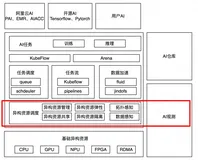
引言
随着人工智能(AI)、大数据分析以及高性能计算需求的不断增长,图形处理器(GPU)因其卓越的并行计算能力而成为加速这些领域的关键技术。GPU算力平台不仅能够显著提升计算效率,还能帮助企业更好地处理大规模数据集,支持复杂的机器学习模型训练,并促进实时数据分析。本文将探讨GPU算力平台在数字化转型中的核心作用,并通过示例代码展示其在实际应用中的优势。
GPU算力平台的重要性
- 并行处理能力:GPU拥有数千个计算核心,可以同时执行大量并行计算任务,非常适合处理密集型计算工作负载。
- 内存带宽:GPU具有高带宽内存,能够快速访问大量数据,这对于数据密集型应用至关重要。
- 可扩展性:通过构建多GPU系统或利用云服务,可以轻松扩展计算资源以满足不同规模的需求。
GPU在数字化转型中的应用场景
深度学习与机器学习:
- 训练复杂的神经网络模型。
- 加速图像识别、自然语言处理等任务。
高性能计算(HPC):
- 气象模拟、分子动力学等科学计算。
- 金融风险建模与量化交易。
大数据分析:
- 实时流处理。
- 大规模数据库查询优化。
图形渲染与虚拟现实:
- 高质量的3D图形渲染。
- 虚拟现实(VR)和增强现实(AR)体验。
示例代码:使用PyTorch进行简单的线性回归
为了说明GPU如何加速深度学习任务,我们将使用Python中的PyTorch库实现一个简单的线性回归模型,并比较在CPU和GPU上的性能差异。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import numpy as np
# 设定随机种子以确保结果的可重复性
torch.manual_seed(1)
# 创建简单数据集
X = Variable(torch.Tensor(np.random.rand(100, 1)).float(), requires_grad=False)
y = Variable((2 * X + 1).float(), requires_grad=False)
# 定义线性回归模型
class LinearRegression(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
# 初始化模型
input_dim = 1
output_dim = 1
model = LinearRegression(input_dim, output_dim)
# 将模型移动到GPU上(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 设置损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
outputs = model(X.to(device))
loss = criterion(outputs, y.to(device))
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 100 == 0:
print(f'Epoch: {epoch+1}, Loss: {loss.item()}')
# 输出最终权重
print('Final Weights:', list(model.parameters()))
结论
GPU算力平台凭借其出色的并行处理能力和高内存带宽,在加速数字化转型过程中扮演着不可或缺的角色。从科学研究到商业决策,GPU的应用范围广泛且日益扩大。随着技术的进步,未来GPU将继续作为推动社会生产力新飞跃的关键因素。
通过上述示例代码,我们可以看到GPU对于加速深度学习模型训练的显著效果。随着硬件技术的发展,GPU算力平台将在未来的数字化转型中发挥更加重要的作用。