在深度学习的世界里,注意力机制(Attention Mechanism)是一种强大的技术,被广泛应用于自然语言处理(NLP)和计算机视觉(CV)领域。它可以帮助模型在处理复杂任务时更加关注重要信息,从而提高性能。在本文中,我们将详细介绍注意力机制的原理,并使用 Python 和 TensorFlow/Keras 实现一个简单的注意力机制模型。
1. 注意力机制简介
注意力机制最初是为了解决机器翻译中的长距离依赖问题而提出的。其核心思想是:在处理输入序列时,模型可以动态地为每个输入元素分配不同的重要性权重,使得模型能够更加关注与当前任务相关的信息。
1.1 注意力机制的基本原理
注意力机制通常包括以下几个步骤:
- 计算注意力得分:根据查询向量(Query)和键向量(Key)计算注意力得分。常用的方法包括点积注意力(Dot-Product Attention)和加性注意力(Additive Attention)。
- 计算注意力权重:将注意力得分通过 softmax 函数转化为权重,使其和为1。
- 加权求和:使用注意力权重对值向量(Value)进行加权求和,得到注意力输出。
1.2 点积注意力公式
点积注意力的公式如下:
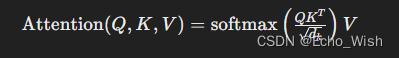
其中:
- Q 是查询矩阵
- K 是键矩阵
- V 是值矩阵
- 𝑑k 是键向量的维度
2. 使用 Python 和 TensorFlow/Keras 实现注意力机制
下面我们将使用 TensorFlow/Keras 实现一个简单的注意力机制,并应用于文本分类任务。
2.1 安装 TensorFlow
首先,确保安装了 TensorFlow:
pip install tensorflow
2.2 数据准备
我们将使用 IMDB 电影评论数据集,这是一个二分类任务(正面评论和负面评论)。
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 加载 IMDB 数据集
max_features = 10000 # 仅使用数据集中前 10000 个最常见的单词
max_len = 200 # 每个评论的最大长度
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
# 将每个评论填充/截断为 max_len 长度
x_train = pad_sequences(x_train, maxlen=max_len)
x_test = pad_sequences(x_test, maxlen=max_len)
2.3 实现注意力机制层
from tensorflow.keras.layers import Layer
import tensorflow.keras.backend as K
class Attention(Layer):
def __init__(self, **kwargs):
super(Attention, self).__init__(**kwargs)
def build(self, input_shape):
self.W = self.add_weight(name='attention_weight', shape=(input_shape[-1], input_shape[-1]), initializer='glorot_uniform', trainable=True)
self.b = self.add_weight(name='attention_bias', shape=(input_shape[-1],), initializer='zeros', trainable=True)
super(Attention, self).build(input_shape)
def call(self, x):
# 打分函数
e = K.tanh(K.dot(x, self.W) + self.b)
# 计算注意力权重
a = K.softmax(e, axis=1)
# 加权求和
output = x * a
return K.sum(output, axis=1)
def compute_output_shape(self, input_shape):
return input_shape[0], input_shape[-1]
2.4 构建和训练模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
# 构建模型
model = Sequential()
model.add(Embedding(input_dim=max_features, output_dim=128, input_length=max_len))
model.add(LSTM(64, return_sequences=True))
model.add(Attention())
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
history = model.fit(x_train, y_train, epochs=5, batch_size=32, validation_split=0.2)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'Test Accuracy: {test_acc}')
2.5 代码详解
- 数据准备:加载并预处理 IMDB 数据集,将每条评论填充/截断为相同长度。
- 注意力机制层:实现一个自定义的注意力机制层,包括打分函数、计算注意力权重和加权求和。
- 构建模型:构建包含嵌入层、LSTM 层和注意力机制层的模型,用于处理文本分类任务。
- 训练和评估:编译并训练模型,然后在测试集上评估模型的性能。
3. 总结
在本文中,我们介绍了注意力机制的基本原理,并使用 Python 和 TensorFlow/Keras 实现了一个简单的注意力机制模型应用于文本分类任务。希望这篇教程能帮助你理解注意力机制的基本概念和实现方法!随着对注意力机制理解的深入,你可以尝试将其应用于更复杂的任务和模型中,如 Transformer 和 BERT 等先进的 NLP 模型。
