[TOC]
概念
ES -> 数据库
索引 index -> 表
文档 document -> 每一条记录
字段 fields -> 列,每一个属性
分片(shard) :把索引库拆分为多份,分别放在不同的节点上,比如有3个节点,3个节点的所有数据内容加在一起是一个完整的索引库。分别保存到三个节点上。可以水平扩展,提高吞吐量。
备份(replica) :每个shard的备份。
倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引
正排索引:
根据文档的ID来获取文档的内容(根据Key去查Value的值,数据量大的时候检索的效率就会降低)
倒排索引:
根据文档的内容来进行分词。
根据分词的内容来查到这些词在哪些文档中出现过,那么就会把这些文档的记录反馈出来。
比如搜索 博客,那么就会把记录1,2,3都返回出来,搜索的效率比正排索引去数据库中查询高的多。
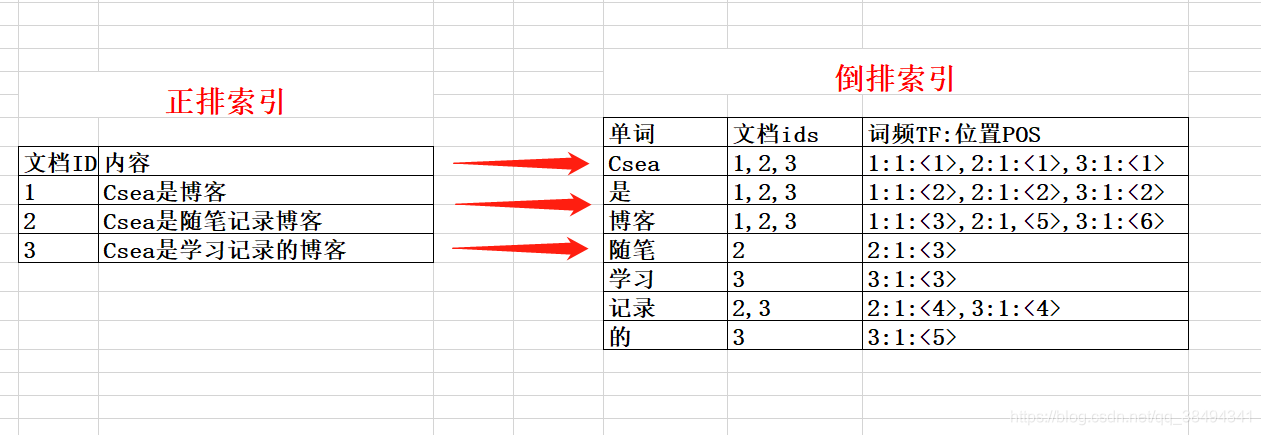
词频: Csea在文档ID为1中出现,出现了1次(1:1)
位置: Csea在文档ID为1中出现的是第一个位置(< 1 >)
为什么使用词频、位置?
这是因为,这是计算中的一个因子,是为了更加方便的去排序。
出现的频率越高,文档和用户搜索的词条相关性就越大,那么就更加容易被用户所搜到。
