









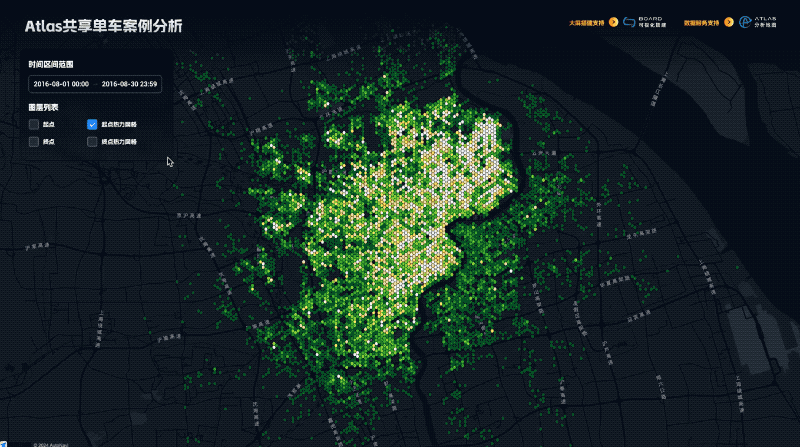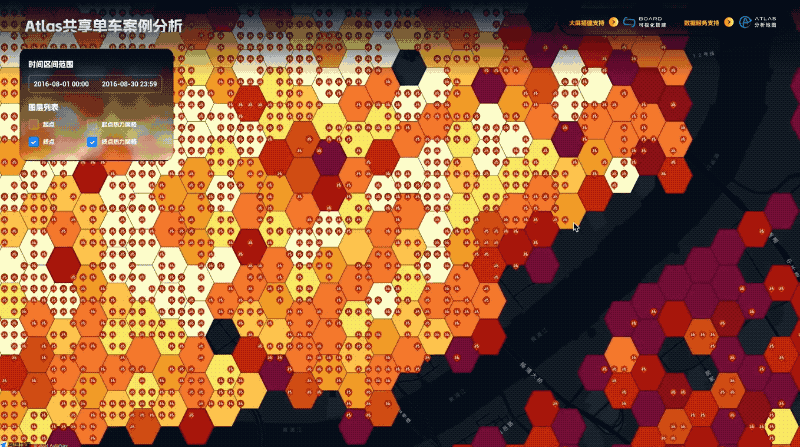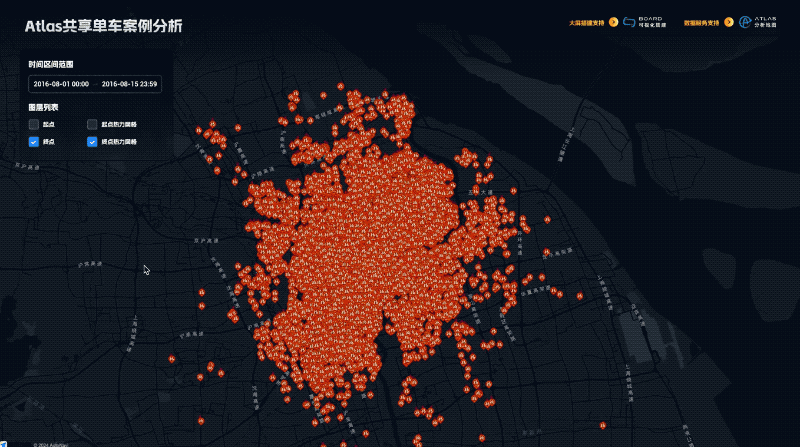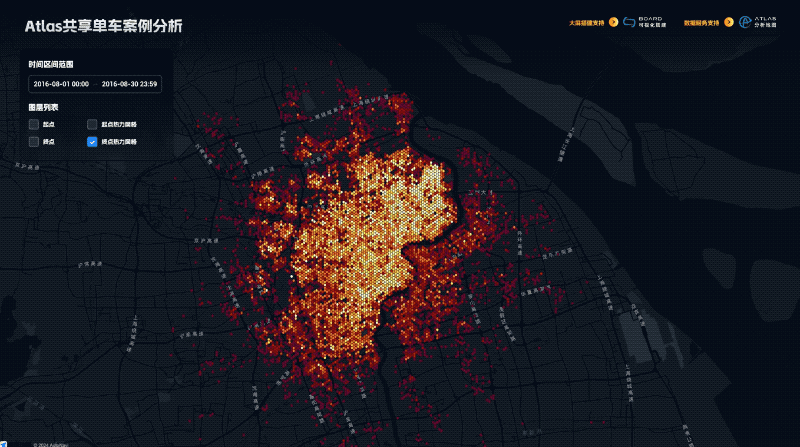
地图不只是导航:DataV Atlas 揭示地理数据的深层价值
随着互联网场景的快速衍生,打车、外卖、智能驾驶等领域的空间数据爆发式增长,海量数据分析成为日常需求。然而,传统地图服务面临性能、安全和成本挑战。为此,我们推出「DataV Atlas 地理数据服务」,提供高效、安全、易用的地理数据解决方案。通过简单的 SQL 查询即可生成专业地理服务,支持多源数据整合、实时更新与分析,确保数据安全,并深度集成 DataV Board 数据看板,实现一键上屏和交互式分析。适用于大屏展示、城市规划等多种场景,助力企业轻松挖掘空间数据价值。
京东商品SKU价格接口(Jd.item_get)丨京东API接口指南
京东商品SKU价格接口(Jd.item_get)是京东开放平台提供的API,用于获取商品详细信息及价格。开发者需先注册账号、申请权限并获取密钥,随后通过HTTP请求调用API,传入商品ID等参数,返回JSON格式的商品信息,包括价格、原价等。接口支持GET/POST方式,适用于Python等语言的开发环境。
nginx安装部署ssl证书,同时支持http与https方式访问
为了使HTTP服务支持HTTPS访问,需生成并安装SSL证书,并确保Nginx支持SSL模块。首先,在`/usr/local/nginx`目录下生成RSA密钥、证书申请文件及自签名证书。接着,确认Nginx已安装SSL模块,若未安装则重新编译Nginx加入该模块。最后,编辑`nginx.conf`配置文件,启用并配置HTTPS服务器部分,指定证书路径和监听端口(如20000),保存后重启Nginx完成部署。

实时计算 Flash – 兼容 Flink 的新一代向量化流计算引擎
本文介绍了阿里云开源大数据团队在实时计算领域的最新成果——向量化流计算引擎Flash。文章主要内容包括:Apache Flink 成为业界流计算标准、Flash 核心技术解读、性能测试数据以及在阿里巴巴集团的落地效果。Flash 是一款完全兼容 Apache Flink 的新一代流计算引擎,通过向量化技术和 C++ 实现,大幅提升了性能和成本效益。
