










nginx在云平台服务几个典型代理场景中的应用案例
在云平台服务中有多种场景需要使用到反向代理,常见的应用场景包括:内网专有云平台访问公网资源、公有云平台访问客户内网IDC机房资源、云产品通过代理访问多个不同的资源等等。笔者总结几种场景配置nginx的7层反向代理、4层反向代理,巧妙实现应用需求。
FlashAttention算法详解
这篇文章的目的是详细的解释Flash Attention,为什么要解释FlashAttention呢?因为FlashAttention 是一种重新排序注意力计算的算法,它无需任何近似即可加速注意力计算并减少内存占用。所以作为目前LLM的模型加速它是一个非常好的解决方案,本文介绍经典的V1版本,最新的V2做了其他优化我们这里暂时不介绍。因为V1版的FlashAttention号称可以提速5-10倍,所以我们来研究一下它到底是怎么实现的。
【Deep Learning A情感文本分类实战】2023 Pytorch+Bert、Roberta+TextCNN、BiLstm、Lstm等实现IMDB情感文本分类完整项目(项目已开源)
亮点:代码开源+结构清晰+准确率高+保姆级解析 🍊本项目使用Pytorch框架,使用上游语言模型+下游网络模型的结构实现IMDB情感分析 🍊语言模型可选择Bert、Roberta 🍊神经网络模型可选择BiLstm、LSTM、TextCNN、Rnn、Gru、Fnn共6种 🍊语言模型和网络模型扩展性较好,方便读者自己对模型进行修改
IM开发者的零基础通信技术入门(十二):上网卡顿?网络掉线?一文即懂!
本文将详细介绍生活中遇到的常见网络问题,及可能的解决方法,虽说是一篇技术文章,但内容将一如既往地通俗易懂,简单实用。

Spark on k8s 在阿里云 EMR 的优化实践
本文整理自阿里云技术专家范佚伦在7月17日阿里云数据湖技术专场交流会的分享。



MaxCompute湖仓一体介绍
本篇内容分享了MaxCompute湖仓一体介绍。 分享人:孟硕 阿里云 MaxCompute产品专家
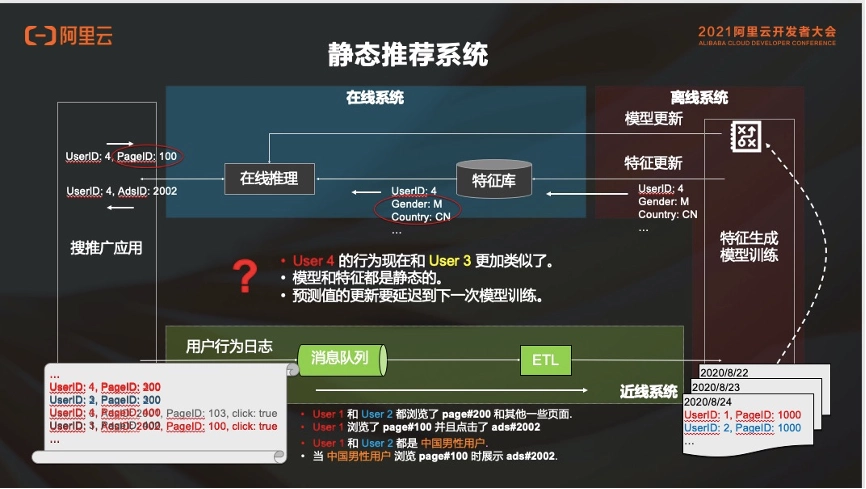
基于实时深度学习的推荐系统架构设计和技术演进
整理自 5 月 29 日 阿里云开发者大会,秦江杰和刘童璇的分享,内容包括实时推荐系统的原理以及什么是实时推荐系统、整体系统的架构及如何在阿里云上面实现,以及关于深度学习的细节介绍
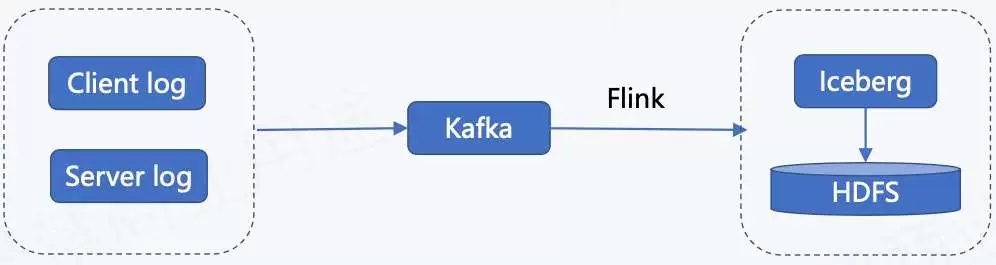
汽车之家:基于 Flink + Iceberg 的湖仓一体架构实践
由汽车之家实时计算平台负责人邸星星在 4 月 17 日上海站 Meetup 分享的,基于 Flink + Iceberg 的湖仓一体架构实践。
UDF精简使用大全
在MaxCompute开发过程中,开发同学遇到的的一些复杂逻辑该如何处理,如何在MaxCompute开发不同场景下的UDF函数?带着这个问题,本文针对UDF的各方面内容做出介绍,其中涉及UDF对应不同语言的类型映射关系、以及对应UDF在重载、访问网络、引用表与资源、以及第三方包的使用为大家做出展示。


