暂时未有相关云产品技术能力~
专注大数据与人工智能技术分享,个人博客:https://blog.csdn.net/qq_36816848
大数据常见运维问题汇总
2016年,微软提出Deep Crossing模型,旨在解决特征工程中特征组合的难题,降低人力特征组合的时间开销,通过模型自动学习特征的组合方式,也能达到不错的效果,且在各种任务中表现出较好的稳定性。与之前介绍的FNN、PNN不同的是,Deep Crossing并没有采用显式交叉特征的方式,而是利用残差网络结构挖掘特征间的关系。本文将对DeepCrossing从原理到实现细节进行详细分析。
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。
leetcode笔记(Python版)待更新
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率).
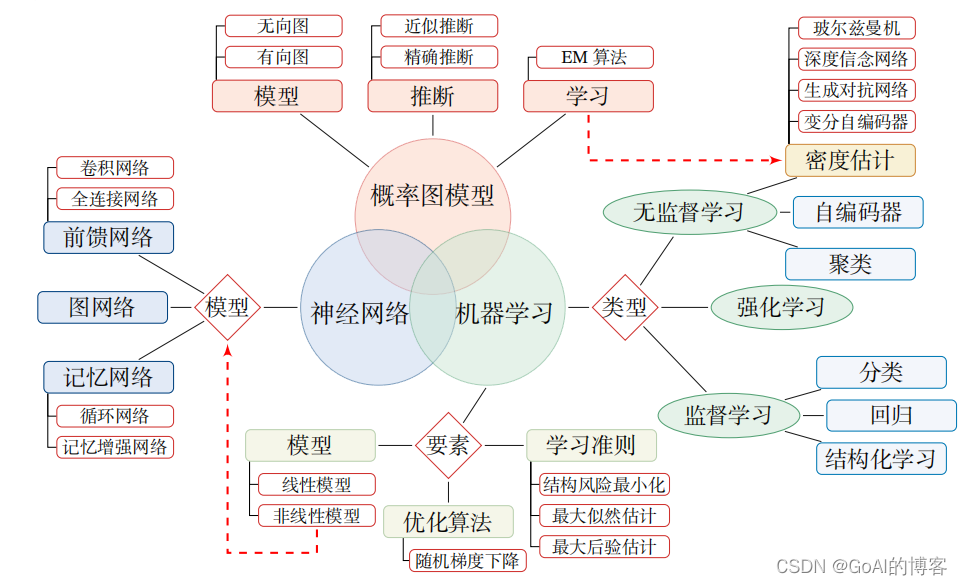
决策树是一个非常常见并且优秀的机器学习算法,它易于理解、可解释性强,其可作为分类算法,也可用于回归模型。
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。并且 Flink 提供了数据分布、容错机制以及资源管理等核心功能。Flink提供了诸多高抽象层的API以便用户编写分布式任务
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。并且 Flink 提供了数据分布、容错机制以及资源管理等核心功能。Flink提供了诸多高抽象层的API以便用户编写分布式任务
Flink: 分布式、高性能框架,支持实时模式和批处理模式
协同过滤算法是一种较为著名和常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。也就是常见的“猜你喜欢”,和“购买了该商品的人也喜欢”等功能。
大数据电商数仓项目
实战代码参考:GitHub - GoAlers/Bigdata_project: 电商大数据项目-推荐系统(java和scala语言)
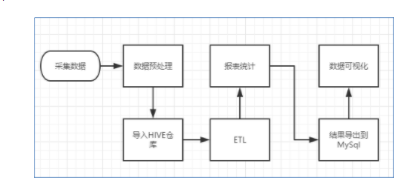
网络发展迅速的时代,越来越多人通过网络获取跟多的信息或通过网络作一番自己的事业,当投身于搭建属于自己的网站、APP或小程序时会发现,经过一段时间经营和维护发现浏览量和用户数量的增长速度始终没有提升。在对其进行设计改造时无从下手,当在不了解用户的浏览喜欢和个用户群体的喜好。虽然服务器日志中明确的记载了用户访浏览的喜好但是通过普通方式很难从大量的日志中及时有效的筛选出优质信息。Spark Streaming是一个实时的流计算框架,该技术可以对数据进行实时快速的分析,通过与Flume、Kafka的结合能够做到近乎零延迟的数据统计分析。
Nginx服务器日志相关指令主要有两条:一条是log_format,用来设置日志格式;另外一条是access_log,用来指定日志文件的存放路径、格式和缓存大小,可以参加ngx_http_log_module。一般在nginx的配置文件中日记配置
在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
数据仓库,英文名为Data Warehouse,简写为DW或DWH。数据仓库,是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
