









VQ-VAE:矢量量化变分自编码器,离散化特征学习模型
VQ-VAE 是变分自编码器(VAE)的一种改进。这些模型可以用来学习有效的表示。本文将深入研究 VQ-VAE 之前,不过,在这之前我们先讨论一些概率基础和 VAE 架构。

X Detector:最值得信赖的多语言 AI 内容检测器
**X Detector** 提供直观界面和高效AI文本检测。支持20种语言,无需登录即可免费使用。高准确率、快速响应,几秒内显示结果。适合多语言内容筛查。尝试[AI Detector](https://xdetector.ai/),轻松检测AI生成文本。

EMR Serverless Spark 实践教程 | 通过 spark-submit 命令行工具提交 Spark 任务
本文以 ECS 连接 EMR Serverless Spark 为例,介绍如何通过 EMR Serverless spark-submit 命令行工具进行 Spark 任务开发。
Transformer中高级位置编码的介绍和比较:Linear Rope、NTK、YaRN、CoPE
在NLP中,位置编码如RoPE、CoPE等增强模型对序列顺序的理解。RoPE通过旋转矩阵编码位置,适应不同距离的相对位置。线性旋转、NTK和YaRN是RoPE的变体,优化长序列处理。CoPE是动态的,根据序列内容调整位置编码,改善长距离依赖的捕捉。这些技术提升了模型在处理复杂语言任务时的性能。
《经典图论算法》迪杰斯特拉算法(Dijkstra)
这个是求最短路径的迪杰斯特拉算法,另外我还写了50多种《经典图论算法》,每种都使用C++和Java两种语言实现,熟练掌握之后无论是参加蓝桥杯,信奥赛,还是其他比赛,或者是面试,都能轻松应对。
Python实现多元线性回归模型(statsmodels OLS算法)项目实战
Python实现多元线性回归模型(statsmodels OLS算法)项目实战
大数据&AI产品月刊【2024年6月】
大数据&AI产品技术月刊【2024年6月】,涵盖本月技术速递、产品和功能发布、市场和客户应用实践等内容,帮助您快速了解阿里云大数据&AI方面最新动态。
LLM推理引擎怎么选?TensorRT vs vLLM vs LMDeploy vs MLC-LLM
有很多个框架和包可以优化LLM推理和服务,所以在本文中我将整理一些常用的推理引擎并进行比较。
ClickHouse(16)ClickHouse日志表引擎Log详细解析
ClickHouse的Log引擎系列适用于小数据量(<1M行)的表,包括StripeLog、Log和TinyLog。这些引擎将数据存储在磁盘,追加写入,不支持更新和索引,写入非原子可能导致数据损坏。Log和StripeLog支持并发访问和并行读取,Log按列存储,StripeLog将所有数据存于一个文件。TinyLog是最简单的,不支持并行读取和并发访问,每列存储在单独文件中。适用于一次性写入、多次读取的场景。

