










「48小时极速反馈」阿里云实时计算Flink广招天下英雄
阿里云实时计算Flink团队,全球领先的流计算引擎缔造者,支撑双11万亿级数据处理,推动Apache Flink技术发展。现招募Flink执行引擎、存储引擎、数据通道、平台管控及产品经理人才,地点覆盖北京、杭州、上海。技术深度参与开源核心,打造企业级实时计算解决方案,助力全球企业实现毫秒洞察。
java Web 项目完整案例实操指南包含从搭建到部署的详细步骤及热门长尾关键词解析的实操指南
本项目为一个完整的JavaWeb应用案例,采用Spring Boot 3、Vue 3、MySQL、Redis等最新技术栈,涵盖前后端分离架构设计、RESTful API开发、JWT安全认证、Docker容器化部署等内容,适合掌握企业级Web项目全流程开发与部署。
Java 实现 SMTP 协议调用的详细示例及实战指南 SMTP Java 调用示例
本文介绍了如何使用Java调用SMTP协议发送邮件,涵盖SMTP基本概念、JavaMail API配置、代码实现及注意事项,适合Java开发者快速掌握邮件发送功能集成。
Post-Training on PAI (4):模型微调SFT、DPO、GRPO
阿里云人工智能平台 PAI 提供了完整的模型微调产品能力,支持 监督微调(SFT)、偏好对齐(DPO)、强化学习微调(GRPO) 等业界常用模型微调训练方式。根据客户需求及代码能力层级,分别提供了 PAI-Model Gallery 一键微调、PAI-DSW Notebook 编程微调、PAI-DLC 容器化任务微调的全套产品功能。
瓴羊入选中国信通院《AI Agent智能体产业图谱》
2025数据智能大会在京召开,中国信通院发布《AI Agent智能体产业图谱1.0》,瓴羊Quick BI凭借智能数据分析能力入选。该图谱系统梳理AI Agent产业生态,涵盖基础底座、平台、通用与行业智能体四大领域。Quick BI通过融合大模型技术,重构企业数据分析方式,实现从“被动响应”到“主动服务”的升级,广泛应用于供应链、零售、财务等多个场景。此次入选标志着瓴羊在数据分析智能体领域的创新成果获高度认可。作为阿里巴巴旗下数智服务品牌,瓴羊将持续推动企业智能化转型,释放数据价值,助力“人工智能+”深度发展。

Flink CDC 3.4 发布, 优化高频 DDL 处理,支持 Batch 模式,新增 Iceberg 支持
Apache Flink CDC 3.4.0 版本正式发布!经过4个月的开发,此版本强化了对高频表结构变更的支持,新增 batch 执行模式和 Apache Iceberg Sink 连接器,可将数据库数据全增量实时写入 Iceberg 数据湖。51位贡献者完成了259次代码提交,优化了 MySQL、MongoDB 等连接器,并修复多个缺陷。未来 3.5 版本将聚焦脏数据处理、数据限流等能力及 AI 生态对接。欢迎下载体验并提出反馈!

零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
随着大语言模型快速发展,如何优化性能同时降低计算成本成为关键问题。本文系统介绍了11种零训练成本的LLM权重合并策略,涵盖线性权重平均(Model Soup)、球面插值(SLERP)、任务算术、TIES-Merging等方法,通过MergeKit工具提供实战配置示例。无论研究者还是开发者,都能从中找到高效优化方案,在有限资源下实现模型性能显著提升。
如何用大模型+RAG 给宠物做一个 AI 健康助手?——阿里云 AI 搜索开放平台
本文分享了如何利用阿里云 AI 搜索开放平台,基于 LLM+RAG 的系统框架,构建“宠物医院AI助手”的实践过程。

