

技术分享:
- 王绍翾(大沙) 阿里达摩院机器智能实验室 资深技术专家
- 肖允锋(鹤冲) 阿里达摩院机器智能实验室 资深技术专家
阿里云搜索推荐产品:
- 开放搜索(OpenSearch):https://www.aliyun.com/product/opensearch
- 智能推荐(AIRec):https://www.aliyun.com/product/bigdata/airec
人工智能,简称 AI,是计算机发明时就存在的一个技术领域。它的一大核心特点就是可以类人脑地辅助人类工作。其通过一系列数学的方法,如概率论、统计、线性代数等,分析和设计出能让计算机自动学习的算法。
如下图所示,人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。这些向量如同数学空间中的坐标,标识着各个实体和实体关系。我们一般将非结构化数据变成向量的过程称为 Embedding,而非结构化检索则是对这些生成的向量进行检索,从而找到相应实体的过程。

非结构化检索本质是向量检索技术,其主要的应用领域如人脸识别、推荐系统、图片搜索、视频指纹、语音处理、自然语言处理、文件搜索等。随着 AI 技术的广泛应用,以及数据规模的不断增长,向量检索也逐渐成了 AI 技术链路中不可或缺的一环,更是对传统搜索技术的补充,并且具备多模态搜索的能力。
1. 业务场景
1.1 语音/图像/视频检索
向量检索的第一大类应用就是对语音、图像、视频这些人类所接触到的,也最为常见的非结构化数据的检索。传统的检索引擎只是对这些多媒体的名称和描述进行了索引,而并没有尝试对这些非结构数据的内容进行理解和建立索引,因此传统引擎的检索结果具有非常大的局限性。
随着人工智能的发展,AI 的能力使得我们可以快速且成本较低地对这些非结构化数据进行理解,这样就使得对这些非结构化的数据内容进行直接检索成为了可能。这其中,很重要的一环就是向量检索。
如下图所示,以图片搜索为例,我们先以离线的方式对所有历史图片进行机器学习分析,将每一幅图片(或者图片里分割出来的人物)抽象成高维向量特征,然后将所有特征构建成高效的向量索引,当一个新查询(图片)来的时候,我们用同样的机器学习方法对其进行分析并产出一个表征向量,然后用这个向量在之前构建的向量索引中查找出最相似的结果,这样就完成了一次以图片内容为基础的图像检索。

1.2 文本检索
向量检索其实很早就已经在常见的全文检索中用到了。
我们这里用地址检索为例来简单介绍下向量检索技术在文本检索中的应用情况和价值。
例1:如下图左边,我们想在标准地址库中搜索“浙一医院”(而标准地址库中恰恰又没有“浙一”这个关键词,“浙一医院”的标准地址是“浙江大学医学院附属第一医院”),如果我们只使用文本分词(“浙一”和“医院”),在标准地址库中是不会找到相关结果的(因为“浙一”这个地址不存在)。但是我们如果能够利用对人们历史语言,甚至之前的点击关联进行分析,建立起语义相关性的模型,把所有的地址都用高维特征来表达,那么“浙一医院”和“浙江大学医学院附属第一医院”的相似度可能会非常高,因此可以被检索出来。
例2:如下图右边所示,同样是地址查询,如果我们想在标准地址库中搜索“杭州阿里巴巴”的地址,在仅使用文本召回的时候,几乎没办法找到相似的结果,但是我们如果通过对海量用户的点击行为进行分析,将点击行为加上地址文本信息合并形成高维向量,这样在检索的时候就可以天然的将点击率高的地址召回并排列在前面。

1.3 搜索/推荐/广告
在电商领域的搜索/推荐/广告业务场景中,常见的需求是找到相似的同款商品和推荐给用户感兴趣的商品,这种需求绝大多数都是采用商品协同和用户协同的策略来完成的。新一代的搜索推荐系统吸纳了深度学习的 Embedding 的能力, 通过诸如 Item-Item (i2i)、User-Item (u2i)、User-User-Item (u2u2i)、User2Item2Item (u2i2i) 等向量召回的方式实现快速检索。
算法工程师通过对商品的相似和相关关系,以及被浏览和被购买的用户行为的抽象,将它们表征成高维向量特征并存储在向量引擎中。这样,当我们需要找一个商品的相似商品(i2i)时,就可以高效快捷地从向量引擎中检索出来。

