

雷锋网 AI 科技评论按:大多数机器学习任务——从自然语言处理、图像分类到翻译以及大量其他任务,都依赖于无梯度优化来调整模型中的参数和/或超参数。为了使得参数/超参数的调整更快、更简单,Facebook 创建了一个名叫 Nevergrad(https://github.com/facebookresearch/nevergrad)的 Python 3 库,并将它开源发布。Nevergrad 提供了许多不依赖梯度计算的优化算法,并将其呈现在标准的问答 Python 框架中。此外,Nevergrad 还包括了测试和评估工具。
Nevergrad 现已对外开放,人工智能研究者和其他无梯度优化相关工作者马上就可以利用它来协助自己的工作。这一平台不仅能够让他们实现最先进的算法和方法,能够比较它们在不同设置中的表现,还将帮助机器学习科学家为特定的使用实例找到最佳优化器。在 Facebook 人工智能研究院(FAIR),研究者正将 Nevergrad 应用于强化学习、图像生成以及其他领域的各类项目中,例如,它可以代替参数扫描来帮助更好地调优机器学习模型。
这个库包含了各种不同的优化器,例如:
差分进化算法(Differential evolution)
序列二次规划(Sequential quadratic programming)
FastGA
协方差矩阵自适应(Covariance matrix adaptation)
噪声管理的总体控制方法(Population control methods for noise management)
粒子群优化算法(Particle swarm optimization)
在此之前,使用这些算法往往需要研究者自己编写算法的实现,这就让他们很难在各种不同的最新方法之间进行比较,有时候甚至完全无法比较。现在,AI 开发者通过使用 Nevergrad,可以轻易地在特定的机器学习问题上对不同方法进行测试,然后对结果进行比较。或者,他们也可以使用众所周知的基准来评估——与当前最先进的方法相比,新的无梯度优化方法怎么样。
Nevergrad 中所包含的无梯度优化方法可用于各类机器学习问题,例如:
多模态问题,比如说拥有多个局部极小值的问题。(如用于语言建模的深度学习超参数化。)
病态问题,通常在优化多个具有完全不同的动态特性的变量的时候,该问题就会出现(如,未对特定问题进行调整的丢弃和学习率)。
可分离或旋转问题,其中包括部分旋转问题。
部分可分离问题,可以考虑通过几个变量块来解决这类问题。示例包括深度学习或其他设计形式的架构搜索,以及多任务网络的参数化。
离散的、连续的或混合的问题。这些问题可以包括电力系统(因为有些发电站具有可调连续输出,而其他发电站则具有连续或半连续输出)或者要求同时选择每层的学习速率、权值衰减以及非线性类型的神经网络任务。
有噪声的问题,即针对这一问题,函数被完全相同的参数调用时可以返回不同结果,例如强化学习中的不同关卡。
在机器学习中,Nevergrad 可用于调整参数,例如学习率、动量、权值衰减(或许每一层)、dropout(丢弃)算法、深度网络每个部分的层参数及其他等。更为普遍地,非梯度方法同样被用于电网管理(https://www.sciencedirect.com/science/article/pii/S0142061597000409)、航空(https://www.sciencedirect.com/science/article/pii/S0142061597000409)、镜头设计(https://www.researchgate.net/publication/222434804_Human-competitive_lens_system_design_with_evolution_strategies)以及许多其他的科学和工程应用中。
为什么有无梯度优化的需求
在某些场景中,例如在神经网络权重优化中,以分析法去计算函数的梯度是简单的。然而,在其他场景中,例如当计算函数 f 的速度慢,或者域不连续的时候,函数的梯度就无法预估出来。在这些应用实例中,无梯度方法提供了解决方案。
一个简单的无梯度解决方案是随机搜索,它由随机采样大量的搜索点、对每个搜索点进行评估、选择最佳搜索点三个步骤组成。随机搜索在许多简单场景中表现很好,但在高维场景中却表现不佳。通常被用于机器学习参数调整的网格搜索,也面临类似的限制。不过,也还有许多替代方法:其中一些来自应用数学,如序列二次规划,它对模拟器的二次近似进行更新;贝叶斯优化也建立目标函数模型,其中包括不确定性模型;进化计算包含大量关于选择、变异以及混合有前景的变体的工作。
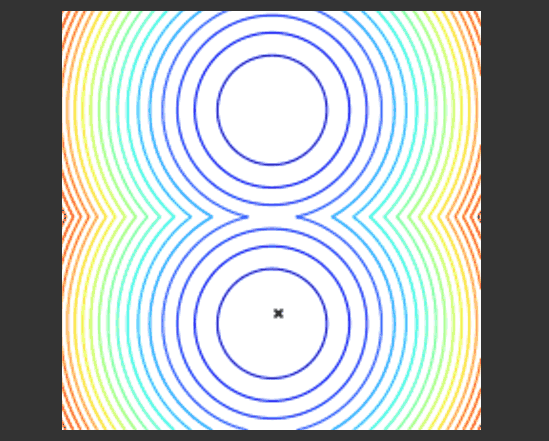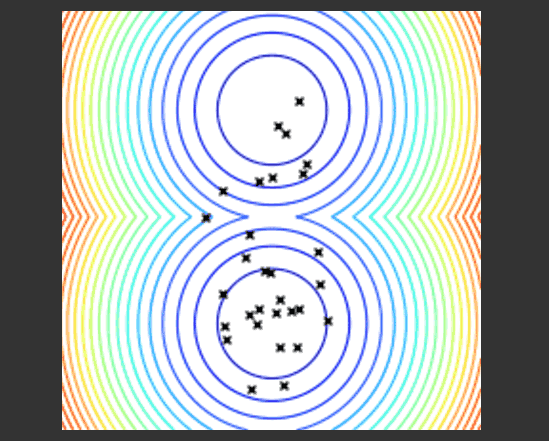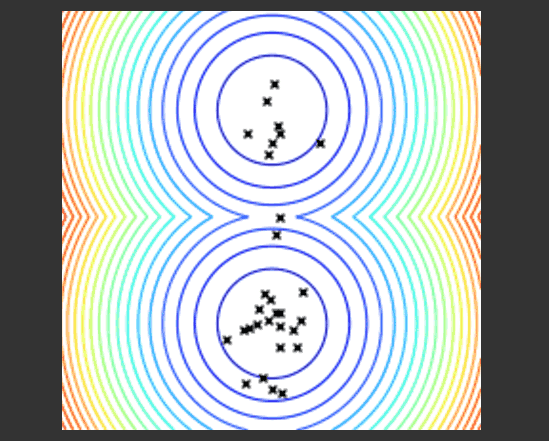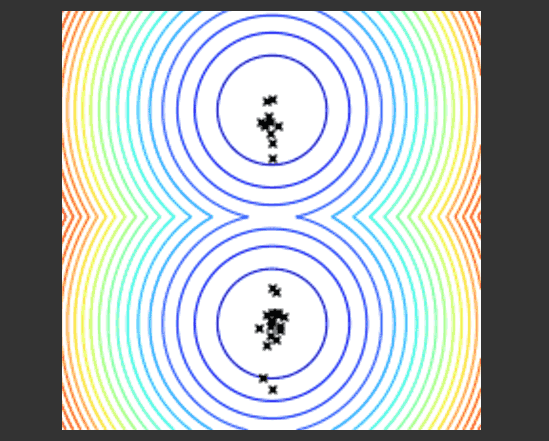
这个示例展示了进化算法如何运行。在函数空间中采样搜索点,并选择最佳点的群落,然后在已有点的周围推荐出新的点来尝试优化当前的点群落。
使用 Nevergrad 生成算法基准
Facebook 研究团队使用了 Nevergrad 实现几个基准测试,来展示特定算法在特定情况下的表现最佳。这些众所周知的示例对应着各种不同设置(多峰或非多峰,噪声或非噪声,离散或非离散,病态或非病态),并展示了如何使用 Nevergrad 来确定最佳优化算法。
在每个基准测试中,Facebook 研究团队对不同的 X 值进行了独立实验。这确保了在几个 X 值上的各个方法之间的一致排序在统计上是显著的。除了下面的两个基准示例,这里(https://github.com/facebookresearch/nevergrad/blob/master/docs/benchmarks.md)还有一份更全面的清单,并附上了如何使用简单的命令行重新运行这些基准的指南。