【最佳实践】阿里云 Elasticsearch 索引数据生命周期管理
索引生命周期管理(ILM)是指:ES数据索引从设置,创建,打开,关闭,删除的全生命周期过程的管理;为了降低索引存储成本,提升集群性能和执行效率,我们可以通过对存储在阿里云 Elasticsearch 的数据做生命周期管理。
BasicEngine — 基于DII平台的推荐召回引擎
BasicEngine是阿里巴巴搜索事业部自研的推荐在线召回引擎,依托强大的搜索底层技术支持,可以在线实现复杂的关联排序运算,支持灵活的推荐策略组合,为推荐系统的升级发展拓展了无限想象空间。
【X-Pack解读】阿里云Elasticsearch X-Pack 监控组件功能详解
阿里云Elasticsearch集成了Elastic Stack商业版的X-Pack组件包,包括安全、告警、监控、报表生成、图分析、机器学习等组件,用户可以开箱即用。本文将对X-Pack 的监控组件功能进行详细解读。
【技术实验】mysql准实时同步数据到Elasticsearch
Elasticsearch作为大数据场景下搜索和分析的引擎,广泛应用于实时数据分析等场景。本文作者梳理了从MySQL准实时同步数据到Elasticsearch的实操步骤,帮助开发者理解和快速上手。

