
新智元报道
编辑:好困
【新智元导读】刚刚,UC伯克利、CMU、斯坦福等,联手发布了最新开源模型骆马(Vicuna)的权重。
3月31日,UC伯克利联手CMU、斯坦福、UCSD和MBZUAI,推出了130亿参数的Vicuna,俗称「小羊驼」(骆马),仅需300美元就能实现ChatGPT 90%的性能。
今天,团队正式发布了Vicuna的权重——只需单个GPU就能跑!
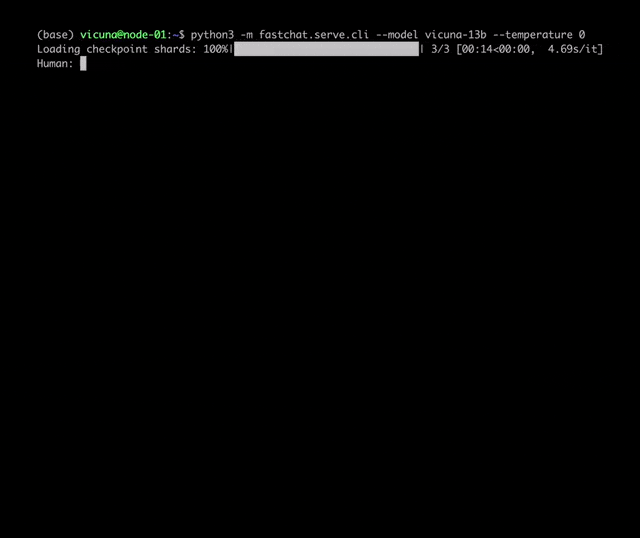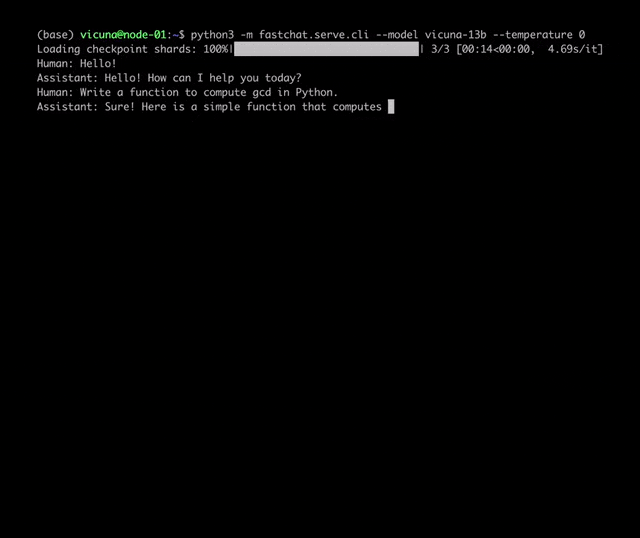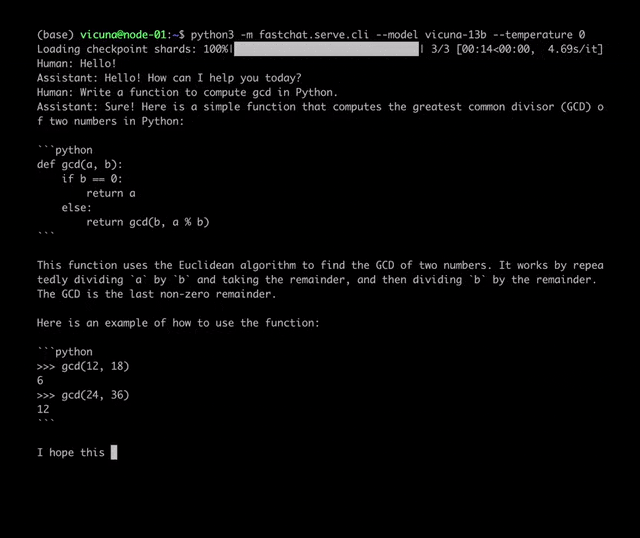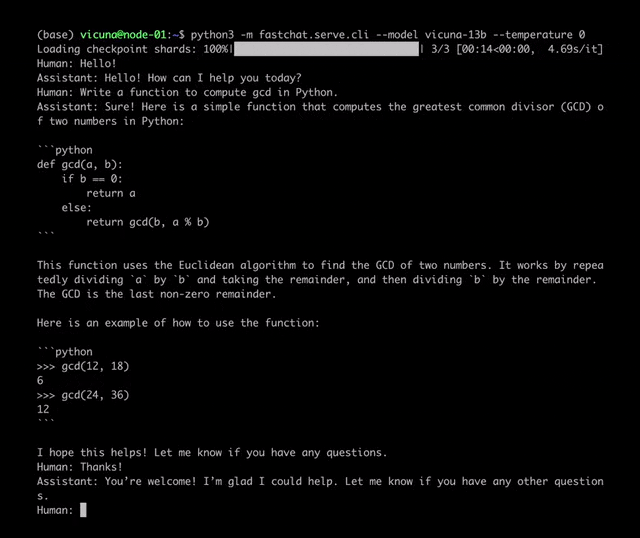
项目地址:https://github.com/lm-sys/FastChat/#fine-tuning
130亿参数,90%匹敌ChatGPT
Vicuna是通过在ShareGPT收集的用户共享对话上对LLaMA进行微调训练而来,训练成本近300美元。
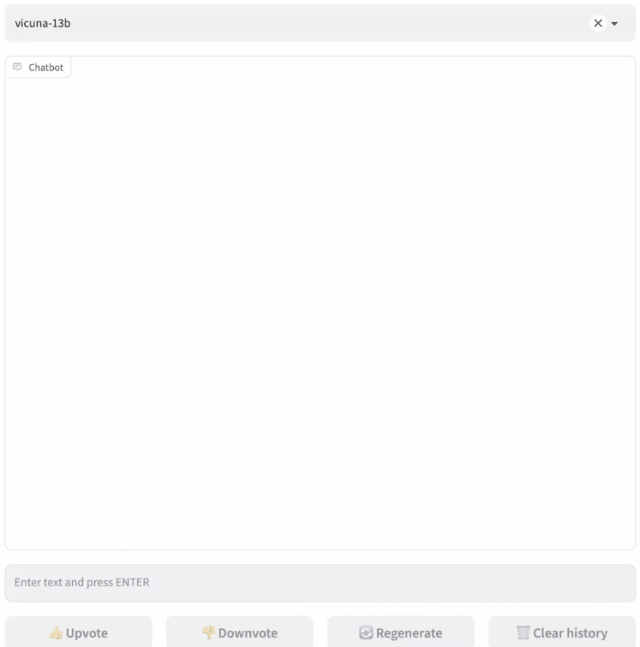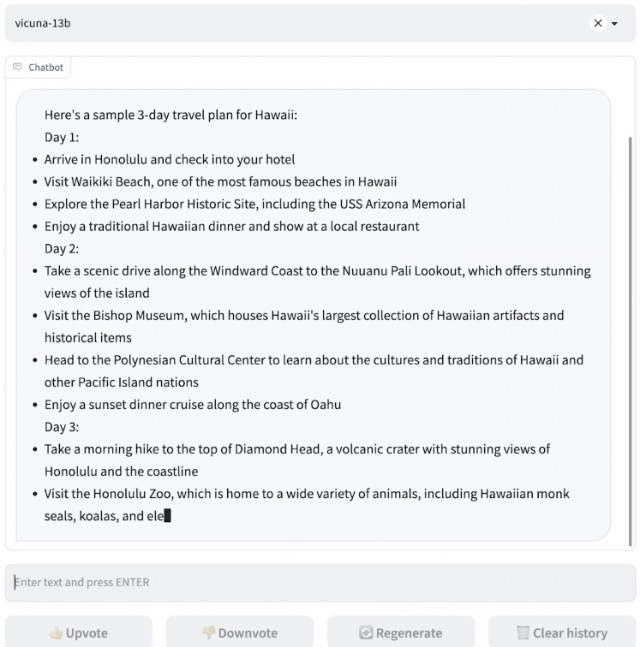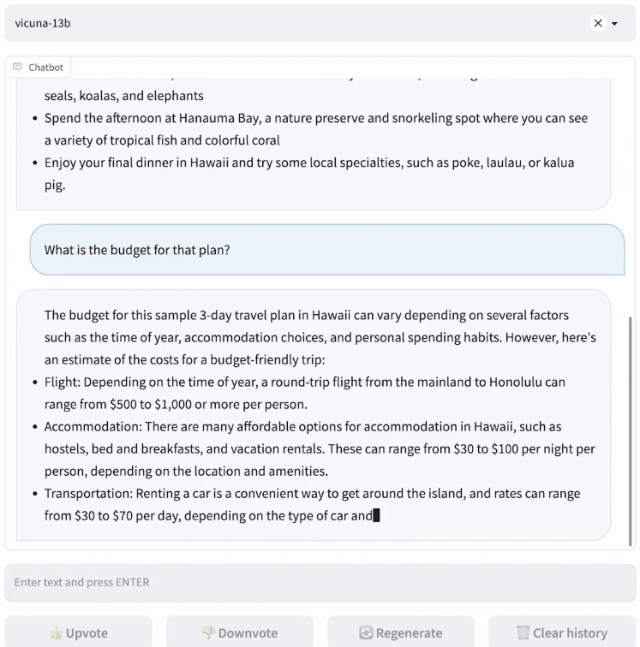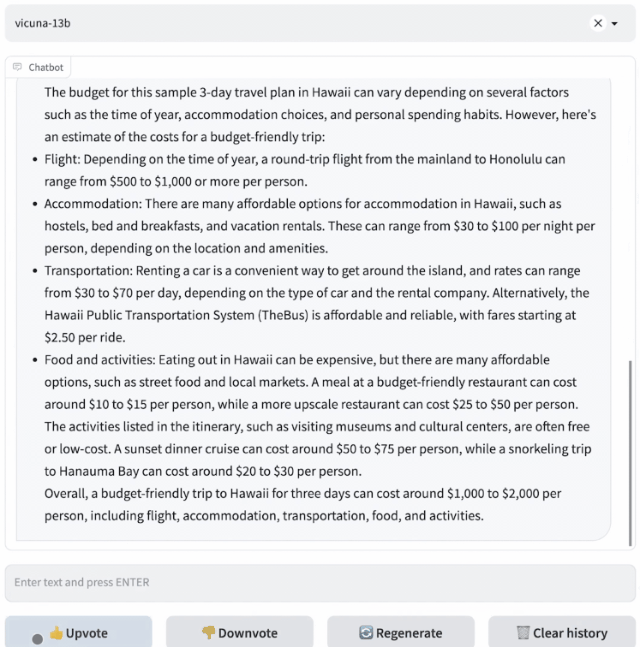
