









免费高效!3步实现Llama3模型远程访问与协作
Meta发布了全新的开源大语言模型Llama 3,LM Studio是一款免费的桌面端工具,支持一键安装和运行Llama 3模型,实现本地使用。LM Studio还提供了Local Server功能,便于集成AI功能。通过贝锐花生壳,可轻松实现LM Studio接口的远程访问,无需公网IP或端口映射。

官宣|Apache Flink 1.20 发布公告
Apache Flink 1.20.0 已发布,这是迈向 Flink 2.0 的最后一个小版本,后者预计年底发布。此版本包含多项改进和新功能,涉及 13 个 FLIPs 和 300 多个问题解决。亮点包括引入物化表简化 ETL 管道开发,统一检查点文件合并机制减轻文件系统压力,以及 SQL 语法增强如支持 `DISTRIBUTED BY` 语句。此外,还进行了大量的配置项清理工作,为 Flink 2.0 铺平道路。这一版本得益于 142 位贡献者的共同努力,其中包括来自中国多家知名企业的开发者。
Python基于RFM模型和K-Means聚类算法进行航空公司客户价值分析
Python基于RFM模型和K-Means聚类算法进行航空公司客户价值分析

「Python入门」python环境搭建及VScode使用python运行方式
**Python 概述与环境搭建摘要** Python是一种解释型、面向对象、交互式的脚本语言,以其简单易学和丰富库著称。安装Python时,推荐在Windows上选择.exe安装程序,记得勾选“Add Python to PATH”。安装完成后,通过环境变量配置确保Python可被系统识别。验证安装成功,可在CMD中输入`python --version`。Visual Studio Code (VScode)是流行的Python IDE,安装Python插件并选择解释器后,可直接在VScode内编写和运行Python代码。

「Python大数据」LDA主题分析模型
使用Python进行文本聚类,流程包括读取VOC数据、jieba分词、去除停用词,应用LDA模型(n_components=5)进行主题分析,并通过pyLDAvis生成可视化HTML。关键代码涉及数据预处理、CountVectorizer、LatentDirichletAllocation以及HTML文件的本地化处理。停用词和业务术语列表用于优化分词效果。
ClickHouse(16)ClickHouse日志表引擎Log详细解析
ClickHouse的Log引擎系列适用于小数据量(<1M行)的表,包括StripeLog、Log和TinyLog。这些引擎将数据存储在磁盘,追加写入,不支持更新和索引,写入非原子可能导致数据损坏。Log和StripeLog支持并发访问和并行读取,Log按列存储,StripeLog将所有数据存于一个文件。TinyLog是最简单的,不支持并行读取和并发访问,每列存储在单独文件中。适用于一次性写入、多次读取的场景。
免费泛域名申请以及无限续期
在Ubuntu 20.04上,使用certbot和snapd安装Let's Encrypt证书以实现免费泛域名(如`*.example.com`)的无限续期。首先安装snapd,然后卸载并安装certbot,创建certbot软连接。设置trust-plugin-with-root,安装certbot-dns-cloudflare插件,配置Cloudflare API token。通过certbot certonly命令获取证书,包括子域名,并设置自动续期。将证书导入nginx并验证。最后,创建post-renewal hook以在续期后自动重启nginx。
Hadoop Yarn 配置多队列的容量调度器
配置Hadoop多队列容量调度器,编辑`capacity-scheduler.xml`,新增`hive`队列,`default`队列占总内存40%,最大60%;`hive`队列占60%,最大80%。配置包括队列容量、用户权限和应用生存时间等,配置后使用`yarn rmadmin -refreshQueues`刷新队列,无需重启集群。多队列配置可在Yarn WEB界面查看。
实时计算 Flink版操作报错合集之报错io.debezium.DebeziumException: The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot. 是什么原因
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。

