★卫星互联网;算力;卫星通信;互联网;低轨卫星互联网;5G基础设施;GPT-4 Turbo;算力;地面通信;液冷;水冷;AI服务器;东数西算;CPU+XPU异构;GPGPU;大模型训练;云服务;高通量计算;A100;A800;H100;H800;L40s;算力服务器;5G;视频渲染一体机;马斯克;SpaceX;边缘计算;嵌入式计算机;深度学习;;英伟达;NVIDIA;人工智能;物联网;IOT;云计算;自动驾驶;无人驾驶;辅助驾驶
据最新消息,马斯克“千人上火星计划”又一次未能如愿。据不完全统计,他在星舰项目上投入至少30亿美元,总投入超过200亿人民币。然而,尽管投入巨大,星舰研发道路仍然充满坎坷。早在今年4月,运力超过150吨的“史上最强运力”火箭在发射后几分钟内就在夜空中崩裂解体。自4月首飞以来,SpaceX对星舰进行1000多次改进。在11月18日21点,星舰33台推进器完成检测,进入预发射状态。发射3分钟后,飞船与推进器成功分离,9分钟后按照预定程序关闭引擎。然而,就在SpaceX团队为这一重要里程碑庆祝时,二级火箭发生故障,导致飞船失去联系。虽然路透社将此次任务定义为“一次失败的发射”,但SpaceX团队和马斯克并未因此放弃。
SpaceX官方表示将继续通过测试提高星舰的可靠性。在这期间,33台猛禽发动机全部成功点火并通过级间热分离。对于马斯克来说,本次项目发射的重点是测试系统和收集数据。他在上个月就表示,“(对于第二次发射)不要把发射台炸了就好。”这位世界首富之所以对商业火箭如此宽容,是因为他的目标远大:将1000人送上火星!盈利或许只是星舰项目的附带产出。
早在16年前,马斯克就预测人类将在2025年前抵达火星。为实现他的愿景,SpaceX团队致力于创新技术,而本次星舰发射是商业公司尝试飞出地球的重大举措。为实现个人航天的目标,马斯克团队研发出垂直起降可回收系统,按照预定设想,星舰飞船将从得克萨斯州发射,并在升空约1.5小时后降落在夏威夷,若需再次执行任务,只需往发动机再次灌满液态甲烷和液态氧。
在璀璨的星辰大海中,卫星互联网正引领着人类探索宇宙、拓宽认知边界的新征程。在这无限可能的征程中,需要对卫星互联网专业知识进行深入探究,借助AI算力,静待应用在未来的星辰大海中开花结果。那么,如何打造互联卫星网平台呢?
卫星互联网:星辰大海,征程无限
卫星互联网利用卫星通信技术,将地面基站搬到太空中的卫星平台,每颗卫星都成为天上移动基站,为全球用户提供高带宽、灵活便捷的互联网接入服务。即使在没有地面通信基站的情况下,利用卫星信号也能支撑电力巡检、应急保障等任务。
卫星互联网作为地面通信重要补充,具有低延时、低成本、广覆盖和宽带化等优势。
一、低延时
由于低轨卫星距离地表较近,时延相对较低,相比传统高轨卫星可以更好地满足实时通信需求。
二、低成本
卫星互联网组网成本较低,比地面5G基础设施及海洋光纤光缆建设更经济高效。随着技术的不断进步,未来卫星制造及发射成本还有望持续下降。
三、广覆盖
卫星互联网可以覆盖到地面网络难以覆盖的偏远地区、海上和空中用户,实现全球无缝覆盖,满足不同用户对互联网服务需求。
四、宽带化
随着高通量技术不断成熟,单星容量得到提升,单位带宽成本降低,可以满足高信息速率业务需求,为下游应用打开新发展空间。
卫星互联网专业知识解答
一、高轨卫星通信系统已经商用,为什么要建设低轨系统?
已商用高轨卫星通信系统服务大众市场,但受限于其通信容量和服务质量,难以满足对时延、带宽要求较高的大众应用场景。因此,需要建设低轨卫星通信系统来弥补高轨系统的不足。华为发布支持卫星通话的Mate 60 Pro手机是高轨卫星通信系统开始面向大众市场提供商用服务的标志。相比高轨系统,低轨卫星通信系统具有更高的系统容量和更低通信时延,能够更好地满足手机通话等大众应用场景需求。
低轨卫星通信系统具有短时延和大容量等优点,比高轨系统更具商业化价值。低轨卫星通信系统空间段由大量低轨道卫星组成,能提供更快的通信速度和更大的系统容量,可同时为大量用户提供宽带网络接入服务。

