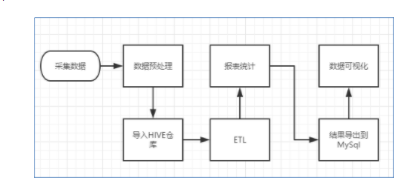
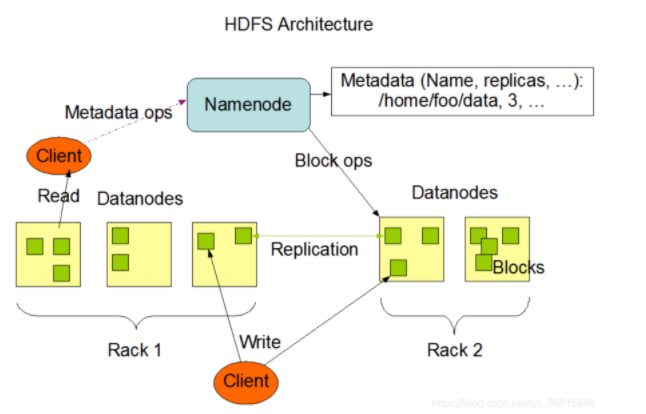
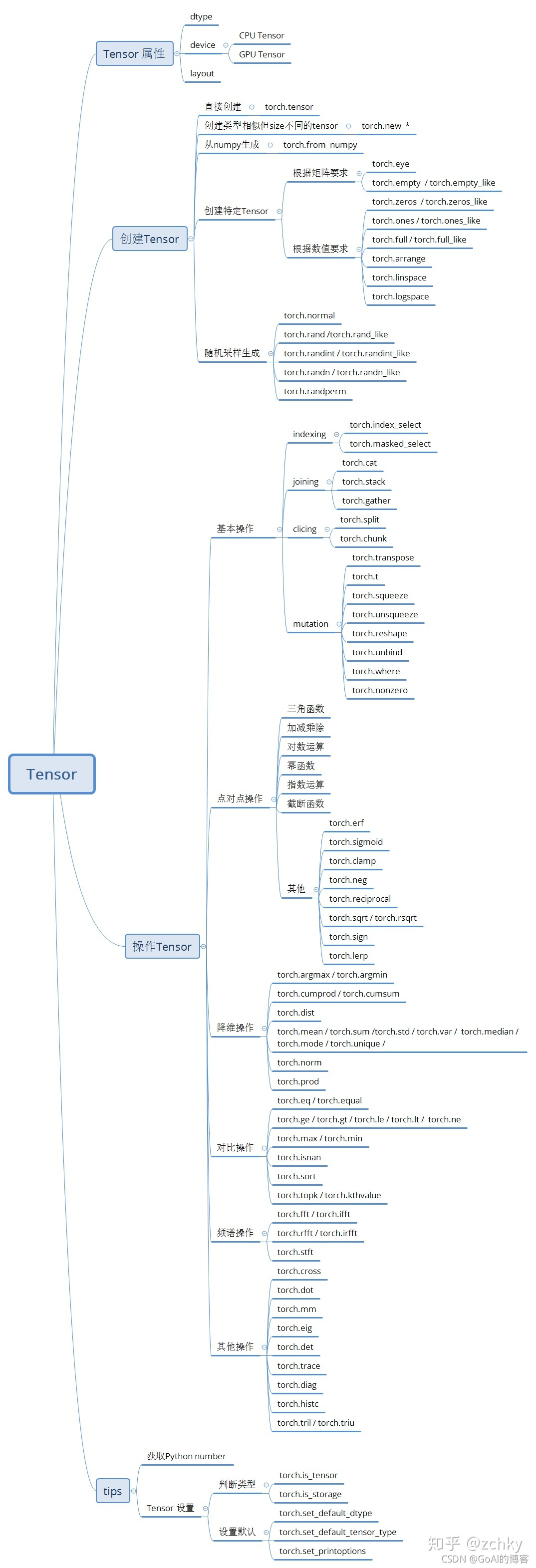
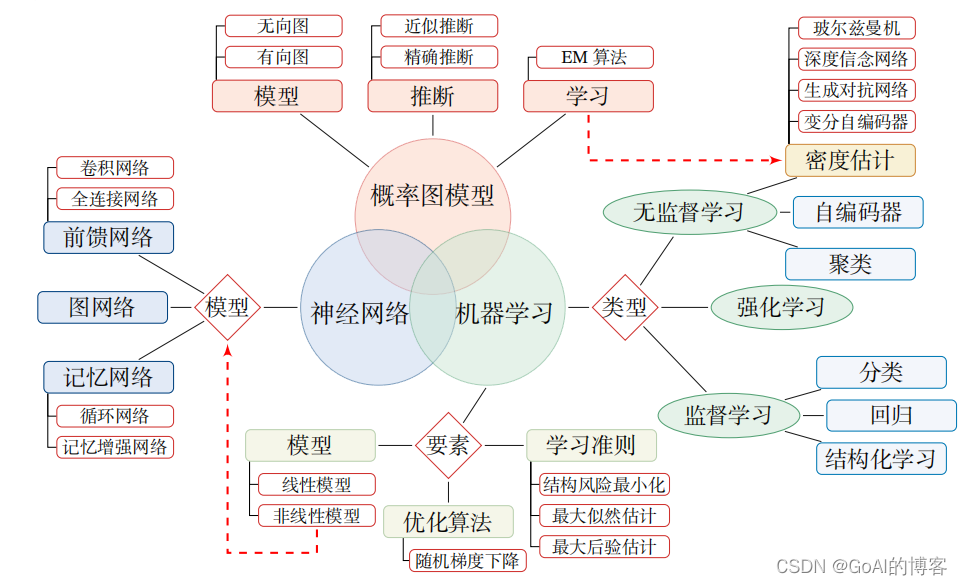
暂时未有相关云产品技术能力~
专注大数据与人工智能技术分享,个人博客:https://blog.csdn.net/qq_36816848
新闻物料爬取:主要采用scrapy爬虫工具,在每天晚上23点将当天的新闻内容从网页中进行抓取,存入MongoDB的SinaNews数据库中。
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。 在高负载的情况下,添加更多的节点,可以保证服务器性能。 MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
创建conda虚拟环境: conda create -n news_rec_py3 python=3.8 安装依赖文件: pip install -r requirements.txt
近几年来,CRNN在计算机视觉文本识别领域取得不错成果。CRNN是一种卷积循环神经网络结构,用于解决基于图像的序列识别问题,特别是场景文字识别问题。CRNN网络实现了不定长验证结合CNN和RNN网络结构,使用双向LSTM循环网络进行时序训练,并在最后引入CTC损失函数来实现端对端的不定长序列识别,
