黄仁勋在熟悉的背景音乐中上场,GTC今年已经是第十年了。
称不上激昂,但显然迫不及待要分享。不是首先揭幕万众期待的新品,而是回归初心——黄仁勋说,图形技术是GPU的核心驱动力,是虚拟现实的根本,在各种各样的领域,我们想将信息和数据可视化,形成了R&D预算,由此也构建了巨大的市场。
重现逼真图像是计算机图形学一直以来的追求,要呈现一幅美丽的图像,40年来,GPU渲染一幅图的时间,从几小时降到了几秒,而且图像的清晰度增加到了4K。
接着,黄仁勋回顾了各种技术,光的反射、散射、漫射、阴影……以及要渲染出种种质感相应的技术。
接着,展示了一段《星球大战》视频的演示,重点是逼真效果的实时Ray Tracing,各种表面的光线反射,每当一束光线遇到一个表面,都要决定要反射还是被吸收,什么角度反射,被吸收多少程度,整个环境中到处都是表面,每一个都需要渲染……这些需要庞大的计算量,因此动画公司才需要超级计算机来计算这些效果。
十年技术成果,首次将实时光线跟踪技术推向商业市场
而英伟达一台DGX-Station就够了。

于是,第一个宣布——RTX Technolgy,这是英伟达十年技术成果,也是Ray Tracing首次在这种规格上,全部实时实现。黄仁勋说,这是首次将实时Ray Tracing带向商业市场。感谢GPU,感谢深度学习。
英伟达推出的Quadro GV100 GPU将该公司最近发布的RTX光线跟踪技术引入工作站。英伟达的RTX光线追踪技术是软件和硬件的组合,允许应用程序生成实时光线追踪效果。
Quadro GV100配备32GB内存,与Tesla V100有相同的底层设计。GV100可以提供高达7.4 TeraFLOPS的双精度和14.8 TeraFLOPS的单精度计算。英伟达表示这个显卡还可以提供高达118.5 TeraFLOPS的深度学习性能。
Quadro GV100还支持NVLink 2互连技术,可以将这两个设备配对在一起。总共64GB的HBM2内存,10,240个CUDA内核和236个张量内核整合到一个工作站中。

电影大片完成后,要得到逼真效果,“CPU渲染一帧10小时,”黄仁勋说:“使用GPU要快很多,而且更重要的是,能省钱——大家都知道了,你买的GPU越多,你省的钱越多。”现在这已经是常识了。
全球最大GPU,核弹轰炸!!!
接着,也是全场最重要揭幕了全球最大GPU——Quadro GV100,这是一个GPU工作站,2个GV100,使用NVLink相连,形成一个完整的工作站,软件感觉不到切换。

VIDIA TESLA V100 32GB,SXM3
这个全球最大的GPU有多大?感受一下:
普通GPU(你能看出型号吗?是N粉就说!)

这是最大GPU:

相比庞大繁重的CPU机架,使用英伟达RTX Quadro GV100,14-Quad-GPU服务器,“省下成千万上亿美元”。

新系统旨在允许开发人员扩大其神经网络的规模。DGX-2具有12个NVSwitch,每个NVSwitch的特点是在台积电12nm FinFET工艺上制造了120亿个晶体管。每个交换机都具有18个8位NVLink连接。IBM已经宣布将于2019年推出采用NVLink 3.0的Power9系统,因此我们预计NVSwitch将利用这种互补互连。
太美了,太性感了,太美了。
黄仁勋掩饰不住沉醉。
DGX-2专门为深度学习,而生一天半就完成了。
如今AI研究员使用AI设计/发现AI,实验的规模和数量都不断增长。更多的实验、更多的数据,DGX-2推出的时机不能在好了。
价格?
39.9万美元。
加倍Tesla V100内存
下面简单介绍其他宣布。
特斯拉V100采用了迄今为止生产量最大的单模芯片。采用台积电12纳米FFN工艺制造的815毫米2 伏特晶体管,使用了210亿个晶体管,几乎是全分划板的尺寸。GPU包装了5120个用于AI工作负载的CUDA核心,虽然它具有足够的处理能力,但英伟达已经使用额外的16GB HBM2内存支持该卡。英伟达表示,更强大的32GB内存可以在内存受限的HPC工作负载中实现双倍的性能。
NVSwitch拓扑将16个GPU连接在一起,形成一个具有统一内存空间的统一内核单元,从而创建Jensen吹捧为“世界上最大的GPU”的内容。该系统共有512GB HBM2内存,可提供高达14.4TB / s的吞吐量。它共有81,920个CUDA内核。
GPU接受程度前所未有,形成全球计算范式
接着,黄仁勋表示,英伟达做的最好决定之一,是这些年来,让GPU越来越通用,在不损失计算机图形学性能的前提下,将GPU导向深度学习。然后,引爆点到来,现在,GPU已经成为广为接受的一种计算范式,全世界有100万GPU工程师,GTC成为全球会议,cuDNN 800万次下载,一大半都发生在去年一年,而英伟达10年前就开始提供。
GPU接受程度前所未有,然而,这还不够。
我们还需要更大的计算机,更快的计算机。加州理工大学要模拟一个项目,需要7天;要模拟一个艾滋病模型,需要3个月。过去5年,GPU增速25倍,远远超出摩尔定律。我们正处于超级摩尔定律时代,而这一趋势也将持续。
接着是教主的自豪/自傲时间,英伟达基本上每年都推出新架构,与软件工程师合作保持套件更新。总之,说道这里,教主表示,祝贺John Hennessy和David Patterson获得2017年的图灵奖,“John的体系结构演讲精彩非凡——但是,我的演讲很简单,”黄仁勋说,没错,英伟达在高性能计算(HPC)方面,也(买越多越)省钱!
要让医生/医院更换现有基础设施,需要30年。等不了这么久,怎么办?有没有办法利用现有技术,在改动不大的前提下,给予医生更大的智能能力。