典型高低轨卫星通信系统效率对比
二、为什么频轨资源是卫星互联网争夺的焦点?
LEO轨道资源相对丰富,但高价值轨位仍是稀缺资源。为避免频率干扰和卫星碰撞风险,卫星之间需保持安全距离,导致同一高度轨道存在容量上限。研究显示,200年内,高度200~900km的LEO轨道空间可容纳180万颗活动卫星。另据中科院软件所研究,当同层与跨层星间最小安全距离均为50km时,高度300~2000km轨道空间内可容纳17.5万颗卫星。尽管LEO轨道卫星容量较大,但300~600km左右轨道高度在卫星寿命、通信时延、频率干扰等方面具有一定优势,是卫星互联网星座运营方重点争夺的位置。
传统卫星频段日益拥挤,Ka频段成为低轨卫星通信核心通道。卫星频段由ITU划分并分配给各国,1.5GHz和2GHz的L、S频段有“黄金频段”之称,但因稀缺性及大量频率资源已被占用,国内申报和海外协调难度大,目前卫星通信业务几乎无法使用L/S频段实现全球覆盖。NGSO宽带互联网星座大都选择Ku、Ka频段,但Ku、Ka频段在轨GEO卫星网络资料数量大,同一区域多个NGSO频谱排他性严重,如OneWeb声称拥有Ku频段独家频谱拥有权,Ku/Ka频段的频率协调难度越来越大。

不同频段资源的主要应用领域
三、怎么理解申报的星座规模和实际发射数量间的关系?
国际上卫星频轨资源获取采用“先到先得”原则,申报方需要向ITU提交申请,并在公示后一定时间内拥有该频轨资源的独家使用权。SpaceX于2015年提出“Starlink计划”,并于2016年向ITU申请1.2万颗卫星的发射计划,随后于2019年将星座规模扩大至4.2万颗。此后,卫星频轨资源的竞争日益激烈,全球主要国家均采取批量申报的方式以锁定优势轨位及频率资源。包括波音、空客、亚马逊、Google、Facebook等企业在内的众多企业均已在ITU申报大量的卫星频轨资源。

海外小卫星星座建设计划
四、如何降低卫星互联网的星座部署成本?
卫星工程大系统包括卫星系统、运载火箭系统、发射场系统、测控系统和地面应用系统,其中卫星系统和运载火箭系统是成本占比最高的两大系统。据SpaceX数据,猎鹰9号运载火箭发射成本主要由火箭成本、发射成本、保险成本和测控成本组成,其中火箭成本占比达70%。据美国卫星工业协会数据,2022年全球卫星制造业收入约158亿美元,发射服务业收入约70亿美元,卫星行业市场规模约为发射服务环节的2.25倍。目前国内卫星制造成本和火箭发射成本与海外存在明显差距,未来具有较大优化空间。

猎鹰9号火箭发射成本的构成
卫星平台和有效载荷各占整星成本的50%。卫星平台包括结构与热控、姿态与轨道控制、电源与供配电、测控和数据管理等分系统,是实现卫星基本功能的主要组成。其中,卫星结构和热控分系统成本约占整星的5%-10%;姿态与轨道控制分系统起到卫星姿态、轨位控制功能,包括星敏感器、太阳敏感器、磁力矩器、动量轮、推进器等部件,约占整星成本30%-40%;测控与数据传输、数据管理系统约占整星成本10%-15%左右。有效载荷是实现卫星设计功能的仪器和设备,根据卫星任务不同分为通信、导航、遥感或科学研究载荷,通常有效载荷约占整星成本的50%左右。

