
一:逻辑回归分类的原理
逻辑回归和线性回归最大的区别在于线性回归的输出一般是连续的,而逻辑回归的输出一般是离散的,但是输入可以是连续的。逻辑回归也使用了线性回归的函数,即h(θ)=θ.T*X,但是线性回归的输出值的范围是负无穷到正无穷的,我们要把输出值压缩到0-1这个范围,因此引入了sigmoid函数

当z趋于负无穷时,g(z)趋于0,当z趋于正无穷时,g(z)趋于1,我们线性回归的输出当做逻辑回归的输入即可将输出压缩在0-1之间,即z=θ.T*X,因此可以构造出预测函数

至此我们就可以用线性回归的知识来完成剩下的工作,同样也是构造出损失函数然后令损失函数取得极小值。令H代表上式,H的维度是(n+1)*1,Y维度也为(n+1)*1,损失函数可表示为
Cost = -Y log(H) - (1 - Y)log(1-H)
对其求θ的偏导,得到
d(Cost)/d(θ) = X.T(H - Y)
因此可以得到θ的更新规则:
θ := θ - α(X.T(H - Y))
不断迭代直至损失函数收敛即可得到θ。
二:朴素贝叶斯分类的原理
贝叶斯公式为P(Y∣X)=P(X∣Y)P(Y)/P(X),其原理是应用所观察到的现象对有关概率分布的主观判断(即先验概率)进行修正的标准方法。朴素贝叶斯是贝叶斯分类算法中的一种,与贝叶斯的不同之处在于朴素贝叶斯进行了独立性假设,假设各个特征之间相互独立不相关。应用到分类中,可以定义
P(类别|特征)=(P(类别)P(特征|类别))/P(特征)
也即由当前已知特征求得该样本属于什么类别的概率,最终结果是概率最大值的类别。由于分母是不变的,所以只需要比较分子即可,P(类别)可以由该类别在所有训练样本中所占的比例求得,称为先验概率;然后求条件概率P(特征|类别),由于假设X的n个维度之间相互独立,Ck表示类别,可以得到

当所有特征是连续型变量时,可以假设所有特征均符合正态分布,通过样本计算出均值和方差,也就是得到正态分布的密度函数,有了密度函数,就可以把值代入,算出某一点的密度函数的值。
三:程序清单
(一)梯度下降参数求解:
import pandas as pd import numpy as np from itertools import chain from matplotlib import pyplot as plt from sklearn.model_selection import train_test_split from sklearn.metrics import roc_auc_score data = pd.read_csv('./adult.csv',header=None) data.columns=['age', 'workclass', 'fnlwgt', 'education', 'education-num','marital-status','occupation','relationship','race','sex','capital-gain','capital-loss','hours-per-week','native-country','income'] #删除冗余数据 # data.drop(['education','fnlwgt'], axis=1, inplace=True) # 去除字符串数值前面的空格 str_cols=[1,3,5,6,7,8,9,13,14] for col in str_cols: data.iloc[:,col]=data.iloc[:,col].map(lambda x: x.strip()) # 删除缺失值样本 data.replace("?",np.nan,inplace=True) data.dropna(inplace=True) # 对字符数据进行编码 from sklearn import preprocessing label_encoder=[] # 放置每一列的encoder encoded_set = np.empty(data.shape) for col in range(data.shape[1]): encoder=None if data.iloc[:,col].dtype==object: # 字符型数据 encoder=preprocessing.LabelEncoder() encoded_set[:,col]=encoder.fit_transform(data.iloc[:,col]) else: # 数值型数据 encoded_set[:,col]=data.iloc[:,col] label_encoder.append(encoder) # 对某些列进行范围缩放 cols=[2,10,11] data_scalers=[] # 专门用来放置scaler for col in cols: data_scaler=preprocessing.MinMaxScaler(feature_range=(-1,1)) encoded_set[:,col]=np.ravel(data_scaler.fit_transform(encoded_set[:,col].reshape(-1,1))) data_scalers.append(data_scaler) # 拆分数据集为train set和test set dataset_X,dataset_y=encoded_set[:,:-1],encoded_set[:,-1] from sklearn.model_selection import train_test_split train_X, test_X, train_y, test_y=train_test_split(dataset_X,dataset_y, test_size=0.3,random_state=42) #划分数据 Y = train_y.reshape(-1,1) # 训练集Y X = train_X X = np.hstack([np.ones((len(X), 1)), X]) # 训练集X y = test_y.reshape(-1,1) # 测试集y x = test_X x = np.hstack([np.ones((len(x), 1)), x]) # 测试集x #sigmoid函数 def sigmoid(X,theta): return 1/(1+np.exp(-X.dot(theta))) #损失函数 def cost(X,Y,theta): H = sigmoid(X,theta) return (1-Y).T.dot(np.log(1-H+1e-5)) - Y.T.dot((np.log(H+1e-5))) #梯度下降 y_t = [] def Gradient_descent(X,Y,alpha,maxIter): #初始化theta np.random.seed(42) theta = np.mat(np.random.randn(15,1)) loss = cost(X,Y,theta) y_t.append(loss) #更新theta for i in range(maxIter): H = sigmoid(X,theta) dtheta = X.T.dot((H - Y))/len(Y) theta -= alpha*dtheta loss = cost(X,Y,theta) y_t.append(loss) return theta theta = Gradient_descent(X,Y,0.0014,10000) #查看何时收敛 y_t = np.array(y_t) y_t = list(chain.from_iterable(y_t)) plt.plot(y_t) plt.xlabel('iterations') plt.ylabel('loss_value') plt.show() print("梯度下降:") print("theta=") print(theta) # 计算准确率 correct = 0 for Xi, Yi in zip(x,y): pred = sigmoid(Xi,theta) pred = 1 if pred > 0.5 else 0 if pred == Yi: correct += 1 print("正确率:",correct/len(x)) # 计算AUC Y_predict = 1/(1+np.exp(-x.dot(theta))) Y_predict = np.asarray(Y_predict) Y_true = np.asarray(y) auc = roc_auc_score(Y_true,Y_predict) print('AUC=',auc)

