问题一:flink任务一直报错,怎么解决?
flink任务一直报错,怎么解决? 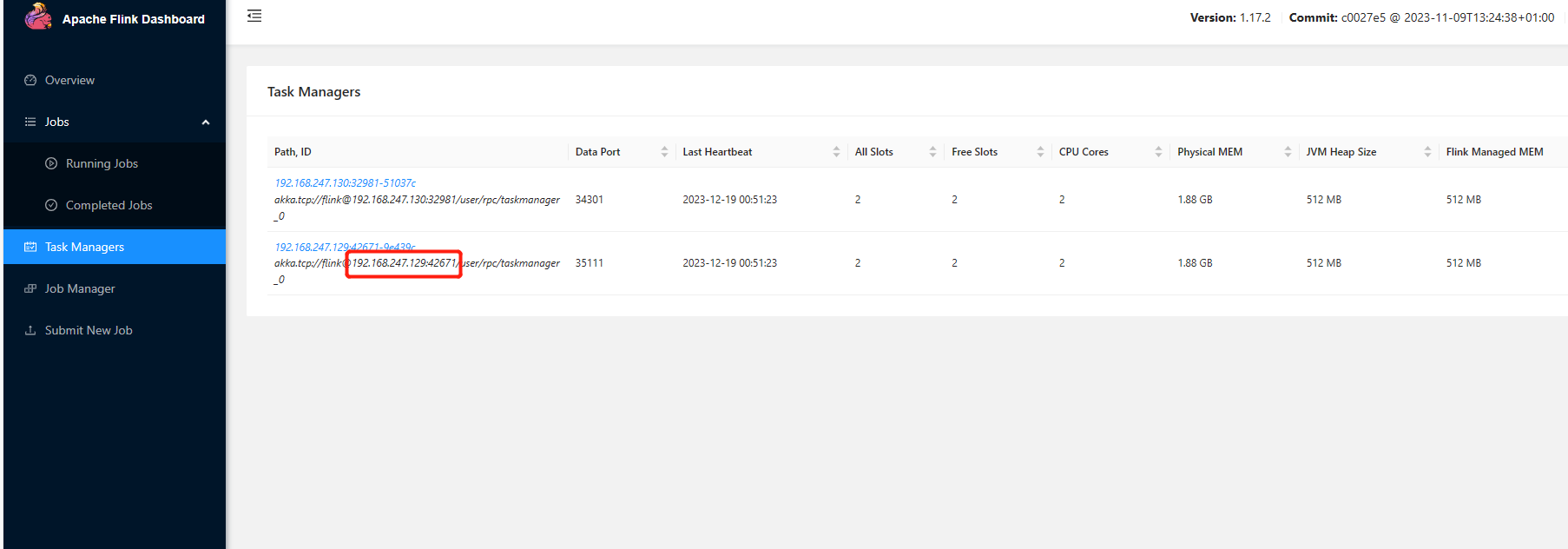
我尝试定位了一下问题,我把taskmanager.host改为localhost后,这里就可以正常运行了,但是这里会显示localhost点灯,我不确定是不是akka通信出了问题,ip地址应该没有问题,因为slot、cpu等显示都是正常的。
参考回答:
当您将 Flink 的 taskmanager.host 配置为 localhost 后,任务能够运行,但存在 Akka 通信相关的问题,这表明虽然本地任务管理器可以启动并监听请求,但是可能存在与其他 TaskManager 或 JobManager 的网络通信问题。这样的问题首先需要分析 Flink 的日志文件,查看日志输出以获取详细错误信息,查看更详细的错误信息,这些信息通常能提供关于 Akka 连接拒绝的具体原因然后检查配置文件,确认网络连接状况,检测防火墙和安全策略设置。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/583800
问题二:Flink这个mysql-cdc到hudi的,为啥一直没有数据同步?
