
车牌识别基础功能演示

摘要:
车牌识别系统(Vehicle License Plate Recognition,VLPR)是指能够检测到受监控路面的车辆并自动提取车辆牌照信息(含汉字字符、英文字母、阿拉伯数字及号牌颜色)进行处理的技术。车牌识别是现代智能交通系统中的重要组成部分之一,应用十分广泛。本文详细介绍了车牌识别技术的基本实现原理,并且基于python与pyqt开发了一套功能完整的车牌识别的停车场管理系统软件,实现了通过图片或者摄像头的方式进行进出停车场车辆车牌自动识别、车牌登记信息录入、已登记车辆有效期时间管理、车辆进出记录管理以及外来车辆收费系统等功能。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
1. 前言
车牌识别系统(Vehicle License Plate Recognition,VLPR) 是指能够检测到受监控路面的车辆并自动提取车辆牌照信息(含汉字字符、英文字母、阿拉伯数字及号牌颜色)进行处理的技术。车牌识别是现代智能交通系统中的重要组成部分之一,应用十分广泛。它以数字图像处理、模式识别、计算机视觉等技术为基础,对摄像机所拍摄的车辆图像或者视频序列进行分析,得到每一辆汽车唯一的车牌号码,从而完成识别过程。
车牌识别技术主要应用领域有停车场收费管理,交通流量控制指标测量,车辆定位,汽车防盗,高速公路超速自动化监管、闯红灯电子警察、公路收费站等等功能。对于维护交通安全和城市治安,防止交通堵塞,实现交通自动化管理有着现实的意义。
博主根据车牌识别技术开发了本文中介绍的一套功能完整的停车场收费与车辆管理系统,功能主要包括:进出停车场车辆车牌自动识别、车牌登记信息录入、已登记车辆有效期时间管理、车辆进出记录管理以及外来车辆收费系统等功能。
基于该车牌识别技术,博主经过长时间开发,总共写了近3000行代码,并且整个系统经过了详细的调试修改。最终开发了本文介绍的车牌识别停车场管理系统软件【python与PYQT5]】,功能主要包括:进出停车场车辆车牌自动识别、车牌登记信息录入、已登记车辆有效期时间管理、车辆进出记录管理以及外来车辆收费系统等。
觉得不错的小伙伴,感谢点赞、关注加收藏哦!更多干货内容持续更新…
登录后的软件初始界面如下图所示:

2. 软件核心功能介绍及效果演示
软件主要功能包括以下几个部分:
1. 登录注册模块:提供系统的登录注册功能;
2. 车辆信息登记录入模块:用于进行特殊车辆、月租车辆或业主车辆的信息管理,登记指定日期内车辆进出不收费,过期后正常收费;
3. 车牌进出识别模块:用于识别停车场出入车辆的车牌信息,同时记录出入时间,并显示出入信息、收费信息、停车场车位数量信息;
4. 已登记录入车辆信息管理模块:对已录入的车辆信息进行搜索、修改、删除等管理;
5. 车辆进出信息管理模块:记录车辆进出信息、并对进出车辆进出信息搜索、删除等管理
6. 自动收费模块:能够依据记录的出入时间自动计算出入车辆的需要缴纳的费用。
下面将详细介绍各个模块的基本功能:
2.1 登录注册功能模块
本软件提供了基础的登录注册功能,对于新用户需要先注册账号才可以进行登录。界面如下:

2.2 车辆信息登记录入功能模块
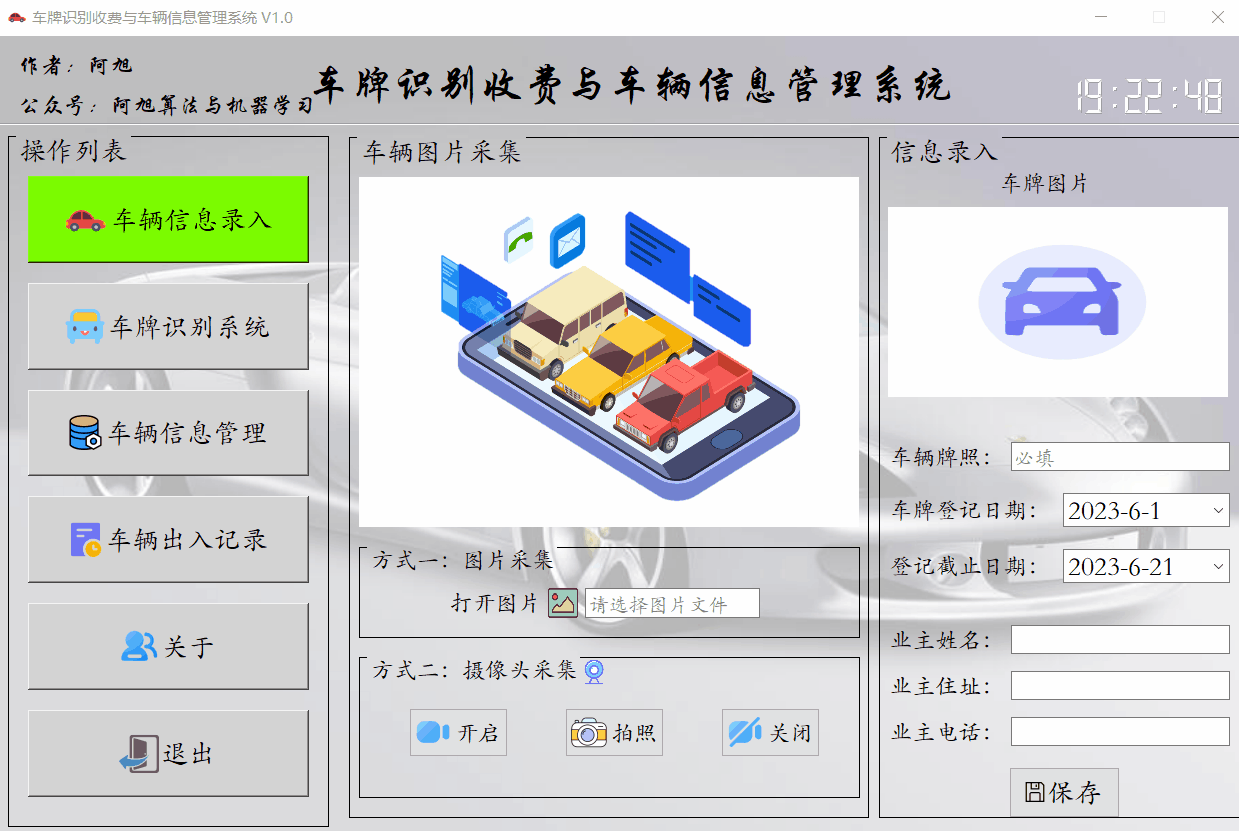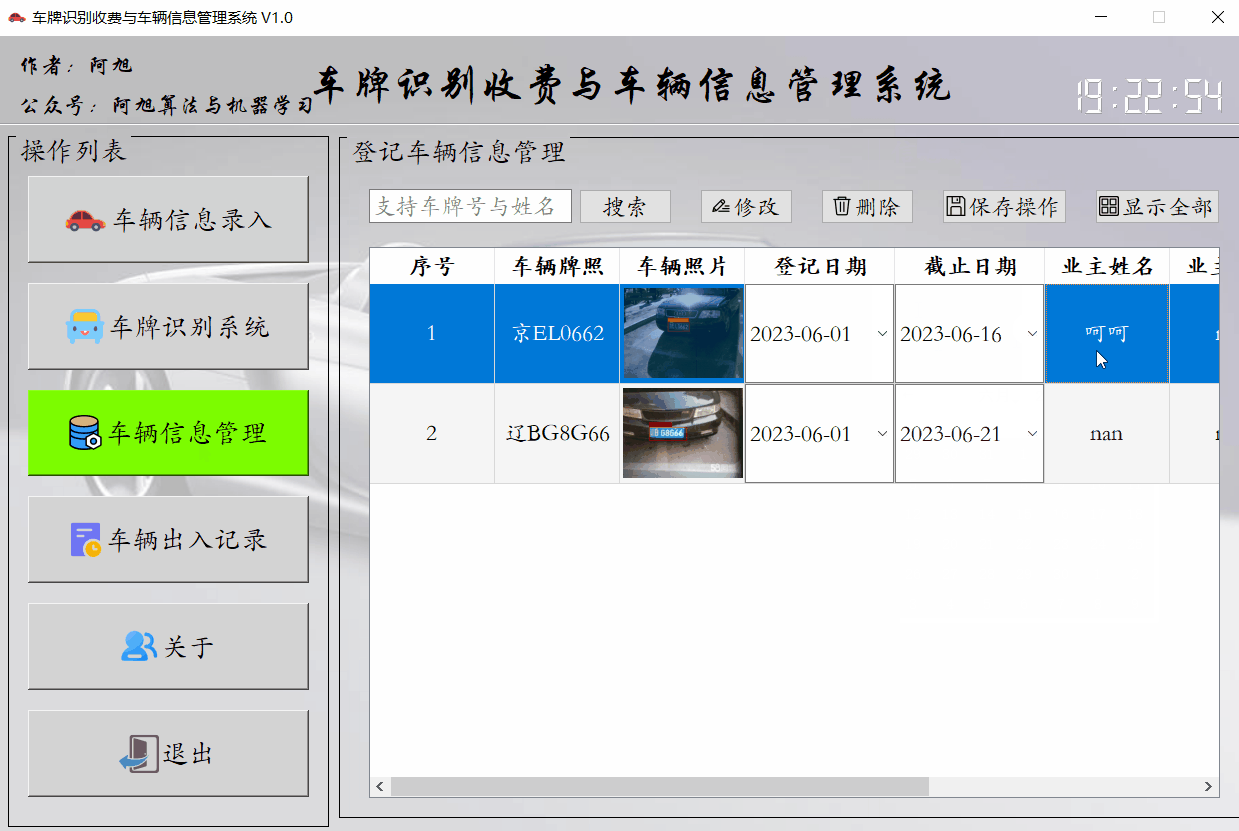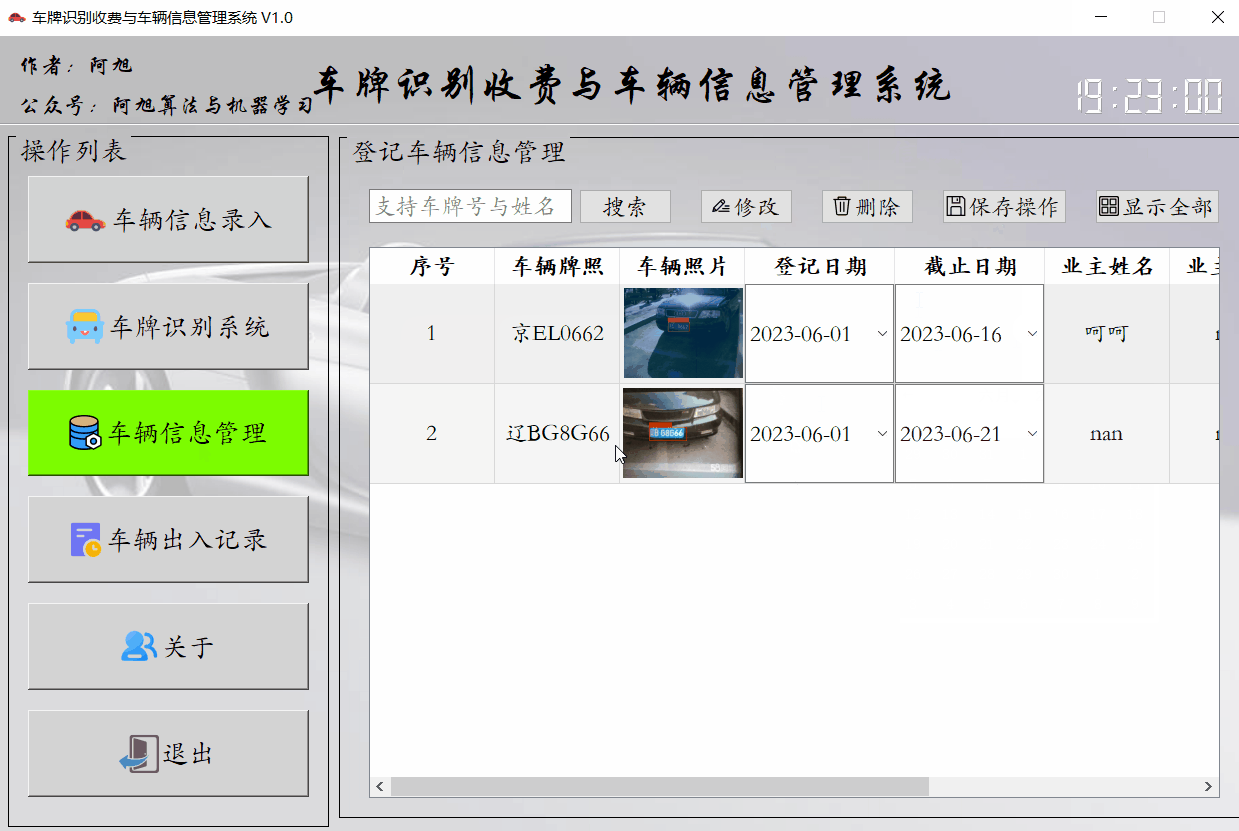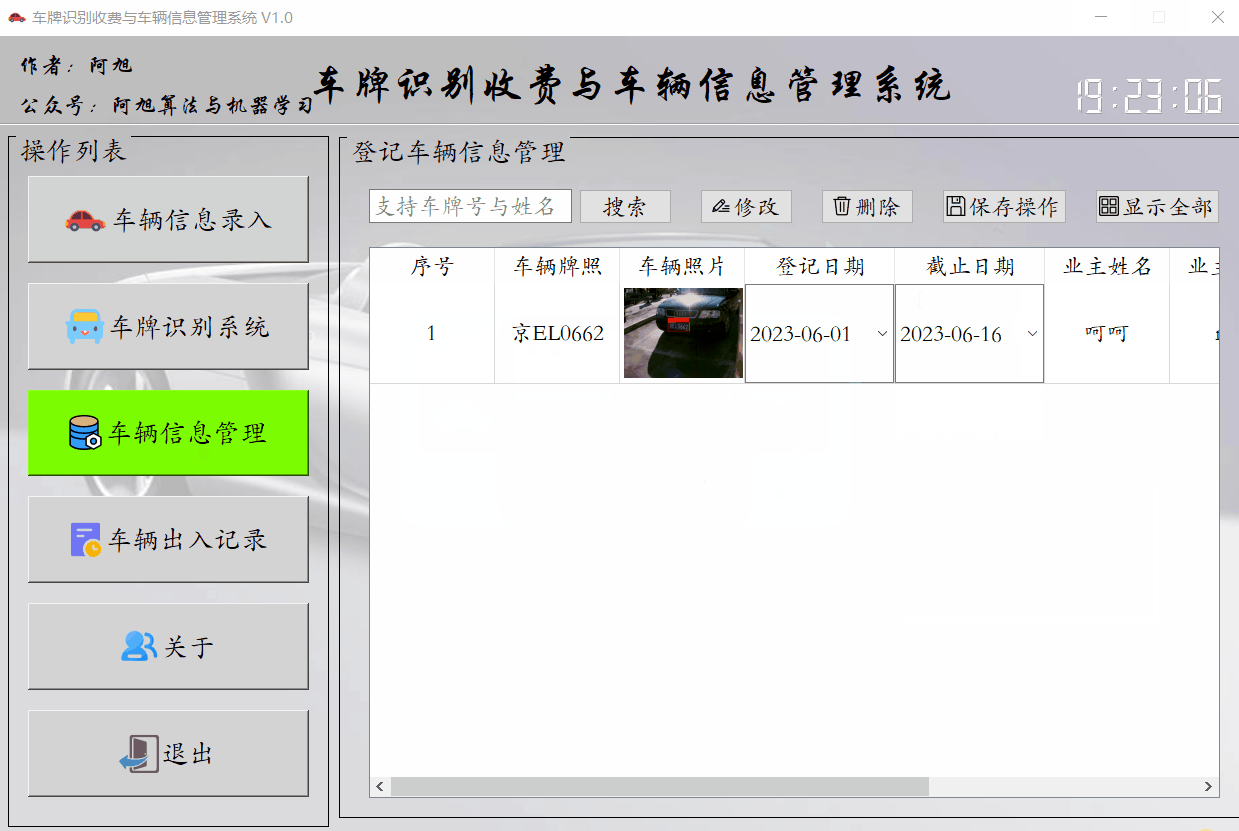