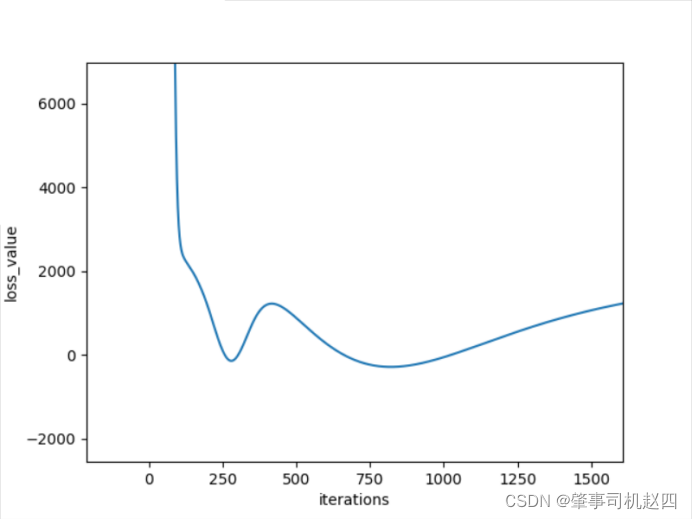



对图1可以看到损失函数在迭代次数为800次左右时候取得了一个最小值,但是当迭代次数为800次时候,准确率仅为64%左右,AUC指标仅为0.54,这说明该分类器对正例和负例毫无区分能力,对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的。显然这种分类器是不乐观的,类似于抛硬币。因此更换迭代次数,当迭代次数为4000次左右时候,可以看到函数基本收敛,此时的准确率为76%,与迭代800次相比要好很多,而且AUC指标也达到了了0.73,。继续增加迭代次数,当迭代到10000次左右时候准确率达到了79%,而迭代次数达到11000次时候准确率又开始下降,因此最好的迭代次数为10000左右,此时的分类效果是最好的,此时的theta值为:

(二)朴素贝叶斯求解
import math import numpy as np import pandas as pd from sklearn.metrics import roc_auc_score data = pd.read_csv('adult.csv',header=None) #去除字符串数值前面的空格 str_cols=[1,3,5,6,7,8,9,13,14] for col in str_cols: data.iloc[:,col]=data.iloc[:,col].map(lambda x: x.strip()) # 删除缺失值样本 data.replace("?",np.nan,inplace=True) data.dropna(inplace=True) # 对字符数据进行编码 from sklearn import preprocessing label_encoder=[] # 放置每一列的encoder encoded_set = np.empty(data.shape) for col in range(data.shape[1]): encoder=None if data.iloc[:,col].dtype==object: # 字符型数据 encoder=preprocessing.LabelEncoder() encoded_set[:,col]=encoder.fit_transform(data.iloc[:,col]) else: # 数值型数据 encoded_set[:,col]=data.iloc[:,col] label_encoder.append(encoder) # 划分训练集与测试集 def splitData(data_list,ratio): train_size = int(len(data_list)*ratio) np.random.seed(44) np.random.shuffle(data_list) train_set = data_list[:train_size] test_set = data_list[train_size:] return train_set,test_set data_list = np.array(encoded_set).tolist() trainset,testset = splitData(data_list,ratio = 0.7) print("朴素贝叶斯求解:") print('Split {0} samples into {1} train and {2} test samples '.format(len(data), len(trainset), len(testset))) # 按类别划分数据 def seprateByClass(dataset): seprate_dict = {} info_dict = {} for vector in dataset: if vector[-1] not in seprate_dict: seprate_dict[vector[-1]] = [] info_dict[vector[-1]] = 0 seprate_dict[vector[-1]].append(vector) info_dict[vector[-1]] +=1 return seprate_dict,info_dict train_separated,train_info = seprateByClass(trainset) #划分好的数据 # 计算每个类别的先验概率(P(yi)) def calulateClassPriorProb(dataset,dataset_info): dataset_prior_prob = {} sample_sum = len(dataset) for class_value, sample_nums in dataset_info.items(): dataset_prior_prob[class_value] = sample_nums/float(sample_sum) return dataset_prior_prob prior_prob = calulateClassPriorProb(trainset,train_info) # 每个类别的先验概率(P(yi)) # 均值 def mean(list): list = [float(x) for x in list] #字符串转数字 return sum(list)/float(len(list)) # 方差 def var(list): list = [float(x) for x in list] avg = mean(list) var = sum([math.pow((x-avg),2) for x in list])/float(len(list)-1) return var # 概率密度函数 def calculateProb(x,mean,var): exponent = math.exp(math.pow((x-mean),2)/(-2*var)) p = (1/math.sqrt(2*math.pi*var))*exponent return p # 计算每个属性的均值和方差 def summarizeAttribute(dataset): dataset = np.delete(dataset,-1,axis = 1) # delete label summaries = [(mean(attr),var(attr)) for attr in zip(*dataset)] #按列提取 return summaries # 按类别提取属性特征 会得到 类别数目*属性数目 组 def summarizeByClass(dataset): summarize_by_class = {} for classValue, vector in train_separated.items(): summarize_by_class[classValue] = summarizeAttribute(vector) return summarize_by_class train_Summary_by_class = summarizeByClass(trainset) # 按类别提取属性特征 #计算属于某类的类条件概率(P(x|yi)) def calculateClassProb(input_data,train_Summary_by_class): prob = {} for class_value, summary in train_Summary_by_class.items(): prob[class_value] = 1 for i in range(len(summary)): mean,var = summary[i] x = input_data[i] p = calculateProb(x,mean,var) prob[class_value] *=p return prob # 朴素贝叶斯分类器 def bayesianPredictOneSample(input_data): classprob_dict = calculateClassProb(input_data,train_Summary_by_class) # 计算属于某类的类条件概率(P(x|yi)) result = {} for class_value,class_prob in classprob_dict.items(): p = class_prob*prior_prob[class_value] result[class_value] = p return max(result,key=result.get) # 单个样本测试 # print(testset[6][14]) # input_vector = testset[6] # input_data = input_vector[:-1] # result = bayesianPredictOneSample(input_data) # print("the sameple is predicted to class: {0}.".format(result)) # 计算准确率 save = [] def calculateAccByBeyesian(dataset): correct = 0 for vector in dataset: input_data = vector[:-1] label = vector[-1] result = bayesianPredictOneSample(input_data) save.append(result) if result == label: correct+=1 return correct/len(dataset) acc = calculateAccByBeyesian(testset) print("正确率:",acc) #计算AUC Y_predict = np.array(save) temp = np.array(testset) Y_true = np.array(temp[:,-1]) auc = roc_auc_score(Y_true,Y_predict) print('AUC=',auc)

可以看到朴素贝叶斯算法相较于梯度下降其准确率提高了一点,但是其AUC指标却明显低很多,仅为0.64。理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,而实际生活中要想属性之间是相互独立的是不太实际的,就比如数据集中的工作时间和国籍,不同的国家之间的工作时间是不一样的,而且每个国家之间的收入也是不同的。