研究人员设计了8个问题类别,包括数学、写作、编码,对Vicuna-13B与其他四个模型进行了性能测试。
测试过程使用GPT-4作为评判标准,结果显示Vicuna-13B在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力。同时,在在超过90%的情况下胜过了其他模型,如LLaMA和斯坦福的Alpaca。
训练
Vicuna-13B的训练流程如下:首先,研究人员从ChatGPT对话分享网站ShareGPT上,收集了大约70K对话。接下来,研究人员优化了Alpaca提供的训练脚本,使模型能够更好地处理多轮对话和长序列。之后利用PyTorch FSDP在8个A100 GPU上进行了一天的训练。 · 内存优化:为了使Vicuna能够理解长上下文,将最大上下文长度从Alpaca的512扩展到2048,这大大增加了GPU内存需求。在此,研究人员通过使用梯度检查点和闪存注意力来解决内存压力。· 多轮对话:通过调整训练损失以考虑多轮对话,并仅在聊天机器人的输出上计算微调损失。· 通过Spot实例降低成本:采用SkyPilot托管的Spot实例来降低成本,将7B模型的训练成本从500美元降低到约140美元,将13B模型的训练成本从约1000美元降低到300美元。
· 内存优化:为了使Vicuna能够理解长上下文,将最大上下文长度从Alpaca的512扩展到2048,这大大增加了GPU内存需求。在此,研究人员通过使用梯度检查点和闪存注意力来解决内存压力。· 多轮对话:通过调整训练损失以考虑多轮对话,并仅在聊天机器人的输出上计算微调损失。· 通过Spot实例降低成本:采用SkyPilot托管的Spot实例来降低成本,将7B模型的训练成本从500美元降低到约140美元,将13B模型的训练成本从约1000美元降低到300美元。
评估
在模型的质量评估方面,研究人员创建了80个不同的问题,并用GPT-4对模型输出进行了评价。为了比较不同的模型,研究人员将每个模型的输出组合成一个单独的提示,然后让GPT-4评估哪个模型给出的回答更好。其中,GPT-4在超过90%的问题中更喜欢Vicuna,而不是现有的SOTA开源模型(LLaMA、Alpaca)。在45%的问题中,GPT-4认为Vicuna的回答和ChatGPT差不多甚至更好。综合来看,Vicuna在总分上达到ChatGPT的92%。
安装使用
安装
方法一:
方法二:
1. clone版本库并变更目录到FastChat文件夹
git clone https://github.com/lm-sys/FastChat.gitcd FastChat
2. 安装Package
pip3 install --upgrade pip # enable PEP 660 supportpip3 install -e .