1.4 几乎覆盖了所有的 AI 场景
其实,向量检索的应用场景远不止上面提到的这些类型。如下图所示,它几乎覆盖了大部分的可以应用AI的业务场景。

2. 向量检索的现状和挑战
2.1 繁多的检索算法
向量检索本质为了求解 KNN 和 RNN 两个问题,KNN(K-Nearest Neighbor)是查找离查询点最近的 K 个点,而 RNN (Radius Nearest Neighbor) 查找查询点某半径范围内的所有点或 N 个点。在涉及到大数据量的情况下,百分之百准确求解 KNN 或 RNN 问题的计算成本较高,于是引入了求近似性解的方法,因此大数据量检索实际要解决的是 ANN(Approximate Nearest Neighbor)的问题。

为求解 ANN 的问题,业内提出了不少的检索算法。常用的算法,最早可以溯源到 1975 年提出的 KD-Tree,其基于欧式空间,采用多维二叉树数据结构解决 ANN 检索问题。20 世纪 80 年代末,产生了空间编码和哈希的思想,主要以分形曲线和局部敏感哈希为代表。分形曲线和局部敏感哈希属于空间编码和转换的思想,类似思想的算法还有 Product Quantization (PQ) 等,这些量化算法将高维问题映射到低维进行求解,从而提高检索效率。21 世纪初,采用邻居图解决 ANN 问题的思想也开始萌芽,邻居图主要基于“邻居的邻居可能也是邻居”的假设,预先建立数据集中所有点的邻居关系,形成具有一定特性的邻居图,检索时在图上进行游走遍历,最后收敛得到结果。
向量检索的算法繁多且缺乏通用性,应对不同数据维度和分布有不同算法,但总体可归为三类思想:空间划分法、空间编码和转换法、以及邻居图法。空间划分法以 KD-Tree、聚类检索为代表,检索时快速定位到这些小集合,从而减少需要扫描的数据点的量,提高检索效率。空间编码和转换法,如 p-Stable LSH、PQ 等方法,将数据集重新编码或变换,映射到更小的数据空间,从而减少扫描的数据点的计算量。邻居图法,如 HNSW、SPTAG、ONNG 等,通过预先建立关系图的方法,去加快检索时的收敛速度,减少需要扫描的数据点的量,以提高检索效率。
2.2 面临的技术挑战
向量检索在发展过程中,也涌现出了一些优秀的开源作品,如 FLANN、Faiss 等。这些作品对业内一些常用和有效的 ANN 算法进行了统一实现和优化,通过运行库的方式,形成一些工程化的检索方案。基于这些运行库和改进,业内也产生了一些服务化的工程引擎,如 milvus、vearch 等。
虽然向量检索发展多年,并逐渐成为非结构化检索的主流方法,但仍存在了不少的技术挑战和问题。

2.2.1 超大规模索引的精度和性能
源于非结构化数据的繁多而复杂,向量检索天生便是用于应对这种大规模的数据检索,但面对亿级,甚至十亿级以上的场景,许多检索算法仍面临了挑战,工程实现也存在着一些问题,要么构建成本巨大,要么检索效率低下。
另外,维数的增加也造成了一些向量检索方法的效率下降,在高维空间下华而不实,同时工程上也增加了数据计算和存储成本。其次,算法上缺乏完全通用性,无法对数据实现泛一致性检索,即任何数据分布上,检索算法都是有效的。