卫星的结构组成及价值量分布
我国卫星制造成本高于海外商业卫星,规模化生产是降低卫星制造成本的关键途径。根据长江日报报道,我国每颗卫星的平均生产成本超过亿元,而Starlink和亚马逊单颗卫星的制造成本仅为50万和100万美元。为降低制造成本,可采用新设计理念、新技术、新工艺,并引入商用货架产品替代宇航级元器件。此外,面对大规模卫星组网发射需求,规模化生产也是降低卫星制造成本的重要途径。例如,OneWeb卫星工厂引入自动化生产线和协作机器人、智能工具等先进技术,单条生产线每天可以生产2颗卫星。我国已有多个机构建成智能化生产产线,有助于提高卫星批产效率、降低研制成本。

OneWeb卫星工厂生产流程示意图
相较于美国等成熟商业发射市场,国内火箭发射成本仍有优化空间。SpaceX公司的猎鹰9号发射任务成本包括火箭成本、发射成本、测控成本和保险费用,其中火箭成本占比最大,测控成本约占总成本13%。运载火箭是发射成本中最主要的可控项。据SpaceX公司公布的数据,猎鹰9号火箭LEO轨道发射服务公开报价约3000美元/千克,低于其他同等运载能力的一次性运载火箭。国内快舟1号运载火箭的LEO轨道发射服务价格约为2万美元/千克,仍有较大的优化空间。

国内外商业火箭发射价格及运载能力
商业火箭有助于降低卫星发射成本,可重复使用,有望在2025年后投入使用,进一步降低卫星互联网星座部署成本。面对大规模卫星组网发射需求,国内火箭仍存在有效运力不足、发射成本较高问题。近年来,国内商业发射领域蓬勃发展,涌现出一批代表性商业火箭企业,具备商业载荷入轨发射能力,并探索低成本商业发射路径。商业火箭的发展有助于降低卫星发射成本。同时,我国新型重复使用运载火箭可逐步承担更大规模的组网发射任务,有望进一步降低卫星互联网星座的部署成本。
五、国内是否具备大规模卫星组网发射的能力?
巨型星座是卫星互联网空间段的主要形态,其中Starlink已经成为全球发射主力。Starlink已完成5033颗星链通信卫星发射,其发射计划密集且卫星数量众多,整体发射规模远超其他星座。在2020~2022年期间,Starlink分别完成14/19/34次发射,年发射次数逐年递增,其中2022年月均发射近3次。通过设计、制造、发射的全流程协同,Starlink卫星采用可堆叠构型,可以通过一箭多星的形式快速部署,猎鹰9号火箭单次可以发射60颗Starlink V1/1.5卫星或22颗Starlink V2 Mini卫星。

Starlink不同版本卫星发射数量占比
Starlink推动全球航天发射和低轨卫星的发展。作为全球首个超大规模低轨星座计划,Starlink对全球航天发射市场产生了强烈推动作用。统计数据显示,2000~2018年全球航天年均发射次数为73次,其中低轨发射平均为11.4次,每年占全球航天发射次数的10%~20%。然而,自2021年Starlink开始密集组网发射后,全球低轨发射次数占比提升至总发射次数的35%~40%,显示Starlink对全球低轨卫星发展的强劲推动作用。

Starlink推动全球轨道发射数量和低轨发射占比提升
我国已掌握高效部署关键技术,如一箭多星和可堆叠卫星,以提高星座部署效率和降低单星发射成本。例如,6月15日,我国使用长征二号丁火箭成功发射吉林一号高分06A星等41颗卫星,创下我国一箭多星新纪录。此外,7月23日,长征二号丁运载火箭成功将银河航天灵犀03星等卫星送入预定轨道,该卫星采用平板可堆叠构型,进一步提高部署效率。这些技术的突破为我国巨型卫星星座的高效组网奠定基础。