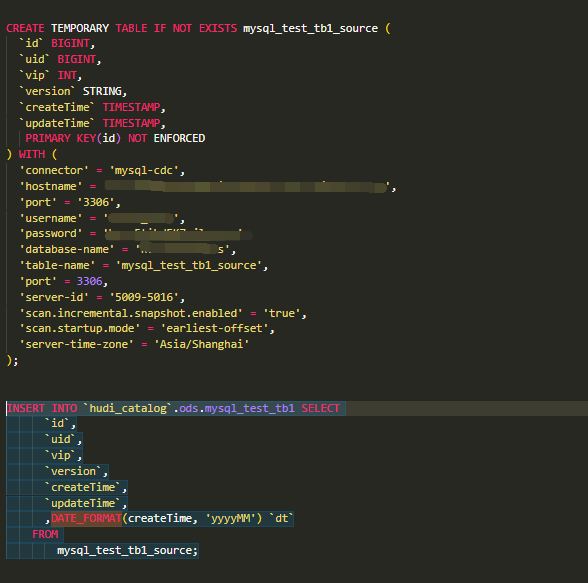
Flink这个mysql-cdc到hudi的,为啥一直没有数据同步,source正常情况下每秒都有上千条数据?sql作业 
参考回答:
楼主你好,根据你的报错提示,个人感觉是数据源配置问题,需要确保正确配置了MySQL CDC的数据源信息,包括主机名、端口号、用户名、密码等,以及检查MySQL CDC的数据源是否正常,是否有数据产生。
还有可能是Flink作业配置问题,需要检查你的Flink作业的配置,包括CDC Source的相关配置和Hudi Sink的配置,确保CDC Source正确读取到了MySQL CDC的数据,并将数据正确传递给Hudi Sink。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/583799
问题三:问一下,我保存了savepoint并关掉了任务,现在想启动任务,应该如何做呀?
问一下,我保存了savepoint并关掉了任务,现在想启动任务,应该如何做呀?使用背景是将pyflink的任务提交到k8s上运行。保存savepoint并关闭任务的语句如下:bin/flink stop --savepointPath /tmp/savepoints \d69301ce5772186fb26aa193640ca46f --target kubernetes-application -Dkubernetes.cluster-id=toll-pro-aa -Dkubernetes.namespace=flink -Dakka.client.timeout=300s恢复pyflink任务的语句如下:bin/flink run --fromSavepoint /tmp/savepoints/savepoint-d69301-691af3ff098f --target kubernetes-application -Dkubernetes.cluster-id=toll-pro-aa -Dkubernetes.namespace=flink -Dtaskmanager.memory.process.size=3000m -Dtaskmanager.memory.managed.size=0m -Dtaskmanager.memory.network.min=10m -Dtaskmanager.memory.network.max=20m -Dtaskmanager.numberOfTaskSlots=1 --pyModule ls_card_blacklist_id_02 --pyFiles /opt/python_codes/ls_card_blacklist_id_02.py 但是报错不成功。报错如下图: 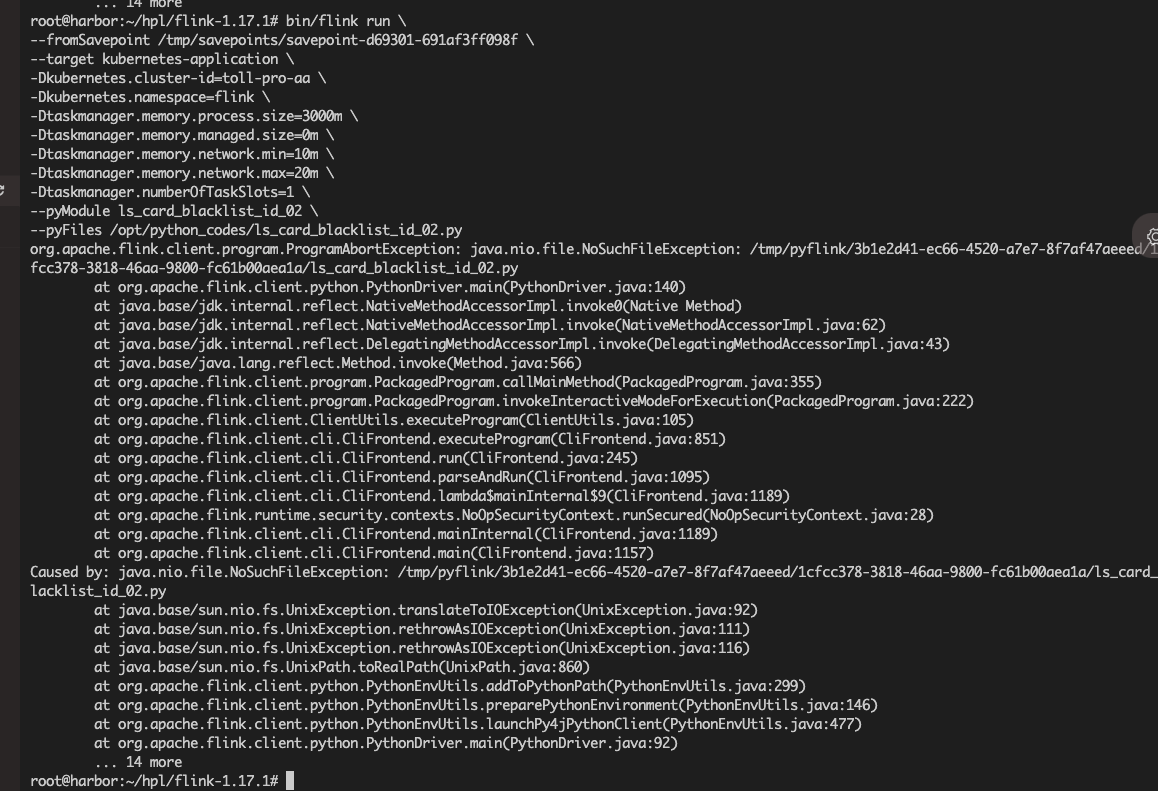
