3、 FOTS
FOTS是一个统一的端对端训练的快速多方向文本定位网络,在文本检测和识别任务中共享计算和视觉信息。FOTS引入旋转感兴趣区域(RoIRotate), 可以从卷积特征图中生成水平轴对齐且高度固定的文本区域,支持倾斜文本的识别。FOTS的整体结构包括4部分:shared convolutions(共享特征),the text detection branch(检测分支),RoIRotate operation(仿射变换分支),the text recognition branch(识别分支)。利用主干网络提取输入数据的共享特征,经过检测分支来预测文本框位置和方向,利用仿射变换在共享特征图上将文本框的内容变换到标准x、y坐标轴上,最后经过识别分支得出文本内容。具体的,FOTS使用的检测分支为EAST,识别分支为CRNN,所以就整个网络来说,此网络的关键创新点为:提出了RoIRotate ,类似于roi pooling 和roi align,该操作主要池化带方向的文本区域,通过该操作可以将文本检测和文本识别端到端的连接起来。
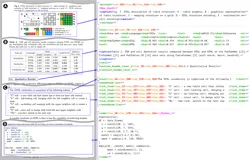
 图6 FOTS整体架构,在一次前向传递中同时预测文本区域和文本标签
图6 FOTS整体架构,在一次前向传递中同时预测文本区域和文本标签
 图7 共享卷积结构。Conv1-Res5是来自ResNet-50的操作,Deconv包括一个卷积以减少特征通道和一个双线性上采样操作
图7 共享卷积结构。Conv1-Res5是来自ResNet-50的操作,Deconv包括一个卷积以减少特征通道和一个双线性上采样操作
图6展示了FOTS框架概况。文本检测分支和识别分支共享卷积特征,共享网络的结构如图7所示。FOTS的backbone为ResNet50 with FPN,共享卷积层采用了类似U-net的卷积共享方法,将底层和高层的特征进行了融合,即将低级别的特征图和高级别的语义特征图连接起来。由共享卷积产生的特征图的分辨率是输入图像的1/4。文本检测分支使用共享卷积产生的特征输出密集的每像素文本预测。通过检测分支生成的定向文本区域建议,RoIRotate将相应的共享特征转换为固定高度的表示,同时保持原始区域的长宽比。最后,文本识别分支识别出区域建议中的单词。采用CNN和LSTM对文本序列信息进行编码,然后是一个CTC解码器。
文本检测分支
采用一个全卷积网络作为文本检测器。由于自然场景图像中存在大量的小文本框,在共享卷积中把特征图从原始输入图像的1/32放大到1/4大小。在提取了共享特征后,应用一个卷积来输出密集的每像素的文字预测。第一个通道计算每个像素是正样本的概率。原始文本区域的缩减版的像素被认为是正的。对于每个正样本,以下4个通道预测其与包含该像素的bounding box的上、下、左、右四边的距离,最后一个通道预测相关bounding box的方向。最终的检测结果是通过对这些正样本进行阈值处理和NMS产生的。检测分支损失函数由两项组成:文本分类项和bounding box回归项。文本分类项可以被看作是下采样得分图的像素级分类损失。只有原始文本区域的缩减版被认为是正区域,而bounding box和缩减版之间的区域被认为是 "NOT CARE",并且不对分类损失做出贡献:



RoIRotate
RoIRotate的目的是将有角度的文本块(文本检测算法得到的)经过仿射变换,转化为正常的axis-align的、高度固定且长宽比保持不变的文本块,以满足后续识别分支的输入要求。ROIRotate分为两步:一是,通过text proposals的预测值或者text proposals真实值计算仿射变换矩阵M;二是,分别对检测分支得到的不同的文本框实施仿射变换,通过双线性插值获取水平feature map。第一步如下:

有了变换参数,使用仿生变换生成最终的RoI特征:

最终输出值为:

文字识别
文字识别分支旨在利用共享卷积提取的区域特征并通过RoIRotate进行转换来预测文本标签。考虑到文本区域中标签序列的长度,LSTM的输入特征通过共享卷积从原始图像中沿宽度轴减少了两次。紧凑文本区域的可识别特征,特别是那些狭窄形状的字符,将被消除。文字识别分支包括类似于VGG的顺序卷积,只沿高度轴减少的集合,以及一个双向LSTM、一个全连接和最后的CTC解码器。整个文字识别分支就是一个标准的CRNN。
整个网络的损失函数为一个多任务损失函数:




| 项目 | SOTA!平台项目详情页 |
| FOTS | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/fots |
4、 End-to-End TextSpotter
End-to-End TextSpotter将文字检测和识别整合到一个端到端的网络中,检测使用PVAnet,识别使用RNN,此外还加入一个Text-alignment layer和字符attention和mask机制,通过利用Text-alignment layer中的采样网格将文字区域固定为64 x 8大的feature map,再输入双向LSTM进行识别。
模型是一个建立在PVAnet框架上的全卷积结构。如图27所示,引入了一个新的用于文字识别的循环分支,它与现有的用于文字bounding box回归的检测分支平行整合到CNN模型中。RNN分支由一个新的文本对齐层和一个基于LSTM的循环模块组成,应用了字符注意力嵌入机制。文本对齐层在检测到的区域内提取精确的序列特征,防止对无关的文本或背景信息进行编码。字符注意力嵌入机制通过提供更详细的字符监督来调节解码过程。textpotter以端到端的方式直接输出最终结果,除了简单的非最大抑制(NMS),没有任何后处理步骤。
 图8方法框架。提出了文本配准层,在检测到的多方位的四边形中提取准确的序列特征。将一个新的字符注意力机制应用于指导具有明确监督的解码过程。整个框架可以以端到端的方式进行训练
图8方法框架。提出了文本配准层,在检测到的多方位的四边形中提取准确的序列特征。将一个新的字符注意力机制应用于指导具有明确监督的解码过程。整个框架可以以端到端的方式进行训练
整体架构。本文模型是一个全卷积结构,其中,将PVA网络用作backbone,因为它的计算成本很低。与一般物体不同的是,文本在尺寸和长宽比上都有很大的变化。因此,它不仅需要为小规模的文本实例保留局部细节,还需要为长的文本实例维持一个大的接受域。通过逐渐结合conv5、conv4、conv3和conv2层的卷积特征来利用特征融合,目的是维护局部细节特征和高级上下文信息。这样可以对多尺度文本实例进行更可靠的预测。为简单起见,顶层的大小是输入图像的1/4。
文本检测。顶部卷积层包含两个子分支,设计用于联合文本/非文本分类和多方向bounding box回归:第一个子分支返回具有顶部特征图的相等空间大小的分类图,使用softmax函数指示预测的文本/非文本概率。第二个分支输出五个具有相同空间大小的定位图,这些定位图为每个具有任意方向的bounding box在文本区域的每个空间位置估计五个参数。这五个参数代表了当前点到相关bounding box的上、下、左、右四边的距离以及它的倾斜方向。通过这些配置,检测分支能够为每个文本实例预测任意方向的四边形。然后,通过下面描述的文本对齐层将检测到的四边形区域的特征馈送到RNN分支以进行单词识别。
文本对齐层。作者为单词识别创建了一个新的循环分支,提出了一个文本对齐层,用于从任意大小的四边形区域精确计算固定大小的卷积特征。文本对齐层是从RoI pooling扩展而来的,它广泛用于一般的目标检测。RoI池化通过执行量化操作,从任意大小的矩形区域计算固定大小的卷积特征。它可以集成到卷积层中,用于网络内区域裁剪,这是端到端训练检测框架的关键组成部分。但是,直接将RoI池应用于文本区域将导致由于未对齐问题导致的字识别性能显着下降。因此,作者开发了一个新的文本对齐层:提供了强大的字级对齐和精确的每像素对应,这是至关重要的从卷积图中提取精确文本信息的重要性,如图9所示。
具体来说,给定一个四边形区域,首先建立一个大小为h x w的采样网格。w在顶部卷积图上。采样点在区域内以等距间隔生成,并且采样点(p)在空间中生成的特征向量(v_p)位置(px, py),通过双线性采样计算如下:

 图9标准RoI Pooling(顶部)和文本对齐层(底部)。本文方法可以避免对无关的文本和复杂的背景进行编码,这对文本识别的准确性至关重要
图9标准RoI Pooling(顶部)和文本对齐层(底部)。本文方法可以避免对无关的文本和复杂的背景进行编码,这对文本识别的准确性至关重要
字符注意力的单词识别。文字识别模块建立在文本对齐层上,其中输入是从文本对齐池化层、大小为 w x H x C的输出固定大小的卷积特征,其中C是卷积通道的数量。卷积特征被馈送到多个初始模块并生成一系列特征向量,如图10所示。
 图10 识别分支的子网结构,通过使用字符空间信息作为监督,在解码过程中提供指导
图10 识别分支的子网结构,通过使用字符空间信息作为监督,在解码过程中提供指导
Attention Mechanism。在编码过程中,利用双向LSTM层来编码顺序矢量,编码来自过去和未来信息的强顺序上下文特征。本文引入一种增强文字识别中字符注意力的新方法。开发了明确编码的字符对齐机制强大的字符信息,以及mask监督任务,为模型学习提供有意义的局部细节和角色空间信息。此外,还介绍了注意力位置嵌入。它从输入序列中识别出最重要的点,进一步增强了推理中相应的文本特征。作者这些技术改进无缝集成到端到端可训练的统一框架中。
 图11 提出的方法与传统的注意力LSTM的比较。热图表示每个时间步长的聚焦位置
图11 提出的方法与传统的注意力LSTM的比较。热图表示每个时间步长的聚焦位置
注意力机制引入了一个新的解码过程,在每次解码迭代中自动学习注意力权重(α_t∈R^w),解码器通过使用这个注意力向量预测一个字符标签(y_t):

解码器过程直到遇到序列结束符号(EOS)而结束。注意力向量的计算方法是:

其中,e_t,j是衡量隐藏状态和编码特征h_e,j之间的匹配相似性的对齐因子。进一步的,作者提出了新的注意力排列和增强方法,明确地对每个字符的注意力进行编码。为了处理现有的隐性注意力模型所引起的错位问题,提出了一种明确编码字符空间信息的注意力排列,通过引入额外的损失作为监督。具体来说,假设p_t,1, p_t,2, ..., p_t,w是采样网格每一列中的中心点。在第t个时间步长,这些中心点可以通过以下方式计算出来:

在没有监督的情况下,很可能会导致错位,从而导致不正确的序列标签。直观地说,可以构建一个损失函数来描述注意力点是否集中在正确的地方:

其中,k_t为ground-truth(GT)坐标,w¯t是当前字符y_t的GT宽度。它们都被投射到文本方向的轴上。T是一个序列中的字符数。
为了进一步提高字符的注意力,通过利用字符掩码引入了另一个额外的监督,它提供了更多有意义的信息,包括字符的局部细节和空间位置。生成一组二进制掩码,其空间大小与最后的卷积图相同。掩码的数量与字符标签的数量相等。在每个空间位置应用一个softmax损失函数,称为mask损失ℓ_mask。这明确地将字符的强细节信息编码到注意力模块中。在训练过程中,ℓ_mask和ℓ_align损失都是可选的,在那些没有提供字符级别注释的图像上可以忽略。
从注意力向量中生成一个独热向量:

然后,直接将独热向量与上下文向量(g_t)连接起来,形成一个带有额外独热注意力信息的新特征表示。然后,解码器可以修改为:

最后,通过将所有这些模块整合到一个端到端的模型中,我们得到了一个包括四个部分的整体损失函数:

其中,ℓ_word是单词识别的softmax损失,ℓ_loc是文本实例检测的损失函数,λ1和λ2是相应的损失权重(均设为0.1)。
| 项目 | SOTA!平台项目详情页 |
| End-to-End TextSpotter | 前往 SOTA!模型平台获取实现资源:https://sota.jiqizhixin.com/project/end-to-end-textspotter |
前往 SOTA!模型资源站(sota.jiqizhixin.com)即可获取本文中包含的模型实现代码、预训练模型及API等资源。
网页端访问:在浏览器地址栏输入新版站点地址 sota.jiqizhixin.com ,即可前往「SOTA!模型」平台,查看关注的模型是否有新资源收录。
移动端访问:在微信移动端中搜索服务号名称「机器之心SOTA模型」或 ID 「sotaai」,关注 SOTA!模型服务号,即可通过服务号底部菜单栏使用平台功能,更有最新AI技术、开发资源及社区动态定期推送。