
探索云世界




四月的计算机视觉研究涵盖多个子领域,包括扩散模型和视觉语言模型。在扩散模型中,Tango 2通过直接偏好优化改进了文本到音频生成,而Ctrl-Adapter提出了一种有效且通用的框架,用于在图像和视频扩散模型中添加多样控制。视觉语言模型的论文分析了CLIP模型在有限资源下的优化,并探讨了语言引导对低级视觉任务的鲁棒性。图像生成与编辑领域关注3D感知和高质量图像编辑,而视频理解与生成则涉及实时视频转游戏环境和文本引导的剪贴画动画。

【4月更文挑战第24天】本文介绍了如何使用Java实现基于概率的中奖率计算,涵盖权重分配法和轮盘法。通过实例代码展示了使用Java的权重分配法进行计算,并讨论了常见问题和解决办法,如概率设置错误、浮点数比较误差和随机数生成。此外,还探讨了性能优化、动态调整概率、支持多种抽奖模式以及确保公平性与监管合规的方法。最后,提到了构建一个完整的抽奖系统涉及的奖品管理、抽奖服务、用户接口、日志记录与审计等核心组件。
【4月更文挑战第24天】Go语言标准库中的`text/template`包用于动态生成HTML和文本,但不熟悉其用法可能导致错误。本文探讨了三个常见问题:1) 忽视模板执行错误,应确保正确处理错误;2) 忽视模板安全,应使用`html/template`包防止XSS攻击;3) 模板结构不合理,应合理组织模板以提高可维护性。理解并运用这些最佳实践,能提升Go语言模板编程的效率和安全性,助力构建稳健的Web应用。
【4月更文挑战第24天】Go语言的`net/http`包在HTTP客户端编程中扮演重要角色,但使用时需注意几个常见问题:1) 检查HTTP状态码以确保请求成功;2) 记得关闭响应体以防止资源泄漏;3) 设置超时限制,避免长时间等待;4) 根据需求处理重定向。理解这些细节能提升HTTP客户端编程的效率和质量。
总之,Java的设计目标之一是提供一个安全、稳定和易于开发的平台,通过禁止直接使用指针来实现这些目标。虽然指针可以提供更大的灵活性,但也带来了许多潜在的问题和安全风险。因此,Java采用了更高级的内存管理和安全性机制,以减少这些问题的发生。
【4月更文挑战第23天】Go语言的`sync/atomic`包支持原子操作,防止多线程环境中的数据竞争。包括原子整数和指针操作,以及原子标量函数。常见问题包括误用非原子操作、误解原子操作语义和忽略内存排序约束。解决方法是使用原子函数、结合其他同步原语和遵循内存约束。注意始终使用原子操作处理共享变量,理解其语义限制,并熟悉内存排序约束,以实现并发安全和高效的应用程序。
【4月更文挑战第23天】在Go语言中,使用`os/signal`包处理信号对实现程序优雅退出和响应中断至关重要。本文介绍了如何注册信号处理器、处理常见问题和错误,以及提供代码示例。常见问题包括未捕获关键信号、信号处理不当导致程序崩溃和忽略清理逻辑。解决方案包括注册信号处理器(如`SIGINT`、`SIGTERM`)、保持信号处理器简洁和执行清理逻辑。理解并正确应用这些原则能增强Go程序的健壮性和可管理性。
【4月更文挑战第23天】Go语言中的`select`语句是并发编程的关键,用于协调多个通道的读写。它会阻塞直到某个通道操作可行,执行对应的代码块。常见问题包括忘记初始化通道、死锁和忽视`default`分支。要解决这些问题,需确保通道初始化、避免死锁并添加`default`分支以处理无数据可用的情况。理解并妥善处理这些问题能帮助编写更高效、健壮的并发程序。结合使用`context.Context`和定时器等工具,可提升`select`的灵活性和可控性。
【4月更文挑战第23天】Go语言并发编程中,`sync.Mutex`和`sync.RWMutex`是保证线程安全的关键。互斥锁确保单个goroutine访问资源,而读写锁允许多个读者并发访问。常见问题包括忘记解锁、重复解锁以及混淆锁类型。使用`defer`可确保解锁,读写锁不支持直接升级或降级,需释放后再获取。根据读写模式选择合适锁以避免性能下降和竞态条件。理解并正确使用锁是编写并发安全程序的基础。
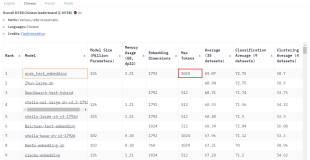
