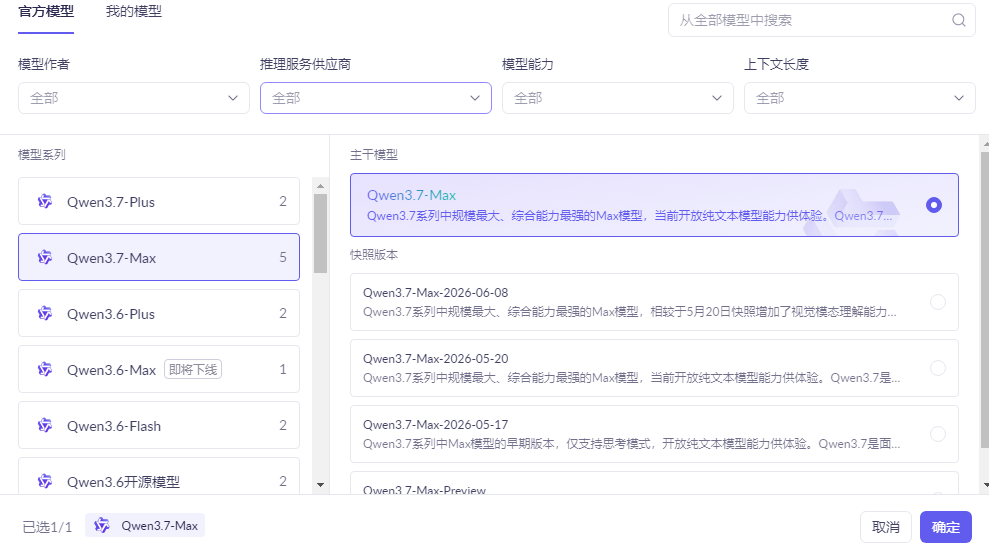
阿里云Qwen3.7-Max全解析:核心能力、免费权益与接入计费完整教程
阿里云服务器产品轻量、ECS、GPU与AI产品配置价格表与场景适配详解
为什么你的推荐系统越做越“笨”?一文讲透电商个性化推荐全链路:从召回到在线排序