【一文解读】阿里自研开源核心搜索引擎 Havenask简介及发展历史
本次分享内容为Havenask的简介及发展历史,由下面五个部分组成(Havenask整体介绍、名词解释、架构、代码结构、编译与部署),希望可以帮助大家更好了解和使用Havenask。
基于 NVIDIA Megatron-Core 的 MoE LLM 实现和训练优化
本文将分享阿里云人工智能平台 PAI 团队与 NVIDIA Megatron-Core 团队在 MoE (Mixture of Experts) 大型语言模型(LLM)实现与训练优化上的创新工作。
flink cdc 同步问题之如何同步多张库表
Flink CDC(Change Data Capture)是一个基于Apache Flink的实时数据变更捕获库,用于实现数据库的实时同步和变更流的处理;在本汇总中,我们组织了关于Flink CDC产品在实践中用户经常提出的问题及其解答,目的是辅助用户更好地理解和应用这一技术,优化实时数据处理流程。
阿里云OpenSearch RAG混合检索Embedding模型荣获C-MTEB榜单第一
阿里云OpenSearch引擎通过Dense和Sparse混合检索技术,在中文Embedding模型C-MTEB榜单上拿到第一名,超越Baichuan和众多开源模型,尤其在Retrieval任务上大幅提升。
Python进行AI声音克隆的端到端指南
人工智能语音克隆是一种捕捉声音的独特特征,然后准确性复制它的技术。这种技术不仅可以让我们复制现有的声音,还可以创造全新的声音。它是一种彻底改变内容创作的工具,从个性化歌曲到自定义画外音,开辟了一个超越语言和文化障碍的创意世界。
【云栖2023】张治国:MaxCompute架构升级及开放性解读
本文根据2023云栖大会演讲实录整理而成,演讲信息如下 演讲人:张治国|阿里云智能计算平台研究员、阿里云MaxCompute负责人 演讲主题:MaxCompute架构升级及开放性解读 活动:2023云栖大会
MaxCompute元数据使用实践--作业统计
通过MaxCompute租户级别Information Schema的“TASKS_HISTORY”视图可以统计查看MaxCompute计算作业的元数据信息,方便您进行作业审计以及各类统计,指导作业性能、成本优化。
数据管理能力成熟度模型
为促进大数据产业持续深入发展,提高政府、企事业单位大数据资产管理意识,借鉴国内外成熟度相关理论思想,结合数据生命周期管理各个阶段的特征,对数据管理能力进行了分析、总结,提炼出组织数据管理的八大过程域,并对每项能力进行了二级过程域和发展等级的划分以及相关功能介绍和评定标准的制定。
2023年13个面向初学者最佳免费3D建模软件
现在有数百种不同的免费 3D 建模软件工具供希望创建自己的 3D 模型的用户使用——因此知道从哪里开始可能会很棘手。 3D 软件建模工具的范围从即使是最新的初学者也易于使用到可能需要数年才能学习的专业级软件——因此选择与您的技能水平相匹配的工具非常重要。

nginx在云平台服务几个典型代理场景中的应用案例
在云平台服务中有多种场景需要使用到反向代理,常见的应用场景包括:内网专有云平台访问公网资源、公有云平台访问客户内网IDC机房资源、云产品通过代理访问多个不同的资源等等。笔者总结几种场景配置nginx的7层反向代理、4层反向代理,巧妙实现应用需求。

猿辅导基于 EMR StarRocks 的 OLAP 演进之路
猿辅导大数据平台团队负责人申阳分享了猿辅导基于EMR StarRocks 的 OLAP 演进之路。

【DSW Gallery】介绍如何使用SDK提交DLC训练任务
您可以通过Python SDK的方式提交PAI-DLC任务,本文介绍如何通过Python SDK提交使用公共DLC资源组或专有DLC资源组的训练任务,核心步骤包括下载Python SDK、安装Python SDK及创建并提交任务。

外部工具连接SaaS模式云数仓MaxCompute 实战—— 数据库管理工具篇
本次直播将主要分享MaxCompute查询加速功能、数据库管理工具DBeaver、DataGrip、SQL Workbench/J的部分连接演示。
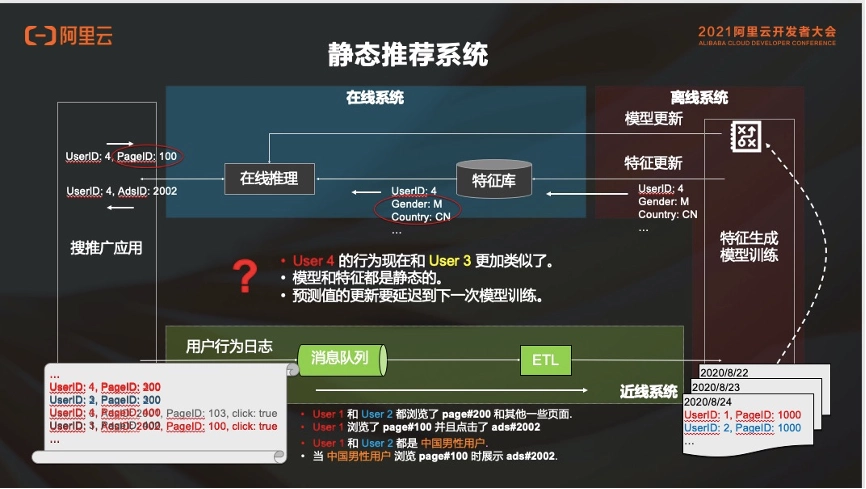
基于实时深度学习的推荐系统架构设计和技术演进
整理自 5 月 29 日 阿里云开发者大会,秦江杰和刘童璇的分享,内容包括实时推荐系统的原理以及什么是实时推荐系统、整体系统的架构及如何在阿里云上面实现,以及关于深度学习的细节介绍