文本向量化方法包括词袋模型、TF-IDF、词嵌入和预训练模型(如BERT、GPT)。词嵌入如Word2Vec、GloVe和FastText捕捉单词语义,预训练模型则保留上下文信息。C-MTEB是中文文本嵌入评估平台,测试模型在检索、相似性、分类等任务的性能。合合信息的acge_text_embedding模型在C-MTEB中表现优秀,适用于情感分析、文本生成等任务,具有高分类聚类准确性、资源效率和场景适应性。技术突破涉及数据集优化、模型训练策略和持续学习,提供Demo展示如何使用acge模型计算句子相似度。acge_text_embedding是提升文本处理效率和智能化的有力工具。
本文介绍了如何将 Prometheus 数据接入 DataV 进行可视化展示。如果使用的是阿里云可观测监控中的 Prometheus 实例,或者自建的 Prometheus 开放了公网可访问的 HTTP API,那么可直接通过 API 将数据接入 DataV 展示。
该文介绍了时间序列分析的基本方法,以西伯利亚东南部2023年的气象数据为例,包括2米气温、总降水量、地表净太阳辐射和地表压力。首先,导入相关库如pandas、seaborn和xarray,然后展示时间序列的折线图。接着,通过statmodels库进行时间序列的分解,分析趋势、季节性和噪声。文章还讨论了数据的平稳性,使用ADF检验确认所有变量的平稳性,并通过Box-Cox变换尝试改善非正态分布。此外,还展示了自相关和部分自相关图以揭示序列的结构。这些步骤帮助理解数据特性,为后续建模做准备。
【4月更文挑战第22天】Go语言的Channels是并发通信的核心,用于Goroutines间安全高效的数据交换。本文介绍了Channels的基础知识,包括创建(无缓冲和缓冲通道)、发送与接收数据,以及如何避免常见问题。创建通道使用`make(chan T)`,发送数据用`ch <- value`,接收数据则相反。无缓冲通道需匹配的发送和接收操作,否则会阻塞。缓冲通道能暂存数据,但需注意缓冲区大小以防止死锁。关闭通道后不能发送,但能接收剩余数据,多值接收可检测通道状态。掌握这些概念和技巧,能提升Go语言并发编程的效率和稳定性。
【4月更文挑战第22天】Go语言的Goroutine是其并发模型的核心,是一种轻量级线程,能低成本创建和销毁,支持并发和并行执行。创建Goroutine使用`go`关键字,如`go sayHello("Alice")`。常见问题包括忘记使用`go`关键字、不正确处理通道同步和关闭、以及Goroutine泄漏。解决方法包括确保使用`go`启动函数、在发送完数据后关闭通道、设置Goroutine退出条件。理解并掌握这些能帮助开发者编写高效、安全的并发程序。
【4月更文挑战第22天】Go语言接口提供抽象能力,允许类型在不暴露实现细节的情况下遵循行为约定。接口定义了一组方法签名,类型实现这些方法即实现接口,无需显式声明。接口实现是隐式的,通过确保类型具有接口所需方法来实现。空接口`interface{}`接受所有类型,常用于处理任意类型值。然而,滥用空接口可能丧失类型安全性。理解接口、隐式实现和空接口的使用能帮助编写更健壮的代码。正确使用避免方法,如确保方法签名匹配、检查接口实现和谨慎处理空接口,是关键。
【4月更文挑战第22天】Go语言无类和继承,但通过方法与接收者实现OOP。方法是带有接收者的特殊函数,接收者决定方法可作用于哪些类型。值接收者不会改变原始值,指针接收者则会。每个类型有相关方法集,满足接口所有方法即实现该接口。理解并正确使用这些概念能避免常见问题,写出高效代码。Go的OOP机制虽不同于传统,但具有灵活性和实用性。
【4月更文挑战第22天】Go语言中的结构体是构建复杂数据类型的关键,允许组合多种字段。本文探讨了结构体定义、使用及常见问题。结构体定义如`type Person struct { Name string; Age int; Address Address }`。问题包括未初始化字段的默认值、比较含不可比较字段的结构体以及嵌入结构体字段重名。避免方法包括初始化结构体、自定义比较逻辑和使用明确字段选择器。结构体方法、指针接收者和匿名字段嵌入提供了灵活性。理解这些问题和解决策略能提升Go语言编程的效率和代码质量。
【4月更文挑战第22天】Go语言结构体标签用于添加元信息,常用于JSON序列化和ORM框架。本文聚焦JSON序列化和反射应用,讨论了如何使用`json`标签处理敏感字段、实现`omitempty`、自定义字段名和嵌套结构体。同时,通过反射访问标签信息,但应注意反射可能带来的性能问题。正确使用结构体标签能提升代码质量和安全性。