安装
VM虚拟机Centos7.3
elasticsearch7.4.2
上传下载的ES到虚拟机
# 解压
tar -zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz
# 移动ES
mv elasticsearch-7.4.2 /usr/local
# 进入目录
cd elasticsearch-7.4.2
# 新建一个data文件夹
mkdir data文件夹说明
bin:包含了一些脚本文件
config:配置文件目录
JDK:java环境
lib:相关依赖jar文件
logs:日志文件
modules:es相关的模块
plugins:可以自己开发的插件
data:自己新建的,后续可以作为索引目录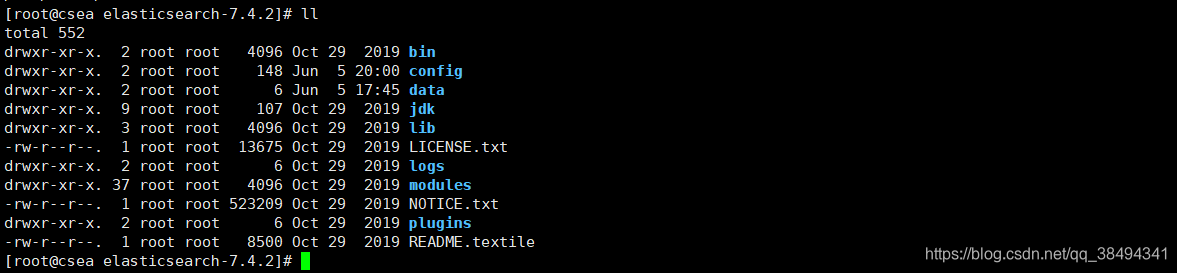
修改配置
cd config
# 编辑配置文件
vim elasticsearch.yml配置文件
# 集群名称,默认是elasticsearch,单节点也可以命名
cluster.name: csea-elasticsearch
# 节点名称
node.name: es-node1
# 数据目录
path.data: /usr/local/elasticsearch-7.4.2/data