长二丁一箭41星发射
国内拥有四个陆地发射场和一个海上发射场,但要保障大规模卫星互联网发射,还需提升运载能力。现有的发射场包括酒泉、太原、西昌和文昌等,同时海阳海上发射场也具备一定的发射能力,可满足不同类型火箭和卫星的发射需求。此外,文昌、象山、烟台等地正在筹建新的商业发射工位,有望进一步提升现有的运载能力。然而,面对卫星互联网密集组网带来的运力需求,当前的发射能力仍需进一步提升。
六、卫星互联网有哪些应用场景,商业模式是否具有经济可行性?
卫星互联网在航空、航海、车联网等领域有广泛应用,未来成长空间广阔。传统卫星通信系统能满足基本通信需求,而卫星互联网能实现全地域稳定网络服务,弥补传统地面通信的不足。典型应用场景包括航空和航海,如ATG形式的空中互联网对基站建设存在依赖,卫星互联网能够满足全地域稳定网络服务的要求;传统地面基站无法在海上铺设,卫星互联网可直接通过船载卫星设备终端实现海上船只与地面通信网络的互联网互通。未来,卫星互联网在众多应用场景中具有广阔成长空间。

卫星互联网的应用场景
七、怎么理解卫星互联网与地面蜂窝网的关系?
卫星互联网和地面蜂窝网正逐渐从“两网分离”走向“星地融合”。传统高轨通信卫星采用DVB-S、DVB-S2等标准,地面蜂窝网采用4G、5G等标准,卫星通信采用的频段、协议等与地面蜂窝网不兼容。2021年6月,《6G总体愿景与潜在关键技术白皮书》发布,提出“星地一体融合组网”是6G十大关键技术之一,可实现空基、天基、地基网络的深度融合。卫星互联网和地面蜂窝网的融合包括三种策略:星地组合、星地一体化、地面辅助。其中,星地组合策略,卫星系统作为地面网络的补充,主要解决数据中传和后传问题;星地一体化策略,3GPPR17制定NTN标准协议支持物联网和智能设备通信应用,实现卫星与手机直接连接提供语音电话和通信服务;地面辅助策略,通过引入地面基站优化卫星网络地面覆盖效果,解决卫星在市内、楼宇间通信质量较差的问题。
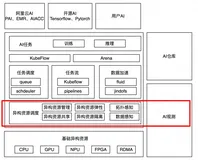
AI算力:算力先行,静待应用开花
OpenAI推出的GPT-4 Turbo、GPT应用商店和Assistant API等有望引领应用生态发展,智算中心建设和国产AI算力崛起的同时,AI服务器、交换机和液冷散热也成为受益者。随着智算中心加速部署,计算、网络、存储需求高速增长,头部厂商在散热领域受益于AI驱动,单机柜功率高速增长也催生新技术应用。
一、AI算力成大国博弈焦点,国内外算力链演绎不同投资逻辑
根据2023中国算力大会公布的数据,截至目前,中国算力总规模达到每秒1.97万亿亿次浮点运算,位居全球第二,其中智能算力规模占比25.4%,同比增长45%。工信部发布的《算力基础设施高质量发展行动计划》指出,未来三年,中国算力规模计划超过300EFLOPS,智能算力占比达到35%。