Hadoop Yarn 配置多队列的容量调度器
配置Hadoop多队列容量调度器,编辑`capacity-scheduler.xml`,新增`hive`队列,`default`队列占总内存40%,最大60%;`hive`队列占60%,最大80%。配置包括队列容量、用户权限和应用生存时间等,配置后使用`yarn rmadmin -refreshQueues`刷新队列,无需重启集群。多队列配置可在Yarn WEB界面查看。
Hive 解析 JSON 字符串数据的实现方式
Hive 提供 `get_json_object` 函数解析 JSON 字符串,如 `{"database":"maxwell"}`。`path` 参数使用 `$`、`.`、`[]` 和 `*` 来提取数据。示例中展示了如何解析复杂 JSON 并存储到表中。此外,Hive 3.0.0及以上版本内置 `JsonSerDe` 支持直接处理 JSON 文件,无需手动解析。创建表时指定 `JsonSerDe` 序列化器,并在 HDFS 上存放 JSON 文件,可以直接查询字段内容,方便快捷。
ClickHouse 如何实现数据一致性
本文探讨了在 ClickHouse 中实现数据一致性的方法,主要关注 `ReplacingMergeTree` 引擎。该引擎允许更新已有数据,通过定期合并操作删除重复并保持最终一致性。然而,由于合并时间不可预测,单纯依赖此引擎无法确保实时一致性。为解决此问题,文章提出了四种策略:1)手动触发合并,但不建议频繁使用;2)使用 `FINAL` 查询,但在查询时合并数据,效率较低;3)通过标记和 `GroupBy` 查询实现一致性;4)在允许一定偏差的情况下,直接使用 `ReplacingMergeTree` 保持最终一致性。在实践中,推荐结合标记列和 `GroupBy` 以保证数据一致性。
案例:批量区域识别内容重命名,批量识别扫描PDF区域内容识别重命名,批量识别图片区域内容重命名图片修改图片名字,批量识别图片区域文字并重命名,批量图片部分识别内容重命文件,PDF区域内容提取重命名
该内容介绍了如何使用区域识别重命名软件高效整理图片,例如将图片按时间及内容重命名,适用于简历、单据等识别。文中提供了软件下载链接(百度云盘和腾讯网盘),并列出软件使用的几个关键条件,包括文字清晰、文件名长度限制等。示例展示了银行单据和公司工作单据的识别情况。文章还提及OCR技术在图片文字识别中的应用,强调了识别率、误识率和用户友好性等评估指标。如有类似需求,读者可留言或下载软件测试,并提供图片以获取定制的识别方案。
Java一分钟之——Java模块系统:模块化开发(Jigsaw)
【5月更文挑战第20天】Java 9引入了Jigsaw模块系统,改善代码组织和依赖管理。模块通过`module-info.java`定义,声明名称、导出包及依赖。常见问题包括依赖循环、未声明依赖和过度导出。避免这些问题的策略包括明确声明依赖、谨慎导出包和避免循环依赖。通过实例展示了模块间的关系,强调理解模块系统对于构建整洁、安全和可维护的Java应用的重要性。

Golang深入浅出之-Go语言函数基础:定义、调用与多返回值
【4月更文挑战第21天】Go语言函数是代码组织的基本单元,用于封装可重用逻辑。本文介绍了函数定义(包括基本形式、命名、参数列表和多返回值)、调用以及匿名函数与闭包。在函数定义时,注意参数命名和注释,避免参数顺序混淆。在调用时,要检查并处理多返回值中的错误。理解闭包原理,小心处理外部变量引用,以提升代码质量和可维护性。通过实践和示例,能更好地掌握Go语言函数。
大数据隐私保护策略:加密、脱敏与访问控制实践
【4月更文挑战第9天】本文探讨了大数据隐私保护的三大策略:数据加密、数据脱敏和访问控制。数据加密通过加密技术保护静态和传输中的数据,密钥管理确保密钥安全;数据脱敏通过替换、遮蔽和泛化方法降低敏感信息的敏感度;访问控制则通过用户身份验证和权限设置限制数据访问。示例代码展示了数据库、文件系统和API访问控制的实施方式,强调了在实际应用中需结合业务场景和平台特性定制部署。
eBPF动手实践系列三:基于原生libbpf库的eBPF编程改进方案
为了简化 eBPF程序的开发流程,降低开发者在使用 libbpf 库时的入门难度,libbpf-bootstrap 框架应运而生。本文详细介绍基于原生libbpf库的eBPF编程改进方案。

Flink 在蚂蚁实时特征平台的深度应用
本文整理自蚂蚁集团高级技术专家赵亮星云,在 Flink Forward Asia 2023 AI 特征工程专场的分享。
阿里云PAI大模型RAG对话系统最佳实践
本文为大模型RAG对话系统最佳实践,旨在指引AI开发人员如何有效地结合LLM大语言模型的推理能力和外部知识库检索增强技术,从而显著提升对话系统的性能,使其能更加灵活地返回用户查询的内容。适用于问答、摘要生成和其他依赖外部知识的自然语言处理任务。通过该实践,您可以掌握构建一个大模型RAG对话系统的完整开发链路。
大麦网 API 接口商品详情信息 API
为了让更多用户了解到大麦网的商品详情,并能够方便地获取相关信息,大麦网推出了商品详情 API 接口。本文将介绍大麦网商品详情 API 接口的作用、使用方法和注意事项,帮助广大开发者更加方便地接入大麦网的产品。
浅谈RISC-V指令集的基本指令格式和立即数操作
在以前的文章中,我分享了RISC-V在设计的初衷,除了可以被通用软件开发使用之外,还有一个目的就是,可以支持更多定制化的设计。也就是说,用户可以在基本指令集上面,进行一个或者多个的指令集扩展操作,但是有一个条件,不能再重新定义基本指令集。也就是说,任何一款基于RISC-V指令集的处理器,都要能够支撑整数基本指令集。可以看出基本指令集的重要性。

