本文总结了Hologres对接Flink/Blink时的常见问题以及对应的诊断方法。
Common Sense
1. Hologres性能
写入性能:
列存表 InsertOrIgnore > InsertOrReplace > InsertOrUpdate
行存表 InsertOrReplcae = InsertOrUpdate > InsertOrIgnore
- InsertOrIgnore: 结果表有主键,实时写入时如果主键重复,丢弃后到的数据
- InsertOrReplace: 结果表有主键,实时写入时如果主键重复,按照主键更新,如果写入的一行数据不包含所有列,缺失的列的数据补Null
- InsertOrUpdate: 结果表有主键,实时写入时如果主键重复,按照主键更新,如果写入的一行数据不包含所有列,缺失的列不更新
点查性能: 行存 = 行列混存 > 列存
2.Blink/Flink(VVP)/开源Flink支持程度
产品形态 |
源表 |
结果表 |
维表 |
Binlog |
Hologres Catalog |
备注 |
Flink全托管 |
支持行、列存 |
支持行、列存 |
推荐使用行存 |
支持 |
支持 |
无 |
开源Flink1.10 |
支持行、列存 |
支持行、列存 |
- |
不支持 |
不支持 |
无 |
开源Flink1.11 |
支持行、列存 |
支持行、列存 |
推荐使用行存 |
不支持 |
不支持 |
从开源Flink1.11版本开始,Hologres代码已开源,详细使用请参考git。 |
开源Flink1.12 |
支持行、列存 |
支持行、列存 |
推荐使用行存 |
支持 |
不支持 |
|
Blink独享(贝叶斯) |
支持行、列存 |
支持行、列存 |
推荐使用行存 |
Hologres 0.8版本只支持行存 0.9及以上支持行存、列存 推荐使用行存 |
不支持 |
已开始逐步下线,推荐使用阿里云Flink全托管 |
3.Blink/Flink SQL例子:
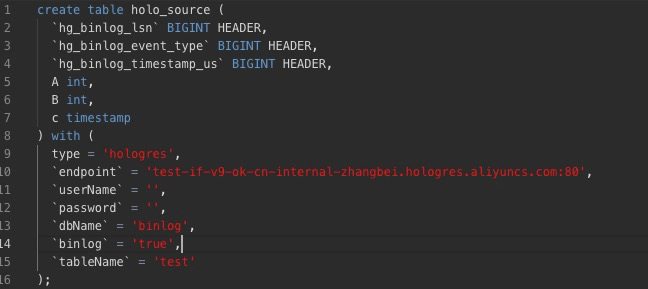
Blink/VVP/Flink SQL,都是在Flink侧声明一张表,然后根据参数映射至Hologres的一张具体的物理表,所以不支持映射至外表
实时写入慢问题排查流程
步骤1:首先确认写入相关配置
- 目标表是行存表,还是列存表,还是行列混存
- Insert模式是InsertOrIgnore、InsertOrUpdate还是InsertOrReplace
- 确认表的Table group及Shard Count
步骤2:看监控指标的实时写入延迟。
如果平均写入延迟偏高,在百毫秒甚至秒级别,通常便是后端达到了写入瓶颈,这时候有若干种可能:
- 使用了列存表的InsertOrUpdate,即局部更新,且流量较高,这种情况下会导致整体实例的CPU负载和写入延迟偏高。解决办法:这种情况下通常建议使用行存表,1.1版本后可以选择行列混存表
- 去监控查看整体实例的CPU负载,整体水位接近100%,但没有列存表的局部更新,那么通常情况下是由于高qps的查询,或者本身写入量较高导致的,解决办法:该情况下可以考虑扩容实例资源
- 确认是否有不断的Insert into select from,触发了该表的Bulkload写入,当前Bulkload写入会Block实时写入,解决办法:将Bulkload写入也转成实时写入,或者错峰执行
排查步骤3: 看是否有数据倾斜
通过一些sql看下是否有数据倾斜,或者找值班在后台查看是否shard上有数据倾斜。
select count(1) from t1 group by hg_shard_id;
解决办法:修改Distribution key
排查步骤4:后端压力
如果上述步骤检查下来没有明显问题,写入性能突然下降,一般情况是后端集群压力比较大,存在瓶颈。可以找值班确认情况
排查步骤5: 查看Blink/Flink侧的反压情况
如果上述步骤排查下来,发现Hologres侧没有明显的异常,通常情况下是客户端慢了,也就是Blink/Flink侧本身就慢了,这时候可以确认是否是Sink节点反压了。
如果作业只有一个节点,就无法看出是否反压了,这时候可以将Sink节点单独拆开再观察。具体可以请联系Flink技术支持排查。
写入的数据有问题排查流程
这种情况通常是由于数据乱序引起的,比如相同主键的数据分部在不同的Flink Task上,写入的时候无法保序。需要确认Flink SQL的逻辑,最后写出到Hologres的时候,是否按照Hologres表的主键进行Shuffle了。
维表查询问题排查流程
维表join和双流Join
对于读Hologres的场景,需要首先确认用户是否使用对了,是否错将双流Join当成维表Join来使用了。以下是Hologres作为维表的用法,如果少了以下关键字,则会变成双流Join!

维表查询
1. 首先确认维表存储格式
确认是行存表、列存表还是行列混存
2. 维表查询延迟高
维表的使用,最常见的问题就是Flink/Blink侧用户反馈Join节点有反压,导致整个作业的吞吐上不去
排查步骤1: 确认Flink维表Join的模式
当前Hologres Flink Connector的维表Join功能支持同步和异步模式两种,异步模式性能要优于同步模式,具体需要看Flink Sql进行区分,以下是一个开启异步维表查询功能的SQL实例:
注意:这里的async参数,该参数的默认值为False,即如果Flink SQL没有该参数,则没有开启异步模式,可以建议开启异步模式。
CREATE TABLE hologres_dim(
id INT,
len INT,
content VARCHAR
) with (
'connector'='hologres',
'dbname'='', --Hologres的数据库名称。
'tablename'='', --Hologres用于接收数据的表名称。
'username'='', --当前阿里云账号的AccessKey ID。
'password'='', --当前阿里云账号的AccessKey Secret。
'endpoint'='' --当前Hologres实例VPC网络的Endpoint。
'async' = 'true'--异步模式
);
排查步骤2: 确认后端查询延迟
同实时写入一样,依旧去监控界面查看延迟:
- 确认是否是列存表在做维表,列存表的维表在高QPS场景下开销很高。
- 如果是行存表,且延迟高,通常情况下是实例整体负载较高导致的,需要进行扩容。
排查步骤3: 确认Join的Key是否是Hologres表的主键
自VVR 4.x (Flink 1.13) 版本开始,Hologres Connector基于Holo Client实现了Hologres表的非主键查询,这种情况通常性能会比较差、实例负载也比较高,尤其是建表没有特别优化过的情况。这时候需要引导优化表结构,最常见的就是将Join的key设置成Distribution Key,这样就能实现Shard Pruning。
排查步骤4 查看Blink侧的反压情况
同写入,同样可以排查是否是Join节点导致的反压。
常见问题
ERPC_ERROR_TIMEOUT或者ERPC CONNECTION CLOSED
出现如下报错:com.alibaba.blink.store.core.rpc.RpcException: request xx UpsertRecordBatchRequest failed on final try 4, maxAttempts=4, errorCode=3, msg=ERPC_ERROR_TIMEOUT,
报错原因:一般是写入压力太大写入失败或者集群比较繁忙,可以观察Holo实例的CPU负载是否打满, CONNECTION CLOSED可能是负载过大导致后端节点挂掉了,OOM或者Coredump。
解决办法:如果是偶尔一次可以正常重试可以忽略;如果频繁出现可以联系值班排查原因。
BackPresure Exceed Reject Limit

报错原因:通常是Hologres后端写入压力过大,导致Memtable来不及刷盘导致写入失败。
解决办法:如偶发失败可忽略该问题,或者Sink加上参数rpcRetries = '100' 来调大写入重试次数。如果一直报该错误,需要联系Hologres值班同学确认后端实例状态。
The requested table name xxx mismatches the version of the table xxx from server/org.postgresql.util.PSQLException: An I/O error occurred while sending to the backend.Caused by: java.net.SocketTimeoutException: Read timed out
报错原因:通常是用户做了Alter Table导致Blink写入所带表的Schema版本号低于Server端版本号导致的,并且超过了客户端的重试次数。
解决办法:
- 如果不是经常发生可以忽略该报错
- 若是重试多次还是报错,请联系值班同学处理
Failed to query table meta for table
报错原因:对于该报错,一种可能是用户读写了一张Hologres的外表,Hologres Connector不支持读写外表。
如果不是,可能是Hologres实例 Meta出现了问题,联系Hologres值班同学确认
Cloud authentication failed for access id
报错原因:该报错通常是用户配置的AK信息不对,或者用户没有添加账号至Hologres实例。
解决办法:
1.检查当前账户的access id 和access key填写是否正确,一般是access key错误或者有空格。
2.检查不出原因可以用当前ak连接holoweb(使用账号密码方式登录),在测试联通性时看报错是什么,还是一样的报错说明access key有问题,若是报错没有FATAL:role“ALIYUN$xxxx“does not exist,说明账号没有实例的权限,需要管理员给授权。
Hologres维表Join不到数据
确认用户的Hologres维表是不是使用了分区表,Hologres维表暂不支持分区表‘
Modify record by primary key is not on this table
报错原因:实时写入的时候选择了更新模式,但是hologres的结果表没有主键
shard columns count is no match
报错原因:用户写入Hologres的时候,没有写入完整的distribution key的列(默认是主键)
Full row is required, but the column xxx is missing
报错原因:Hologres 老版本的报错信息不是很明显,这个通常是用户没有写某列数据,而那一列是not nullable的
VVP用户读写Hologres导致JDBC连接数暴涨
报错原因:VVP Hologres Connector读写Hologres(除了Binlog),采用JDBC模式,最大占用读写holo表数量*并发度 * connectionSize(VVP表的参数,默认为3)个连接。
解决办法:合理规划任务连接数,降低并发度或者connectionSize。如无法调低并发度或connectionSize,可以为表设置参数useRpcMode = 'true' 切回至Rpc模式。
Blink/VVP用户读写Hologres报错显示无法连接Hologres
报错原因:弹外Blink/VVP集群默认访问公网很慢或者无法访问。
解决办法:需要保证和Hologres实例在相同Region,且使用VPC的Endpoint
Hologres rpc mode dimension table does not support one to many join
Blink/VVP的rpc mode维表必须是行存表,且join的字段必须是主键,抛此异常的原因往往是以上两个条件不满足;jdbc模式没有这个要求,但是维表仅推荐使用行存表或者行列共存表。
DatahubClientException
Caused by: com.aliyun.datahub.client.exception.DatahubClientException: [httpStatus:503, requestId:null, errorCode:null, errorMessage:{"ErrorCode":"ServiceUnavailable","ErrorMessage":"Queue Full"}]
大量消费binlog作业由于某种原因同时重启导致线程池被占满,可以分批次恢复作业。
Error occurs when reading data from datahub
Error occurs when reading data from datahub, msg: [httpStatus:500, requestId:xxx, errorCode:InternalServerError, errorMessage:Get binlog timeout.]
可能是binlog每条数据太大,乘上攒批之后,每个rpc请求的大小超过限制,在每行数据字段较多且有很长的字符串等字段时,可以减小攒批配置。