基于阿里云通义千问的AI模型应用开发指南
阿里云通义千问是阿里巴巴集团推出的多模态大语言模型平台,提供了丰富的API和接口,支持多种AI应用场景,如文本生成、图像生成和对话交互等。本文将详细介绍阿里云通义千问的产品功能,并展示如何使用其API来构建一个简单的AI应用,包括程序代码和具体操作流程,以帮助开发者快速上手。

【Prompt Engineering:自我反思(Reflexion)】
自我反思(Reflexion)是一种通过语言反馈强化基于语言的智能体的新范式,无需微调模型即可提升其在决策、推理和编程等任务中的表现。该框架包括参与者(生成动作)、评估者(评分)和自我反思(生成反馈)三个部分,利用大语言模型生成具体反馈,帮助智能体从错误中快速学习,显著提高了多种任务的性能。
ONNX 优化技巧:加速模型推理
【8月更文第27天】ONNX (Open Neural Network Exchange) 是一个开放格式,用于表示机器学习模型,使模型能够在多种框架之间进行转换。ONNX Runtime (ORT) 是一个高效的推理引擎,旨在加速模型的部署。本文将介绍如何使用 ONNX Runtime 和相关工具来优化模型的推理速度和资源消耗。
数据包络分析(Data Envelopment Analysis, DEA)详解与Python代码示例
数据包络分析(Data Envelopment Analysis, DEA)详解与Python代码示例
数仓常用分层与维度建模
本文介绍了数据仓库的分层结构和维度建模。数仓通常分为ODS、DIM、DWD、DWS和ADS五层,各层负责不同的数据处理阶段。维度建模是数据组织方法,包括星型和雪花模型。星型模型简单直观,查询性能高,适合简单查询;雪花模型则通过规范化减少冗余,提高数据一致性和结构复杂性,但可能影响查询效率。选择模型需根据业务需求和数据复杂性来定。
Apple Music中的DRM保护
苹果音乐(Apple Music)是一种流媒体音乐服务,为用户提供了广泛的音乐内容。然而,为了保护音乐版权,Apple Music使用数字版权管理(DRM)技术对其音乐进行保护。DRM保护是一种加密技术,旨在防止用户未经授权地复制、传播或修改受版权保护的音乐。
【经典论文解读】YOLACT 实例分割(YOLOv5、YOLOv8实例分割的基础)