目前,业内在处理高维十亿级别的数据时仍显得力不从心,多采用多片索引分别检索合并的方法,增加了实际计算成本。
2.2.2 分布式构建和检索
向量检索目前多通过数据分片的方式实现水平扩展,然而过多的分片容易造成计算量的上升,从而导致检索效率的下降。在分布式方面,仍存在向量索引快速合并算法的难题,这便导致了数据一旦分片之后,无法很好套用 Map-Reduce 计算模型合并成效率更高的索引。

2.2.3 流式索引的在线更新
传统的检索方法能很方便的实现增查改删(CRUD)的操作,向量检索依赖数据分布和距离度量,部分方法还有数据集训练的要求,数据点的变更甚至动一发而牵全身。因此,要实现向量索引的从 0 到 1 的全流式构建,并满足即增即查、即时落盘、索引实时动态更新的要求,对算法和工程仍存在着一些挑战。
目前,对于非训练的检索方法,能较方便的支持全内存索引的在线动态新增和查询,然而面对即时落盘、内存不足、在线向量动态更新和删除等要求,操作成本很大,满足不了实时性。

2.2.4 标签+向量的联合检索
在大多数业务场景下,需要同时满足标签检索条件和相似性检索的要求,如查询某些属性条件组合下相似性的图片等,我们称这种检索为“带条件的向量检索”。
目前,业内采用多路归并的方式,即分别检索标签和向量再进行结果合并,虽可以解决部分问题,但多数情况下结果不甚理想。主要原因在于,向量检索无范围性,其目标是尽可能保证 TOPK 的准确性,TOPK 很大时,准确性容易下降,造成归并结果的不准确甚至为空的情况。

2.2.5 复杂的多场景适配
向量检索是一种通用能力,但目前尚无通用算法可以适配任意场景和数据,就算同一种算法适配不同数据时,也存在参数配置的差异。如对于多层聚类检索算法,使用什么聚类算法、分多少层、聚多少类、检索时使用什么样的收敛阈值,这些在面对不同场景和数据时都是不一样的。正是因为这些超参调优的存在,大大加大了用户的使用门槛。
想让用户变得更简单,必然需要考虑场景适配的问题,主要包括数据适配(如:数据规模、数据分布、数据维度等)和需求适配(如:召回率、吞吐、时延、流式、实时性等)两方面。基于不同的数据分布,通过选择合适的算法和参数,以满足实际的业务需求。

3. 达摩院向量检索技术揭秘
Proxima 是阿里巴巴达摩院自研的向量检索内核。目前,其核心能力广泛应用于阿里巴巴和蚂蚁集团内众多业务,如淘宝搜索和推荐、蚂蚁人脸支付、优酷视频搜索、阿里妈妈广告检索等。同时,Proxima 还深度集成在各式各类的大数据和数据库产品中,如阿里云 Hologres、开放搜索(OpenSearch)、搜索引擎 ElasticSearch 和 ZSearch、离线引擎 MaxCompute (ODPS) 等,为其提供向量检索的能力。
Proxima 是通用化的向量检索工程引擎,实现了对大数据的高性能相似性搜索,支持 ARM64、x86、GPU 等多种硬件平台,支持嵌入式设备和高性能服务器,从边缘计算到云计算全面覆盖,支持单片索引十亿级别下高准确率、高性能的索引构建和检索。
3.1 核心能力

