
从上一篇中我们知道,PXC集群中任何一个节点都是可以读写的,但是,一旦PXC集群上线后,我们不能把所有的数据库请求全部发送给一个数据库节点,而是这个PXC集群中的数据库节点都应该参与到请求的处理。那么负载均衡的工作,就是让每个请求均匀的发送给每个数据库节点。
负载均衡的必要性
- 虽然搭建了集群,但是不使用数据库负载均衡,单节点处理所有请求,会造成负载高、性能差等问题。如图:

- 使用Haproxy做负载均衡,请求被均匀分发给每个节点,单节点负载低,性能好。如下图:
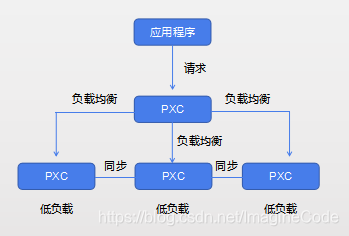
你可能会问:为什么不用Nginx作负载均衡?
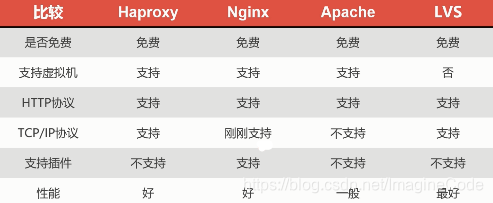
原因:每个中间件的选择都是需要进行考量的,如下图所示,Nginx对TCP/IP协议的支持的比较晚,而Haproxy是一个老牌的中间件产品,虽然不支持插件,但其成熟性使得它很可靠。
下面,我们列出负载均衡中间件的对比图:
安装Haproxy镜像
到Docker仓库下载即可:docker pull haproxy
haproxy是这个镜像的缩写。
现在,我们下载好了haproxy镜像,但是别急,我们先把Haproxy的配置文件(haproxy.cfg)创建好,再去创建容器:
创建Haproxy配置文件
touch /home/soft/haproxy.cfg
首先现在宿主机上通过touch指令创建一个配置文件haproxy.cfg,然后通过 目录映射技术把soft目录映射到haproxy容器里面。这样,资Haproxy容器就可以找到这个配置文件,然后启动Haproxy的服务,自然而然就会有配置文件。
关于详细的配置文件编写,请参考:https://zhangge.net/5125.html
我们重点来看下数据库负载均衡这块:
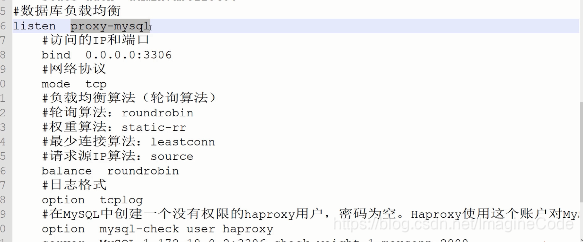
解释:
listen proxy-mysql:定义一个配置,名称叫proxy-mysqlbing 0.0.0.0:3306开放的端口为3306,0.0.0.0表示任何IP地址都能访问3306端口mode tcp表示3306支持的协议是tcp,例如有应用程序向3306端口发起数据库请求,它就会把请求转发给具体的PXC数据库实例。
同时,Haproxy自带了转发算法:
因为PXC容器里跑的数据库硬件配置都是相同的,所以不需要使用权重算法,只有当主机的硬件配置不同时,才需要采用权重算法。如,主机硬件配置高的,可以把它的权重设置的高些,这样它可以处理更多的数据库请求;硬件配置低的数据库节点,就分配低一些的权重。
balance roundrobin 这里采用的是轮询算法
- 心跳检测:

option mysql-check user haproxy//给数据库创建一个叫haproxy的账户,密码为空,不分配任何权限。Haproxy通过这个账户登录到Mysql上,发送心跳检测。这样它就知道Mysql是在运行,还是宕机。
连接到数据库上 要发送心跳检测,那么要提供一个Haproxy能登录的账号user,后面跟的haproxy是你在PXC数据库上创建的用户,用户名可以随意取,如你叫abc,那么就是 user abc。
再往下,配置要进行负载均衡的数据库节点:
server MySQL_1(自定义名字) 172.18.0.2:3306(数据库节点的地址,容器的端口是3306)check(发送心跳检测,可以具体设置每隔几毫秒检测一次,具体设置可以在百度上搜下) weight 1(权重。如果采用的是轮询算法,即使写上权重,也不会生效)maxconn 2000 (最大连接数,这里为2000)
接下来,如果你已经配置好了Haproxy配置文件,我们就可以创建Haproxy容器:
这里给出一份参考的配置文件:
# 启动容器时使用目录映射技术使容器读取该配置文件 # $ touch /home/haproxy/haproxy.cfg # haproxy.cfg global #工作目录 chroot /usr/local/etc/haproxy #日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info log 127.0.0.1 local5 info #守护进程运行 daemon defaults log global mode http #日志格式 option httplog #日志中不记录负载均衡的心跳检测记录 option dontlognull #连接超时(毫秒) timeout connect 5000 #客户端超时(毫秒) timeout client 50000 #服务器超时(毫秒) timeout server 50000 #监控界面 listen admin_stats #监控界面的访问的IP和端口 bind 0.0.0.0:8888 #访问协议 mode http #URI相对地址 stats uri /dbs #统计报告格式 stats realm Global\ statistics #登陆帐户信息 stats auth admin:abc123456 #数据库负载均衡 listen proxy-mysql #访问的IP和端口 bind 0.0.0.0:3306 #网络协议 mode tcp #负载均衡算法(轮询算法) #轮询算法:roundrobin #权重算法:static-rr #最少连接算法:leastconn #请求源IP算法:source balance roundrobin #日志格式 option tcplog #在MySQL中创建一个没有权限的haproxy用户,密码为空。Haproxy使用这个账户对MySQL数据库心跳检测 option mysql-check user haproxy server MySQL_1 172.18.0.2:3306 check weight 1 maxconn 2000 server MySQL_2 172.18.0.3:3306 check weight 1 maxconn 2000 server MySQL_3 172.18.0.4:3306 check weight 1 maxconn 2000 server MySQL_4 172.18.0.5:3306 check weight 1 maxconn 2000 server MySQL_5 172.18.0.6:3306 check weight 1 maxconn 2000 #使用keepalive检测死链 option tcpka
创建Haproxy容器
docker run -it -d -p 4001:888 -p 4002:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy --name haproxy --privileged --net=net1 haproxy haproxy -f /usr/local/etc/haproxy/haproxy.cfg
解释:
- Haproxy提供了一个后台监控的画面(能查看数据库负载均衡的状况),这个画面在配置文件里定义的就是
8888端口(可以在Haproxy的配置文件中查看) -v /home/soft/happroxy:/usr/local/etc/haproxy目录映射,把宿主机的haproxy映射到容器的/usr/local/etc/haproxy目录上。--name h1 --privileged --net=net1给容器起一个名字h1,权限,net1网段(跟数据库实例在同一个网段上)- 启动haproxy:
haproxy -f /usr/local/etc/haproxy/haproxy.cfg
实际操作:
- 首先,在服务器上新建一个soft/haproxy文件夹,并把haproxy.cfg配置文件放到haproxy文件夹下:


- 然后使用xshell 进入到/home/soft/haproxy文件夹下:

- 然后,创建Haproxy容器,使用指令:
docker run -it -d -p 4001:8888 -p 4002:3306 -v /home/soft/haproxy:/usr/local/etc/haproxy --name h1 --privileged --net=net1 --ip 172.18.0.2(注:选择一个适合的子网地址) haproxy
我是根据我这边的网段进行设置的,如图: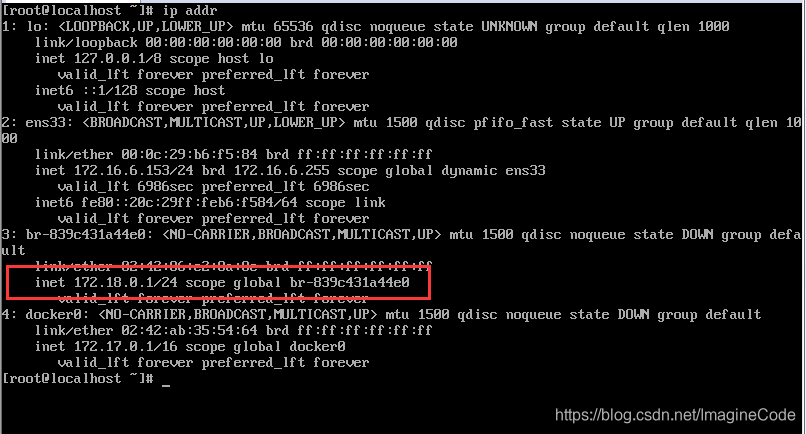
执行指令,运行后:

- 由于创建的容器在后台运行,我必须要进入到后台的容器,执行指令:
docker exec -it (注:有交互界面) h1(注:容器名字) bash(注:交互指令类型)
此时,我们就进入到刚才启动的Haproxy容器里面。 - 执行启动Haproxy的指令:
haproxy -f(表示加载配置文件) /usr/local/etc/haproxy/haproxy.cfg(配置文件的路径)

这样,我们就启动了haproxy。一会我们切换到浏览器上查看监控画面,我们就会知道数据库的负载均衡是否已经运行起来了。
现在我们需要在Mysql数据库上创建一个名叫 haproxy的账号,因为Haproxy中间件要用这个账号登录数据库,然后发送心跳检测。
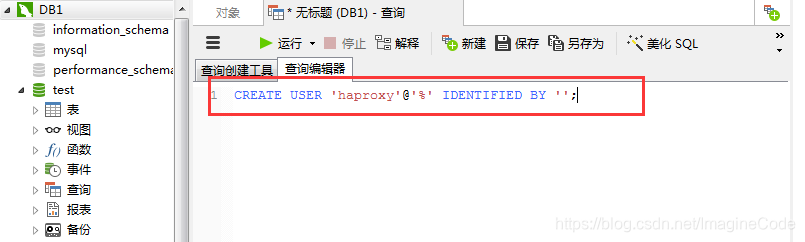
- 在浏览器中输入:
宿主机地址:监控端口/dbs,然后回车,如下图我的宿主机IP是这样的:(你要输入你自己宿主机的地址)
注:这些可以在haproxy.cfg配置文件中定义:
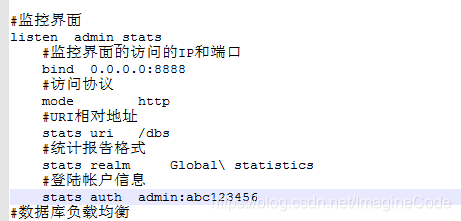
- 输入用户名和密码后,我们就可以进入到监控画面:
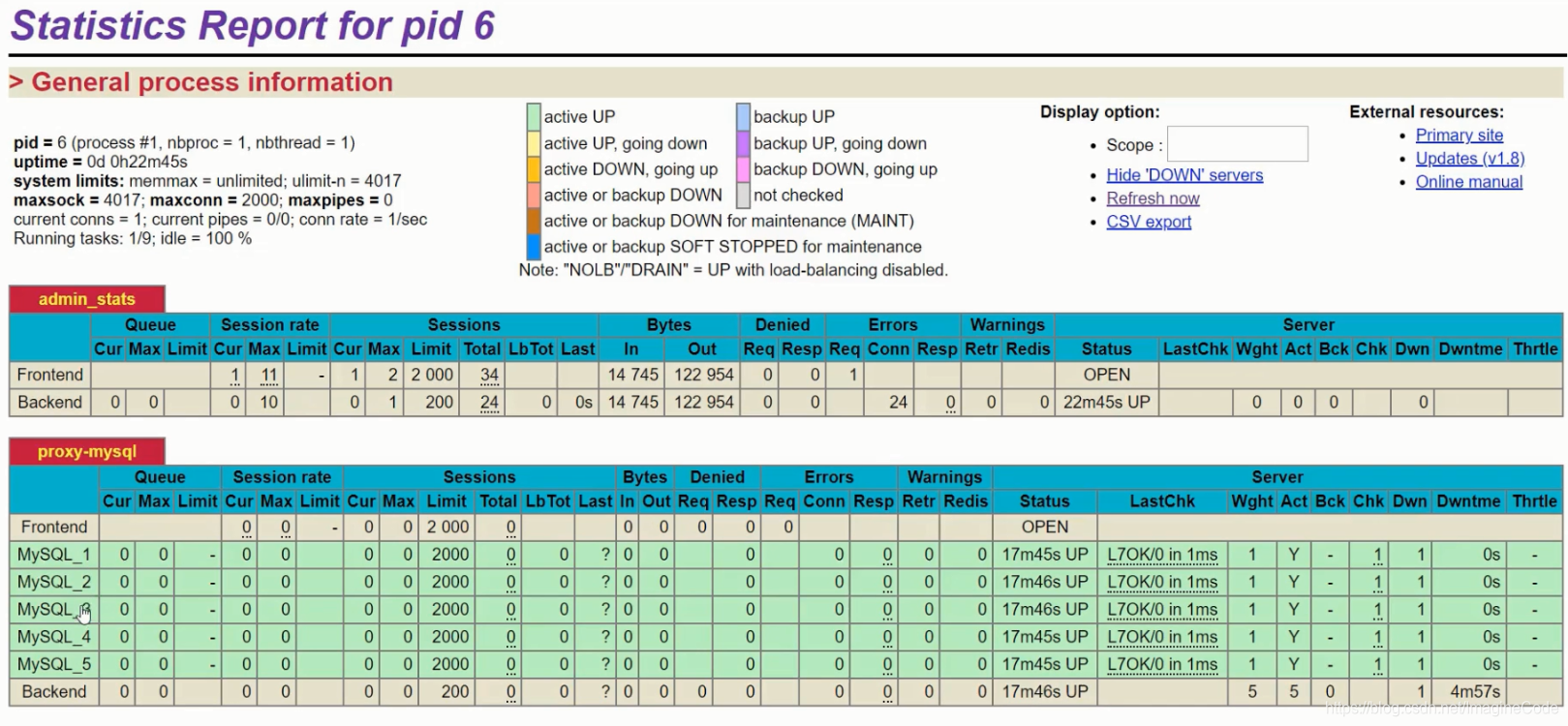
- 从上图监控画面中我们可以看到,里面有5个数据库节点。我们把node1 关掉,再看看:
docker stop node1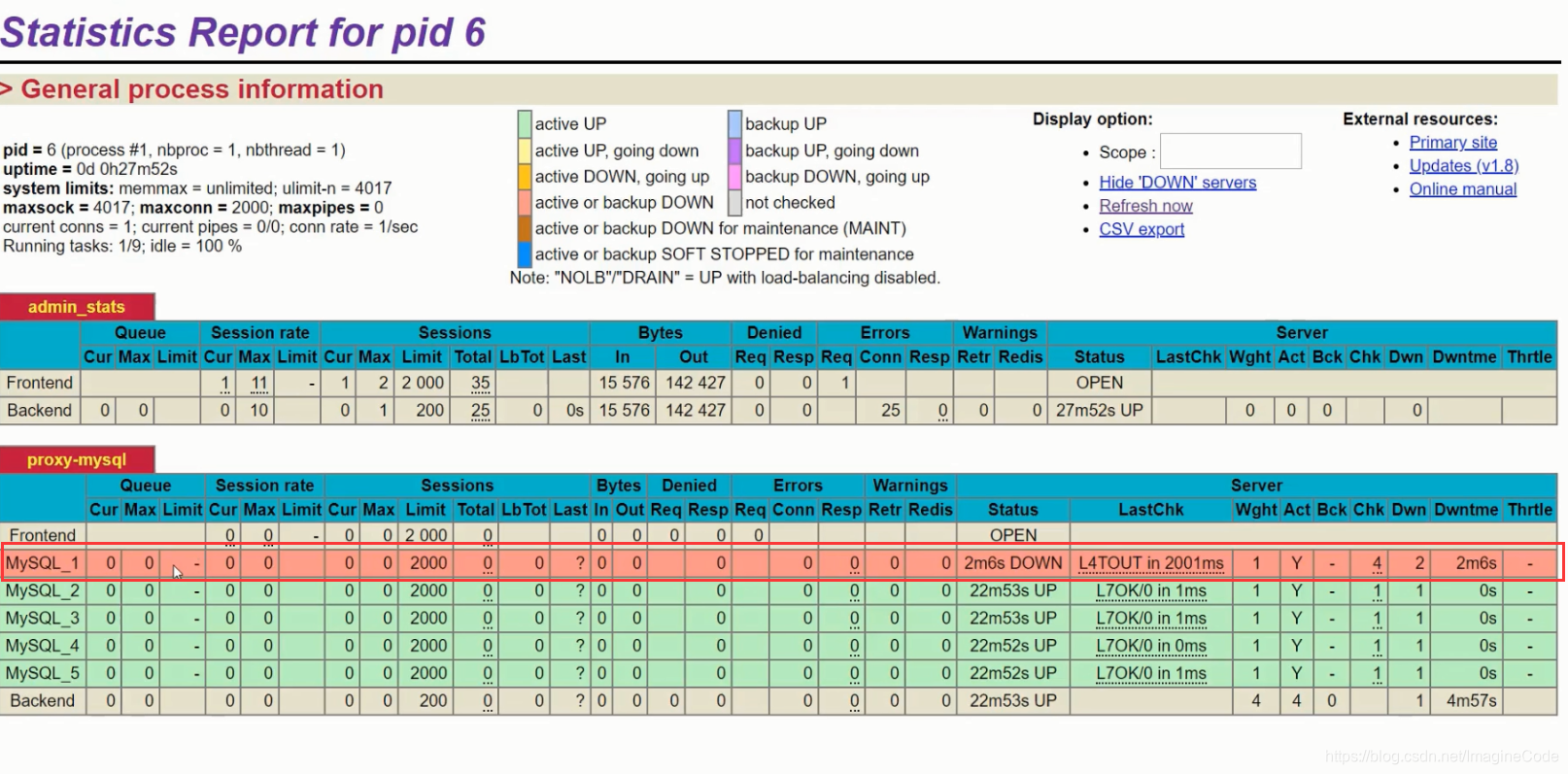
- 最后我们在主机上新建一个Haproxy数据库,并连接到CentOS中的宿主机IP,端口号也是宿主机映射的端口:

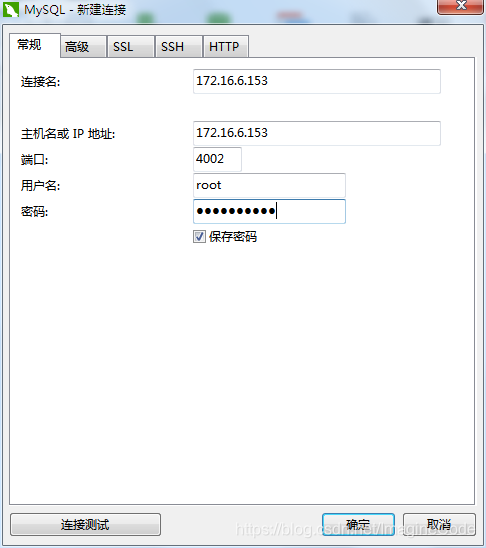
然后,我们可以在H1中对test表进行增删操作,此时H1会把这条操作转发给D1至D5的其中一个节点(实际上H1是不存储任何真实数据的,它只是进行分发操作),这个节点就会进行更新,然后由于这个节点具备PXC同步机制,它会把这次操作同步给其他4个节点。
由此可见,这样就完成了负载均衡的操作。
下一篇中,我们将探索负载均衡高可用方案。