权重
根据LLaMA模型的许可,权重将以delta的形式发布。只需将其加到原来的LLaMA权重上,就可以获得最终的Vicuna权重。
1. 按照huggingface上的说明,获得原始的LLaMA权重
2. 通过脚本,自动从团队的Hugging Face账户上下载delta权重
python3 -m fastchat.model.apply_delta \ --base /path/to/llama-13b \ --target /output/path/to/vicuna-13b \ --delta lmsys/vicuna-13b-delta-v0
使用· 单个GPUVicuna-13B需要大约28GB的GPU显存。
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights
· 多个GPU如果没有足够的显存,则可以使用模型并行来聚合同一台机器上多个GPU的显存。
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --num-gpus 2
· 仅用CPU
如果想在CPU上运行,则需要大约60GB的内存。
python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --device cpu
Web UI· 启动控制器
python3 -m fastchat.serve.controller
· 启动model worker
python3 -m fastchat.serve.model_worker --model-path /path/to/vicuna/weights
当进程完成模型的加载后,会看到「Uvicorn running on ...」。
· 发送测试消息
python3 -m fastchat.serve.test_message --model-name vicuna-13b
· 启动gradio网络服务器
python3 -m fastchat.serve.gradio_web_server
现在,你就可以打开浏览器和模型聊天了。
微调
· 数据Vicuna是通过使用从ShareGPT收集到的大约7万个用户共享的对话与公共API来微调一个LLaMA基础模型而创建的。为了确保数据质量,团队将HTML转换回markdown,并过滤掉一些不合适或低质量的样本。此外,团队还将冗长的对话分成较小的片段,以符合模型的最大上下文长度。· 代码和超参数团队使用斯坦福大学Alpaca的代码对模型进行微调,并做了一些修改以支持梯度检查点和Flash注意力。此外,团队也使用与斯坦福Alpaca相似的超参数。 · 用SkyPilot在云服务上进行微调SkyPilot是由加州大学伯克利分校建立的一个框架,可以在任何与一个云服务(AWS、GCP、Azure、Lambda等)上轻松、经济地运行ML工作负载。安装说明:https://skypilot.readthedocs.io/en/latest/getting-started/installation.html
· 用SkyPilot在云服务上进行微调SkyPilot是由加州大学伯克利分校建立的一个框架,可以在任何与一个云服务(AWS、GCP、Azure、Lambda等)上轻松、经济地运行ML工作负载。安装说明:https://skypilot.readthedocs.io/en/latest/getting-started/installation.html
# Install skypilot from the master branchpip install git+https://github.com/skypilot-org/skypilot.git
Vicuna可以在8个拥有80GB内存的A100 GPU上进行训练。下面的命令将自动启动一个满足要求的节点,在上面设置并运行训练作业。
sky launch -c vicuna -s scripts/train-vicuna.yaml --env WANDB_API_KEY
对于Alpaca来说,训练作业会在具有4个A100-80GB GPU的单一节点上启动。
sky launch -c alpaca -s scripts/train-alpaca.yaml --env WANDB_API_KEY
· 使用本地GPU进行微调
Vicuna也可以用以下代码在8个A100 GPU上训练,显存为80GB。如果要在更少的GPU上训练,则可以减少per_device_train_batch_size,并相应地增加gradient_accumulation_steps,以保持全局批大小不变。要设置环境,可以参见scripts/train-vicuna.yaml中的设置部分。
torchrun --nnodes=1 --nproc_per_node=8 --master_port=<your_random_port> \ fastchat/train/train_mem.py \ --model_name_or_path <path-to-llama-model-weight> \ --data_path <path-to-data> \ --bf16 True \ --output_dir ./checkpoints \ --num_train_epochs 3 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 4 \ --gradient_accumulation_steps 1 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 1200 \ --save_total_limit 100 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --fsdp "full_shard auto_wrap" \ --fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \ --tf32 True \ --model_max_length 2048 \ --gradient_checkpointing True \ --lazy_preprocess True
参考资料:https://github.com/lm-sys/FastChat/#fine-tuning