Triton入门教程:安装与编写和运行简单Triton内核
Triton是一款开源GPU编程语言与编译器,专为AI和深度学习领域设计,提供高性能GPU代码开发的高效途径。它支持通过Python编写自定义GPU内核,性能接近专家级CUDA代码,但无需掌握底层CUDA知识。本文全面介绍了Triton的核心功能、安装方法、基础应用、高级优化策略,以及与CUDA和PyTorch的技术对比。此外,还探讨了其在实际项目中的应用场景,如加速Transformer模型训练和实现高效的量化计算内核。Triton简化了GPU编程流程,降低了开发门槛,同时保持高性能表现,成为连接高级框架与底层硬件的重要工具。
智能体Agent解析:用自然语言重构数据开发工作方式
大数据开发治理平台DataWorks基于MCP协议,正式发布了DataWorks Agent,内置DataWorks MCP Server V1.0。该功能支持在DataWorks Data Studio中通过自然语言交互完成数据开发任务,实现了需求即代码的开发体验。本文将详细介绍如何通过配置使用DataWorks MCP Server进行任务的开发和运维管理。
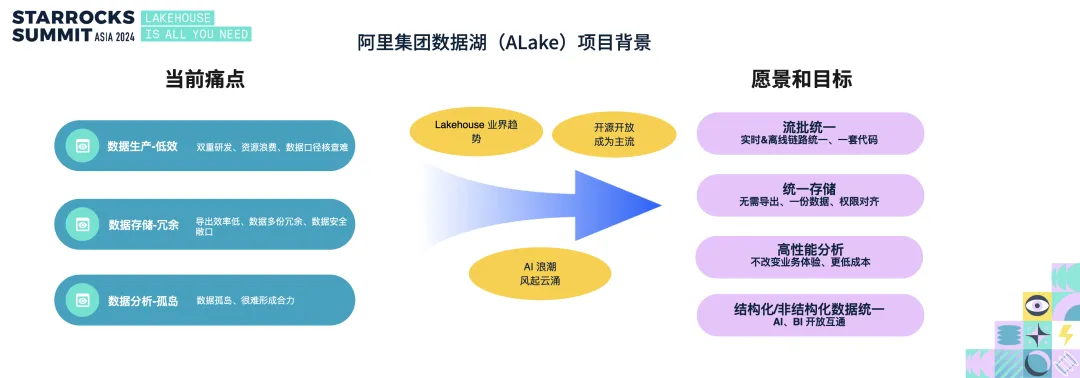
StarRocks + Paimon 在阿里集团 Lakehouse 的探索与实践
阿里集团在推进湖仓一体化建设过程中,依托 StarRocks 强大的 OLAP 查询能力与 Paimon 的高效数据入湖特性,实现了流批一体、存储成本大幅下降、查询性能数倍提升的显著成效: A+ 业务借助 Paimon 的准实时入湖,显著降低了存储成本,并引入 StarRocks 提升查询性能。升级后,数据时效提前60分钟,开发效率提升50%;JSON列化存储减少50%,查询性能提升最高达10倍;OLAP分析中,非JOIN查询快1倍,JOIN查询快5倍。 饿了么升级为准实时Lakehouse架构后,在时效性仅损失1-5分钟的前提下,实现Flink资源缩减、StarRocks查询性能提升(仅5%
淘宝淘口令转换API接口(淘宝API系列)
淘宝淘口令转换API是用于将淘宝商品或店铺链接与淘口令进行双向转换的接口,支持HTTP POST请求。开发者可通过此API生成或解析淘口令,方便在不同平台传播淘宝内容,吸引更多潜在客户。API返回JSON格式数据,包含转换结果和状态信息。使用前需注册并申请权限,确保调用稳定可靠。示例代码展示了如何通过Python实现淘口令的生成和解析功能。
义乌购商品列表数据接口(义乌购API系列)
义乌购作为全球知名的小商品批发平台,提供了丰富的商品数据接口。通过其商品列表接口,开发者和商家可以获取商品名称、价格、库存等信息,助力电商数据分析、竞品调研及店铺运营优化。本文详细介绍该接口的概念、请求方式、参数与响应数据,并提供Python请求示例,帮助用户高效利用接口资源。接口支持HTTP/HTTPS协议的GET和POST请求,返回JSON格式数据,需在开放平台注册并申请权限,遵守调用限制。
携程网获取景点列表 API 接口(携程 API 系列)
携程作为国内知名的在线旅游服务提供商,其景点列表API对接口功能、参数和返回格式进行了详细定义。该接口可获取景点基本信息(名称、地区、开放时间等),支持条件筛选查询(如按地区、评分、价格区间等)。接口返回JSON或XML格式数据,并设有调用限制以确保系统稳定性和数据安全。虽然携程未公开免费API,开发者可通过商务合作申请权限。以下为模拟Python请求示例,展示了如何使用该接口获取景点信息。 代码示例中,通过`requests.get()`发送GET请求,设置请求参数(如地区、门票价格等)和请求头(模拟浏览器访问),并处理响应数据。实际应用需替换为真实的接口URL,并遵循携程官方文档要求。
Transformer 学习笔记 | Encoder
本文记录了学习Transformer模型过程中对Encoder部分的理解,包括多头自注意力机制(Multi-Head Self-Attention)和前馈网络(Feed-Forward Network)的工作原理。每个Encoder Layer包含残差连接(Residual Connection)和层归一化(Layer Normalization),以缓解梯度消失问题并稳定训练过程。文中详细解释了Q、K、V的含义及缩放点积注意力机制(Scaled Dot-Product Attention),并通过图解展示了各组件的工作流程。欢迎指正。