Spark Streaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,可以使用诸如map、reduce、join等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,处理结果保存到HDFS,数据库等。
Kafka分布式流式处理
1、分布式消息队列系统,先入先出,同时提供数据分布式缓存功能 2、消息持久化:数据读取速度可以达到O(1)——预读,后写(按顺序,ABCDE,正读A,预读B;尾部追加写)对磁盘的顺序访问比内存访问还快)
Flume是数据采集,日志收集的框架,通过分布式形式进行采集,(高可用分布式)
针对常规电商网站进行大数据分析,通过完整大数据处理流程最终对每个区域热门商品进行统计,支持用户决策。
Scala学习总结
UI矩阵–>II矩阵–>排序
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引。
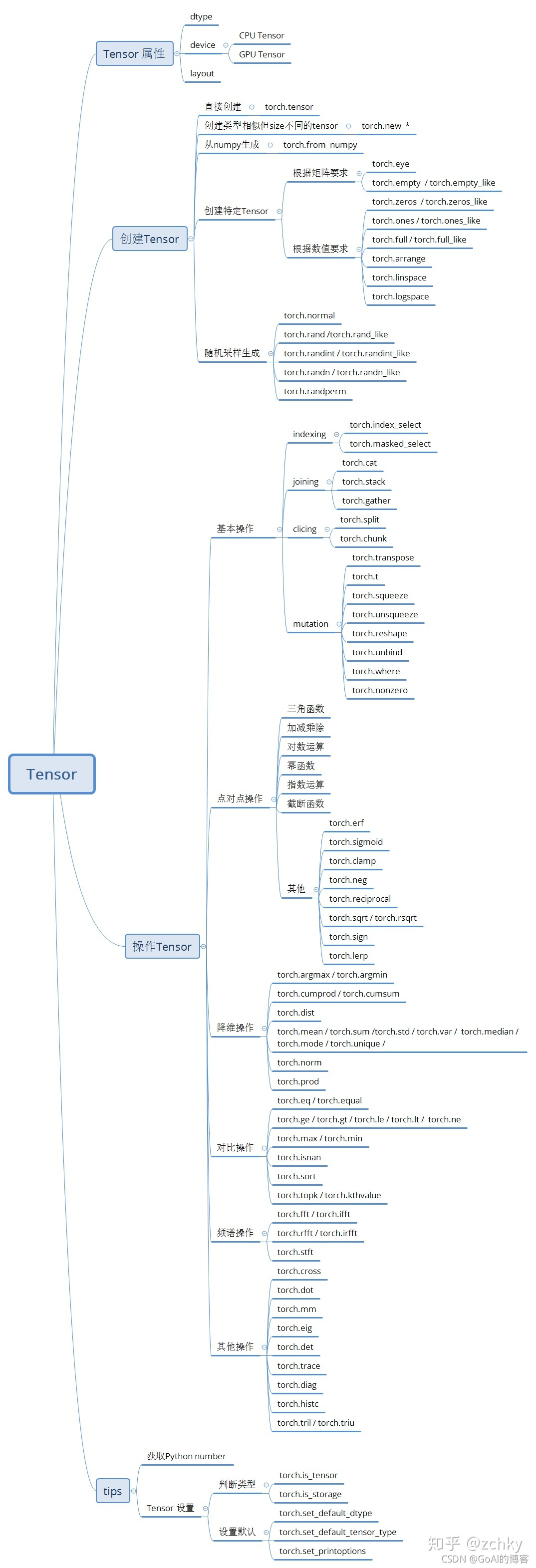
Python知识笔记总结
首先安装Centos系统修改网络配置 我的三台机器: master 192.168.179.10 slave1 192.168.179.11 slava2 192.168.179.12
大数据常见端口汇总:
ZooKeeper 是一个开源的分布式协调服务。它是一个为分布式应用提供一致性服务的软件,分布式应用程序可以基于 Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。 ZooKeeper 的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper 是一个开源的分布式协调服务。它是一个为分布式应用提供一致性服务的软件,分布式应用程序可以基于 Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。 ZooKeeper 的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
(要求先配置好hadoop环境,版本hadoop2皆可,先启动zookeeper)
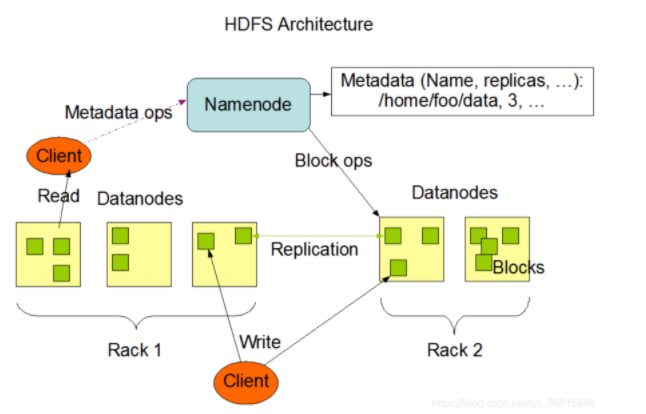
HBase 本质上是一个数据模型,可以提供快速随机访问海量结构化数据。利用 Hadoop 的文件系统(HDFS)提供的容错能 力。它是 Hadoop 的生态系统,使用 HBase 在 HDFS 读取消费/随机访问数据,是 Hadoop 文件系统的一部分。
Hive调优策略
Hive主要解决海量结构化日志的数据统计分析,它是hadoop上的一种数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类似于SQL的查询方式,本质上来说是将Hive转化成MR程序。
MapReduce是采用一种分而治之的思想设计出来的分布式计算框架,它由两个阶段组成:map阶段和reduce阶段。
Apache Hadoop YARN 是 apache Software Foundation Hadoop的子项目,为分离Hadoop2.0资源管理和计算组件而引入。YARN的诞生缘于存储于HDFS的数据需要更多的交互模式,不单单是MapReduce模式。Hadoop2.0 的YARN 架构提供了更多的处理框架,不再强迫使用MapReduce框架。
