Spark等引擎都是作为工具被开发者使用的,而我们使用这些工具的最终目的是搭建合适的平台提供给业务方。以下是YipitData‘s Platform的相关介绍。
一、为什么要用到平台 (Why a platform) ?
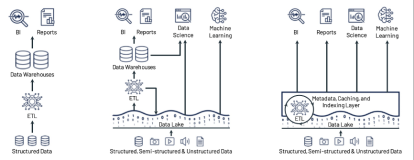
YipitData是一家咨询公司,其客户主要是投资基金以及财富五百强中的一些公司。该公司通过自己的数据产品进行分析,提供给客户相应的数据分析报告。YipitData的主要产出方式和赚钱方式就是做数据分析,其公司内部有53个数据分析师,却只有3个数据工程师。数据分析的基础是数据,所以对于该公司来说大数据分析的平台是非常重要的。
二、平台中有什么 (What is in our platform) ?
YipitData公司希望通过他们自己的数据分析平台能够让数据分析师不需要付出太大的成本就完成数据分析的任务,也就是Own The Product,而这个过程主要包括如下图所示的Data Collection、Data Exploration、ETL Workflows和Report Generation四个阶段。

上面我们提到YipitData公司的人员主要包括数据分析师和数据工程师,其中数据分析师来分析数据并且提供基于数据的问题解答和分析报告,数据工程师来给数据分析师提供数据和分析数据的平台。
Databricks中的一个产品叫做Workspace,简单来说它就是一个Notebook,你可以在其中写python、Scala、SQL等语言的代码,然后交由Databricks平台去执行并返回结果。YipitData' Platform是基于Databricks平台来搭建的,简而言之就是他们对Databricks进行了更深一层的封装,创建了一个Python Library,更加方便分析师来进行使用。
(一)获取数据 (Ingesting data)
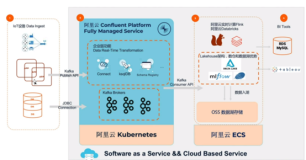
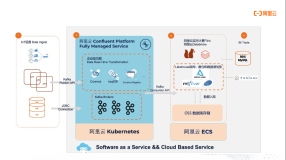
YipitData公司的数据量是非常大的,有压缩后大小超过1PB的Parquet,60K的Tables和1.7K的Databases。他们的数据收集使用的是Readypipe,简单理解就是一个网络爬虫,在有了URL之后,将网页内存download下来然后进行存储,实现从URLs到Parquet。首先,使用Readypipe对网页进行爬取,然后以流的方式源源不断的写入kinesis Firehose,kinesis Firehose会接着将数据写入AWS的S3上。在这个阶段所存储的数据都是原始JSON数据,是没有schema的,这类数据对于数据分析师来说是很难进行使用的。因此,第二步我们要对数据进行一些格式转换和清理,比较典型的做法是将JSON文件转换成Bucket,这一步也自带了压缩效果。转换完成之后会有两个输出,如下图所示,一个是元数据,会写入Glue Metastore,另外一个是数据,会写入Parquet Bucket中。通过上面的过程,就完成了数据的收集和清理过程,整个过程是非常经典,非常有参考价值的。

另外,因为数据流是实时数据,每隔一段时间就会产生一些JSON文件,属于小文件,时间久了S3上面会存在非常多的小文件,带来性能方面的许多问题,于是要对小文件做相应的Merge处理,将小文件汇聚成大文件,这对后续的处理非常有帮助。
YipitData公司所使用的的数据都是第三方数据,他们本身不生产任何数据,而使用第三方数据会面临一些问题,主要包括如下四类问题:
- Various File Formats
- Permissions Challenges
- Data Lineage
- Data Refreshes

上面几类问题是在实际业务中经常遇到的,如果不解决好自然也不能有很好的成果产出。YipitData公司解决上面几类问题主要是靠Databricks平台,比如上传并利用额外的元数据将文件转为parquet等,如下图所示。