DataWorks Copilot:让你的数据质量覆盖率一键飞升!
在数据加工链路中,如何确保高质量的数据产出是一个一直需要重点解决的问题。阿里云DataWorks的数据质量规则模板可以帮助用户建设数据质量,在离线表上定义相关的规则。为优化手动配置规则的工作量,DataWorks的智能助手 DataWorks Copilot 推出了数据质量规则推荐功能,您可以使用这一功能,一键提升数据质量覆盖度。
Druid 架构原理及核心特性详解
Druid 是一个分布式、支持实时多维OLAP分析的列式存储数据处理系统,适用于高速实时数据读取和灵活的多维数据分析。它通过Segment、Datasource等元数据概念管理数据,并依赖Zookeeper、Hadoop和Kafka等组件实现高可用性和扩展性。Druid采用列式存储、并行计算和预计算等技术优化查询性能,支持离线和实时数据分析。尽管其存储成本较高且查询语言功能有限,但在大数据实时分析领域表现出色。

数据仓库建模规范思考
本文介绍了数据仓库建模规范,包括模型分层、设计、数据类型、命名及接口开发等方面的详细规定。通过规范化分层逻辑、高内聚松耦合的设计、明确的命名规范和数据类型转换规则,提高数据仓库的可维护性、可扩展性和数据质量,为企业决策提供支持。
淘宝天猫商品评论数据接口丨淘宝 API 实时接口指南
淘宝天猫商品评论数据接口(Taobao.item_review)提供全面的评论信息,包括文字、图片、视频评论、评分、追评等,支持实时更新和高效筛选。用户可基于此接口进行数据分析,支持情感分析、用户画像构建等,同时确保数据使用的合规性和安全性。使用步骤包括注册开发者账号、创建应用获取 API 密钥、发送 API 请求并解析返回数据。适用于电商商家、市场分析人员和消费者。

使用PaliGemma2构建多模态目标检测系统:从架构设计到性能优化的技术实践指南
本文详细介绍了PaliGemma2模型的微调流程及其在目标检测任务中的应用。PaliGemma2通过整合SigLIP-So400m视觉编码器与Gemma 2系列语言模型,实现了多模态数据的高效处理。文章涵盖了开发环境构建、数据集预处理、模型初始化与配置、数据加载系统实现、模型微调、推理与评估系统以及性能分析与优化策略等内容。特别强调了计算资源优化、训练过程监控和自动化优化流程的重要性,为机器学习工程师和研究人员提供了系统化的技术方案。