【大数据干货】轻松处理每天2TB的日志数据,支撑运营团队进行大数据分析挖掘,随时洞察用户个性化需求。
“用户每天产生的日志量大约在2TB。我们需要将这些海量的数据导入云端,然后分天、分小时的展开数据分析作业,分析结果再导入数据库和报表系统,最终展示在运营人员面前。”墨迹天气运维部经理章汉龙介绍,整个过程中数据量庞大,且计算复杂,这对云平台的大数据能力、生态完整性和开放性提
流计算精品翻译: The Dataflow Model
我们提出了Dataflow模型,并详细地阐述了它的语义,设计的核心原则,以及在实践开发过程中对模型的检验。
【玩转数据系列五】农业贷款发放预测
很多农民因为缺乏资金,在每年耕种前会向相关机构申请贷款来购买种地需要的物资,等丰收之后偿还。农业贷款发放问题是一个典型的数据挖掘问题。贷款发放人通过往年的数据,包括贷款人的年收入、种植的作物种类、历史借贷信息等特征来构建经验模型,通过这个模型来预测受贷人的还款能力。
数据库开放权限太危险,又不想写API。DataV给你另外一个选择。
~ DataV 后台21日晚上线,现在暂时还不能用哦 ~ DataV 增加了一个新的数据代理协议,旨在提供更安全的数据查询。它将 SQL 查询字符串和数据库 id 加密后传到这个应用,而后这个应用连接数据库将查询后的结果返回到 DataV 的页面中。 根据新的协议,我做了一个示例应用在githu
ajax请求总是不成功?浏览器的同源策略和跨域问题详解
XMLHttpRequest cannot load http://oldwang.com/isdad. No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://xiao
告别传统Prompt写法!聚AI提示词工程新范式
本章系统讲解Python提示词工程实战,涵盖专业环境搭建、API调用与结构化响应、企业级模板引擎及多步骤对话管理,并延伸至Prompt迭代优化、外部工具集成与性能监控,助力构建工业级AI应用系统。(239字)
#Nginx教程 Nginx作为目前最流行的高性能Web服务器和反向代理服务器,凭借其高并发、低内存消耗的特点,被广泛应用于各类生产环境。本文将从零开始,带你快速掌握Nginx的核心配置与实战技巧。
本教程详解Nginx安装、核心配置、反向代理、负载均衡与HTTPS部署,并内嵌标准JSON-LD结构化数据(Article/BreadcrumbList/WebPage等),助力SEO优化与搜索富摘要展现,提升点击率。
数据智能行业投融资趋势出现了哪些新变化,为什么语义层技术更受关注?
截至2026年4月初,数据智能行业投融资出现了一个很明确的新变化:资本关注点正从“通用大模型能力展示”转向“能否进入企业真实数据生产链路”,其中语义层、本体语义层、指标治理与跨系统问数能力因此明显升温。更具体地看,当前市场大致可分为预置SQL/问答对路线、Text2SQL+宽表路线、指标平台路线,以及语义层/本体语义层路线
AI 成为主流负载后,数据基础设施将如何演进?|Apache Doris 2026 Roadmap
Scale Intelligence, Accelerate Insight,不仅是年度主题,也定义了 Doris 在 AI 时代的演进方向。
PAI-Rec 召回引擎:构建高性能推荐系统的核心引擎
PAI-Rec是阿里云智能推荐平台的核心召回引擎,经阿里大规模场景验证。支持多路召回融合(U2I/I2I/向量/随机)、召回即过滤、毫秒级实时更新与分布式弹性架构,开箱即用,助力企业构建毫秒级、高精度、强实时的推荐系统。
我学GEO的第一天:原来AI搜东西和百度完全不一样
第1天学GEO,我发现:以前做SEO是让网页排得靠前,现在做GEO是让AI直接提到你。我用这篇文章做了第一个实验,一个月后告诉你结果。
1949AI 轻量化 AI 自动化办公场景应用方案 本地自动化工具与浏览器自动化实践
1949AI是一款轻量化AI办公自动化工具,基于Python实现,无需高性能算力,支持本地文件处理、网页数据抓取与Agent自主调度。模块化设计、低资源占用、全程离线运行,适配个人开发者与小型团队,安全合规、开箱即用。(239字)