这个图展示了一个噪声优化示例
这个示例展示了使用 pcCMSA-ES 噪声管理原理(https://homepages.fhv.at/hgb/New-Papers/PPSN16_HB16.pdf)的 TBPSA 如何在表现上胜过几种替代方案。Facebook 研究团队在这里只将 TBPSA 与算法的一个有限示例进行了对比,不过,比起其他的方法,它的表现同样更好。
Nevergrad 平台还可以执行在很多机器学习场景中都会出现的离散目标函数。这些场景包括,举例来说,在一组有限的选项中进行选择(例如神经网络中的激活函数)和在层的各个类型中进行选择(例如,决定在网络中的某些位置是否需要跳过连接)。
现有的替代平台(Bbob 和 Cutest)并不包含任何离散的基准。Nevergrad 可以执行经过 softmax 函数(将离散问题转换成有噪声的连续问题)或连续变量离散化进行处理了的离散域。
Facebook 研究团队注意到在这个场景中,FastGA(https://arxiv.org/abs/1703.03334)的表现最好。DoubleFastGA 对应的是 1/dim 和 (dim-1)/dim 之间的突变率,而不对应 1/dim 和 1/2。这是因为原始范围对应于二进制域,而在这里,他们考虑的是任意域。在几种场景中,简单一致的突变率混合(https://arxiv.org/abs/1606.05551)表现良好。

为研究者和机器学习科学家扩展工具箱
Faacebook 将会持续为 Nevergrad 增加功能,从而帮助研究者创建和评估新算法。最初的版本拥有基本的人工测试功能,不过 Facebook 计划为其增加更多功能,其中包括表示物理模型的功能。在应用方面,他们将继续让 Nevergrad 变得更易用,并尝试用它来对无法很好地确定梯度的 PyTorch 增强学习模型中的参数进行优化。Nevergrad 还可以帮助 A/B 测试以及作业调度等其他任务进行参数扫描。
via:https://code.fb.com/ai-research/nevergrad/ ,雷锋网 AI 科技评论编译。雷锋网(公众号:雷锋网)