如上图所示,Proxima 的主要核心能力有以下几点:
•超大规模索引构建和检索:Proxima 精于工程实现和算法底层优化,引入了复合性的检索算法,基于有限的构建成本实现了高效率的检索方法,单片索引可达几十亿的规模。
•索引水平扩展:Proxima 采用非对等分片的方法实现分布式检索。对于邻居图索引,解决了有限精度下图索引快速合并的难题,与 Map-Reduce 计算模型可有效进行结合。
•高维 & 高精度:Proxima 支持多种检索算法,并对算法做了更深层的抽象,形成算法框架,依据不同数据维度和分布选择不同算法或算法组合,根据具体场景需求实现精度和性能之间的平衡。
•流式实时 & 在线更新:Proxima 采用扁平化的索引结构,支持在线大规模向量索引的从 0 到 1 的流式构建,并利用邻居图的便利性和数据特点,实现了索引即增即查、即时落盘,以及实时动态更新。
•标签+向量检索:Proxima 在索引算法层实现了“带条件的向量检索”方法,解决了传统多路归并召回结果不理想的情况,更大程度的满足了组合检索的要求。
•异构计算:Proxima 支持大批量高吞吐的离线检索加速,同时解决了 GPU 构建邻居图索引的难题,另一方面也成功解决了小批量+低延时+高吞吐的资源利用问题,并将其全面应用在淘宝的搜索推荐系统中。
•高性能和低成本:有限成本下实现最大化性能并满足业务的需求是向量检索需要解决的主要问题。Proxima 实现了对多种平台和硬件的优化,支持云服务器和部分嵌入式设备,通过与分布式调度引擎的结合实现离线数据检索和训练,通过扁平化索引和磁盘检索的方案实现了对冷数据的快速检索。
•场景适配:结合超参调优和复合索引等方法,通过对数据采样和预实验,Proxima 可以解决一些数据场景智能适配的问题,从而提高系统的自动化能力,以及增强用户的易用性。
3.2 业内对比
目前,业内普遍使用的向量检索库是 Facebook AI 团队开源的 Faiss (Facebook AI Similarity Search) 引擎。Faiss 非常优秀,也是不少服务化引擎的基础核心,但 Faiss 在大规模通用检索场景方面仍存在一些局限性,如流式实时计算、离线分布式、在线异构加速、标签&向量联合检索、成本控制以及服务化等方面。
例如,针对公开的十亿规模的 ANN_SIFT1B 数据集(来源 corpus-texmex.irisa.fr),在 Intel(R) Xeon(R) Platinum 8163 CPU & 512GB 内存的服务器上,由于 Faiss 要求的计算资源过于庞大,无法实现单机十亿规模的索引的构建和检索。而 Proxima 在同样的环境和数据量下单机可以轻松完成十亿规模的索引的构建和检索。
考虑到测试的可行性,达摩院团队在同样是 2 亿规模的数据量下,针对索引构建和检索对比了 Faiss 和 Proxima,另外,同样 2000 万规模的数据量下,对比了 Faiss 和 Proxima 单卡的异构计算能力,对于十亿规模的数据量 Proxima 则单独给出测试数据,具体结果如下。
3.2.1 检索对比


Proxima 的检索性能优于 Faiss 数倍,并且能实现更高精度的召回,针对 TOP1 的检索更是技胜一筹。除此,Faiss 在一些算法实现上也存在设计缺陷,例如 HNSW 的实现,针对大规模索引,检索性能非常低。
3.2.2 构建对比

Faiss 两亿规模索引的构建时间需要 45小时,采用 HNSW 优化的情况下可缩短到 15小时,而相同资源下 Proxima 一个多小时便可构建完索引,并且索引的存储更小,精度更高(见检索对比)。
3.2.3 异构计算
Proxima 采用了和 Faiss 不一样的 GPU 计算方法,特别针对“小批量+低延时+高吞吐”的在线检索场景进行优化。

Proxima 在小批量场景表现出了惊人的优势,小批量、低延时、高吞吐,并能充分利用 GPU 资源。目前,该检索方案也大规模应用在阿里的搜索推荐业务上。
3.2.4 十亿规模
Proxima 支持流式索引和半内存构建检索模式,真正做到了有限资源下,单机十亿规模级别的索引构建,以及高性能高精度检索。 Proxima 这种高性能低成本能力为 AI 大规模离线训练和在线检索提供了强有力的基础支持。