英伟达医疗图像超级计算机Clara应运而生。接入现有的医疗设备,比如超声波检测仪,就能将整套流程全部升级——使用深度学习,在原来的黑白图像上实时渲染出颜色,分层、分区域,并且变为3D图像,后期各种计算机技术,提升图像质量,医生的检测能够变得更加敏锐清晰。
目前,英伟达的Clara计划已经与数十家公司,初创企业为主,构建了生态。可以想象,将英伟达的超级医疗图像计算机部署到医院,又打开了一大市场。
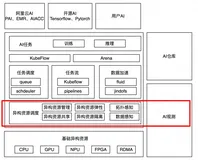
推理很难:公布TensorRT 4.0,以及Kubernetes on GPU
讲到这里,黄教主已经一个人说了1个多小时。
“Plaster。”说完这个词,他停了一会,歇一口气。
这也是教主自己发明的词,希望向世人传达的GTC第二大要点。
这个词是关于推理(inference)。推理很难,精度、通量……各种变量要考虑。如何让推理变得更好?这里,当然是英伟达的高性能神经网络推理引擎TensorRT的更新——TensorRT 4.0发布,用于在生产环境中部署深度学习应用程序,应用有图像分类、分割和目标检测等,可提供最大的推理吞吐量和效率。TensorRT是第一款可编程推理加速器,能加速现有和未来的网络架。TensorRT 4.0实现全栈连接。
与CPU相比,NVIDIA TensorRT 4 现在可以将AI任务的参数加速200倍,适用于图像分类、分割、物体检测、语音识别、机器翻译等应用。

此外,还有英伟达GPU Kubernets。
Kubernetes借助NVIDIA GPU,开发人员现在可以即时地将GPU加速的深度学习和HPC应用程序部署到multi-cloud GPU群集中。
“人生完整了。”黄仁勋说。
暂停无人车研发,英伟达股价下跌3.8%
一口气发布这么多款产品,黄教主可谓是蛮拼的,但其实这样做也是英伟达不得不为之的事情。
值得一提,在黄仁勋演讲接近尾声的时候,英伟达股票下跌了3.8%。
“我们要暂定无人驾驶的研发。”黄仁勋说。
Uber自动驾驶致死事故显然对英伟达造成了巨大的影响。根据公开资料,Uber从2016年首次部署沃尔沃SC90 SUVS测试车队以来,一直使用英伟达的计算技术。
这让人想起了当年特斯拉车祸时,与特斯拉分手的Moibleye——但不同的是,Mobileye并没有要停止研发,而是迅速搭上了其他公司,而后被英特尔以153亿美元的高价收归旗下。
英伟达目前没有表示具体研发计划暂定的时间。

虽然现实世界中停止路测,但英伟达还推出了一个测试自动驾驶汽车的新系统DRIVE Con stellation,这是一款基于云计算的平台,将使用逼真模拟测试驾驶场景。
系统在两台服务器上运行。第一台服务器支持Nvidia DRIVE Sim,它一款模拟自动驾驶汽车各种传感器(包括其摄像头,激光雷达和雷达)的软件。第二台服务器包含Nvidia DRIVE Pegasus AI,它将处理收集的数据,就好像它来自道路上自驾车的传感器。
前压后赶,英伟达衰相已现?
其次,也不要忘记英伟达面临的众多对手。
首先是英特尔。英特尔去年宣布发布Nervana神经网络处理器(NNP)系列芯片,代号为Lake Crest。这款芯片的强大之处在于,它由“处理集群”阵列构成,处理“活动点(flexpoint)”的简化数学运算。这种运算相对于浮点运算所需的数据量更少,性能号称提升10倍。

不过,Nervana系列芯片宣称2017年年底量产,但直到现在还一直跳票;而且,英伟达已经在游戏、深度学习、自动驾驶等领域建立起自己的芯片生态圈,“护城河”相当宽。但是,就像黄教主经常揶揄CPU的摩尔定律一样,反过来看,GPU并没有本质上的突破,GPU的现在优势可能很容易就被性能一日千里的神经网络芯片超越,英伟达的护城河很快就会被攻破。
跟英特尔一起攻城的还有赛灵思。
今年3月20日,赛灵思推出ACAP(Adaptive Compute Acceleration Platform,自适应计算加速平台),ACAP是一个高度集成的多核异构计算平台,它的核心是新一代FPGA架构,能根据各种应用与工作负载的需求从硬件层对其进行灵活变化。ACAP的灵活应变能力可在工作过程中进行动态调节,它的功能将远超FPGA的极限。

赛灵思新任CEO Victor Peng在接受新智元采访时表示,GPU虽然在某些方面比CPU能处理的更好,但也不能适应所有的情况,因此现在更多需要的是异构计算。尤其是在人工智能时代,赛灵思也想通过自身在异构计算方面优势来实现对英伟达以及英特尔的赶超。
除了前面两个大块头,AI芯片创业公司也让这片市场从蓝海变成红海。中国有寒武纪、地平线、深鉴科技,英国有哈萨比斯投资的Graphcore,美国也有多家AI芯片初创公司。这些公司针对的是不同的应用场景,每一家都有可能抢走英伟达的细分市场。
不过,最能给英伟达造成威胁的,还应当是带头大哥谷歌。
虽然谷歌的TPU只是用在谷歌内部,但单从硬件性能看,TPU已经超越英伟达GPU。
原文发布时间为:2018-03-28
本文作者:闻菲、张乾、肖琴
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号