
近日,阿里云机器学习平台PAI与华东师范大学高明教授团队合作在自然语言处理顶级会议EMNLP2022上发表基于Prompt-Tuning的小样本机器阅读理解算法KECP(Knowledge Enhanced Contrastive Prompt-tuning)。KECP是一种面向机器阅读理解的小样本学习算法,采用Prompt-Tuning作为基础学习范式,在仅需要标注极少训练数据的情况下,在给定文章中抽取满足要求的文本作为答案。
论文:
Jianing Wang*, Chengyu Wang*, Minghui Qiu, Qiuhui Shi, Hongbin Wang, Jun Huang, Ming Gao. KECP: Knowledge-Enhanced Contrastive Prompting for Few-shot Extractive Question Answering. EMNLP 2022
背景
在预训练语言模型广泛应用的背景下,传统的机器阅读理解(Machine Reading Comprehension)任务通常需要大量的标注数据来微调模型(例如BERT)。机器阅读理解任务旨在给定一篇文章(Passage)和一个问题(Question),从文章中寻找对应问题的答案(Answer)。通常情况下,我们假设答案来自于文章中的子片段,这一任务可以进一步被称为抽取式阅读理解,或抽取式问答(Extractive Question Answering)。这一任务在大量深度学习应用中有广泛的应用场景,例如任务型对话系统等。
传统的抽取式问答采用序列标注或指针网络的方法,获得答案在给定文章的区间,其学习范式如下图(a)所示:
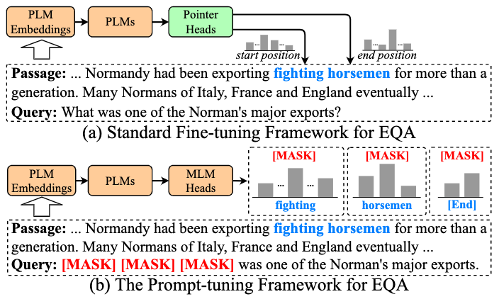
然而,这种方法需要重头开始学习Preduction Head的参数,在小样本场景下容易过拟合。最近Prompt-Tuning(即提示微调)相关方法的提出缓解了预训练语言模型在低资源场景下的过拟合问题。特别地,对于BERT类模型,其通常是将下游任务目标转换为预训练目标(例如Masked Language Modeling),以充分复用预训练阶段的先验知识。受到这个启发,我们将抽取式阅读理解转换为基于BERT的生成任务,如上图(b)。
算法概述
我们提出的KECP(Knowledge Enhanced Contrastive Prompt-tuning)模型综合利用了模型表示的知识增强和对比学习技术,提升了小样本学习场景下的机器阅读理解准确度,模型架构图如下:

模型输入
首先,我们将问题(Question)转换为陈述句,并通过一些启发式规则将问题变为类似完形填空任务。例如,我们可以将问题:
What was one of the Normans’major exports?
变为:
[MASK] [MASK] [MASK] was one of the Normans’major exports.
其中[MASK]为待预测的Token。最后,我们将这一陈述句和文章进行拼接在一起,形成统一的输入序列:
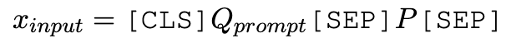
知识增强的语义表达
因为训练样本很少时,模型的推理能力有限;因此,我们提出了知识注入方法,即给定一个知识库(例如Wikidata5M),我们使用实体链指工具识别出文章(Passage)中所有实体。在KECP算法中,我们提出了Passage Knowledge Injection模块,将预训练知识库实体表征与Word Embedding表征向量通过门控单元进行向量融合:

为了避免注入过多知识引起知识噪音(Knowledge Noise)问题,我们将融合了知识的文章表征信息聚集到问题部分挑选的Token中。例如,在前述示例中,我们挑选了名词“Norman Major Exports”,我们可以通过Self-Attention模型将文章中的实体融合向量进一步融合到这些选定的Token中:
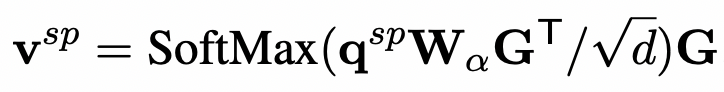
这样,我们能获得更好的文本表征。
对比学习增强的模型训练
在获得新的表征向量后,我们将这些表征喂入BERT模型中,进行模型的训练。我们复用了预训练任务目标Masked Language Modeling(MLM)。为了提高模型效果,我们采用对比学习对学习目标进行增强。在KECP的对比学习模块中,正样本为Ground Truth,负样本为通过知识库检索到文章中的一些错误的实体(这些实体可能会对模型预测产生混淆),损失函数如下:
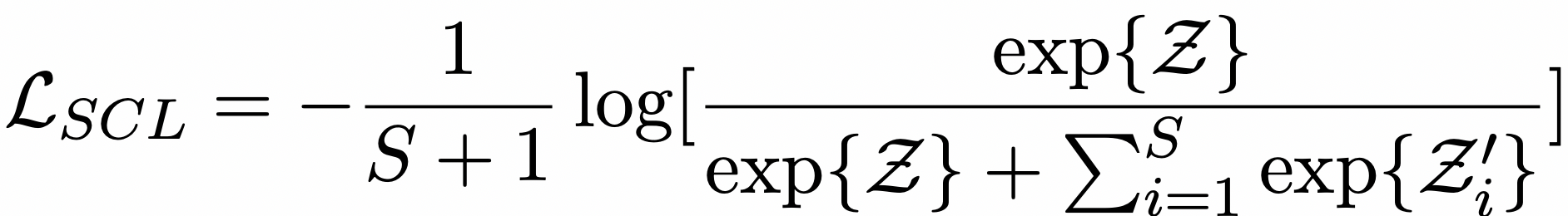
KECP协同最小化MLM和对比学习损失,得到最终的机器阅读理解模型。
算法精度评测
为了评测KECP算法的精度,我们在一些常用的机器阅读理解数据集上,随机采样16个样本进行训练,结果如下:

结果可以证明,KECP在这些数据集上获得不错的效果。在未来,我们会拓展KECP到到BART、T5等生成式模型上,训练更加通用的生成式阅读理解模型。为了更好地服务开源社区,KECP算法的源代码即将贡献在自然语言处理算法框架EasyNLP中,欢迎NLP从业人员和研究者使用。
EasyNLP开源框架:https://github.com/alibaba/EasyNLP
参考文献
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Xiang Lisa Li, Percy Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation. ACL/IJCNLP 2021: 4582-4597
- Ori Ram, Yuval Kirstain, Jonathan Berant, Amir Globerson, Omer Levy. Few-Shot Question Answering by Pretraining Span Selection. ACL/IJCNLP 2021: 3066-3079
- Rakesh Chada, Pradeep Natarajan. FewshotQA: A simple framework for few-shot learning of question answering tasks using pre-trained text-to-text models. EMNLP 2021: 6081-6090
- Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, Omer Levy. SpanBERT: Improving Pre-training by Representing and Predicting Spans. Trans. Assoc. Comput. Linguistics 8: 64-77 (2020)
- Xiao Liu, Kaixuan Ji, Yicheng Fu, Zhengxiao Du, Zhilin Yang, Jie Tang. P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks. CoRR abs/2110.07602 (2021)
论文信息
论文名字:KECP: Knowledge-Enhanced Contrastive Prompting for Few-shot Extractive Question Answering
论文作者:王嘉宁、汪诚愚、邱明辉、石秋慧、王洪彬、黄俊、高明
论文pdf链接:https://arxiv.org/abs/2205.03071