4.向量检索在行业搜索中的应用
4.1阿里云智能搜索开发平台-开放搜索(OpenSearch)
开放搜索(OpenSearch)是基于阿里巴巴自主研发的大规模分布式搜索引擎搭建的一站式智能搜索业务开发平台,目前为包括淘宝、天猫在内的阿里集团核心业务提供搜索服务支持。通过内置各行业的查询语义理解、机器学习排序算法等能力,提供充分开放的引擎能力,助力开发者快速搭建更高性能、更高搜索基线效果的智能搜索服务。
4.2行业搜索应用
各个行业的搜索业务具有不同的行业特性和业务需求,开放搜索根据多年积累的行业经验打造了独有的行业垂直解决方案,借助达摩院先进的智能语言处理技术,贴合行业痛点与需求,提供了行业专属查询分析能力、内置好行业排序表达式及行业算法能力,降低接入门槛,实现一键式配置,提升接入效率的同时也为企业提供更优质的搜索效果。
4.2.1电商行业应用
开放搜索电商行业模板将行业搜索产品化落地,用户无需各方向技术探索,只需按模板接入即可拥有更优搜索服务,免去了大量的数据标注与模型训练工作,直接内置淘系搜索算法能力。支持个性化搜索与服务能力,通过引擎侧的多路召回能力,实现搜索结果、下拉提示、底纹词等重要服务,并根据电商行业变化,不断迭代更新原有能力,提供更高时效性的服务保障;

向量召回在商品搜索多路召回中的应用:

了解更多:https://www.aliyun.com/page-source//data-intelligence/activity/opensearch
4.2.2在线教育拍照搜题应用
开放搜索拍照搜题解决方案:
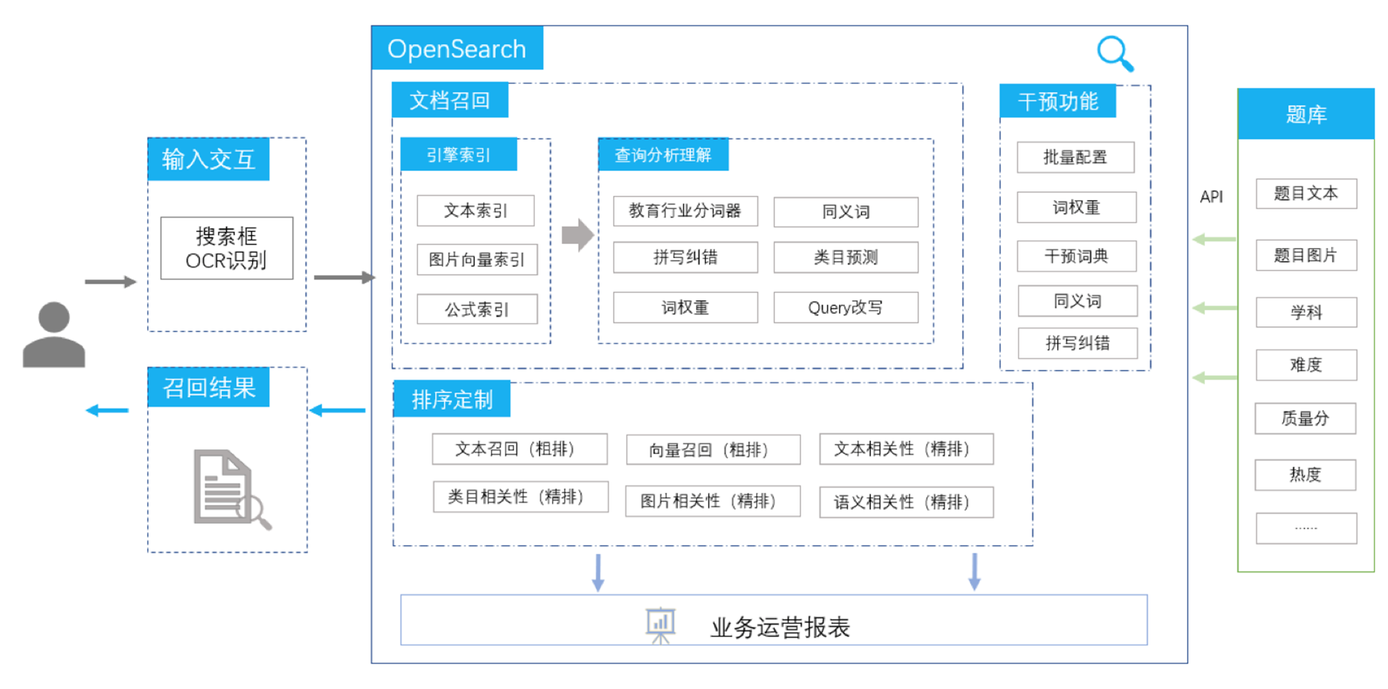
多路召回在教育搜题中的应用:
为什么搜题要做多路召回?
教育拍照搜题场景相比网页/电商的文本搜索有显著差异:
- 搜索query特别长:常规检索term数上限30,搜题需要放到100;
- 搜索query是由拍照OCR识别之后得到的文本,关键term的识别错误会严重影响召回排序;
纯文本查询方案
1. OR逻辑查询
- 为了降低无结果率,搜题客户常见的系统是基于ES默认的OR逻辑,latency高,计算消耗大;
- OpenSearch也支持OR逻辑,针对latency高可以通过并行seek的方式优化,但整体计算消耗仍然高;
2. AND逻辑查询
- 采用通用的query分析模块,无结果率高,整体准确性不如OR逻辑;
- 针对教育领域优化定制的query分析模块,大幅提高效果,准确性接近OR逻辑;
如何去兼顾计算消耗和搜索准确性那?我们在此引入了文本向量检索
文本向量检索
目标:通过文本向量检索扩召回,结合AND逻辑查询,做到latency和计算消耗低于OR逻辑的情况下准确性更高;
向量召回采用目前最先进的BERT模型,其中针对教育搜题做的特别优化有:
- BERT模型采用达摩院自研的StructBERT,并针对教育行业定制模型;
- 向量检索引擎采用达摩院自研的proxima引擎,准确性和运行速度远超开源系统;
- 训练数据可以基于客户的搜索日志不断积累,效果持续提升;
这个图我们可以看到有一项召回,在召回率上已经达到凹逻辑。同时在准确性上现在超出2逻辑3到5个点,整体的召回到数减少40倍的情况下,latency 可以降低10倍以上。