各国计算力指数及排名
相比之下,美国在计算能力和计算效率方面具有较大优势,其基础设施支持也非常发达。超大规模数据中心建设维持全球第一,而中国的云计算普及水平紧随其后,互联网企业在公有云上的投入不断扩大,推动了超大规模数据中心的快速发展。
AI算力需求主要来自大模型训练和推理,在AI军备竞赛下,芯片供应成为核心矛盾。美国和中国AI竞争表现在英伟达和华为AI算力产业链上,主要包括算力租赁、AI服务器、交换机、光模块和散热等环节。
以英伟达为代表的GPU占据AI芯片主流市场,需求升级和头部芯片厂商产品创新引领AI算力链的产业变革。AI算力硬件技术架构呈现几个趋势:计算集群是必然趋势,包括计算、存储和网络通信功能;CPU+xPU异构方案成为标配;算力升级有多个路径,英伟达GPGPU持续迭代,包括DSA技术、引入HBM,通过近存计算架构提升数据吞吐速率;网络互连是算力性能的重要瓶颈,持续向高带宽、低时延方向发展。华为算力产品线聚焦于鲲鹏、昇腾基础软硬件创新,昇腾系列处理器包括昇腾310和昇腾910,分别用于电子终端和高端服务器及云计算。
二、数据中心:云边协同成为新触角,超算性能提升显著
1、行业发展现状:智能算力占比迅速提升
全球数据中心市场规模持续扩大,我国数据中心市场规模在19-21三年内以31%的年复合增长率稳步增长。根据工信部数据,截至2021年底,我国在用数据中心机架总规模超过520万标准机架,平均上架率超过55%。其中,大型规模以上数据中心规模机架数占总机架数的比例在2021年已超过80%。
全球算力规模正在迅速扩大,智能算力在其中占比逐渐提高。据信通院的测算,2021年全球计算设备算力总规模达到615EFlops,同比增长44%。其中,智能算力规模为232EFlops,占总算力的37.7%。预计到2030年,全球算力规模将以平均年增速65%的速度达到56ZFlops。2021年,我国的算力规模位列全球第二,达到202EFlops。其中,智能算力规模达到104EFlops,同比增长85%,在总算力中占比已超过50%,取代基础算力成为算力结构最主要构成。

中国大型规模以上数据中心机架规模
2、智能计算中心:AI将加速智算/超算数据中心建设
根据ICPA智算联盟的统计,截至2022年3月,全国已经投入运营的智能计算中心近20个,正在建设中的超过20个。中国超级计算机性能在过去二十年中取得显著的提升,增长4万多倍。根据中国计算机学会HPC专业委员会的统计,2022年6月实测超算算力达到530,240,332 GFlops,目前超算算力是平台最主要应用构成。

我国智能算力规模(单位:EFLOPS)及预测,EFLOPS 为每秒浮点运算次数
大模型训练需要大量智能算力。例如,千亿参数的盘古大模型训练使用2000多块昇腾910,持续两个多月。据OpenAI统计,自2012年以来,随着深度学习模型的演进,模型计算所需计算量增长30万倍。华为预测,未来十年人工智能算力需求将增长500倍以上。IDC预测,到2026年,中国智算规模预计达到1271.4EFLOPS(FP16),2022-2026年CAGR达到47.58%。

智算中心产业链
3、AI背景下行业新趋势:云边协同成为新触角
边缘计算作为平台技术,为5G、物联网、机器人、人工智能等新兴技术提供重要的承载能力。据IDC预计,未来五年,全球边缘计算服务器支出占比将快速增长,到2025年将从14.4%提升到24.9%。边缘计算产品形态和底层架构正在走向多样化,定制服务器产品可能会成为边缘计算基础设施主力军。
边缘计算在数据、模型、任务调度方面与云端计算协同,以降低时延和提高效率。根据《中国互联网发展报告2022》发布数据,我国云计算市场规模正在快速增长,2021年已达到3229亿元,同比增长54.4%。然而,由于终端产生大量数据,全部由云端处理会导致极高的通信时延。通过云边协同融合云计算可以提高效率,同时具备边缘计算低时延的优点。
在数据方面,边缘节点负责数据采集,对实时数据进行处理,并将数据上传至云节点进行处理和存储复杂数据;
在任务调度方面,云节点下发管理策略,边缘节点则分配资源并执行;
在模型方面,云节点完成全局模型训练后下发边缘节点,边缘节点进行本地训练及推理。