持续定义SaaS模式云数据仓库+AI
本文由阿里云计算平台事业部 MaxCompute 产品经理孟硕为大家带来《持续定义SaaS模式云数据仓库+AI》的相关分享。

数据湖 VS 数据仓库之争?阿里提出大数据架构新概念:湖仓一体
随着近几年数据湖概念的兴起,业界对于数据仓库和数据湖的对比甚至争论就一直不断。有人说数据湖是下一代大数据平台,各大云厂商也在纷纷的提出自己的数据湖解决方案,一些云数仓产品也增加了和数据湖联动的特性。但是数据仓库和数据湖的区别到底是什么,是技术路线之争?是数据管理方式之争?二者是水火不容还是其实可以和谐共存,甚至互为补充?本文作者来自阿里巴巴计算平台部门,深度参与阿里巴巴大数据/数据中台领域建设,将从历史的角度对数据湖和数据仓库的来龙去脉进行深入剖析,来阐述两者融合演进的新方向——湖仓一体,并就基于阿里云MaxCompute/EMR DataLake的湖仓一体方案做一介绍。

大神都这么做,让 Kibana 搜索语法 query string 也能轻松上手
kibana 的搜索框默认选择了 query string 的搜索语法,虽然简洁却不简单,本文来帮大家如何轻松上手;

Demo 示例:如何原生的在 K8s 上运行 Flink?
Kubernetes 相信大家都比较熟悉,近两年大家都在讨论云原生的话题,讨论 Kubernetes。本文由阿里巴巴技术专家王阳(亦祺)分享,社区志愿者翟玥整理主要介绍如何原生的在 Kubernetes 上运行 Flink。
【X-Pack解读】阿里云Elasticsearch X-Pack 机器学习组件功能详解
阿里云Elasticsearch集成了Elastic Stack商业版的X-Pack组件包,包括安全、告警、监控、报表生成、图分析、机器学习等组件,用户可以开箱即用。本文将对X-Pack 的机器学习功能进行详细解读。
阿里云大数据利器Maxcompute-使用mapjoin优化查询
small is beautiful,small is powerful
国内电商平台商品详情API返回数据Python模型格式
本接口服务支持淘宝、京东、1688三大平台商品详情数据获取,返回标准化Python字典,涵盖标题、价格、库存、图片、SKU、规格、评价等核心字段,含OAuth2.0/签名认证、调用示例及统一解析函数,助力电商数据高效对接。
告别传统Prompt写法!聚AI提示词工程新范式
本章系统讲解Python提示词工程实战,涵盖专业环境搭建、API调用与结构化响应、企业级模板引擎及多步骤对话管理,并延伸至Prompt迭代优化、外部工具集成与性能监控,助力构建工业级AI应用系统。(239字)
天猫商品详情API数据解析
天猫商品详情API解析方案,涵盖taobao/tmall.item.get接口字段说明、JSON结构、解析代码及SKU/详情图/规格提取。支持价格库存、竞品监测、舆情预警等场景,AI智能清洗、卖点解析与爆款预测,助力中小卖家高效用数。(239字)
基于Flutter3.41+Dart3.11+DeepSeek生成式AI对话应用App助手
Flutter3.41+Dart3+Dio+Getx+Markdown聚合DeepSeek-chat实战AI流式打字智能会话模板。新增深度思考模式、latex公式、mermaid图表,代码高亮/复制代码、图片预览、链接、表格等功能。
PAI-Rec 召回引擎:构建高性能推荐系统的核心引擎
PAI-Rec是阿里云智能推荐平台的核心召回引擎,经阿里大规模场景验证。支持多路召回融合(U2I/I2I/向量/随机)、召回即过滤、毫秒级实时更新与分布式弹性架构,开箱即用,助力企业构建毫秒级、高精度、强实时的推荐系统。
1949AI轻量化AI自动化:有头浏览器自动化竞品词排名监控与邮件提醒实践
1949AI轻量化AI自动化工具,基于Playwright实现有头浏览器本地监控:可视化调试、低资源占用、安全合规。支持关键词排名追踪、波动预警与邮件提醒,单文件部署、零外部依赖,专为个人开发者与小型团队打造。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