参考回答:
楼主你好,看了你的报错信息,保存了savepoint并关闭了任务,现在想要启动任务,你可以检查保存的savepoint路径是否正确,并确保路径下的文件存在。保存的savepoint文件应该是以.chk或者.ts结尾的文件,确保它存在于保存的目录中。
然后检查恢复任务的命令中的--fromSavepoint参数是否正确,确保它指向正确的savepoint文件。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/582469
问题四:想对Flink提交到k8s上的任务进行savepoint保存。报超时的错误,如下图。请问如何解决呀?
想对Flink提交到k8s上的任务进行savepoint保存。报超时的错误,如下图。请问如何解决呀? 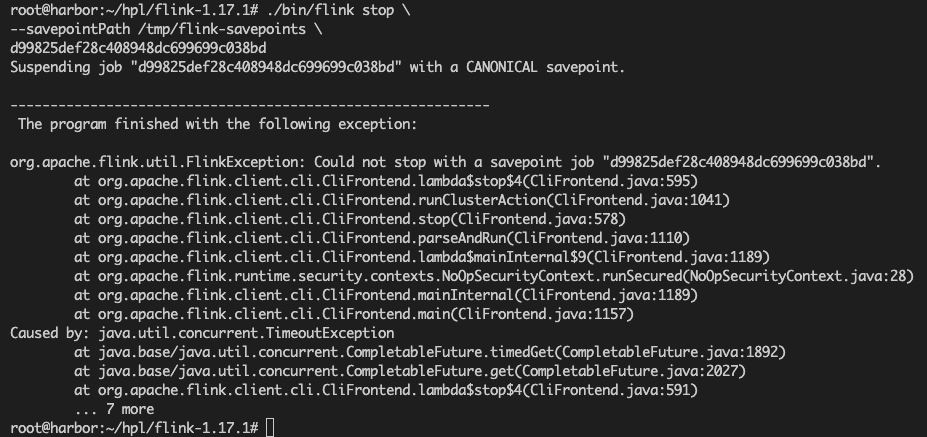
运行语句是: ./bin/flink stop --savepointPath /tmp/flink-savepoints \d99825def28c408948dc699699c038bd
参考回答:
当执行 Flink 的 stop 命令并指定 --savepointPath 参数时,如果操作超时,可能是由于不同原因导致的。以下是一些建议,你可以尝试解决该问题:
1.检查 Flink Job 是否处于正常状态:
2.确保 Flink Job 处于正常运行状态。
3.使用 Flink 的 Web UI 或者命令行工具查看作业的状态,确保它没有失败或处于异常状态。
4.确认 Savepoint 路径存在并且可用:
5.确保指定的 --savepointPath 路径存在,并且 Flink 进程有足够的权限访问该路径。
6.验证文件系统是否正常,以确保 Flink 能够正确读取和写入 Savepoints。
7.查看 Flink 日志:
8.检查 Flink 的日志,特别是 JobManager 和 TaskManager 的日志,以查看是否有任何与 Savepoint 相关的错误或警告消息。
9.Flink 的日志通常位于 log/ 目录下,可以使用 tail 或其他日志查看工具实时监控日志文件。
10.增加超时时间:
11.如果超时是因为 Savepoint 过程比较耗时,可以尝试增加 stop 命令的超时时间。例如,可以使用 --timeout 参数来指定更长的超时时间,例如 --timeout 600000(单位是毫秒)。
./bin/flink stop --savepointPath /tmp/flink-savepoints -d d99825def28c408948dc699699c038bd --timeout 600000