云边协同总体架构
4、AI算力租赁:供需失衡下的新生态,向云发展
算力租赁业务发展原因与其他租赁业务相似,主要是由于供需不匹配问题。随着人工智能模型在办公、法律、医疗、金融等各个领域的广泛应用,尤其是在年初ChatGPT的推动下,我国大模型开发数量不断增加。根据赛迪顾问发布报告,截至7月底,我国已研发大模型数量达到130个,外国已发布大模型数量为138个。然而,对于许多企业来说,主要缺乏足够的算力来支持大模型训练和推理,因此对于算力需求非常庞大。而另一方面,算力供给是有限的,并且获取算力的及时性对于企业在业务开发中能否获取先发优势至关重要。因此,算力租赁业务应运而生。

不同类型厂商的业务模式总结
三、 ICT设备: AI服务器需求扩容,网络设备同步升级
1、AI服务器:需求提速,占比提升
近五年,全球服务器市场格局相对稳定,新华三/HPE、戴尔、浪潮及联想主导市场。华为因制裁退出X86服务器市场后,超聚变有望接管其空缺。同时,ODM厂商如超微、广达、仁宝及鸿海精密等因定制化需求增长,市场份额也有所提升。在中国市场,2021年浪潮以30.7%领先,新华三/HPE、戴尔、联想、华为分别以17.5%、7.5%、7.4%及6.6%(2020年19.2%)位列二至五位。

AI服务器与通用服务器区别
2 、交换机:智算中心网络要求提升,带动交换机升级和需求增长
智算中心作为新型基础设施,旨在提供更大的计算规模和更快的计算速度,以支持AI计算。区别于传统数据中心,智算中心更加注重单位时间单位能耗下的运算能力及质量。智算中心将算力资源全面解耦,以实现计算、存储资源的极致弹性供给和利用。智算中心网络作为连接CPU、GPU、内存、存储等资源的重要基础设施,贯穿数据计算、存储全流程。因此,网络性能成为提升智算中心算力的关键要素。智算中心网络向超大规模、超高带宽、超低时延、超高可靠等方向发展。

英伟达 DGX SuperPOD 的数据中心集群互联方案
全球以太网交换机市场在2022年取得稳步增长,达到365亿美元,同比增长18.7%。其中,第四季度市场规模同比增长22.0%,达到103亿美元。这一增长既源于供应链短缺情况持续缓解,也归功于云厂商和企业端不断扩大以太网交换容量需求。预计2023年国内以太网交换机市场规模将达到66.2亿美元,同比增速为9.4%。
四、散热领域:IDC与储能双核推动,液冷技术加速渗透
1、AI催化数据中心液冷应用加速
随着数据流量高速增长,数据中心建设正在加速。5G的全面商用以及AIGC和ChatGPT的兴起将极大地推动数据存储和计算需求。根据IDC和Seagate的联合预测,全球数据流量将从2018年的33ZB增长到2025年的175ZB。其中,我国的数据流量预计将持续增长7年,在2025年之前成为全球数据流量最高地区,CAGR达到30%以上。数据流量的持续增长将推动数据中心的持续建设。

全球数据流量高速增长
受制于选址成本和传输距离的物理极限,单机柜功率高速增长。我国网络环境是典型中心化网络,围绕珠三角、长三角、京津冀等人口稠密、经济发达中心地区密集分布。由于大型城市用地紧张,在一线城市周边地区建设数据中心用地成本过高。但是,在中心地区向周边地区的延伸过程中,网络延迟问题随着数据传输距离的延长愈发严重,因此,提高单机柜功率和增加机柜陈列密度以最大程度利用建筑面积成为解决方案。