50%的人给了差评:龙虾为何在技术论坛翻车了?
OpenClaw(龙虾)AI工具因“自动赚钱”“代约主播”等夸张宣传走红,但吾爱破解论坛投票显示:50%技术用户未下载且不认可其能力。技术圈冷静源于见惯“神器”泡沫——AI擅写代码(搬砖),却难懂需求、统筹系统。它不是神药,而是待磨的砍柴刀。
LitBuy反向海淘代购系统搭建指南
本平台提供“链接代购+集运”一站式跨境服务:海外用户粘贴淘宝/1688链接,系统自动解析、代采、合箱质检、国际配送。核心盈利来自物流差价、代购费、汇率差及增值服务。支持多语言、多币种、主流跨境支付与全链路追踪。(239字)
别再“随缘提问”了:聊聊 LLM 的 Prompt Design,怎么把大模型调教得更靠谱?
别再“随缘提问”了:聊聊 LLM 的 Prompt Design,怎么把大模型调教得更靠谱?
GEO时代,普通人也能抓住的AI红利
本文介绍“生成式引擎优化”(GEO)——普通人弯道超车的新机会。在AI搜索时代,无需烧钱投流,只需将真实专业经验结构化输出(如装修坑点、育儿知识),就能被ChatGPT等AI高频引用,获精准流量。早入局,竞争小,见效快。
咨询还是平台?企业启动GEO的七步诊断与战略匹配框架
本文提供GEO(生成式引擎优化)服务模式选择的系统性决策框架,围绕专业能力、预算、目标周期、流程基础、需求性质、能力建设与时间资源七大维度,帮助企业精准匹配咨询或软件方案,避免投资错配,实现从启动校准到规模化落地的可持续竞争优势。
想让大模型更懂你?从原理到实践,详解高效微调的全流程
本文深入解析大模型微调中的核心参数调优与显存优化策略,涵盖学习率、训练轮数、批量大小、截断长度、LoRA秩五大关键参数的原理、调参技巧及显存影响,并结合LLaMA-Factory实战演示高效微调全流程,助你低成本、高质地打造专属AI助手。(239字)
安全对齐不是消灭风险,而是重新分配风险
本文揭示模型对齐的本质是“风险权衡”而非“绝对安全”:每轮对齐压低一类风险(如越界),必抬升另一类(如保守失能)。破除五大错觉——对齐不减风险总量、reward非中立、多轮≠更安全、对齐非纯技术问题、“临上线再对齐”难解根本责任。核心在于清醒选择可接受的代价,让系统真正“敢用”。
重构认知——AI智能体来了从0到1的落地工程全指南
本文系统阐述AI智能体开发方法论:突破“调参”思维,以感知、决策、执行、记忆四大架构为基,提出从场景锁定到评估优化的“五步跃迁法”,助力开发者构建具备行业深度与自主行动力的数字生命。(239字)
智能体对传统行业冲击:中后台,才是产业重塑的第一现场
本文探讨AI从“流程自动化”迈向“认知自主化”后,对传统行业结构性变革的影响:中后台(非一线岗位)正率先被智能体重构——因其任务具数字原生性、决策密度高、协调成本大。供应链、财务、人力三大场景首当其冲。组织正加速演进为“沙漏型”:价值重心转向决策自动化与智能体策略成熟度。(239字)
NumPy技术文档:科学计算的基石
本教程系统讲解NumPy核心知识:从环境搭建与Hello World入门,到ndarray、广播机制、向量化运算三大核心概念;通过销售额分析实战,涵盖统计计算、移动平均、异常检测等典型应用;并总结最佳实践、常见陷阱及进阶方向,助你高效掌握科学计算基石。
1688宝贝详情数据接口实战—B 端视角下的竞品(供应商)数据拆解全指南
本指南面向B端企业,详解如何通过1688宝贝详情API实现竞品与供应商数据化拆解。涵盖API接入、字段商业价值映射(价格梯度、MOQ、SKU库存、资质认证、物流履约、销量反馈等)、实战分析框架及合规要点,助力跨境铺货、批发选品、定价优化与供应链决策,真正将API转化为业务增长引擎。(239字)

从 0 到跑通一次微调:别急着追效果,先让它“真的动起来”
微调最难的不是算法,而是“跑通全流程”。首次微调应聚焦简单目标:让模型回答更规范、语气更一致。避免复杂数据与环境折腾。loss下降不等于成功,关键看输出是否按预期改变。跑通一次,复盘流程,才是真正入门。
智能体来了:AI Agent 职业路线的体系化进阶指南
在AGI浪潮下,阿里云开发者需重塑职业路径:从写代码转向设计AI Agent目标与推理链路。掌握“逻辑蒸馏”、多代理协同与意志对齐,构建可沉淀的数字资产,实现从线性产出到指数级价值跃迁,抢占智能时代新高地。(239字)
用好代理 IP:加密付费拒绝免费陷阱
代理IP兼具隐私保护与安全风险,合规使用可防追踪、保障跨境业务,但非正规服务易致信息泄露、账号风控,甚至被用于违法活动。用户应选择加密付费代理,避开免费陷阱,遵守法规,强化安全防护,让技术真正服务于合法需求。
HTTP与Socks5:功能边界及场景适配
本文深入解析Socks5与HTTP协议的核心差异:HTTP是专用于Web通信的应用层协议,支持丰富的请求交互;Socks5则是通用代理协议,可转发各类网络流量,适用多场景。二者定位不同,一为“专用通信语言”,一为“全能流量中介”。文章从机制、功能与应用场景对比,助你精准选型,提升网络效率与安全。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
