
MaxCompute ODPS SQL费用估算与控制
作者:顾飞
一 需求背景
费用挑战
ODPS老用户应该都了解过其计费方式,如果不清楚计费方式,可以参考阿里云文章:https://help.aliyun.com/document_detail/27989.html?spm=5176.doc27833.6.701.8vl39E 。阿里云本身提供了CU(固定资源)和计算两种计费方式,而我们公司在BI上云的过程中使用的是采云间,它仅支持SQL计算计费方式步支持CU方式,而保险行业又是一个基于数据才能工作的行业, 每个部门都有自己的数据需求,在数据仓库之上的数据用户和应用又是非常的多,这使得我们在ODPS SQL费用控制上遇到了很大的挑战。刚开始3个月,我们的ODPS费用都是差好几倍,这与我们的业务增长两完全不符合。 在使用ODPS的前四个月我们面对如此大的费用差距,而我们的SQL 每个月都有几万次执行次数,几乎无从下手。
具体问题
1 遇到费用差距如此之大, 那我们就要去找到那些费用非常高的SQL, 我们根据阿里云提供的SQL 执行日志,发现很多SQL 运行一次要数千元, 很多都是LEFT JOIN没有做到分区过滤造成,比如:a left outer join b on a.id = b.id where a.pt= "${date}" and b.pt= "${date}",对于b表的分区过滤是失效的,造成sql的全表扫描,而需要将其改成: a left outer join (select * from b where b.pt= "${date}" ) b on a.id = b.id where pt where a.pt= "${date}" 这样写才能做到过滤分区
2 还有一些SQL 有数千条,都是100元以上的费用, 主要原因由于每个SQL都是从最明细的底层表去抽取,造成SQL 的复杂度和输入数据量都非常得高。
二 解决方案
对于这样局面我们提供了三种解决方案,来改进这样的局面。
方案一: SQL 签名
大家用过ORACLE 应该都知道AWR报表,里面可以根据同一个SQL ID在不同时间维度下进行SQL执行次数、平均执行时长、耗CPU率来分析性能问题,同样这对ODPS SQL同样适用,如下:
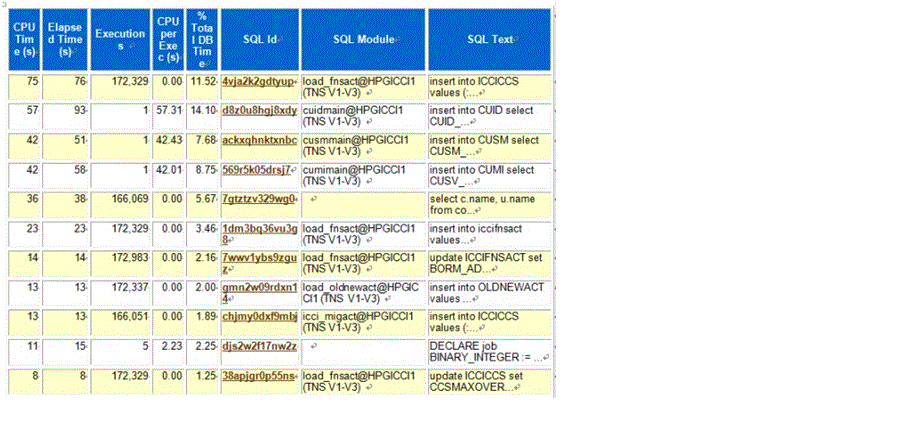
每个SQL都需要有一个唯一的签名才能做到, 我们的做法是用MD5算法进行哈希,生成一个128位的Hash Value,其中低32位作为HASH VALUE显示,SQL_ID则取了后64位,你可以用任何语言来实现。当这个SQL签名出来以后,我们很容易找到那些执行次数多, 数据量大,SQL复杂度高的SQL,给我们SQL 费用优化上带来了极大的便利。
方案二: SQL费用估算器
接下来我们需要一个SQL估算器,我们每写完一个SQL都需要去估算下多少钱,我们才能上线,ODPS计算计费公式为:一次SQL计算费用 = 计算输入数据量 * SQL复杂度 * SQL价格, 那么我就需要用一个WEB界面来实现这个公式。 非常感觉阿里云提供了ODPS sdk,使得用户可以构建给予ODPS的SAAS服务。
下面是我的工程目录:

其中最核心的API调用如下,SqlCostTask 这个函数就能获取(计算输入数据量 * SQL复杂度 * SQL价格)这三个变量了:

估算界面:

方案三:在数据仓库之上构建汇总层
在我们知道哪些SQL费用比较高以后,我们就可以有针对性地优化, 最好的方式就是根据需求的共性在DW 层之上建立一层汇总层, 很报表和对帐MaxCompute最佳实践