车辆信息登记录入功能的主要作用是对特殊车辆、月租车辆或业主车辆进行信息管理,车辆在登记日期区间内,可以免费进出停车场,但是过期后需正常缴费。可在信息管理界面修改日期信息。
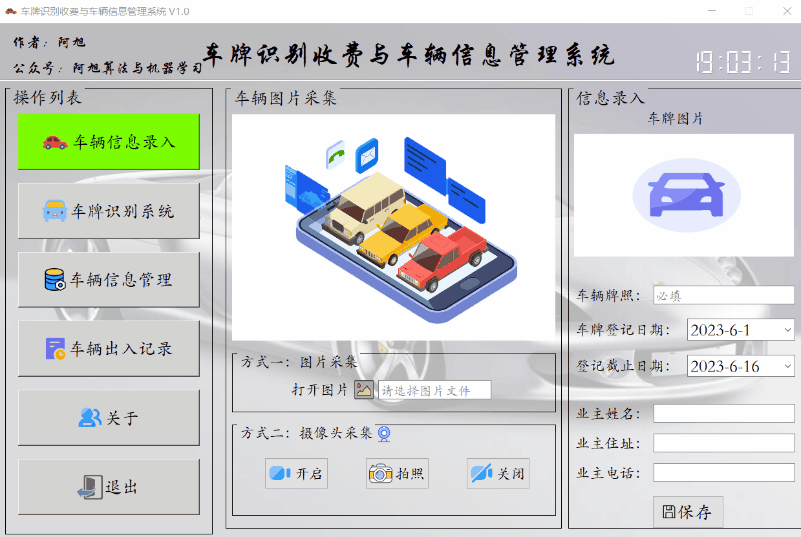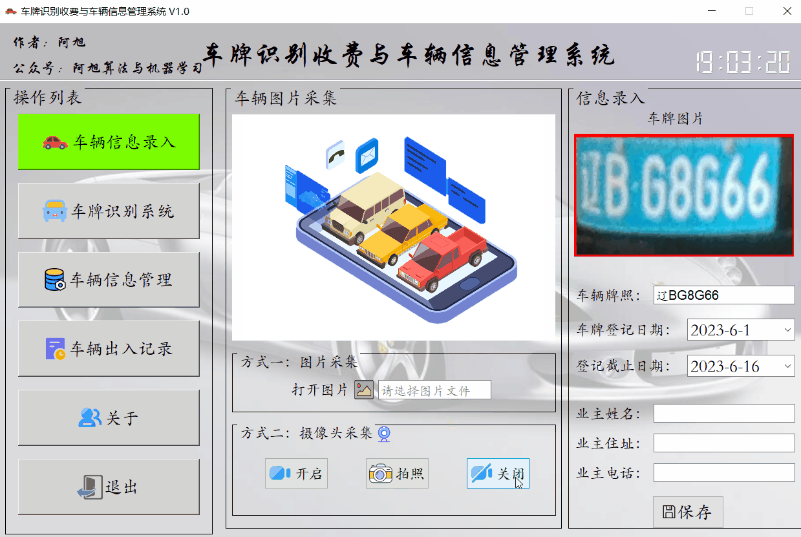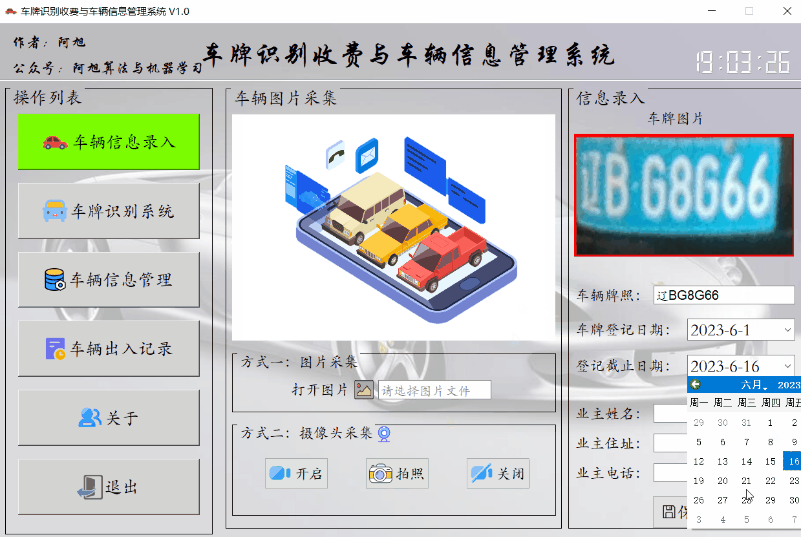