LSTM算法是一种重要的目前使用最多的时间序列算法,是一种特殊的RNN(Recurrent Neural Network,循环神经网络),能够学习长期的依赖关系。主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
RNN是一种特殊的神经网络结构, 它是根据"人的认知是基于过往的经验和记忆"这一观点提出的. 它与DNN,CNN不同的是: 它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种'记忆'功能.
上世纪60年代,Hubel等人通过对猫视觉皮层细胞的研究,提出了感受野这个概念,到80年代,Fukushima在感受野概念的基础之上提出了神经认知机的概念,可以看作是卷积神经网络的第一个实现网络,神经认知机将一个视觉模式分解成许多子模式(特征),然后进入分层递阶式相连的特征平面进行处理,它试图将视觉系统模型化,使其能够在即使物体有位移或轻微变形的时候,也能完成识别。
人工智能分类:强人工智能、弱人工智能、超级人工智能 机器学习分类:有监督学习、无监督学习、强化学习
入库,设置随机种子
在本次学习中,我们将对具有 6 个类的数据集执行分类。请注意,该数据集实际上并不是情感分析数据集,而是问题数据集,任务是对问题所属的类别进行分类。但是,本次学习中涵盖的所有内容都适用于任何包含属于 𝐶C 类之一的输入序列的示例的数据集。
能够从局部输入图像块中提取特征,并能将表示模块化,同时可以高效第利用数据 可以用于处理时序数据,时间可以被看作一个空间维度,就像二维图像的高度和宽度 那么为什么要在文本上使用卷积神经网络呢?