-1...1
cosine-simlu,
0.8
0.6
QPYHeaY
0.4
pooling
pooling
tentOR
0.2
BERT
BERT
textAND
SimiloritySearch
textAnD+SimilaritySearch
---
SentenceA
SentenceB
0.0
MWW
numoftopkinSimilaritySearch
效果:
- 召回率达到OR逻辑
- 准确性超出OR逻辑3%-5%
- 整体召回doc数量减少40倍,latency降低10倍以上
多路召回优势:
文本召回和语义向量召回的结合在搜题场景已经验证有效,开放搜索的多路召回架构还将有更多的使用空间:图片向量召回、公式召回、个性化召回。
除了开放搜索内置的向量模型,我们也将支持客户自己的向量索引,欢迎客户和我们一起深耕搜题算法优化。
了解更多:https://www.aliyun.com/page-source/data-intelligence/activity/edusearch
5. 技术展望
随着 AI 技术的广泛应用以及数据规模的不断增长,向量检索作为深度学习中的主流方法,其具备的泛检索和多模态搜索的能力也将进一步得到发挥。物理世界的实体和特征,通过向量化技术进行表征和组合,映射到数字世界,借助计算机进行计算和检索,挖掘潜在逻辑和隐式关系,更智能的服务于人类社会。
未来,向量检索除了要面对数据规模的不断增长,算法上仍需要解决混合空间检索、稀疏空间检索、超高维、泛一致性等问题。工程上,面对的场景将越来越广泛,也越来越复杂,如何形成强有力的系统化体系,贯穿场景和应用,将是向量检索下一步发展的重点。
如果您对AI检索技术感兴趣可以关注公众号了解更多内容

如果您对搜索与推荐相关技术感兴趣,欢迎加入钉钉群内交流

【开放搜索】新用户活动:阿里云实名认证用户享1个月免费试用