12.手动执行 Savepoint:
13.如果 stop 命令仍然失败,尝试手动执行 Savepoint。可以使用以下命令:
bash
./bin/flink savepoint <jobID> <savepointDirectory>
其中,<jobID> 是作业的 JobID,可以在 Flink 的 Web UI 或者日志中找到,<savepointDirectory> 是 Savepoint 保存的目录。
14.版本兼容性问题:
15.确保 Flink 的版本与执行 Savepoint 和 Stop 命令的版本兼容。有时,不同版本之间的兼容性问题可能导致异常。
如果以上方法都无法解决问题,可能需要更详细的日志信息或者进一步调查。在这种情况下,建议查阅 Flink 的官方文档、社区论坛或者向 Flink 社区寻求帮助。
关于本问题的更多回答可点击原文查看:
https://developer.aliyun.com/ask/582455
问题五:我想保存Flink savepoint,却报超时错误,应该如何处理呀?
我想保存Flink savepoint,却报超时错误,应该如何处理呀? 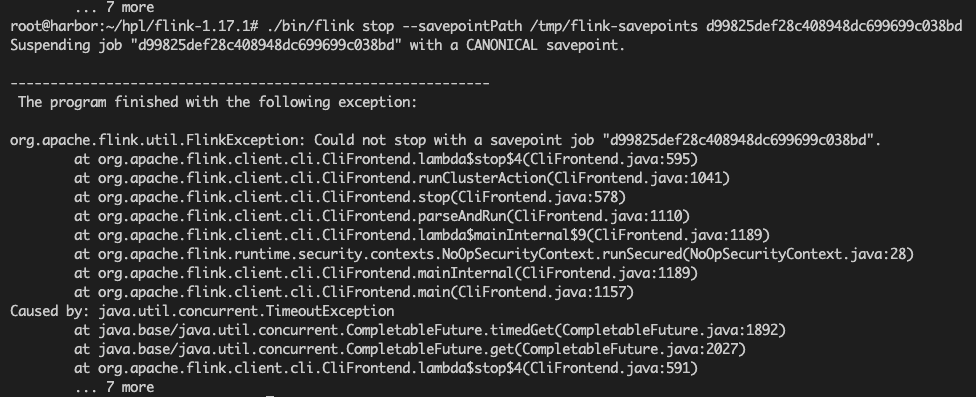
参考回答:
Flink在保存savepoint时出现超时错误,可能是由于任务执行时间过长或者网络问题导致的。你可以尝试以下方法来解决这个问题:
- 增加超时时间:在调用savepoint API时,可以通过设置
withSavepointDisposalTimeout参数来增加超时时间。例如,使用Python API时,可以这样设置:
env.enable_checkpointing(interval=60 * 1000, min_pause_between_checkpoints=60 * 1000) savepoint = env.get_checkpoint_status("your-savepoint-path", with_options=CheckpointOptions().with_savepoint_disposal_timeout(3600 * 1000))
- 优化任务性能:检查你的Flink任务,看是否有可以优化的地方,例如减少数据倾斜、优化数据源和sink的读写速度等。
- 检查网络状况:确保Flink集群的网络连接正常,没有丢包或延迟过高的情况。
- 升级Flink版本:如果问题仍然存在,可以尝试升级到最新的Flink版本,看看是否解决了问题。
- 联系社区支持:如果以上方法都无法解决问题,可以联系Apache Flink社区支持,他们会帮助你进一步排查问题。
关于本问题的更多回答可点击原文查看:

