









网页模板源码-网站源码建设方式
本文聚焦免费开源企业网站源码模板,解析其低成本、高灵活等优势,推荐 PageAdmin CMS、Joomla、帝国 CMS 等主流模板并说明适配场景,阐述选择方法与二次开发优化要点,为企业低成本高效搭建网站提供实用指引。
1688商品详情API指南
1688商品详情API提供商品基础信息、规格参数及价格库存等核心数据,支持多语言、多维度SKU与实时价格查询,采用OAuth 2.0认证,返回标准JSON格式,助力B2B电商高效集成与应用。
当销售额下降时,ChatBI 如何实现多维下钻、归因分析?
ChatBI 的归因分析能力,能够通过自动化拆解指标、关联业务维度、量化因子贡献度,将“数据表象”转化为“可解释的决策依据”。
拼多多商品列表API使用指南
拼多多商品列表API是拼多多开放平台的核心接口,支持关键词搜索、类目筛选、价格与销量排序,并提供分页查询功能,便于高效获取海量商品基本信息,适用于电商数据分析与商品聚合等场景。
实验报告:让AI自动生成采集代码,会踩哪些坑?
本文复盘AI自动生成采集代码的实战效果,梳理出“模拟行为”与“接口调用”两大技术路线。AI在浏览器自动化中表现良好,适合简单场景;但面对加密接口与强反爬时仍需人工介入。最终结论:AI是高效助手,但核心难题仍需工程师掌控。
1688商品列表API完整指南
1688商品列表API是阿里巴巴B2B平台核心接口,支持通过关键词、分类、价格等多条件筛选,分页批量获取商品信息、价格、供应商及库存数据,采用JSON格式与AppKey签名认证,助力企业高效实现商品搜索、数据采集与供应链自动化管理。
U盘如何防泄密?这几个技术手段迎刃而解
安得卫士提供U盘防泄密四大核心措施:准入控制、操作管控、行为审计与离线防护。通过注册授权、权限细分、敏感数据拦截、全流程操作审计及加密外发控制,实现U盘数据全周期安全防护,有效防范数据泄露风险。
Python | 贝叶斯搜索参数优化的XGBoost+SHAP可解释性分析回归预测及可视化算法
本教程将推出Python实现的XGBoost贝叶斯调参+SHAP可解释性分析与可视化,涵盖数据应用、算法原理及SHAP理论,助力SCI论文提升模型可解释性,附完整代码与环境配置指南。
隔壁火锅店天天排队,老板悄悄做了这件事?
成都火锅店两周营业额提升38%?秘诀是GEO优化!AI搜索时代,让店铺被推荐成“附近首选”。从信息标记到场景内容布局,三步打造AI推荐门店。别再等顾客找你,让AI把客流送到门口。
ODPS 十五周年实录 | Data + AI,MaxCompute 下一个15年的新增长引擎
本文根据 ODPS 十五周年·年度升级发布实录整理而成,演讲信息如下: 于得水(得水):阿里云智能集团计算平台事业部资深技术专家 活动:【数据进化·AI 启航】ODPS 年度升级发布
【跨国数仓迁移最佳实践6】MaxCompute SQL语法及函数功能增强,10万条SQL转写顺利迁移
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第六篇,MaxCompute SQL语法及函数功能增强。 注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
AI 驱动数据分析民主化,企业如何构建可信智能 Data Agent?
企业构建可信智能的 Data Agent 需以强大的数据底座为支撑,统一指标语义层和 NoETL 数据工程成为关键。
阿里云 Elasticsearch 的 AI 革新:高性能、低成本、智能化的搜索新纪元
本文介绍了数智化浪潮下, 阿里云 Elasticsearch 打通了 云原生内核优化、RAG 闭环方案、云原生推理平台 三大能力模块,实现了从底层到应用的全链路升级,助力企业构建面向未来的智能搜索中枢。
EMR AI助手开启公测:用AI重塑大数据运维,更简单、更智能
EMR AI 助手开启公测,通过合理利用 EMR AI 助手的各项功能,可以快速查询资源信息、唤起相关操作、诊断组件异常、获取技术支持等,能帮您提升运维效率和操作体验。
新材料企业CRM软件怎么选?2025年新版选型指南来了!
新材料行业销售周期长、客户多元、数据复杂,亟需高效CRM系统支撑。理想CRM应具备强数据整合、灵活定制、多系统协同及高安全性,助力企业提升销售效率与客户忠诚度,推动数字化转型与可持续发展。
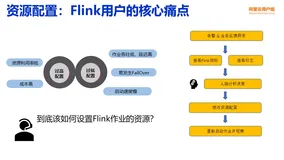
Flink 智能调优:从人工运维到自动化的实践之路
本文由阿里云Flink产品专家黄睿撰写,基于平台实践经验,深入解析流计算作业资源调优难题。针对人工调优效率低、业务波动影响大等挑战,介绍Flink自动调优架构设计,涵盖监控、定时、智能三种模式,并融合混合计费实现成本优化。展望未来AI化方向,推动运维智能化升级。