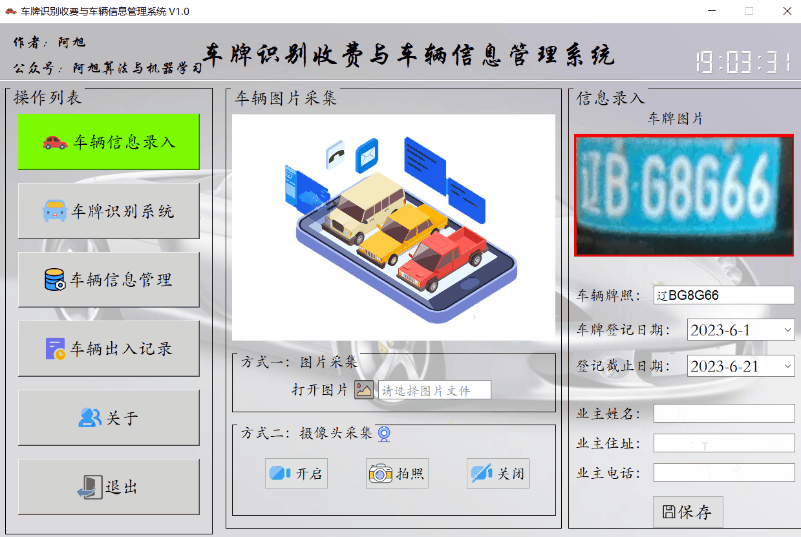
车辆登记需要进行照片采集,可通过上传照片或者摄像头拍照的这两种方式进行采集,车牌会自动识别填入文本框内。然后选择车辆登记有效日期,选填人员信息等内容。点击保存按钮,即可将信息保存至数据库中。采集的车辆图片会默认存入data/imgs目录中,命名方式为车牌号.jpg。
车牌信息登记的初始界面如下:

上传图片方式采集车辆图片方式如下:

摄像头采集车辆图片方式如下:
先开启摄像头,车辆处于合适位置后,点击拍照按钮采集,点击关闭摄像头按钮即可。
采集后的车辆图片存储位置data/imgs目录下:

2.3 车牌识别车辆出入及收费系统模块
可通过图片或者摄像头的方式,对出入的车辆进行车牌识别。并显示车辆信息,收费信息,停车场车位数目等。并且可以通过单选按钮来模拟车辆的进出,从而显示不同的出入信息。
费用计算方式:费用计算:不足半小时免费,超过每小时5元,不足1小时按1小时算,每24小时20元封顶。
图片方式来模拟车辆的进入与外出:
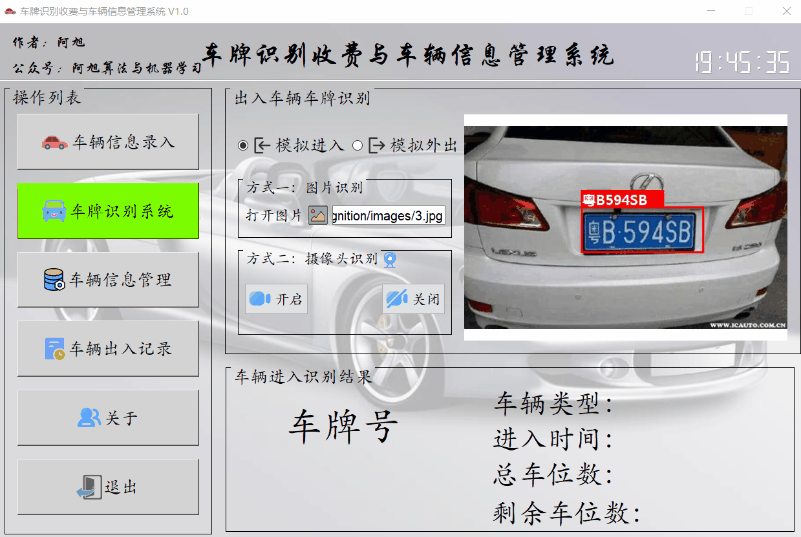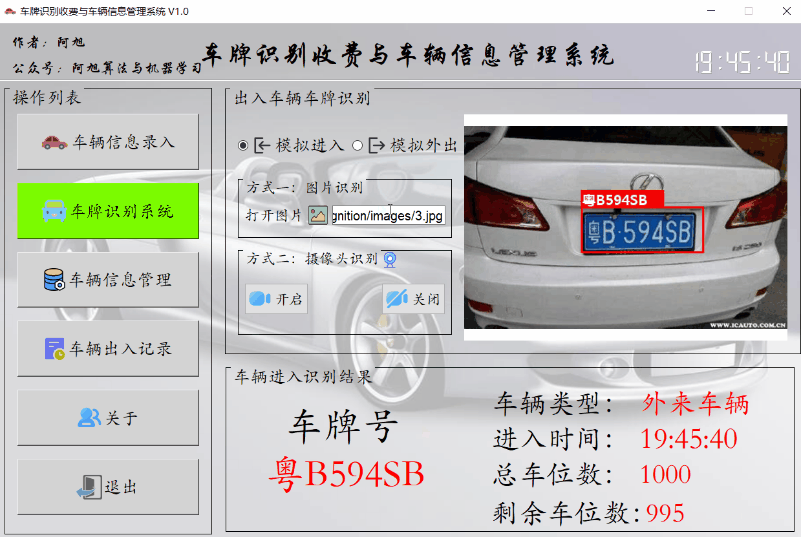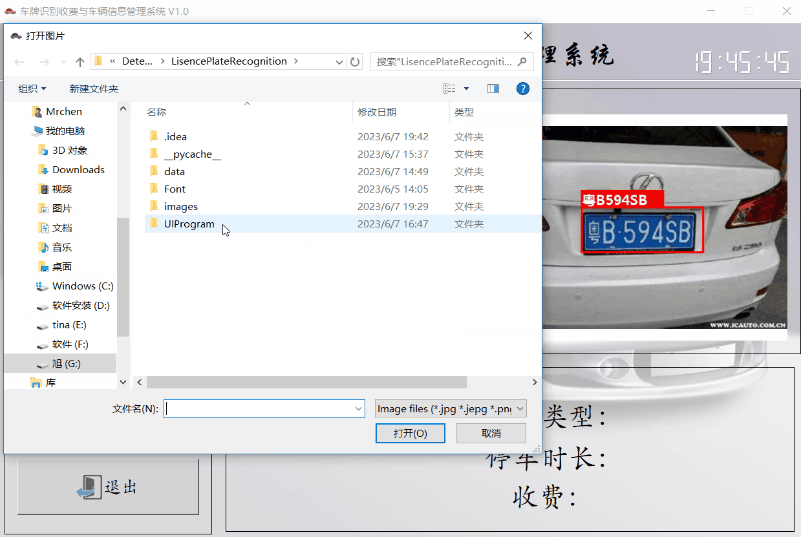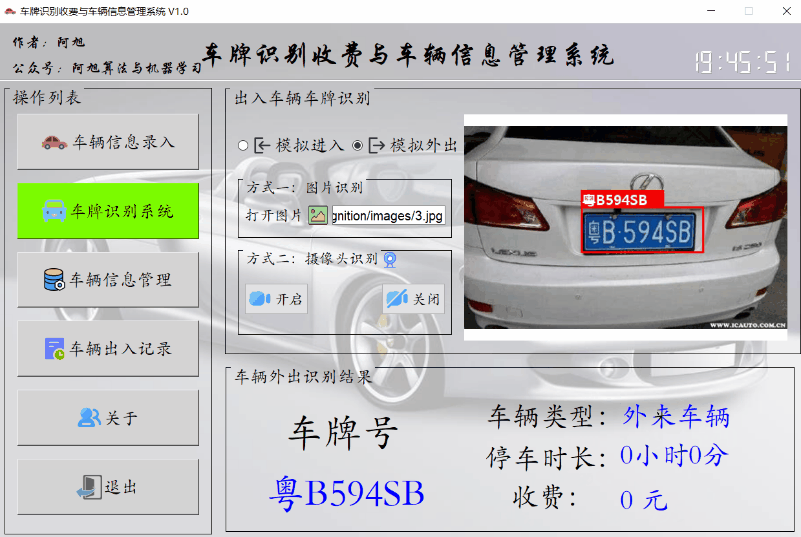
车辆进入显示的信息如下:

车辆外出显示信息如下:
注:登记车辆会显示登记剩余天数,外来车辆没有剩余天数显示。


摄像头方式来模拟车辆的进入与外出:

2.4 车辆信息数据管理模块
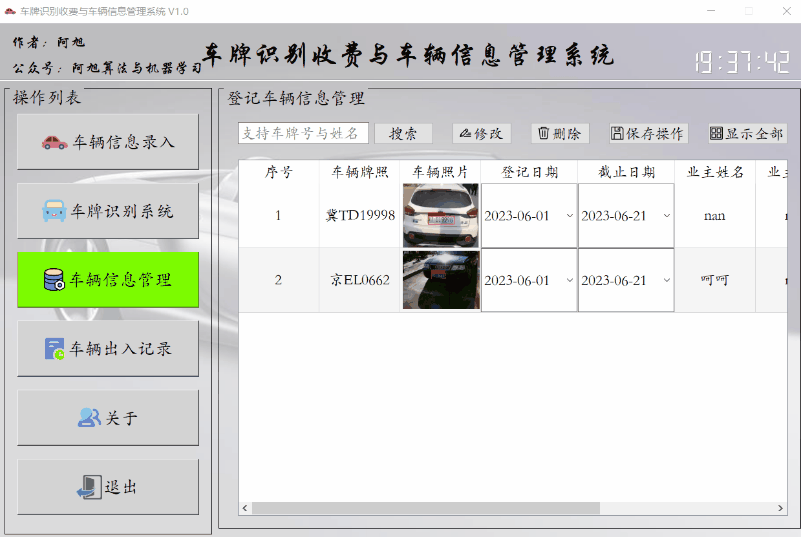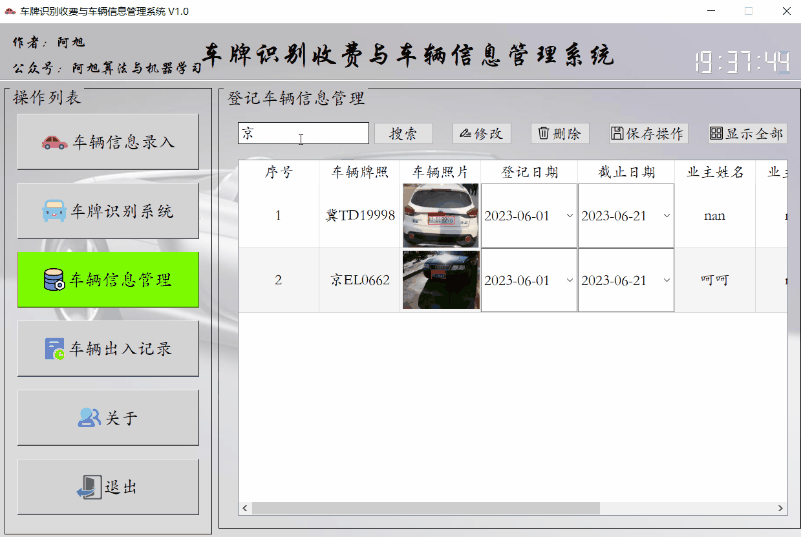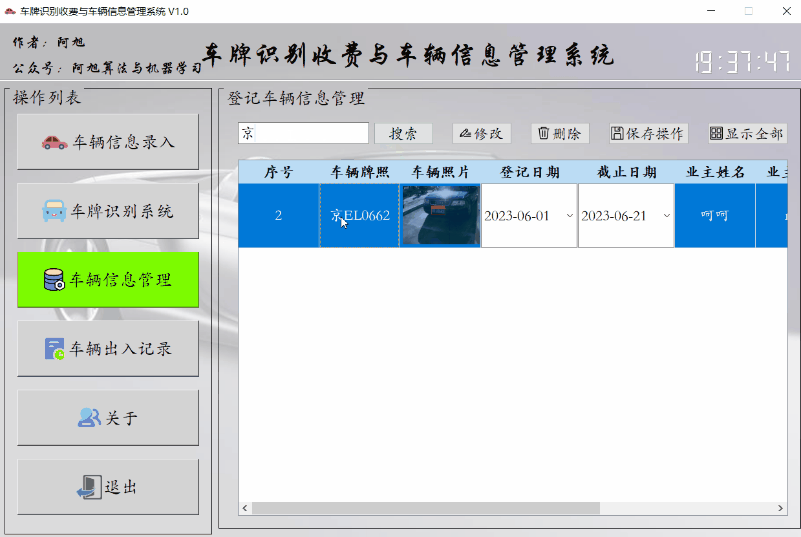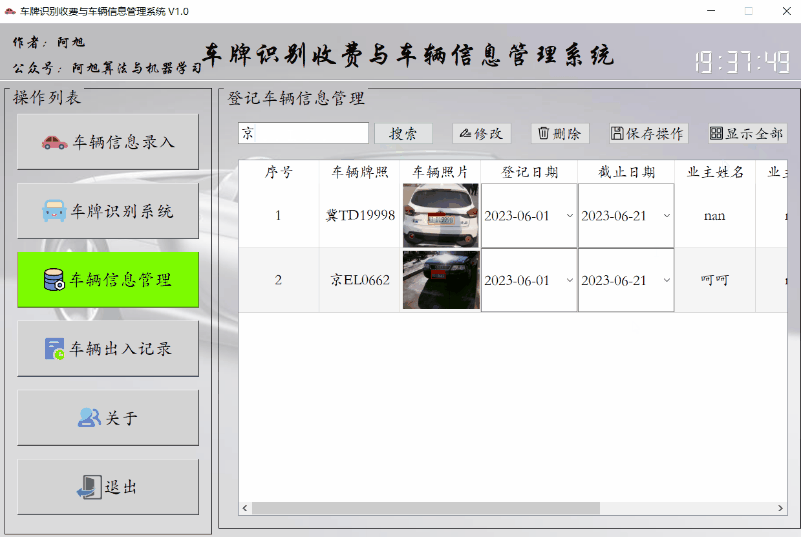
该界面主要是显示已登记的车辆信息,支持搜索及日期、业主信息等修改,以及信息删除功能。
功能展示如下:
搜索功能
修改、删除功能:
修改方法:双击表中的内容后,点击修改按钮,然后点击保存操作按钮,更新数据库。
删除方法:选中要删除的行,然后点击删除按钮,然后点击保存操作按钮,更新数据库。
显示全部按钮用于显示全部已录入的车辆信息。
2.5 车辆出入记录模块
该界面用于记录车辆的出入信息:包括车牌、出入时间、车辆类型。
支持搜索与删除信息功能。
**删除方法:**选中要删除的行,然后点击删除按钮,然后点击保存操作按钮,更新数据库。
功能展示如下:

3. 车牌识别基本原理介绍
3.1 基本原理
车牌识别系统(Vehicle License Plate Recognition,VLPR) 是指能够检测到受监控路面的车辆并自动提取车辆牌照信息(含汉字字符、英文字母、阿拉伯数字及号牌颜色)进行处理的技术。车牌识别技术应用十分广泛,它是以数字图像处理、模式识别、计算机视觉等技术为基础,对含有车辆号牌的图像进行分析处理,从而确定牌照在图像中的位置,并进一步提取和识别出文本字符,得到每一辆汽车唯一的车牌号码,从而完成识别过程。
车牌识别的常规处理过程流程包括:图像采集、图像预处理、车牌定位、字符分割、字符识别及结果输出等处理过程。如下图所示:

上述各个流程相辅相成,每个处理过程均须保证其高效和较高的抗干扰能力,只有这样才能保证识别功能达到满意的效果,其中车牌定位、字符分割及字符识别这三个步骤尤为重要。
车牌定位
车牌定位的主要工作是从静态图片或视频帧中找到车牌位置,并把车牌从图像中单独分离出来以供后续处理模块处理,车牌定位如下图所示:

车牌定位的本质就是车牌目标检测,目前车牌位置检测方法主要有以下两种:
【方法1】基于图形图像学的定位方法
该方法主要有以下几种方式:(1)基于颜色的定位方法,如彩色边缘算法、颜色距离和相似度算法等;(2)基于纹理的定位方法,如小波纹理、水平梯度差分纹理等;(3)基于边缘检测的定位方法;(4)基于数学形态的定位方法。
基于图形图像学的定位方法,容易受到外界干扰信息的干扰而造成定位失败。如基于颜色分析的定位方法中,如果车牌背景颜色与车牌颜色相近,则很难从背景中提取车牌;在基于边缘检测的方法中,车牌边缘的污损也很容易造成定位失败。外界干扰信息的干扰也会欺骗定位算法,使得定位算法生成过多的非车牌候选区域,增大了系统负荷。
【方法2】基于机器学习的定位方法
基于机器学习的方法有基于特征工程的定位方法和基于神经网络的定位方法等。例如通过opencv提供的基于haar特征的级联分类器,训练一个车牌定位系统。但该方法训练十分费时,分类定位的效率也较低。因此当前在目标定位方面,基于深度学习神经网络的方法是主流方法。深度学习的检测算法主要有Mobilene-SSD、YOLO-v5等,利用大批量的标注数据进行训练模型,然后利用训练好的模型进行车牌区域检测。
字符识别
当车牌区域被检测出来后,如何对这一区域中的字符进行识别,主要有两种思路:
【方法1】首先利用一系列字符分割的算法将车牌中的字符逐个分开,然后基于深度学习进行字符分类,得到识别结果;
【方法2】直接对车牌区域采用端到端的网络进行识别。
本文我们直接基于网络上开源的HyperLPR 高性能开源中文车牌识别框架,来进行车牌区域与字符识别,该方法支持支持python3,支持Windows Mac Linux 树莓派等。
具体使用方法如下:
【1】导入第三方库OpenCV和hyperlpr,并读取一张车牌图片调用架构中的车牌识别方法获得结果,示例代码如下:
#导入包 from hyperlpr import * #导入OpenCV库 import cv2 #读入图片 image = cv2.imread("2.jpg") #识别结果 print(HyperLPR_plate_recognition(image))
代码运行结果如下,包含了车牌字符:'京EL0662'、置信度值:0.9737052321434021、车牌位置坐标:[255, 196, 367, 236]、图片尺寸形状:【3, 518, 690】(3通道,高518,宽690)信息。
(1, 3, 518, 690) 255 196 367 236 [['京EL0662', 0.9737052321434021, [255, 196, 367, 236]]]
下面我们将车牌的识别结果信息显示在图片上,代码如下:
# coding:utf-8 # 导入包 from hyperlpr import * # 导入OpenCV库 import cv2 from PIL import Image, ImageDraw, ImageFont import numpy as np # 定义画图函数 def drawRectBox(image, rect, addText, fontC): """ 车牌识别,绘制矩形框与结果 :param image: 原始图像 :param rect: 矩形框坐标 :param addText:车牌号 :param fontC: 字体 :return: """ # 绘制车牌位置方框 cv2.rectangle(image, (int(round(rect[0])), int(round(rect[1]))), (int(round(rect[2]) + 15), int(round(rect[3]) + 15)), (0, 0, 255), 2) # 绘制字体背景框 cv2.rectangle(image, (int(rect[0] - 1), int(rect[1]) - 25), (int(rect[0] + 120), int(rect[1])), (0, 0, 255), -1, cv2.LINE_AA) img = Image.fromarray(image) draw = ImageDraw.Draw(img) draw.text((int(rect[0] + 1), int(rect[1] - 25)), addText, (255, 255, 255), font=fontC) imagex = np.array(img) return imagex # 读取选择的图片 image = cv2.imread('2.jpg') all_res = HyperLPR_plate_recognition(image) # 车牌标注的字体 fontC = ImageFont.truetype("Font/platech.ttf", 20, 0) # all_res为多个车牌信息的列表,取第一个车牌信息 lisence, conf, boxes = all_res[0] image = drawRectBox(image, boxes, lisence, fontC) cv2.imshow('RecognitionResult', image) cv2.waitKey(0) cv2.destroyAllWindows()
上述代码运行结果如下,可以看到车牌信息与方框被很好的标注在了图片上:

但是,在生活中,我们更多用到的是从视频中对车牌进行识别,因此我们只需要对视频的每一帧图片进行车牌识别检测,然后将检测信息绘制上去即可,核心代码如下:
# 读取摄像头 cap = cv2.VideoCapture(0, cv2.CAP_DSHOW) # 车牌标注的字体 fontC = ImageFont.truetype("Font/platech.ttf", 20, 0) while True: ref, frame = cap.read() if ref: # 识别车牌 all_res = HyperLPR_plate_recognition(frame) if len(all_res) > 0: lisence, conf, boxes = all_res[0] frame = drawRectBox(frame, boxes, lisence, fontC) cv2.imshow("RecognitionResult", frame) if cv2.waitKey(10) & 0xFF == ord('q'): break # 退出 else: break
识别结果如下:

以上便是关于车牌识别的基本原理介绍与代码演示。基于该车牌识别技术,最终博主经过长时间开发,总共干了近3000行代码,并且整个系统经过了详细的调试修改。最终开发了本文介绍的车牌识别停车场管理系统软件【python与PYQT5]】,能够基于车牌识别很好的实现进出停车场车辆车牌自动识别、车牌登记信息录入、已登记车辆有效期时间管理、车辆进出记录管理以及外来车辆收费系统等功能。
关于该停车系统的涉及到的完整源码、UI界面代码等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
本文涉及到的完整全部程序文件:包括python源码、UI文件、测试图片、视频等文件(见下图),均已打包上传,按说明配置好环境后,点击运行即可。
【pycharm打开项目界面如下】
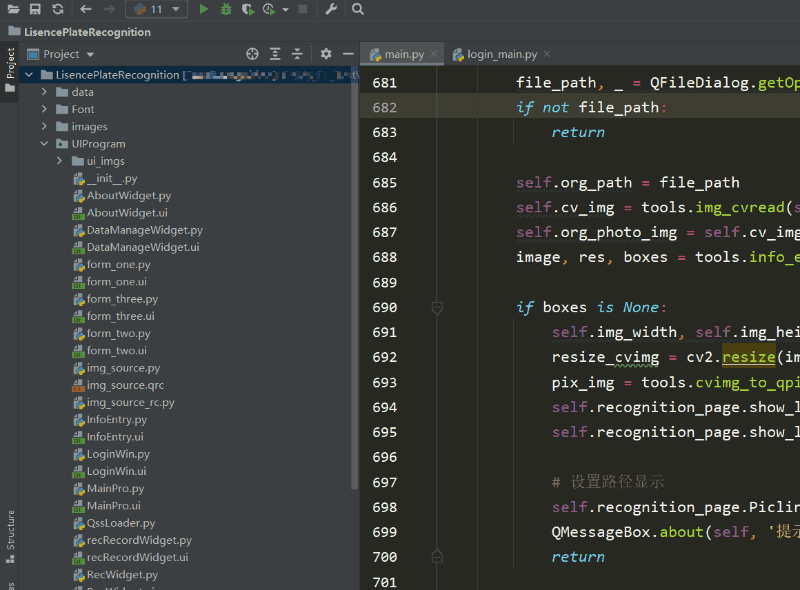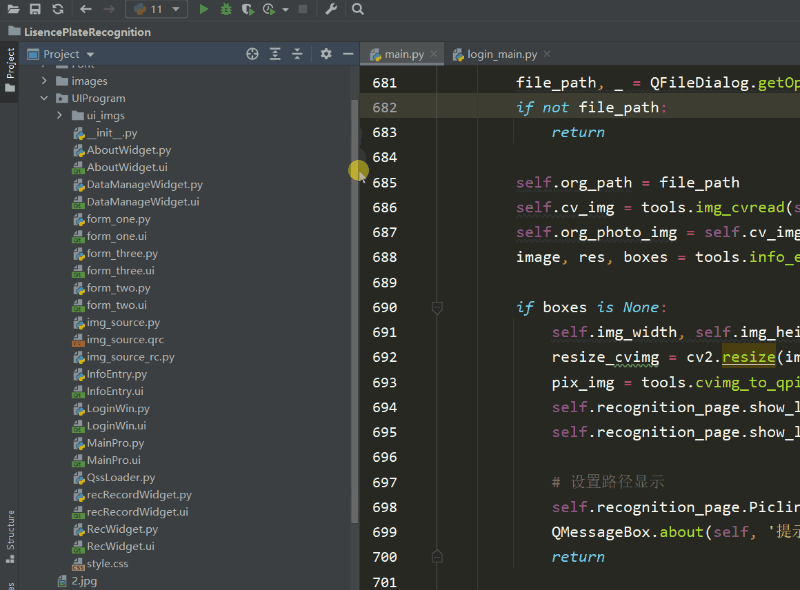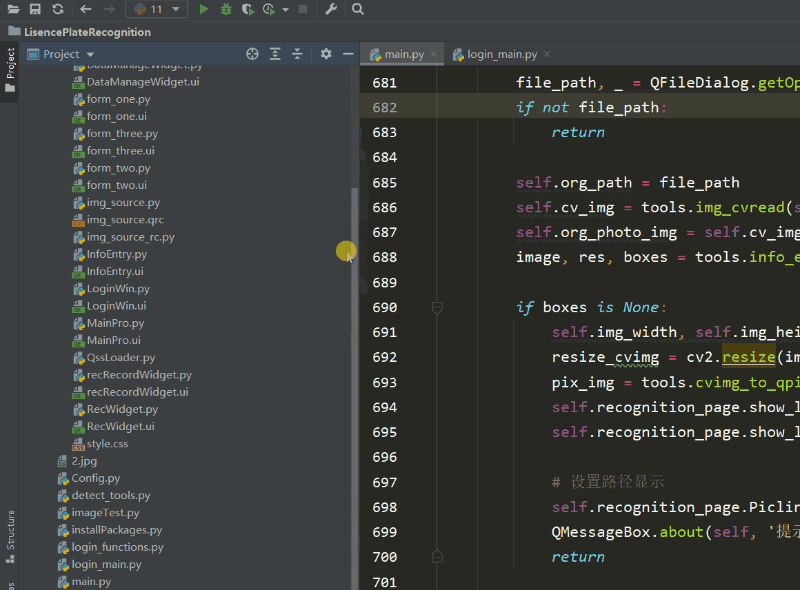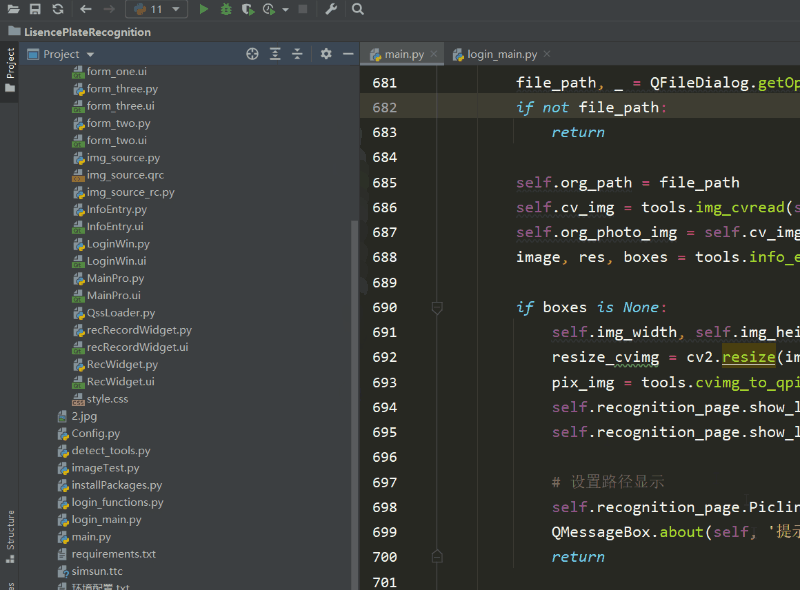
文件夹下的资源显示如下图:

注意:该代码采用Pycharm+Python3.8开发,运行界面的主程序为
main.py(不含登录界面);login_main.py(含登录界面)。为确保程序顺利运行,请按照环境配置.txt配置软件运行环境。
结束语
以上便是博主开发的关于基于OpenCV车牌识别停车场管理系统的全部内容,由于博主能力有限,难免有疏漏之处,希望小伙伴能批评指正