# 日志路径
path.logs: /usr/local/elasticsearch-7.4.2/logs
# 绑定地址,本地可以设置为0.0.0.0
network.host: 0.0.0.0
# es启动端口
http.port: 9200
# 开启跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
# 发现节点,写自己配置的就行了${node.name}
cluster.initial_master_nodes: ["es-node1"]修改JVM的配置
vim jvm.options
# 因为在虚拟机中,没有默认1g这么大,就先改成128m
-Xms128m
-Xmx128m由于启动ES不能由root用户启动,必须另外创一个用户启动
# 查看当前执行命令的用户
whoami
# 添加用户
useradd esuser
cd cd /usr/local/elasticsearch-7.4.2/
# 给esuser添加操作es文件夹的权限
chown -R esuser /usr/local/elasticsearch-7.4.2
chown -R esuser:esuser /usr/local/elasticsearch-7.4.2
# 切换用户
su esuser
# 启动es
./elasticsearch启动的时候报了两个错误:
- es打开的最大文件数只有4096,至少65535
- 最大虚拟内存只有65530,至少262144

修改限制
su root
vim /etc/security/limits.conf
# 添加配置
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
vim /etc/sysctl.conf
# 添加配置
vm.max_map_count=262145
# 刷新配置文件
sysctl -p
# 重新启动es
su esuser
./elasticsearch
# 通过后台的方式运行
./elasticsearch -d9200是web上的访问端口
9300是es集群之间内部通讯的端口,内部是通过TCP进行通讯的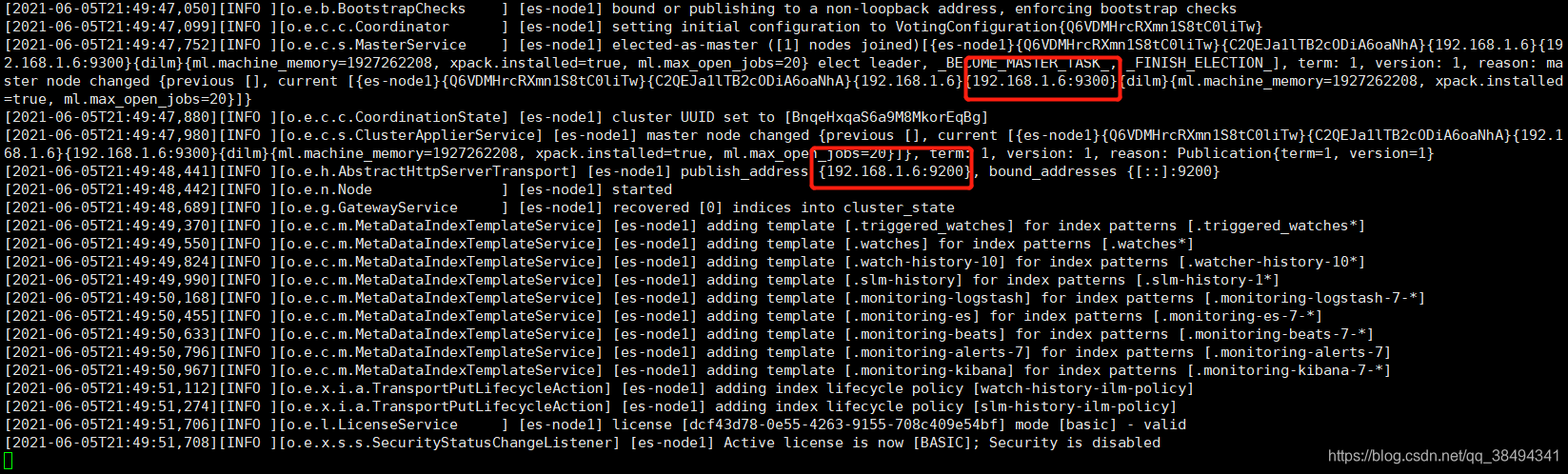
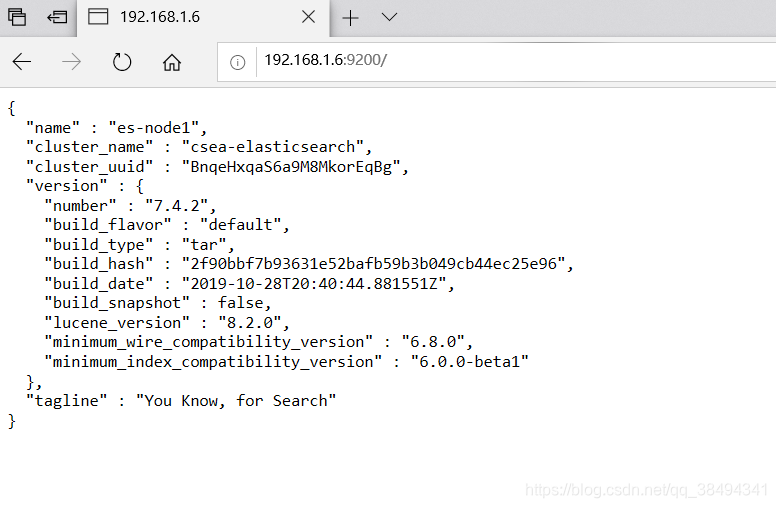
可视化界面
Github地址
chorme应用商店搜索elasticsearch-head插件安装即可
可视化使用
创建索引
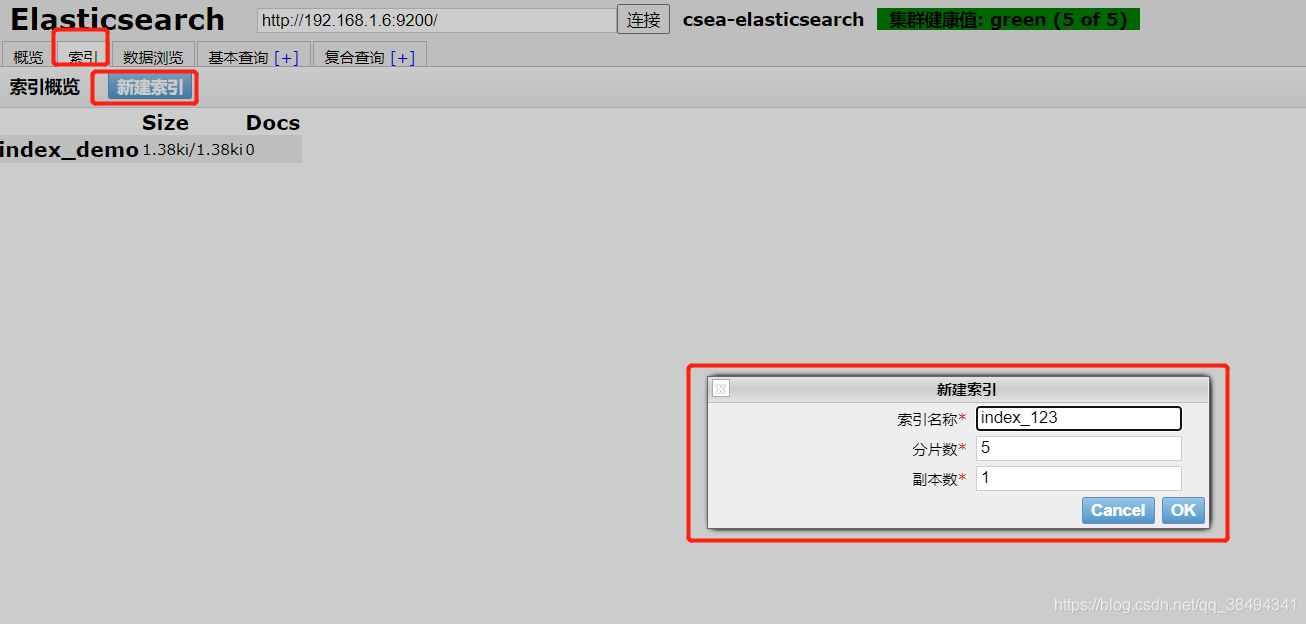
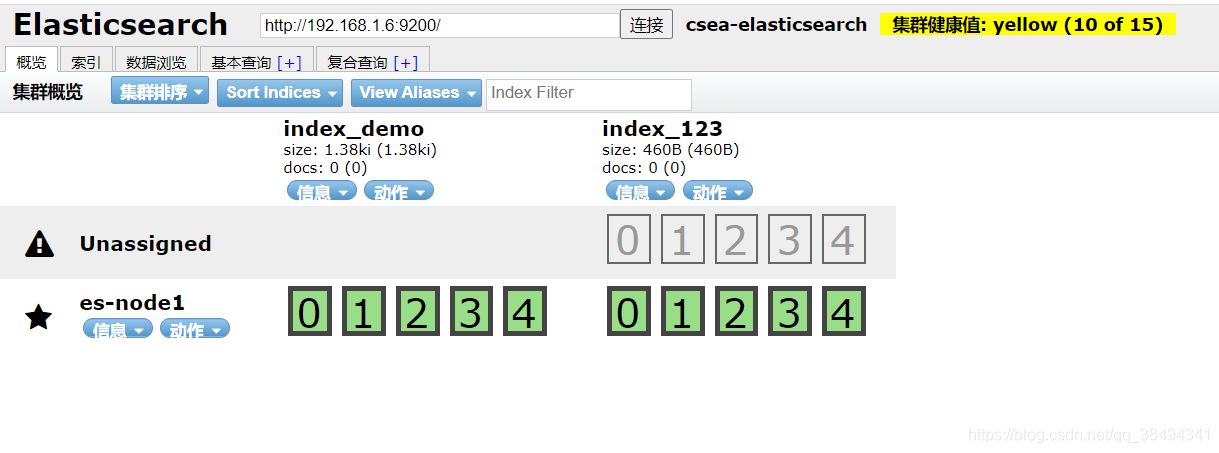