YOLACT是经典的单阶段、实时、实例分割方法,在YOLOv5和YOLOv8中的实例分割,也是基于 YOLACT实现的,有必要理解一下它的模型结构和设计思路。
在 Visual Studio Code 中使用 CodeFuse
Visual Studio Code作为一款广受程序员欢迎的代码编辑器,在前端开发和各类脚本语言开发中占据主流地位,CodeFuse智能研发助手就专门为VS Code研发了插件,只要安装插件就可以使用CodeFuse提供的各种功能,下面我们看看如何在VS Code中使用CodeFuse插件呢?
梯度&散度&旋度&峰度&偏度你分得清楚吗?驻点&鞍点你分得清楚吗?曲率&斜率你分得清楚吗?
本文介绍了四种常见的物理量:加速度,速度,位移和力学功。详细介绍了它们的定义、计算以及在物理学和工程学领域中的应用。此外,本文还介绍了四种与物理量相关的概念:向量、标量、质量和密度。 数学,物理,机器学习领域常见概念区分
阿里封神谈hadoop生态学习之路
在大数据时代,要想个性化实现业务的需求,还是得操纵各类的大数据软件,如:hadoop、hive、spark等。笔者(阿里封神)混迹Hadoop圈子多年,经历了云梯1、ODPS等项目,目前base在E-Mapreduce。在这,笔者尽可能梳理下hadoop的学习之路。
Windows10用户部署OpenClaw的终极指南|路径规范+权限配置+故障排查
专为Windows 10 64位深度优化的OpenClaw(小龙虾)一键部署包:免命令行、免环境配置,解压即装;内置全部依赖与28万Tokens,全程可视化操作;独家解决SmartScreen拦截、权限限制等Win10特有问题,新手也能一次成功“养虾”!
Java获取淘宝商品价格、图片与视频:淘宝开放平台API实战指南
本文详解Java调用淘宝开放平台taobao.item.get接口获取商品详情:涵盖账号注册、权限申请、MD5签名生成、HTTP请求实现及多媒体资源处理,提供完整代码示例与SDK简化方案,助开发者高效集成商品价格、图片、视频等核心数据。(239字)
用 SQL 调大模型?Hologres + 百炼,让数据开发直接“对话”AI
阿里云Hologres深度集成百炼大模型平台,推出AI Function能力——无需Python、GPU或额外服务,用熟悉的SQL即可直接调用大模型,实现PDF解析、多模态理解、向量检索等AI功能,让数据开发者零门槛构建智能应用。
告别“爆显存”:LoRA技术如何用1%的参数,解锁大模型微调自由?
本文深入浅出解析LoRA(低秩自适应)技术:它通过冻结大模型主干、仅训练两个小矩阵(B·A),实现显存节省99%+、性能保留95%+,让RTX 4090等消费卡也能高效微调大模型。含原理、QLoRA量化、六步实操与效果评估,助你零基础打造法律/医疗等垂直领域专属AI。(239字)
1688商品详情API接口使用指南
1688商品详情API(1688.item_get)是阿里1688开放平台核心接口,支持通过商品ID获取50+字段的全量信息,涵盖标题、价格、SKU、库存、图文、批发规则及商家资质等,适用于ERP同步、比价、跨境铺货等B2B场景。需实名认证并创建应用获取app_key与app_secret,接口仅返回JSON格式数据,是对接1688生态的关键技术通道。(239字)
2025数字员工技术选型白皮书:阿里云/亚马逊等5款产品云原生能力实测
本文深度评测阿里云、亚马逊、科大讯飞、玄晶引擎、安恒五款数字员工,围绕架构兼容性、开发友好度、性能稳定性三大维度,结合实测数据与企业案例,为开发者提供选型指南与避坑建议。
小红书笔记评论API:一键获取分层评论与用户互动数据
小红书笔记评论API可获取指定笔记的评论详情,包括内容、点赞数、评论者信息等,支持分页与身份认证,返回JSON格式数据,适用于舆情监控、用户行为分析等场景。
【1分钟解密】如何让 AI 大模型推荐你的品牌
随着AI逐渐取代传统搜索,企业如何让AI“看见”并“信任”你?GEO(生成式引擎优化)应运而生,它不仅是SEO的延伸,更是让AI主动推荐你的关键策略。通过优化内容结构、提升权威性与可读性,GEO助力企业在AI生成的答案中占据一席之地,赢得未来流量入口。
抖音商品详情API秘籍!轻松获取商品详情数据
抖音商品详情API由抖音开放平台提供,支持开发者获取商品基础信息、价格、销量、SKU等关键数据,适用于电商整合、导购平台及直播选品。接口基于HTTP协议,采用GET请求方式,返回JSON格式数据,便于解析处理。附Python请求示例代码,便于快速接入使用。
1688商品列表API全参数指南:从基础搜索到高级筛选
1688商品列表API是阿里巴巴B2B平台的核心接口,支持关键词搜索、高级筛选、排序与分页功能,适用于选品、价格监控等场景。数据规范、稳定高效,日均调用量大。提供Python示例代码,便于快速接入与扩展应用。
2025 年最新 40 个 Java 基础核心知识点全面梳理一文掌握 Java 基础关键概念
本文系统梳理了Java编程的40个核心知识点,涵盖基础语法、面向对象、集合框架、异常处理、多线程、IO流、反射机制等关键领域。重点包括:JVM运行原理、基本数据类型、封装/继承/多态三大特性、集合类对比(ArrayList vs LinkedList、HashMap vs TreeMap)、异常分类及处理方式、线程创建与同步机制、IO流体系结构以及反射的应用场景。这些基础知识是Java开发的根基,掌握后能为后续框架学习和项目开发奠定坚实基础。文中还提供了代码资源获取方式,方便读者进一步实践学习。

http proxy 协议的工作原理与常见用途
在这篇博客文章中,我们将深入探讨HTTP代理协议的工作原理,揭示它如何在客户端和服务器之间传递HTTP请求和响应,并讨论它在各种应用场景中的常见用途。

Apache Paimon统一大数据湖存储底座
Apache Paimon,始于Flink Table Store,发展为独立的Apache顶级项目,专注流式数据湖存储。它提供统一存储底座,支持流、批、OLAP,优化了CDC入湖、流式链路构建和极速OLAP查询。Paimon社区快速增长,集成Flink、Spark等计算引擎,阿里巴巴在内部广泛应用,旨在打造统一湖存储,打通Serverless Flink、MaxCompute等,欢迎大家扫码参与体验阿里云上的 Flink+Paimon 的流批一体服务。