(二)表实用程序 (Table Utilities)
YipitData's Platform提供了一些table utilities来帮助分析师创建table和管理table。比如下图所示的create_table函数,可以帮助数据分析师更快速地创建table。


上图所示的是一个非常典型的Spark Job的场景,通常包括read、processing和write三个模块。但是对于YipitData公司来说,上面的过程仍然是一个比较繁琐的过程,因为该公司最重要的任务是进行数据分析,且大多数人员也是数据分析师,如果让数据分析师使用Spark API去完成上述过程,还是有一定门槛的。对于YipitData公司来说,最好是把一些功能进行封装,不要暴露太多的底层功能,所以有了上面的create_table函数,大大降低了数据分析师的使用难度。
(三)集群管理 (Cluster Management)
对于数据分析师来说,最后还是要进行计算,就牵涉计算资源的管理,那么YipitData是怎么做的呢?
我们知道,搭建一个Spark集群并不是很难,但是如何搭建一个能够最优化地解决问题的Spark集群并不是那么容易,因为Spark集群有非常多的配置,而这项工作如果交给数据分析师来做的话就更不简单了。为了解决易用性的问题,YipitData的工程师参照T-Shirt的Size划分巧妙地将集群划分成SMALL、MEDIUM、LARGE三类,如下图所示,数据分析师在使用的时候虽然少了灵活性,但是节省了很多集群配置的时间,大大的提高了工作效率。背后的原理也是进行更深层次的封装,将众多参数设置隐藏起来,数据分析师只需要像选择T-Shirt的尺寸一样做选择即可,而无需关心背后的复杂配置如何实现。


在集群管理方面,Databricks还提供了许多其他的API来对集群的计算资源进行管理,比如可以通过REST API控制集群,对集群做各种各样的配置,还可以对集群的配置进行动态调整等等,如下图所示。

(四)ETL Workflow的自动化 (ETL Workflow Automation)
YipitData使用Airflow来实现ETL Workflow的自动化。越来越多的人使用Airflow来管理ETL Workflow,已经逐渐成为ETL的一个标准工具。对于数据工程师来说,Airflow的使用不是很难:首先构建一个DAG,然后去定义其中的TASK,最后定义下这些TASKS的依赖关系即可。但是,终究是要写一段代码来实现这个过程,就需要有人来维护,对于大多数员工是数据分析师的YipitData来说就不是那么合适了。因此,YipitData使用Airflow+databricks的API来自动化构建DAGs。具体来说,每个文件夹就代表一个DAG,每个Notebook就代表一个Task,Notebook中指定一些属性(内部是python脚本),然后通过API来自动化构建DAG文件。通过上面的过程完成整个ETL的自动化,其中用户只需要指定Notebook中的参数值即可。YipitData自动化创建Workflows的过程如下图所示,整个流程都是在Databricks平台上扩展得到的。

三、Q&A
Q1:Databricks和Dataworks都是一站式的数据分析平台,两者的区别是什么?
A1:两者的侧重点不一样。Dataworks绑定在阿里云,而Databricks可以在各个云上使用;Databricks绑定了Spark引擎,而Dataworks可以使用各种引擎;Dataworks在数据治理上更强一些,而Databricks的Spark应用更强一些。
Q2:目前Zeppelin、Jupyter、Databricks产品的分析功能有些类似,他们有什么特别推荐的使用场景吗?
A2:这几个产品最大的特点是提供了交互式的编程环境,和传统的IDE开发不同,他们有着更好的开发效率,尤其是在数据分析和机器学习方面。另外,这类产品也不是只能做交互式开发,也可以用来做ETL。
关键词:Databricks、Spark、Analysis Platform、YipitData
获取更多 Spark+AI SUMMIT 精彩演讲视频回放,立刻点击前往:
>>SPARK + AI SUMMIT 2020 中文精华版线上峰会 7月4日第一场<<
>>SPARK + AI SUMMIT 2020 中文精华版线上峰会 7月5日第二场<<