









如何在实际项目中运用面向对象的多态
多态通过“基于抽象编程,适配不同实现”,实现代码解耦与扩展。在支付、数据导出、购物车结算等场景中,借助接口或抽象类统一行为,子类差异化实现,提升灵活性与可维护性,符合开闭原则。
隔壁火锅店天天排队,老板悄悄做了这件事?
成都火锅店两周营业额提升38%?秘诀是GEO优化!AI搜索时代,让店铺被推荐成“附近首选”。从信息标记到场景内容布局,三步打造AI推荐门店。别再等顾客找你,让AI把客流送到门口。
企业网站模板 网站源码下载 网站源码建站
在数字化时代,企业需专业网站拓展市场,网站源码建站因高性价比、强灵活性成中小企业首选,比定制开发成本低、比模板建站自由。选源码要明确需求、看质量售后与 SEO 扩展性,下载用官方渠道,经准备服务器域名、安装设置可上线,助企业低成本建高自由度安全网站。
把品牌塞进AI的“嘴”里——数聚酷亲测有效的3个小动作
数聚酷亲测3招:改官网为Q&A、拆白皮书碎片、蹭热点评论,让AI主动引用品牌。短内容+数据背书+高权重平台互动,轻松把品牌“喂”进AI答案。
【跨国数仓迁移最佳实践8】MaxCompute Streaming Insert:大数据数据流写业务迁移的实践与突破
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第八篇,MaxCompute Streaming Insert:大数据数据流写业务迁移的实践与突破。 注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
Elasticsearch 8.17 智能检索升级全攻略
Elasticsearch 作为一款强大的搜索与分析引擎,支持传统检索、AI 搜索(如语义检索、RAG、多模态检索)及智能运维场景,结合阿里云AI搜索开放平台提供一站式解决方案。 本文介绍了最新发布的 Elasticsearch 8.17 检索增强型应用在性能和功能上的特性。同时本文介绍了利用容量规划工具优化资源分配,特别适合 AI 应用和高弹性场景,为用户提供高性能、低成本、易扩展的搜索服务。
速卖通商品详情API文档
速卖通商品详情API通过标准化接口实时获取商品标题、价格、SKU、库存等信息,支持多语言返回,适用于比价、选品分析等场景。采用AppKey+Token认证与MD5签名保障安全。
阿里云 Elasticsearch 的 AI 革新:高性能、低成本、智能化的搜索新纪元
本文介绍了数智化浪潮下, 阿里云 Elasticsearch 打通了 云原生内核优化、RAG 闭环方案、云原生推理平台 三大能力模块,实现了从底层到应用的全链路升级,助力企业构建面向未来的智能搜索中枢。
微软代码签名证书申请
软件供应链成网络攻击重灾区,代码签名是保障安全的关键。通过数字签名验证软件来源与完整性,可有效防范恶意篡改。申请需选择OV或EV类型,单位用户可通过Gworg实名认证获取证书,EV版享更高信任。个人仅可申请OV,证书签发后邮寄硬件密钥,确保完全所有权与安全性。
NTP电子时钟系统:安徽京准提升医院高效率运转
NTP电子时钟系统由安徽京准提供,通过GPS/北斗授时,实现医院全院时间精准同步。系统支持手术计时、温湿度监测、HIS系统联动,保障医疗安全与管理效率,助力智慧医院高效运行。(238字)
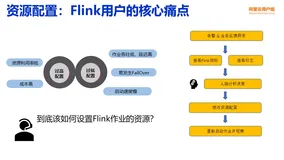
Flink 智能调优:从人工运维到自动化的实践之路
本文由阿里云Flink产品专家黄睿撰写,基于平台实践经验,深入解析流计算作业资源调优难题。针对人工调优效率低、业务波动影响大等挑战,介绍Flink自动调优架构设计,涵盖监控、定时、智能三种模式,并融合混合计费实现成本优化。展望未来AI化方向,推动运维智能化升级。
基于python大数据的台风灾害分析及预测系统
针对台风灾害预警滞后、精度不足等问题,本研究基于Python与大数据技术,构建多源数据融合的台风预测系统。利用机器学习提升路径与强度预测准确率,结合Django框架实现动态可视化与实时预警,为防灾决策提供科学支持,显著提高应急响应效率,具有重要社会经济价值。
微店API使用指南:高效获取商品列表数据
本文介绍如何使用Python爬虫调用微店item_search接口,根据关键词搜索商品并获取商品列表数据,涵盖请求方式、JSON数据解析、分页参数设置及筛选排序功能,适用于电商数据分析与竞品研究。
java调用服务报错415 Content type ‘application/octet-stream‘ not supported
java调用服务报错415 Content type ‘application/octet-stream‘ not supported

从DQN到Double DQN:分离动作选择与价值评估,解决强化学习中的Q值过估计问题
2015年DQN在Atari游戏中突破,但Q值过估计问题浮现。因max操作放大噪声,智能体盲目自信“黄金动作”。根源在于动作选择与价值评估由同一网络完成,导致最大化偏差。

PINN训练新思路:把初始条件和边界约束嵌入网络架构,解决多目标优化难题
PINNs训练难因多目标优化易失衡。通过设计硬约束网络架构,将初始与边界条件内嵌于模型输出,可自动满足约束,仅需优化方程残差,简化训练过程,提升稳定性与精度,适用于气候、生物医学等高要求仿真场景。