全球数据中心单机柜变化情况及预测
随着AI大模型发展,高功率服务器需求增加,导致高能耗,因此液冷渗透率有望提升。单机柜功率上涨和排列密度提高使得传统风冷无法满足散热需求。为提高运算能力,CPU厂商采用叠加多核处理器方式,导致发热功耗显著增加。传统风冷通常只能解决3-5KW/机柜散热需求,但新建单机柜功率普遍超过15KW。相比之下,液冷成为主流方案,因为其适用于高机柜部署密度场景。传统风冷技术更适用于气候干燥、全年温度较低地区,而液冷在数据中心选址方面具有较大优势。CPU能耗和PUE要求的提高将推动液冷技术持续迭代。

英特尔 CPU 功率估算
2、储能液冷温控市场空间广阔,2023年是市场入局关键
液冷技术在储能温控领域应用虽然目前渗透率较低,但具有巨大的增长潜力。目前,液冷系统价值量高于风冷系统,但成本较高。然而,随着技术进步和市场发展,液冷技术在储能温控市场份额有望持续增长。根据GGII数据,预计到2025年,我国液冷储能市场将从2022年7.0亿元增长至74.1亿元,CAGR达到83.1%,市场占有率将从15.0%上升至45.0%。此外,全球电化学储能投资额高速增长和新型储能装机量的逐步攀升也将推动储能系统产热量的不断上升,为储能温控系统带来新的发展机遇。根据测算,储能温控全球市场规模预计将从21年的9.4亿元增长到25年的111亿元。因此,液冷技术在储能温控领域前景十分广阔。