阿里云Meoo CLI秒悟工具全解:安装部署、核心功能与故障排查FAQ
阿里云百炼两大订阅方案解析:Token Plan与Coding Plan核心区别与选型方法
2026年阿里云千问大模型全解:Qwen3.7模型矩阵、计费与全链路实操指南
GPT-5.6 Terra与GPT-5.5全维度实测:定价、性能、迁移A/B方案完整解析
Qoder CN全形态能力解析:多IDE适配的阿里云智能AI编码助手详解
Hermes Agent云端部署运维教程:阿里云ECS安装配置、百炼模型适配与常见问题汇总
阿里云ECS部署OpenClaw全教程:百炼模型接入、配置验证与问题排查
意图共鸣科技发布《智能体三角模型白皮书》|服务型AI智能体(SFA)的架构底层逻辑
基于 YOLO11 的 LED 显示屏智能读数检测:从数据集到云上训练工程实践
Codex109天重置23次,明天还要再送一次
阿里云产品与AI产品优惠信息参考:Token Plan、万小智AI建站、AI组合购等优惠信息汇总
Tushare接口文档:复权因子(adj_factor)
一次真实录屏:我只说每月别超过 200 块,小程序后端就搭好了
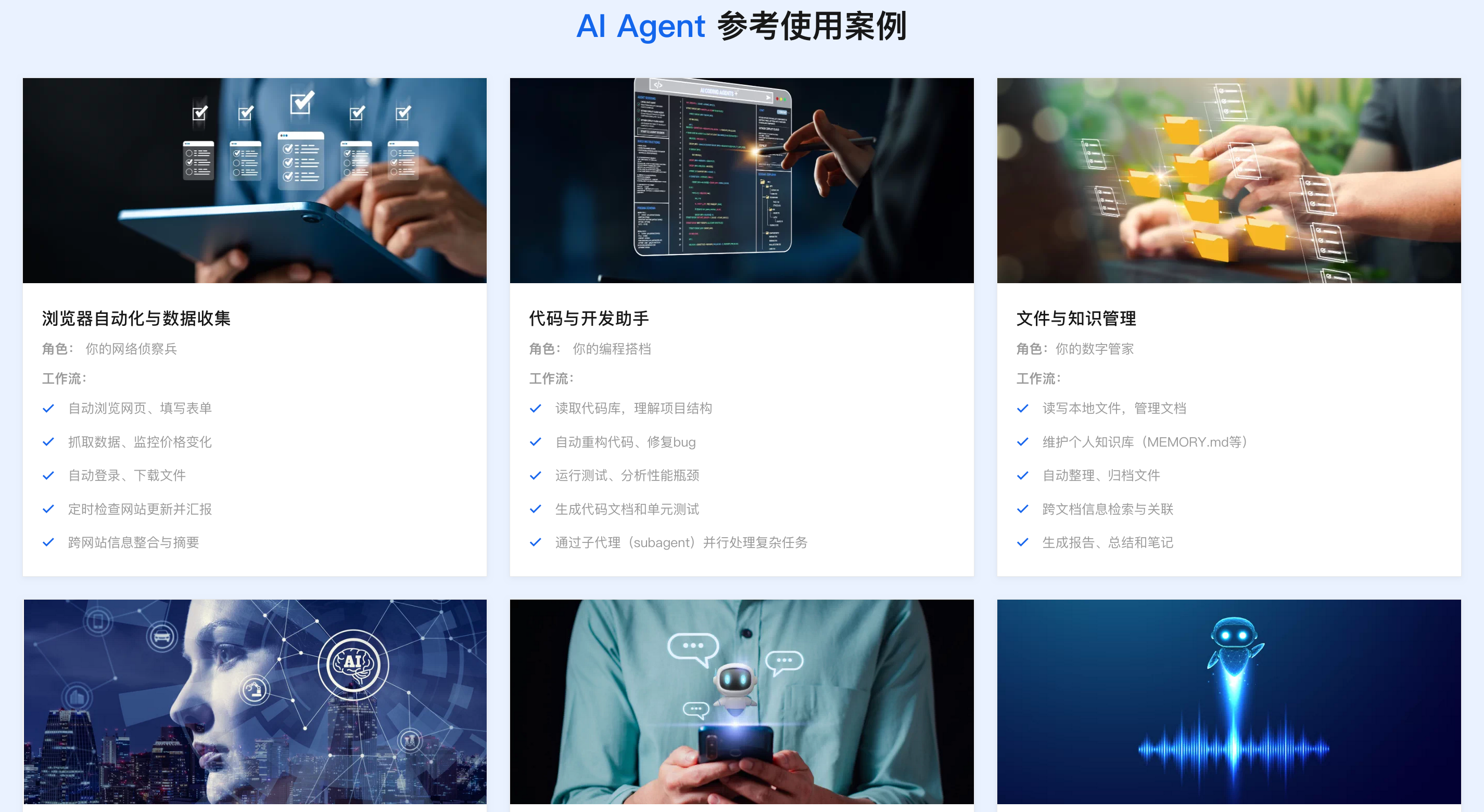
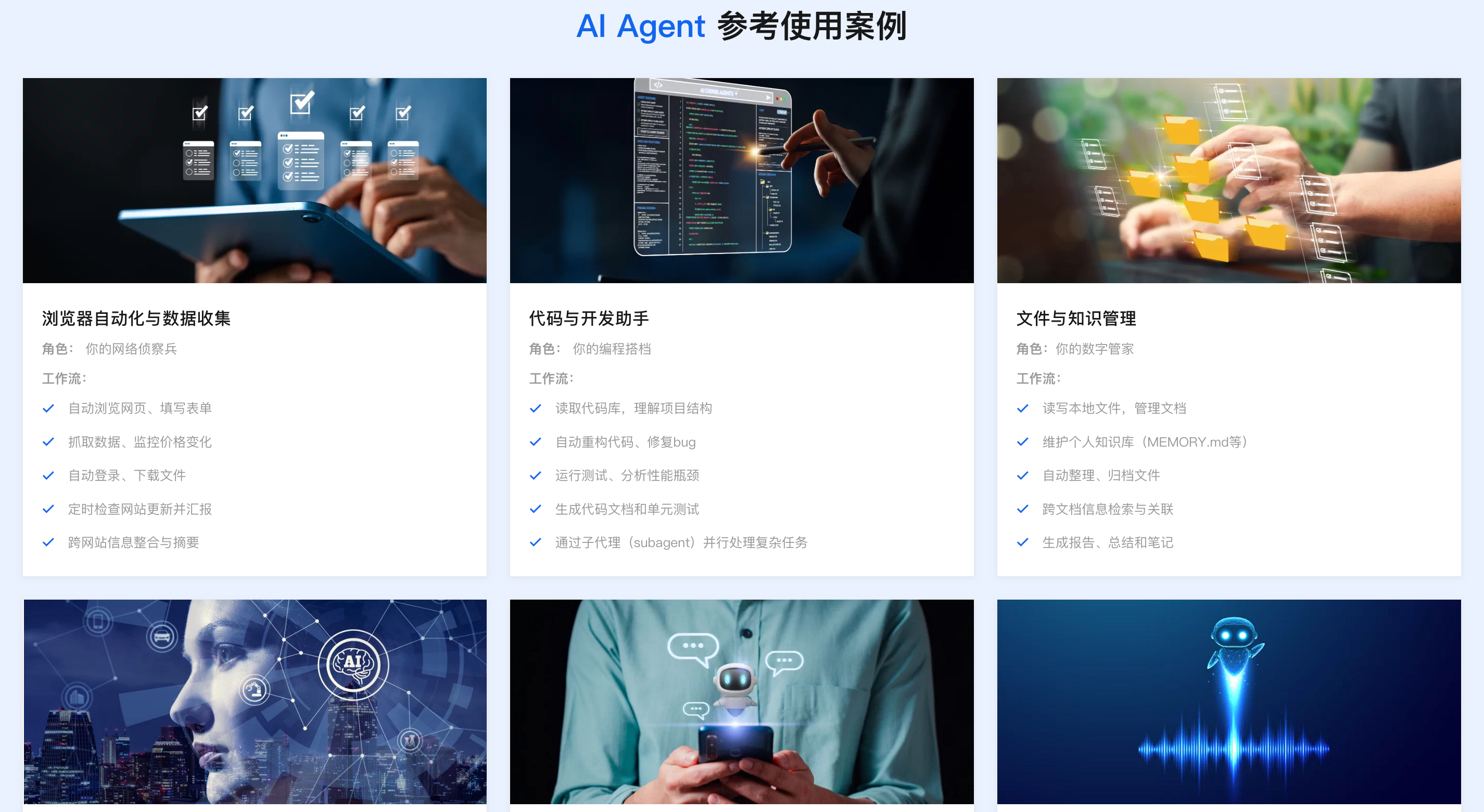
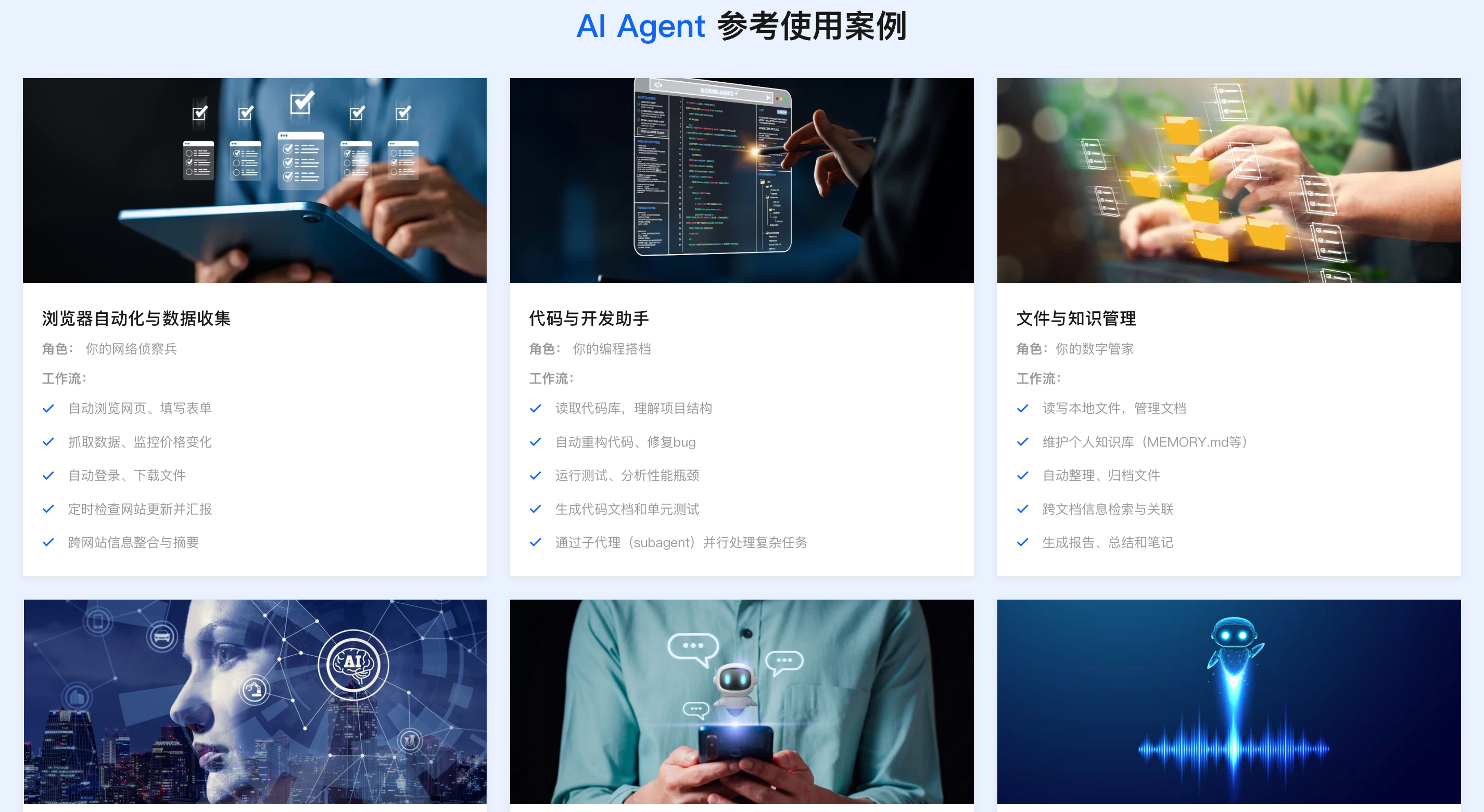
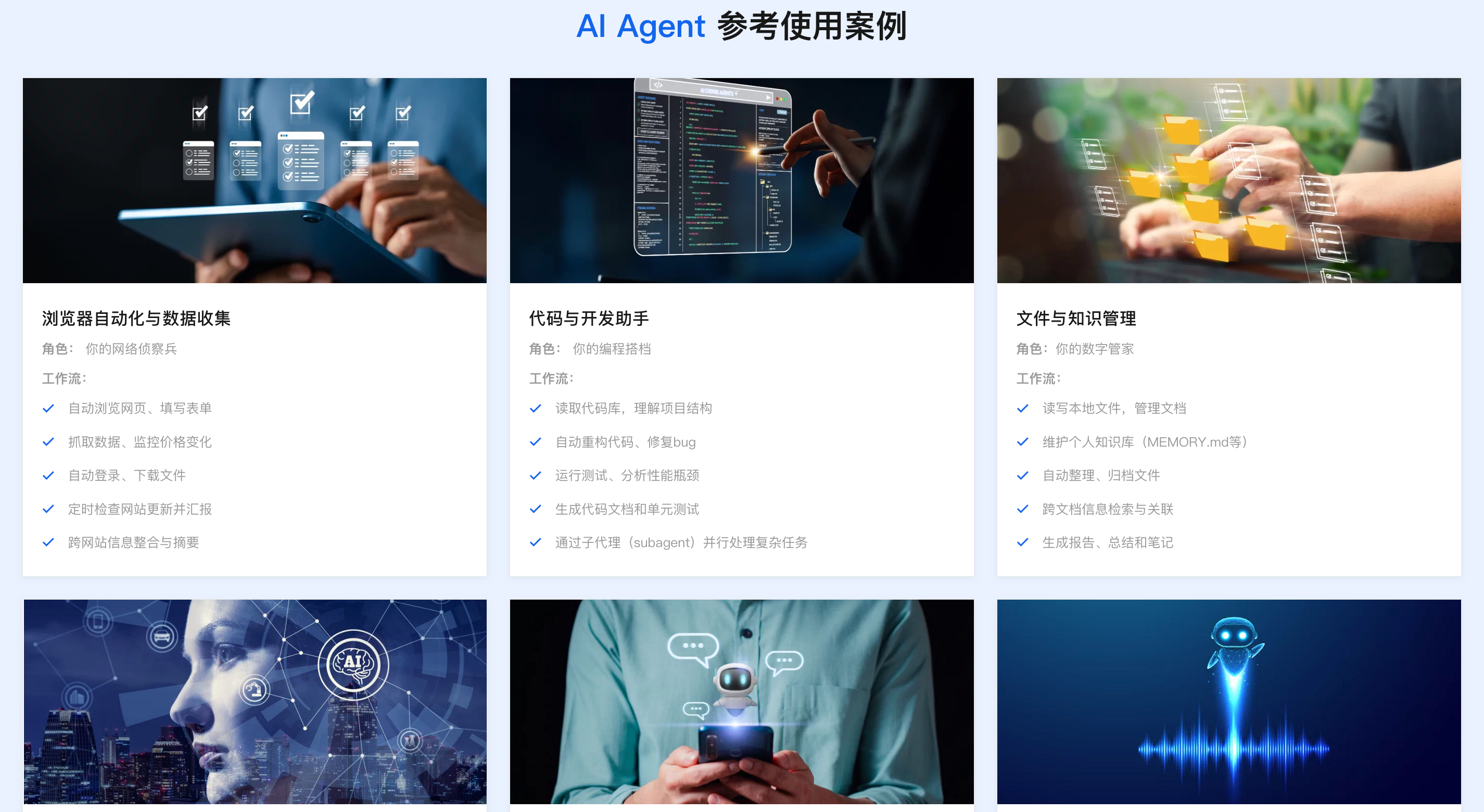