国内首家! 阿里云人工智能平台 PAI 通过 ITU 国际标准测评
阿里云人工智能平台 PAI 顺利通过中国信通院组织的 ITU-T AICP-GA国际标准和《智算工程平台能力要求》国内标准一致性测评,成为国内首家通过该标准的企业。阿里云人工智能平台 PAI 参与完成了智算安全、AI 能力中心、数据工程、模型开发训练、模型推理部署等全部八个能力域,共计220余个用例的测试,并100%通过测试要求,获得了 ITU 国际标准和国内可信云标准评估通过双证书。
【赵渝强老师】部署Hadoop的本地模式
本文介绍了Hadoop的目录结构及本地模式部署方法,包括解压安装、设置环境变量、配置Hadoop参数等步骤,并通过一个简单的WordCount程序示例,演示了如何在本地模式下运行MapReduce任务。
【赵渝强老师】基于Flink的流批一体架构
本文介绍了Flink如何实现流批一体的系统架构,包括数据集成、数仓架构和数据湖的流批一体方案。Flink通过统一的开发规范和SQL支持,解决了传统架构中的多套技术栈、数据链路冗余和数据口径不一致等问题,提高了开发效率和数据一致性。
Big Data for AI实践:面向AI大模型开发和应用的大规模数据处理套件
文叙述的 Big Data for AI 最佳实践,基于阿里云人工智能平台PAI、MaxCompute自研分布式计算框架MaxFrame、Data-Juicer等产品和工具,实现了大模型数据采集、清洗、增强及合成大模型数据的全链路,解决企业级大模型开发应用场景的数据处理难题。

Flink CDC:基于 Apache Flink 的流式数据集成框架
本文整理自阿里云 Flink SQL 团队研发工程师于喜千(yux)在 SECon 全球软件工程技术大会中数据集成专场沙龙的分享。
三种常见的加密算法:MD5、对称加密与非对称加密的比较与应用
网络安全聚焦加密算法:MD5用于数据完整性校验,易受碰撞攻击;对称加密如AES快速高效,密钥管理关键;非对称加密如RSA提供身份验证,速度慢但安全。三种算法各有所长,适用场景各异,安全与效率需权衡。【6月更文挑战第17天】
如何准确的估计llm推理和微调的内存消耗
最近发布的三个大型语言模型——Command-R+ (104B参数), Mixtral-8x22b (141B参数的MoE模型), 和 Llama 3 70b (70.6B参数)——需要巨大的内存资源。推理时,Command-R+需193.72GB GPU RAM,Mixtral-8x22B需262.63GB,Llama 370b需131.5GB。激活的内存消耗根据序列长度、批大小等因素变化。文章详细介绍了计算这些模型内存需求的方法,并探讨了如何通过量化、优化器优化和梯度检查点减少内存使用,以适应微调和推理。
实时数仓 Hologres产品使用合集之报错:ORCA failed to produce a plan : PlStmt Translation: Group by key is type of imprecise not supported如何解决
实时数仓Hologres是阿里云推出的一款高性能、实时分析的数据库服务,专为大数据分析和复杂查询场景设计。使用Hologres,企业能够打破传统数据仓库的延迟瓶颈,实现数据到决策的无缝衔接,加速业务创新和响应速度。以下是Hologres产品的一些典型使用场景合集。
如何为Kafka加上账号密码(二)
本小节我们就为Kafka添加最简单的认证方式,也就是SASL_PLAINTEXT(即SASL/PLAIN+ 非加密通道)。
通义千问Qwen-72B-Chat基于PAI的低代码微调部署实践
本文将以 Qwen-72B-Chat 为例,介绍如何通过PAI平台的快速开始(PAI-QuickStart)部署和微调千问大模型。
机器学习入门-Colab环境
Google Colab(Colaboratory)是一个免费的云端环境,旨在帮助开发者和研究人员轻松进行机器学习和数据科学工作。它提供了许多优势,使得编写、执行和共享代码变得更加简单和高效。Colab在云端提供了预配置的环境,可以直接开始编写代码,并且提供了免费的GPU和TPU资源,这对于训练深度学习模型等计算密集型任务非常有帮助,可以加速模型训练过程。
如何为Kafka加上账号密码(一)
一直以来,我们公司内网的Kafka集群都是在裸奔,只要知道端口号,任何人都能连上集群操作一番。直到有个主题莫名消失,才引起我们的警觉,是时候该考虑为它添加一套认证策略了。