其他文本分类模型最大的不同之处在于其计算了输入句子的n-gram
首先设置seed,并将其分类训练、测试、验证集。
IMDb数据集包含50000条电影评论,每条评论都标记为正面或负面评论
本质上是一个分类任务,其一般是指判断一段文本所表达的情绪状态。其中,一段文本可以是一个句子,一个段落或一个文档。情绪状态可以是两类,如(正面,负面),(高兴,悲伤);也可以是三类,如(积极,消极,中性);或是星级(1星~五星)等等。总的来说,可以理解成:是对带有情感色彩的主观性文本进行数据挖掘与情感倾向分析的过程。
进一步学习机器学习基础,希望以后有机会多多实践,为以后进入这个领域做准备。
CNN常常被用在影像处理上,比如说你想要做影像的分类,就是training一个neural network,input一张图片,然后把这张图片表示成里面的像素(pixel),也就是很长很长的矢量(vector)。output就是(假如你有1000个类别,output就是1000个dimension)dimension。
局部最小值saddle point和鞍点local minima
Step1:神经网络(Neural network) Step2:模型评估(Goodness of function) Step3:选择最优函数(Pick best function)
Regression 就是找到一个函数 function ,通过输入特征 x,输出一个数值 Scalar。
机器学习(Machine Learning),就是让机器自动找函数。如语音识别,就是让机器找一个函数,输入是声音信号,输出是对应的文字。如下棋,就是让机器找一个函数,输入是当前棋盘上黑子白子的位置,输出是下一步应该落子何处。
LightGBM是2017年由微软推出的可扩展机器学习系统,是微软旗下DMKT的一个开源项目,由2014年首届阿里巴巴大数据竞赛获胜者之一柯国霖老师带领开发。它是一款基于GBDT(梯度提升决策树)算法的分布式梯度提升框架,为了满足缩短模型计算时间的需求,LightGBM的设计思路主要集中在减小数据对内存与计算性能的使用,以及减少多机器并行计算时的通讯代价
XGBoost是2016年由华盛顿大学陈天奇老师带领开发的一个可扩展机器学习系统。严格意义上讲XGBoost并不是一种模型,而是一个可供用户轻松解决分类、回归或排序问题的软件包。它内部实现了梯度提升树(GBDT)模型,并对模型中的算法进行了诸多优化,在取得高精度的同时又保持了极快的速度,在一段时间内成为了国内外数据挖掘、机器学习领域中的大规模杀伤性武器。
支持向量机(Support Vector Machine),简称SVM,是一种经典的二分类模型,属于监督学习算法。
神经网络起源于生物神经元的生物原理,生物神经元通常包括细胞体、树突和轴突等部分。其中,树突适用于接受输入信息,突触对输入信息进行处理,达到一定条件后由轴突产生输出,此时神经元表现为激活兴奋的状态。
基于树结构来进行决策,体现人类在面临决策问题时一种很自然的处理机制
对分类变量缺失值:填充某个缺失值字符(NA)、用最多类别的进行填充 对连续变量缺失值:填充均值、中位数、众数
回归任务最常用的性能度量是均方误差,因为均方误差有比较好的几何意义,对应了最常用的**“欧氏距离”,最小二乘法就是基于均方误差进行模型求解的。 求解均方误差最小化的过程称为参数估计
动手学习数据分析(四)——数据可视化
首先导入numpy、pandas包和数据文件
该数据集缺失的都是类别特征里的,且部分类别特征与某些匿名变量线性相关性强 考虑填充新的值,比如-1 填充众数、平均数(需要取整),knn邻近(速度慢)
动手学习数据分析(一)——数据探索性分析