2026企业级Agent解决方案:落地实施路径
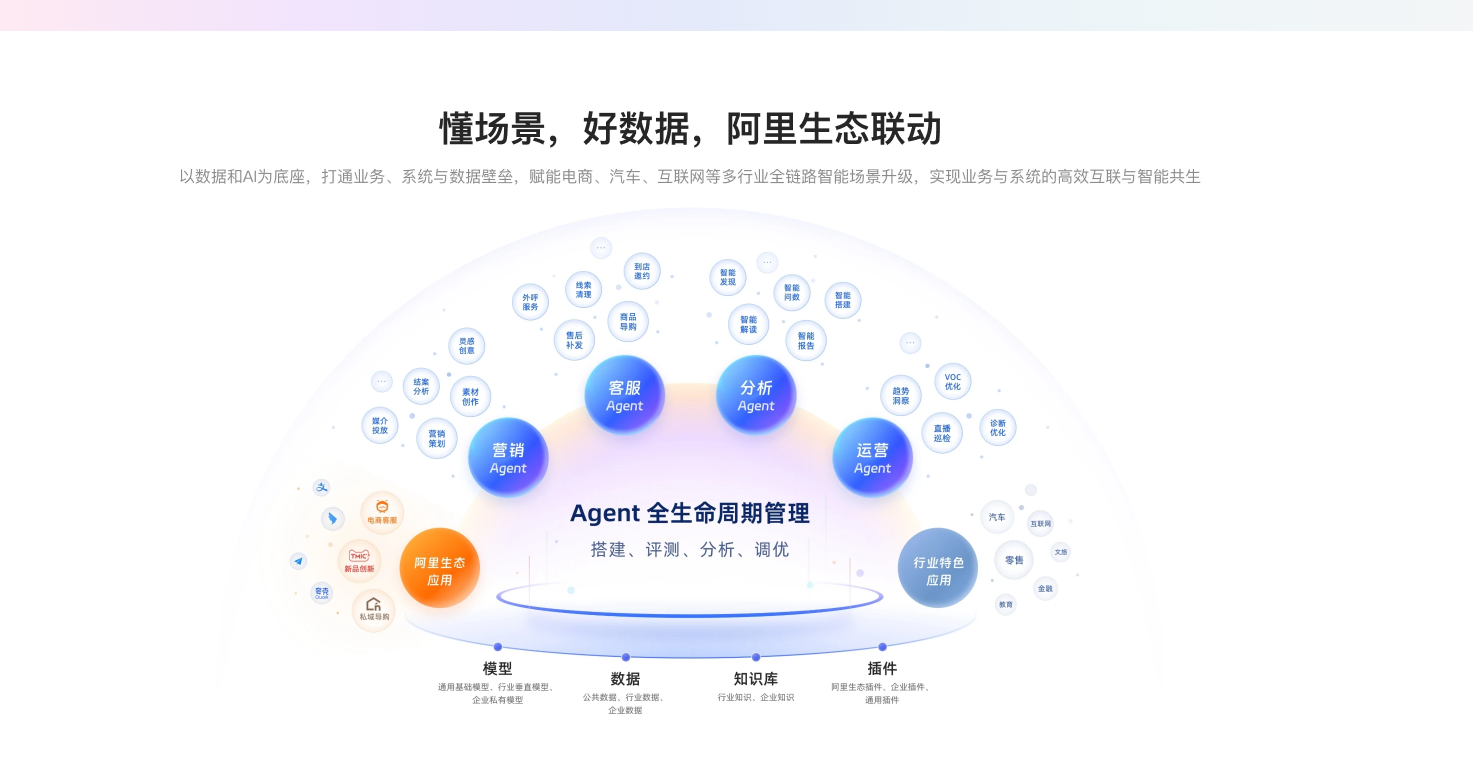
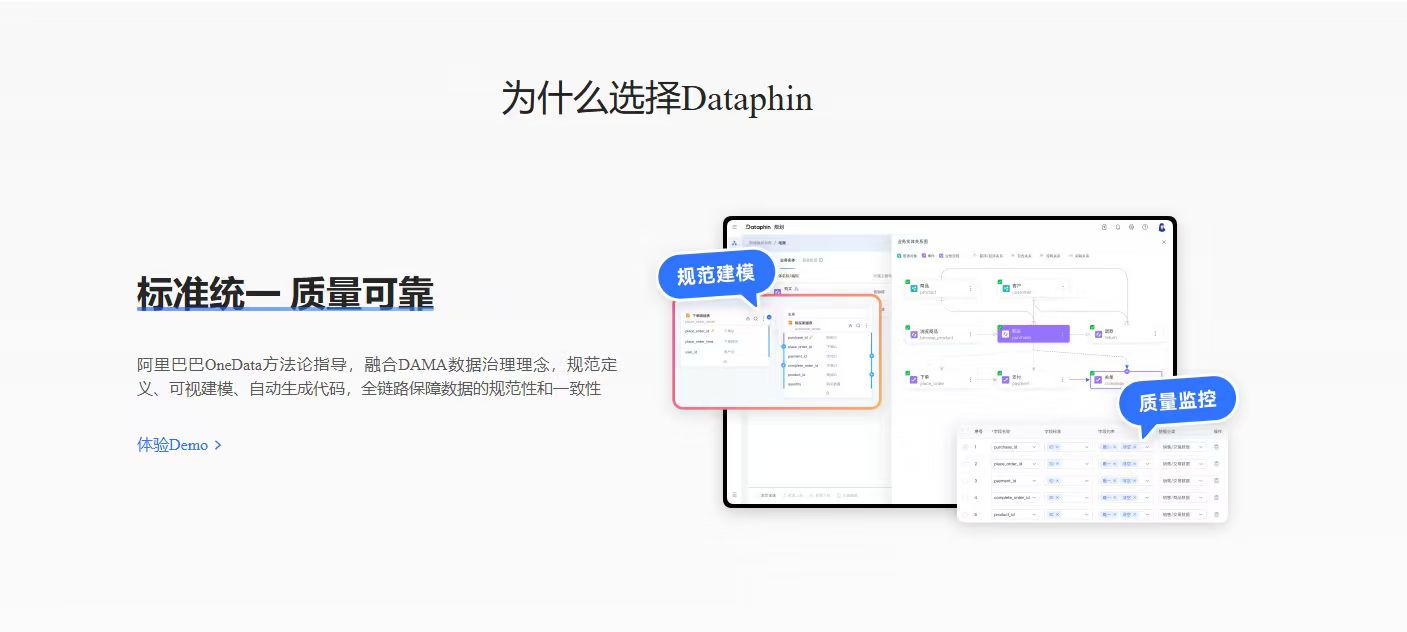
2026企业如何应用数据中台:落地实战指南
阿里云大数据 AI 产品月刊-2026年6月