实时计算 Flink版操作报错之遇到错误org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'jdbc',该如何解决
在使用实时计算Flink版过程中,可能会遇到各种错误,了解这些错误的原因及解决方法对于高效排错至关重要。针对具体问题,查看Flink的日志是关键,它们通常会提供更详细的错误信息和堆栈跟踪,有助于定位问题。此外,Flink社区文档和官方论坛也是寻求帮助的好去处。以下是一些常见的操作报错及其可能的原因与解决策略。
ClickHouse(06)ClickHouse建表语句DDL详细解析
ClickHouse创建表有多种语法,包括在当前服务器上创建、复制已有表结构、从表函数创建和从查询创建。表引擎决定表的特性和数据存储方式,如Memory引擎仅存储内存中。分布式DDL可在CLUSTER子句中实现跨节点操作。临时表生命周期与会话绑定,仅支持Memory引擎。分区表用于优化查询性能,MergeTree系列引擎支持分区。默认值表达式(DEFAULT, MATERIALIZED, EPHEMERAL, ALIAS)影响数据插入和查询行为。主键和约束可增强数据完整性,TTL功能用于自动删除过期数据。列压缩和编码能减少存储空间。文章还提供了ClickHouse更多相关系列内容链接。
CVPR 2023 | 主干网络FasterNet 核心解读 代码分析
本文分享来自CVPR 2023的论文,提出了一种快速的主干网络,名为FasterNet。核心算子是PConv,partial convolution,部分卷积,通过减少冗余计算和内存访问来更有效地提取空间特征。

数字孪生核心技术揭秘(六):传统三维gis与数字孪生的区别
当前对“数字孪生城市”没有一个严格界定的标准,本质上“数字孪生城市”是在传统三维GIS应用的基础上演化而来;随着技术创新和行业需求的发展,两者的差异也越来越大;本文梳理了两者的异同,同时比较了两者的适用场景。
天猫图片搜索 API:通过图片地址获取天猫相似商品
本天猫图片搜索API(taobao.item_search_img)支持传入图片URL或Base64,返回同款/相似商品全量结构化数据(标题、价格、SKU、库存等),含标准返回结构、关键字段解析、避坑指南及辅助接口说明,开箱即用。
微信自动化协作 OpenClaw 长连接配置与生产优化方案
OpenClaw是一款轻量开源工具,一键打通微信与本地/云端服务,支持本地调试、Docker容器化及命令行批量部署。无需复杂开发,适配iOS/安卓微信,兼顾安全、稳定与易维护,助力企业高效落地私域自动化运营。(239字)
大模型应用:近似最近邻搜索(ANN)算法驱动向量数据库的高效检索.29
本文深入解析向量检索核心:精确最近邻(Brute-force)与近似最近邻(ANN)算法。详述BF原理、计算方式及性能瓶颈;系统对比KD-Tree、Ball-Tree、LSH、HNSW等ANN算法原理、特性与适用场景,并结合RAG与大模型长上下文应用,揭示其在AI时代的关键支撑作用。
淘宝闪购基于阿里云 EMR Serverless Spark&Paimon的湖仓实践:超大规模下的特征生产&多维分析双提效
本文介绍阿里云 Serverless Spark + Paimon 在淘宝闪购大数据湖仓场景的应用。
【AI大模型面试宝典七】- 训练优化篇
【AI大模型面试宝典】聚焦强化学习核心考点:从SARSA轨迹、在线/离线数据来源,到同策略与异策略差异,深入解析PPO、DPO、GRPO等主流算法原理与优化技巧,助你系统掌握RLHF、奖励模型设计及训练稳定性方案,轻松应对大模型面试高频难题,快速提升实战能力,offer拿到手软!