本⽂整理⾃阿里云智能集团技术专家王柳焮⽼师在 Flink Forward Asia 2023 中平台建设专场的分享。
该文探讨了向量数据库在语义搜索和RAG中的核心作用,并介绍了四个开源向量数据库:Chroma、Milvus、Faiss和Weaviate。这些数据库用于存储高维向量,支持基于相似性的快速搜索,改变了传统的精确匹配方法。文章详细比较了它们的特性,如Chroma的易用性,Milvus的存储效率,Faiss的GPU加速,和Weaviate的图数据模型。选择合适的数据库取决于具体需求,如数据类型、性能和使用场景。

构建Twitter图像下载器,使用PHP模拟请求抓取图像,通过代理IP规避限制。示例代码展示如何设置代理、用户代理和Cookie,解析HTML提取图像链接并下载。结合机器学习与元数据分析,可洞察用户行为和社会趋势。代理服务器信息及Twitter URL需自行替换。
在 Elasticsearch 中,要查看索引的属性,可以通过发送 HTTP 请求来执行以下操作: 1. **获取索引的映射(Mapping)**: 可以使用 `GET` 请求访问 Elasticsearch 的 `_mapping` 端点来获取特定索引的映射信息。 示例请求: ```http GET http://<elasticsearch_host>:<port>/<index_name>/_mapping ``` 2. **获取索引的设置(Settings)**: 可以使用 `GET` 请求访问 Elasticsearch 的 `_setting
Go语言中的`defer`、`panic`和`recover`提供了一套独特的异常处理方式。`defer`用于延迟函数调用,在返回前执行,常用于资源释放。它遵循后进先出原则。`panic`触发运行时错误,中断函数执行,直到遇到`recover`或程序结束。`recover`在`defer`中捕获`panic`,恢复程序执行。注意避免滥用`defer`影响性能,不应对可处理错误随意使用`panic`,且`recover`不能跨goroutine捕获panic。理解并恰当使用这些机制能提高代码健壮性和稳定性。
【4月更文挑战第21天】Go语言中的指针允许直接操作内存,常用于高效数据共享和传递。本文介绍了指针的基础知识,如声明、初始化和解引用,以及作为函数参数使用。此外,讨论了`new()`与`make()`的区别和内存逃逸分析。在结构体上下文中,指针用于减少复制开销和直接修改对象。理解指针与内存管理、结构体的关系及常见易错点,对于面试和编写高性能Go代码至关重要。

【4月更文挑战第21天】Go语言函数是代码组织的基本单元,用于封装可重用逻辑。本文介绍了函数定义(包括基本形式、命名、参数列表和多返回值)、调用以及匿名函数与闭包。在函数定义时,注意参数命名和注释,避免参数顺序混淆。在调用时,要检查并处理多返回值中的错误。理解闭包原理,小心处理外部变量引用,以提升代码质量和可维护性。通过实践和示例,能更好地掌握Go语言函数。

【4月更文挑战第21天】Go语言中的`map`提供快速的键值对操作,包括初始化、增删查改和遍历。初始化时,推荐使用`make()`函数,如`make(map[string]int)`。插入和查询键值对直接通过索引访问,更新则重新赋值。删除键值对需用`delete()`函数,确保键存在。遍历map常用`for range`,注意避免在遍历中修改map。了解这些并避免易错点,能提升代码效率和可读性。

大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。