数据集:所有数据的集合 训练集:训练样本的集合 属性(特征):某事物或对象在某方面表现的性质 属性值:属性的取值 属性空间/样本空间/输入空间:属性张成的空间 泛化能力:学得模型适用于新样本的能力(泛化能力强更好地适用于样本空间)
python操作excel主要用到openpyxl库。其主要针对xlsx格式的excel进行读取和编辑。下面简单介绍其使用方法及命令。除openpyxl库外,还有xlwt及xlwd也可以对excel表格实现同样操作。
集成学习-蒸汽量预测案例
本次案例来源于天池的一个比赛,赛题使用 139 维的特征,使用 8000 余组数据进行对于个人幸福感的预测(预测值为1,2,3,4,5,其中1代表幸福感最低,5代 表幸福感最高)。以均方误差MSE为评价标准,因为评价标准为均方误差,所以使用回归问题的思路解决该问.
tacking是通过一个元分类器或者元回归器来整合多个分类模型或回归模型的集成学习技术。基础模型利用整个训练集做训练,元模型将基础模型的特征作为特征进行训练。
集成学习(又称模型融合)就是结合若干个体分类器(基学习器)进行综合预测,各个个体学习器通常是弱学习器。集成学习相较于个体学习在预测准确率以及稳定性上都有很大的提高。
kettle主要用于数据清洗,即常见ETL工具,拥有图形化界面且免费的优点。
模型融合是kaggle等比赛中经常使用到的一个利器,它通常可以在各种不同的机器学习任务中使结果获得提升。顾名思义,模型融合就是综合考虑不同模型的情况,并将它们的结果融合到一起。模型融合主要通过几部分来实现:从提交结果文件中融合、stacking和blending。
利用xgb进行五折交叉验证查看模型的参数效果
数据挖掘-二手车价格预测 Task03:特征工程
数据挖掘-二手车价格预测 Task02:数据分析
赛题以预测二手车的交易价格为任务,数据集来自某交易平台的二手车交易记录,总数据量超过40w,包含31列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取15万条作为训练集,5万条作为测试集A,5万条作为测试集B,同时会对name、model、brand和regionCode等信息进行脱敏。
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。
简单介绍了前四种算法,线性回归、逻辑回归、决策树以及随机森林,其中后三种算法都比较常用,特别是逻辑回归算法特别常用,在很多算法比赛中,都会考虑先实现一个逻辑回归算法来跑通整个算法流程,再考虑替换根据复杂的算法模型。而随机森林算是决策树的升级版,性能更好,而且它还能用于评估特征的重要性,可以做特征选择,属于三大特征选择方法中的最后一种,嵌入式选择方法,学习器会自动选择特征。
Deep Interest Network(DIN)是盖坤大神领导的阿里妈妈的精准定向检索及基础算法团队,在2017年6月提出的。 它针对电子商务领域(e-commerce industry)的CTR预估,重点在于充分利用/挖掘用户历史行为数据中的信息。
FM对于特征的组合仅限于二阶,缺少对特征之间深层次关系的抽取。因此,NFM提出来就是在FM的基础上引入神经网络,实现对特征的深层次抽取。
在DeepFM提出之前,已有LR,FM,FFM,FNN,PNN(以及三种变体:IPNN,OPNN,PNN*),Wide&Deep模型,这些模型在CTR或者是推荐系统中被广泛使用。
Wide部分主要作用是让模型具备较强的“记忆能力”;Deep部分的主要作用是让模型具有“泛化能力”。
 发表了文章
2022-10-24
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-24
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20