Python离群值检测实战:使用distfit库实现基于分布拟合的异常检测
本文解析异常(anomaly)与新颖性(novelty)检测的本质差异,结合distfit库演示基于概率密度拟合的单变量无监督异常检测方法,涵盖全局、上下文与集体离群值识别,助力构建高可解释性模型。
从另一个视角看Transformer:注意力机制就是可微分的k-NN算法
注意力机制可理解为一种“软k-NN”:查询向量通过缩放点积计算与各键的相似度,softmax归一化为权重,对值向量加权平均。1/√d缩放防止高维饱和,掩码控制信息流动(如因果、填充)。不同相似度函数(点积、余弦、RBF)对应不同归纳偏置,多头则在多个子空间并行该过程。
别人还在摸索,你用这篇Hoobuy淘宝代购集运系统搭建攻略开拓欧美反向海淘市场!
淘宝代购集运系统为海外用户提供一站式中国电商购物解决方案,集成商品抓取、多语言展示、本地支付、国际物流与订单追踪功能,支持多平台数据同步与合规运营,通过技术整合破解语言、支付、物流难题,助力逆向海淘高效便捷。
基于springboot的健康饮食营养管理系统
本系统基于Spring Boot、Vue与MySQL技术,融合大数据与AI算法,构建个性化健康饮食管理平台。结合用户身体状况、目标需求,智能推荐营养方案,助力科学饮食与健康管理。
PSQLException: ERROR: column “xxxxx“ does not exist
PSQLException: ERROR: column “xxxxx“ does not exist
基于springboot的游乐园管理系统
本系统基于SpringBoot与Vue技术,构建高效、智能的游乐园管理系统,实现票务电子化、设备监控智能化、员工管理自动化,提升运营效率与游客体验,推动游乐园数字化转型与智慧升级。
基于python大数据的天气可视化分析预测系统
本研究探讨基于Python的天气预报数据可视化系统,旨在提升天气数据获取、分析与展示的效率与准确性。通过网络爬虫技术快速抓取实时天气数据,并运用数据可视化技术直观呈现天气变化趋势,为公众出行、农业生产及灾害预警提供科学支持,具有重要的现实意义与应用价值。
构建可观测、可治理的企业智能体:平台核心能力解析
在人工智能快速发展的背景下,企业智能体已成为推动数字化转型的重要力量。然而,其复杂性和不可预测性也带来了可靠性、透明性和可控性等挑战。构建具备全景可观测性、多层治理框架、智能体协同与知识管理、人类监督机制的智能体体系,成为企业实现安全、合规、高效运营的关键。通过系统化实施路径,企业可全面提升智能体的透明度与治理能力,把握智能时代发展机遇。

超越传统XPath:用LLM理解复杂网页信息
本文深入探讨网页信息抽取技术的演进,从传统 XPath/CSS 结构匹配,到结合 LLM(大语言模型)的语义理解方法。分析了旧技术在动态渲染、结构变化和语义识别方面的局限,并通过架构图、实验数据和示例代码展示 LLM 在新闻、电商、社交等复杂场景中的高效应用。同时强调爬虫代理等基础设施的重要性,为信息抓取提供稳定网络环境。
基于python大数据的北京旅游可视化及分析系统
本文深入探讨智慧旅游系统的背景、意义及研究现状,分析其在旅游业中的作用与发展潜力,介绍平台架构、技术创新、数据挖掘与服务优化等核心内容,并展示系统实现界面。
基于python大数据的nba球员可视化分析系统
本课题围绕NBA球员数据分析与可视化展开,探讨如何利用大数据与可视化技术提升篮球运动的表现评估与决策支持能力。研究涵盖数据采集、处理与可视化呈现,结合SQLite、Flask、Echarts等技术构建分析系统,助力球队训练、战术制定及球迷观赛体验提升。

面向教育平台的分层内容采集思路
随着在线教育平台快速发展,其内容采集需应对层级化、动态更新及访问限制等挑战。本文提出分层采集方案,结合代理服务与异步爬虫技术,实现高效稳定的数据抓取,适用于教育平台及其他内容型平台的数据采集需求。

从信息捕获到多维研判的链路解析
本案例构建了一套基于爬虫与数据分析的热点监测系统,通过代理IP与Python工具实现新闻内容抓取,结合时间、来源与关键词分析,打造“信息雷达”,助力舆情研判与趋势预测。

「48小时极速反馈」阿里云实时计算Flink广招天下英雄
阿里云实时计算Flink团队,全球领先的流计算引擎缔造者,支撑双11万亿级数据处理,推动Apache Flink技术发展。现招募Flink执行引擎、存储引擎、数据通道、平台管控及产品经理人才,地点覆盖北京、杭州、上海。技术深度参与开源核心,打造企业级实时计算解决方案,助力全球企业实现毫秒洞察。
1688工厂档案信息API详解
1688工厂档案信息API是阿里巴巴开放平台的核心接口,用于实时获取供应商工厂的基础信息、生产能力、资质认证及合作案例等详细档案。适用于供应链管理与供应商评估,支持企业认证用户获取更完整数据。接口调用需提供app_key、时间戳、签名及工厂ID,支持字段筛选,示例代码展示Python请求实现,包含签名机制与错误处理。
1688图片搜索API秘籍!轻松获取相似商品数据
1688图片搜索API基于图像识别技术,支持通过上传商品图片搜索同款或相似商品,适用于电商选品、供应链管理等场景。提供多种搜索模式与结果过滤条件,支持Python等开发语言,提升采购效率。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