总结:Hadoop由三部分组成:HDFS、分布式计算MapReduce和资源调度引擎Yarn。
以电商数据为基础,详细介绍数据处理流程,结合hive数仓、spark开发采用多种方式实现大数据分析。
学习: 数据处理流程总结
Flink快速上手 --链接:百度网盘 请输入提取码 提取码:1234 Flink: 分布式、高性能框架,支持实时模式和批处理模式
数据仓库:英文Data WareHouse,数据仓库是面向主题,为分析数据而设计的,是一个各种数据(包括历史数据和当前数据)的中心存储系统,主要服务于商业智能(也就是BI)和企业决策管理。
Spark Streaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,可以使用诸如map、reduce、join等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,处理结果保存到HDFS,数据库等。
Spark Streaming接收Kafka、Flume、HDFS等各种来源的实时输入数据,可以使用诸如map、reduce、join等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,处理结果保存到HDFS,数据库等。
推荐系统是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程。个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。
提交任务参数请参考这篇文章(包括优化建议):Spark部署模式、任务提交 - GoAl
SparkSQL实战:统计用户及商品数据指标,包含以下三张表
pring boot集成了tomcat等容器,效率更高,要实现数据的可视化,需要构建spring Boot框架架构web项目。同时使用注意的方式,就可以轻松建立前端访问路径与后端controller方法的映射关系,而不用像servlet一样维护繁琐的xml映射配置表。
Spark SQL:将sql转换成spark任务
项目描述:利用各类元数据为特征构建推荐系统,使用cb、cf算法做推荐召回,使用redis数据库做缓存处理,结合机器学习LR推荐排序,实现推荐引擎搭建。
TF-IDF:衡量某个词对文章的重要性由TF和IDF组成 TF:词频(因素:某词在同一文章中出现次数) IDF:反文档频率(因素:某词是否在不同文章中出现) TF-IDF = TF*IDF TF :一个单词在一篇文章出现次数越多越重要 IDF: 每篇文章都出现的单词(如的,你,我,他) ,越不重要
Hadoop:Hadoop是一个分布式存储和计算框架,具有高可靠, 高扩展, 高容错的特点(数据副本和集群);由底层HDFS分布式文件系统负责存储,和MapReduce负责分布式计算,以及后续增加的yarn负责资源协调管理。
 发表了文章
2022-10-24
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-24
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-21
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20
发表了文章
2022-10-20