铅华洗尽,粉黛不施,人工智能AI基于ProPainter技术去除图片以及视频水印(Python3.10)
视频以及图片修复技术是一项具有挑战性的AI视觉任务,它涉及在视频或者图片序列中填补缺失或损坏的区域,同时保持空间和时间的连贯性。该技术在视频补全、对象移除、视频恢复等领域有广泛应用。近年来,两种突出的方案在视频修复中崭露头角:flow-based propagation和spatiotemporal Transformers。尽管两套方案都还不错,但它们也存在一些局限性,如空间错位、时间范围有限和过高的成本。 说白了,你通过AI技术移除水印或者修复一段不清晰的视频,但结果却没法保证连贯性,让人一眼能看出来这个视频或者图片还是缺失状态,与此同时,过高的算力成本也是普通人难以承受的。
数据管理能力成熟度模型
为促进大数据产业持续深入发展,提高政府、企事业单位大数据资产管理意识,借鉴国内外成熟度相关理论思想,结合数据生命周期管理各个阶段的特征,对数据管理能力进行了分析、总结,提炼出组织数据管理的八大过程域,并对每项能力进行了二级过程域和发展等级的划分以及相关功能介绍和评定标准的制定。
2023年19款最佳3D打印软件
3D打印软件程序是高质量打印,设计和监控的关键 - 没有软件,3D打印机只是没有方向的机器。3D 打印机软件采用各种不同的形式:用于设计 3D 模型的 3D 软件建模工具、用于切片 STL 文件以进行打印的 3D 切片器,以及用于修复模型中错误的专业软件。 为了让您更轻松,我们将每种类型的3D打印机软件分成几个部分。在每个部分中,我们都有免费的3D打印软件选项,以及高级付费选项。
IM开发者的零基础通信技术入门(十二):上网卡顿?网络掉线?一文即懂!
本文将详细介绍生活中遇到的常见网络问题,及可能的解决方法,虽说是一篇技术文章,但内容将一如既往地通俗易懂,简单实用。



MaxCompute湖仓一体介绍
本篇内容分享了MaxCompute湖仓一体介绍。 分享人:孟硕 阿里云 MaxCompute产品专家

Apache Flink CDC 批流融合技术原理分析
以 Flink SQL 案例来介绍 Flink CDC 2.0 的使用,并解读 CDC 中的核心设计。
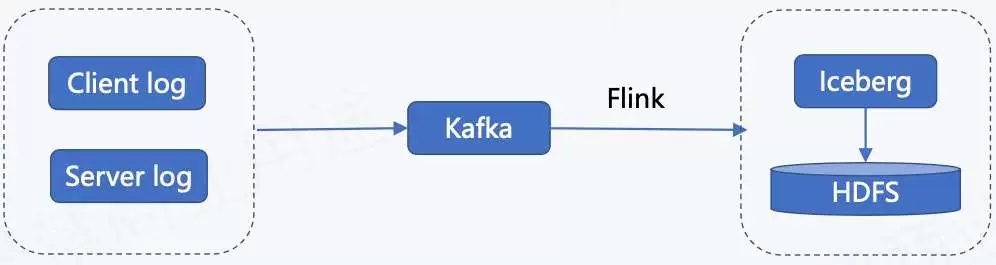
汽车之家:基于 Flink + Iceberg 的湖仓一体架构实践
由汽车之家实时计算平台负责人邸星星在 4 月 17 日上海站 Meetup 分享的,基于 Flink + Iceberg 的湖仓一体架构实践。
UDF精简使用大全
在MaxCompute开发过程中,开发同学遇到的的一些复杂逻辑该如何处理,如何在MaxCompute开发不同场景下的UDF函数?带着这个问题,本文针对UDF的各方面内容做出介绍,其中涉及UDF对应不同语言的类型映射关系、以及对应UDF在重载、访问网络、引用表与资源、以及第三方包的使用为大家做出展示。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