Next Station of Flink CDC
本文整理自阿里云智能 Flink SQL、Flink CDC 负责人伍翀(花名:云邪),在 Flink Forward Asia 2023 主会场的分享。
3D目标检测数据集 DAIR-V2X-V
本文分享国内场景3D目标检测,公开数据集 DAIR-V2X-V(也称为DAIR-V2X车端)。DAIR-V2X车端3D检测数据集是一个大规模车端多模态数据集,包括: 22325帧 图像数据 22325帧 点云数据 2D&3D标注 基于该数据集,可以进行车端3D目标检测任务研究,例如单目3D检测、点云3D检测和多模态3D检测。
区间预测 | MATLAB实现基于QRCNN-BiGRU-Multihead-Attention多头注意力卷积双向门控循环单元多变量时间序列区间预测
区间预测 | MATLAB实现基于QRCNN-BiGRU-Multihead-Attention多头注意力卷积双向门控循环单元多变量时间序列区间预测

“后红海”时代, 阿里资深技术专家揭秘当下大数据体系
任何一种技术都会经历从阳春白雪到下里巴人的过程,就像我们对计算机的理解从 “戴着鞋套才能进的机房”变成了随处可见的智能手机。在前面 20 年中,大数据技术也经 历了这样的过程,从曾经高高在上的 “火箭科技(rocket science)”,成为了人人普惠 的技术。
taocarts深度解析|反向海淘系统+淘宝/1688一键采,核心代码实战(附避坑指南)
在反向海淘风口下,反向海淘系统的核心竞争力在于“货源对接”与“流程自动化”,而淘宝/1688一键采则是提升代购效率的关键。taocarts作为聚焦反向海淘的代购系统,不仅实现了淘宝、1688的无缝对接,更解决了传统代购系统“商品采集混乱、库存不同步、订单卡顿”等痛点,今天就深度解析taocarts的反向海淘系统 + 淘宝/1688一键采核心功能,附上实战代码和避坑指南,助力开发者快速落地反向海淘独立站、1688代采平台。
让 AI 帮你搞定文献阅读
OpenClaw + arxiv-reader技能,让你用手机聊天式阅读arXiv论文:秒获纯文本(自动展开LaTeX)、先看目录再决定是否精读、多文摘要对比筛选、精准定位章节解析——无需下载PDF、不用开电脑、零部署门槛,科研效率翻倍!
AI质检+MES如何重构智能制造质量闭环
AI质检与MES深-度融合,构建“感知-分析-决策-执行”质量闭环:实现100%全检、自动拦截、一物一档、工艺自优化及缺-陷预-测;通过OPC UA/MQTT/边缘网关打通设备数据,支撑全流程精-准质量追溯。
1949AI轻量化AI自动化:定时任务浏览器自动化+数据分发代码实战
基于1949AI轻量化理念,本工具以Python实现浏览器自动化采集、本地存储与飞书/邮箱双通道通知,全程无云依赖、低资源占用、安全合规,适配个人开发者及小型团队的轻量工程化需求。(239字)

基于 Rokid 灵珠与 UXR 3.0 的 AR 智能卡路里识别系统实战
本项目为“AR智能卡路里计算器”,基于Rokid灵珠(AR Lite/Studio)与UXR 3.0 SDK开发。用户佩戴眼镜直视食物,系统通过空间计算实时识别并弹出热量数据,支持水果/正餐双模式切换。采用程序化3D建模、零美术资源依赖、多模态交互(键鼠→手柄→手势捏合),实现“空间即看即得”的沉浸式健康饮食辅助体验。(239字)

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