阿里云、Ververica、Confluent 与 LinkedIn 携手推进流式创新,共筑基于 Apache Flink Agents 的智能体 AI 未来
Apache Flink Agents 是由阿里云、Ververica、Confluent 与 LinkedIn 联合推出的开源子项目,旨在基于 Flink 构建可扩展、事件驱动的生产级 AI 智能体框架,实现数据与智能的实时融合。
mmBERT:307M参数覆盖1800+语言,3万亿tokens训练
mmBERT是基于ModernBERT架构的多语言编码器,在1800多种语言、3万亿token上预训练,创新性地采用逆掩码调度与级联退火语言学习(ALL),动态引入低资源语言并优化采样策略。使用Gemma 2 tokenizer,支持最长8192上下文,结合Flash Attention 2实现高效推理。在GLUE、XTREME、MTEB等基准上超越XLM-R、mGTE等模型,尤其在低资源语言和代码检索任务中表现突出,兼具高性能与高效率。

从DQN到Double DQN:分离动作选择与价值评估,解决强化学习中的Q值过估计问题
2015年DQN在Atari游戏中突破,但Q值过估计问题浮现。因max操作放大噪声,智能体盲目自信“黄金动作”。根源在于动作选择与价值评估由同一网络完成,导致最大化偏差。

PINN训练新思路:把初始条件和边界约束嵌入网络架构,解决多目标优化难题
PINNs训练难因多目标优化易失衡。通过设计硬约束网络架构,将初始与边界条件内嵌于模型输出,可自动满足约束,仅需优化方程残差,简化训练过程,提升稳定性与精度,适用于气候、生物医学等高要求仿真场景。

Python离群值检测实战:使用distfit库实现基于分布拟合的异常检测
本文解析异常(anomaly)与新颖性(novelty)检测的本质差异,结合distfit库演示基于概率密度拟合的单变量无监督异常检测方法,涵盖全局、上下文与集体离群值识别,助力构建高可解释性模型。
四、Sqoop 导入表数据子集
在实际数据导入场景中,我们经常只需要数据库中的一部分数据,比如按条件筛选的行、特定的几列。这篇文章详细讲解了如何使用 Sqoop 的 --where、--columns、--query 等方式灵活实现子集导入,配有完整示例和注意事项,助你更精准地控制数据流向 HDFS 或 Hive。
三、Sqoop 全量导入核心命令
在大数据处理过程中,数据库表怎么高效导入到 Hadoop?这一篇我带大家实战讲解 Sqoop 全量导入 的用法,从基础命令到常用参数配置,再到导入到 HDFS、Hive 的各种格式案例,配合实操示例,帮你一步步掌握全量导入技巧。最后还有练习题,供大家动手巩固一下。
Java基础语法与面向对象
重载(Overload)指同一类中方法名相同、参数列表不同,与返回值无关;重写(Override)指子类重新实现父类方法,方法名和参数列表必须相同,返回类型兼容。重载发生在同类,重写发生在继承关系中。
基于springboot的电影购票管理系统
本系统基于Spring Boot框架,结合Vue、Java与MySQL技术,实现电影信息管理、在线选座、购票支付等核心功能,提升观众购票体验与影院管理效率,推动电影产业数字化发展。
从另一个视角看Transformer:注意力机制就是可微分的k-NN算法
注意力机制可理解为一种“软k-NN”:查询向量通过缩放点积计算与各键的相似度,softmax归一化为权重,对值向量加权平均。1/√d缩放防止高维饱和,掩码控制信息流动(如因果、填充)。不同相似度函数(点积、余弦、RBF)对应不同归纳偏置,多头则在多个子空间并行该过程。
基于springboot的家政服务预约系统
随着社会节奏加快与老龄化加剧,家政服务需求激增,但传统模式存在信息不对称、服务不规范等问题。基于Spring Boot、Vue、MySQL等技术构建的家政预约系统,实现服务线上化、标准化与智能化,提升用户体验与行业效率,推动家政服务向信息化、规范化发展。

MIT新论文:数据即上限,扩散模型的关键能力来自图像统计规律,而非复杂架构
MIT与丰田研究院研究发现,扩散模型的“局部性”并非源于网络架构的精巧设计,而是自然图像统计规律的产物。通过线性模型仅学习像素相关性,即可复现U-Net般的局部敏感模式,揭示数据本身蕴含生成“魔法”。
【1分钟解密】如何让 AI 大模型推荐你的品牌
随着AI逐渐取代传统搜索,企业如何让AI“看见”并“信任”你?GEO(生成式引擎优化)应运而生,它不仅是SEO的延伸,更是让AI主动推荐你的关键策略。通过优化内容结构、提升权威性与可读性,GEO助力企业在AI生成的答案中占据一席之地,赢得未来流量入口。
量子机器学习入门:三种数据编码方法对比与应用
在量子机器学习中,数据编码方式决定了量子模型如何理解和处理信息。本文详解角度编码、振幅编码与基础编码三种方法,分析其原理、实现及适用场景,帮助读者选择最适合的编码策略,提升量子模型性能。
深度解析京东图片搜索API:从图像识别到商品匹配的算法实践
京东图片搜索API基于图像识别技术,支持通过上传图片或图片URL搜索相似商品,提供智能匹配、结果筛选、分页查询等功能。适用于比价、竞品分析、推荐系统等场景。支持Python等开发语言,提供详细请求示例与文档。

ODPS十五周年实录|构建 AI 时代的大数据基础设施
本文根据 ODPS 十五周年·年度升级发布实录整理而成,演讲信息如下: 张治国:阿里云智能集团技术研究员、阿里云智能计算平台事业部 ODPS-MaxCompute 负责人 活动:【数据进化·AI 启航】ODPS 年度升级发布

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