Vue并发控制核心原理与实践技巧
Vue开发中常见并发问题,如重复请求、竞态冲突等,易导致数据混乱与性能下降。本文详解防抖、节流、AbortController、Promise控制及Pinia状态锁等策略,匹配不同场景,实现请求有序、数据稳定,提升用户体验。
AI 十大论文精讲(五):RAG——让大模型 “告别幻觉、实时更新” 的检索增强生成秘籍
本文解读AI十大核心论文之五——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。该论文提出RAG框架,通过“检索+生成”结合,解决大模型知识更新难、易幻觉、缺溯源等问题,实现小模型高效利用外部知识库,成为当前大模型落地的关键技术。
【跨国数仓迁移最佳实践7】基于 MaxCompute 多租的大数据平台架构
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第七篇,基于MaxCompute 多租的大数据平台架构。 注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
计算机相关的软硬件开发工具分类
本文系统梳理了现代开发工具图谱,涵盖软件、硬件、AI等六大领域。软件开发部分对比了传统工具(如IntelliJ IDEA、SpringBoot)与新兴工具(如AI代码助手Cursor、边缘计算框架Workers),并列出国产替代方案(华为CodeArts、阿里OpenSumi)。硬件开发突出开源EDA工具KiCad和物联网OS Zephyr。AI领域对比了TensorFlow与JAX框架,推荐本地LLM工具Ollama。文章特别设置工具选型指南,针对不同场景推荐方案,如国产化需求建议PaddlePaddle
RouteLLM:高效LLM路由框架,可以动态选择优化成本与响应质量的平衡
新框架提出智能路由选择在强弱语言模型间,利用用户偏好的学习来预测强模型胜率,基于成本阈值做决策。在大规模LLMs部署中,该方法显著降低成本而不牺牲响应质量。研究显示,经过矩阵分解和BERT等技术训练的路由器在多个基准上提升性能,降低强模型调用,提高APGR。通过数据增强,如MMLU和GPT-4评审数据,路由器在GSM8K、MMLU等测试中展现出色的性能提升和成本效率。未来将测试更多模型组合以验证迁移学习能力。该框架为LLMs部署提供了成本-性能优化的解决方案。
手把手教你解决 Hive 的数据倾斜
数据倾斜是 Hive 中影响任务执行效率的现象,表现为某些任务处理的数据量或耗时远超其他任务。根本原因是 Shuffle 后 Key 分布不均,导致部分 Reduce 负载过高。常见场景包括空值聚合、不可拆分大文件、数值膨胀、不同数据类型 Join、Count(distinct) 计算以及表 Join 操作。解决方法包括过滤空值、转换数据类型、调整聚合策略、使用 MapJoin 等。通过合理优化,如设置 `hive.groupby.skewindata` 和 `hive.map.aggr` 参数,可以有效缓解数据倾斜问题。

ClickHouse(01)什么是ClickHouse,ClickHouse适用于什么场景
ClickHouse是一款高性能的列式存储OLAP数据库,由俄罗斯的Yandex公司开发,用于在线分析处理(OLAP)。它提供秒级大数据查询,适用于商业智能、广告流量等领域。ClickHouse速度快的原因包括列式存储、数据压缩、向量化执行和多线程分布式处理。然而,它不支持事务,不适合OLTP操作。相比Hadoop生态中的查询引擎,ClickHouse在大量数据查询上表现出色。一系列的文章详细介绍了ClickHouse的各个方面,包括安装、表引擎和使用场景。


【最佳实践】esrally:Elasticsearch 官方压测工具及运用详解
由于 Elasticsearch(后文简称 es) 的简单易用及其在大数据处理方面的良好性能,越来越多的公司选用 es 作为自己的业务解决方案。然而在引入新的解决方案前,不免要做一番调研和测试,本文便是介绍官方的一个 es 压测工具 esrally,希望能为大家带来帮助。
Flink SQL 功能解密系列 —— 流式 TopN 挑战与实现
TopN 是统计报表和大屏非常常见的功能,主要用来实时计算排行榜。流式的 TopN 不同于批处理的 TopN,它的特点是持续的在内存中按照某个统计指标(如出现次数)计算 TopN 排行榜,然后当排行榜发生变化时,发出更新后的排行榜。
OpenClaw爆火背后,企业级智能体为何更需要“私有化部署替代方案”?
OpenClaw(“小龙虾”)引爆AI智能体热潮,但企业落地面临安全、规模化与成本三大困局。OpenOcta应运而生——专为企业打造的私有化智能体平台,具备默认安全、集中管控、成本可控及深度集成能力,已覆盖金融、政务、制造等十余行业,助力企业安全高效迈入智能体时代。(239字)

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