储能温控系统规模测算
如何打造互联卫星网平台?
随着科技的飞速发展,卫星互联网正在成为全球通信网络的重要支柱。然而,要实现高效、稳定的卫星互联网平台,算力成为了关键因素。下面将从算力角度出发,探讨如何打造一个强大的卫星互联网平台。
一、卫星互联网对算力的要求主要体现在以下几个方面:
1、卫星发射数量和卫星互联网产业化程度
中国低轨卫星发射数量较少,卫星互联网产业化程度相对较低。随着卫星互联网的不断深化,相关领域的头部龙头企业,特别是核心技术壁垒较高的企业有望优先收益,带来经营业绩的边际改善。
2、卫星核心网业务和地面组网业务
在卫星互联网领域,主要提供卫星核心网业务,同时针对卫星组网业务也已加速布局。未来,将从地面组网业务、卫星组网业务以及卫星的接入终端业务三个方面积极、全面地参与到卫星互联网行业中。
3、终端直连技术
手机直连卫星是卫星互联网与地面蜂窝网融合发展的基础。手机直连技术需要增加卫星天线发射功率、相控阵天线面积大幅增加,并降低通信频率、提高星上处理能力,以解决手机发射功率不足、天线增益不够的问题。
二、优化数据处理流程
在卫星互联网平台中,数据处理是一项关键任务。通过优化数据处理流程,可以提高数据处理效率,减少计算资源消耗。例如,可以采用分布式数据处理技术,将数据分发到多个计算节点上进行并行处理,从而提高数据处理速度。
三、引入人工智能技术
人工智能技术在卫星互联网领域具有广泛的应用前景。通过引入人工智能技术,可以实现更智能的数据分析和网络管理。例如,利用人工智能技术对网络进行优化,提高网络的性能和稳定性;同时还可以利用人工智能技术对卫星进行智能控制,实现更高效的卫星互联网服务。
四、考虑可扩展性和灵活性
随着卫星互联网不断发展,对算力的需求也将不断增加。因此,在构建卫星互联网平台时,需要考虑可扩展性和灵活性。采用模块化设计方法,将平台划分为多个可扩展模块,可以根据需求灵活地增加或减少计算资源,以满足不断变化的业务需求。
五、加强网络安全保障
算力不仅关乎平台性能和效率,还与网络安全息息相关。在构建卫星互联网平台时,需要加强网络安全保障,确保平台免受攻击和数据泄露等风险。采用先进加密技术和安全防护措施,可以有效保障平台的安全性和稳定性。
六、蓝海大脑液冷工作站助力构建卫星互联网平台
为解决繁琐且效率较低的人工作业工作模式,突破图像分析精准度和工作效率的瓶颈。蓝海大脑通过多年的努力,攻克了各项性能指标、外观结构设计和产业化生产等关键技术问题,成功研制出蓝海大脑液冷工作站。具有图形处理速度快,支持GPU 智能运算,高性价比高及外形美观等特点,满足了人工智能企业对图形、视频等信息的强大计算处理技术的需求。
快速、高效、可靠、易于管理的蓝海大脑液冷工作站具备出色的静音效果和完美的温控系统。在满负载环境下,噪音控制在 35 分贝左右。借助英伟达 NVIDIA 、英特尔Intel、AMD GPU显卡可加快神经网络的训练和推理速度,更快地创作精准的光照渲染效果,提供高速视频和图像处理能力,加速AI并带来更流畅的交互体验。
1、蓝海大脑液冷工作站产品性能
可 靠 性:平均故故障间隔时间MTBF≥15000 h
工作温度:5~40℃
工作湿度:35%~ 80%
存储温度:-40~55℃
存储湿度: 20%~90%
声噪:≤35dB
2、配置清单
1)CPU:
- Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
- Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
- AMD EPYC™ 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
- AMD EPYC™ 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
- Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
- Intel Xeon Gold 6240R 24C/48T,2.4GHz,35.75MB,DDR4 2933,Turbo,HT,165W.1TB
- Intel Xeon Gold 6258R 28C/56T,2.7GHz,38.55MB,DDR4 2933,Turbo,HT,205W.1TB
- Intel Xeon W-3265 24C/48T 2.7GHz 33MB 205W DDR4 2933 1TB
- Intel Xeon Platinum 8280 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W 1TB
- Intel Xeon Platinum 9242 48C/96T 3.8GHz 71.5MB L2,DDR4 3200,HT 350W 1TB
- Intel Xeon Platinum 9282 56C/112T 3.8GHz 71.5MB L2,DDR4 3200,HT 400W 1TB
2)GPU:
- NVIDIA A100, NVIDIA GV100
- NVIDIA L40S GPU 48GB
- NVIDIA NVLink-A100-SXM640GB
- NVIDIA HGX A800 80GB
- NVIDIA Tesla H800 80GB HBM2
- NVIDIA A800-80GB-400Wx8-NvlinkSW
- NVIDIA RTX 3090, NVIDIA RTX 3090TI
- NVIDIA RTX 8000, NVIDIA RTX A6000
- NVIDIA Quadro P2000,NVIDIA Quadro P2200
3)硬盘
- NVMe.2 SSD: 512GB,1TB;M.2 PCIe - Solid State Drive (SSD)
- SATA SSD: 1024TB, 2048TB, 5120TB
- SAS:10000rpm&15000rpm,600GB,1.2TGB,1.8TB
- HDD : 1TB,2TB,4TB,6TB,10TB
3、产品特点
1)开放融合
- 融合计算、网络、存储、GPU、虚拟化的一体机
- 支持主流虚拟化平台,如Vmware、Redhat、Microsoft Hyper-V等虚拟化平台
- 支持在线压缩、重复数据自动删除 、数据保护、容灾备份以及双活等功能
2)超能运算
- 支持主流GPU显卡虚拟化,支持2、8、16块全高全长卡或32、64块半长卡,提高计算性能和图像渲染能力
- 快速实现系统扩展,支持大规模并发运行(百万个理论节点)
3)高效运维
- 一站式部署,开箱即用,助力企业快速实现业务转型。
- 强大的数据、网络、虚拟化及管理安全保障, 提高系统可靠性和高可用性

4、解决方案价值
1)采用NVIDIA 专业显卡,加快神经网络的训练和推理速度,实现精准的光照渲染效果,提供高速视频和图像处理能力,加速深度学习训练、推理并带来更流畅的交互体验。
2)低碳节能,降低噪音,提升创造效率。
3)经过严格测试,可在苛刻的工作环境下确保耐用性和可靠性。