集群健康值
green: 所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow: 所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。
red: 至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
查看健康状态信息
http://{IP}:{port}/_cluster/health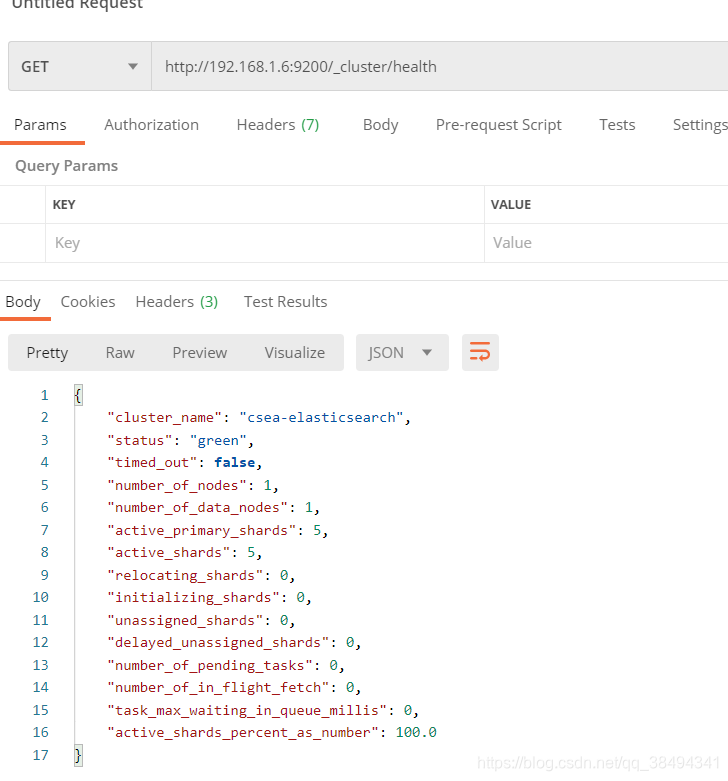
删除索引
方式一: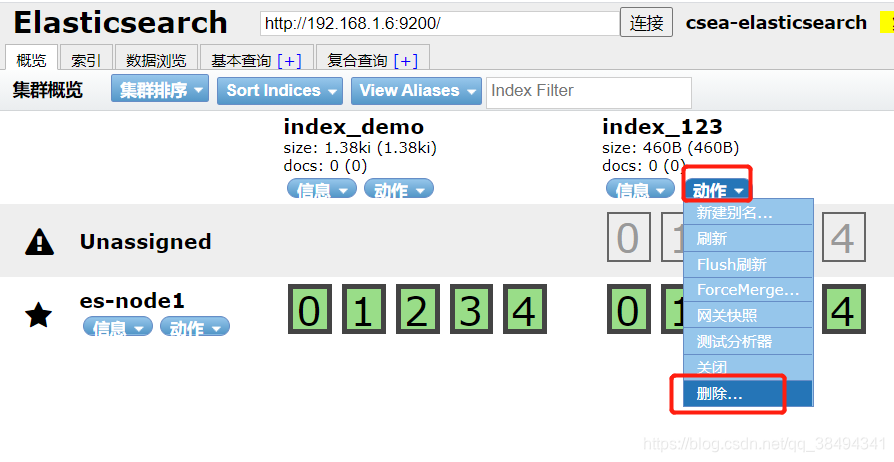
方式二:
Delete请求:http://{IP}:{port}/{索引名称}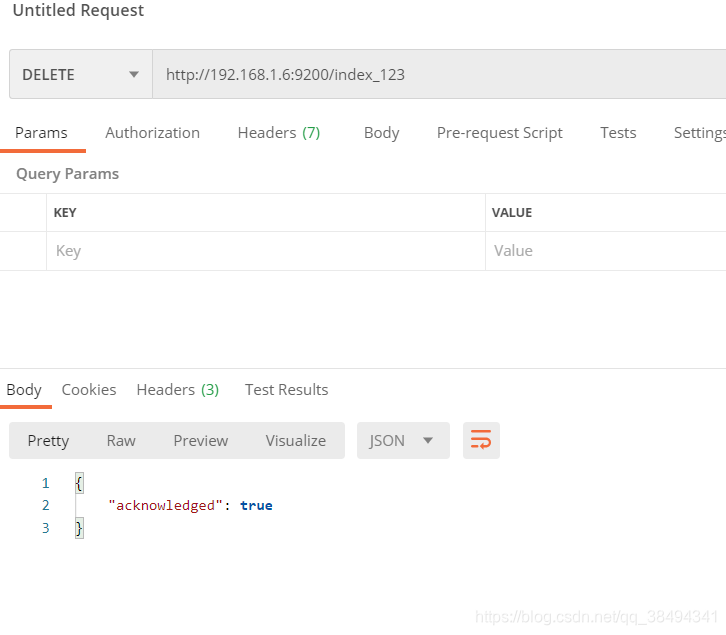
查看索引
查看某个节点下全部的索引:
Get请求:http://{IP}:{port}/_cat/indices?v
url后加上?v可以在返回的信息上面加上列名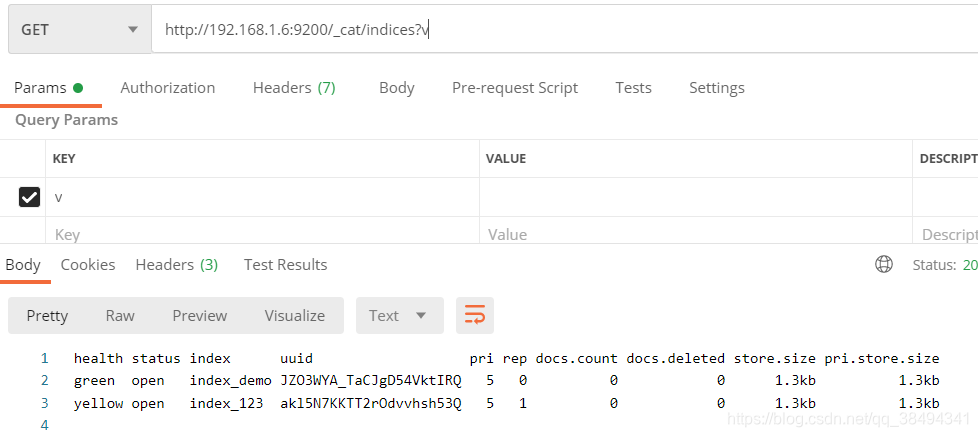
查看某个索引详情:
Get请求:http://{IP}:{port}/{索引名称}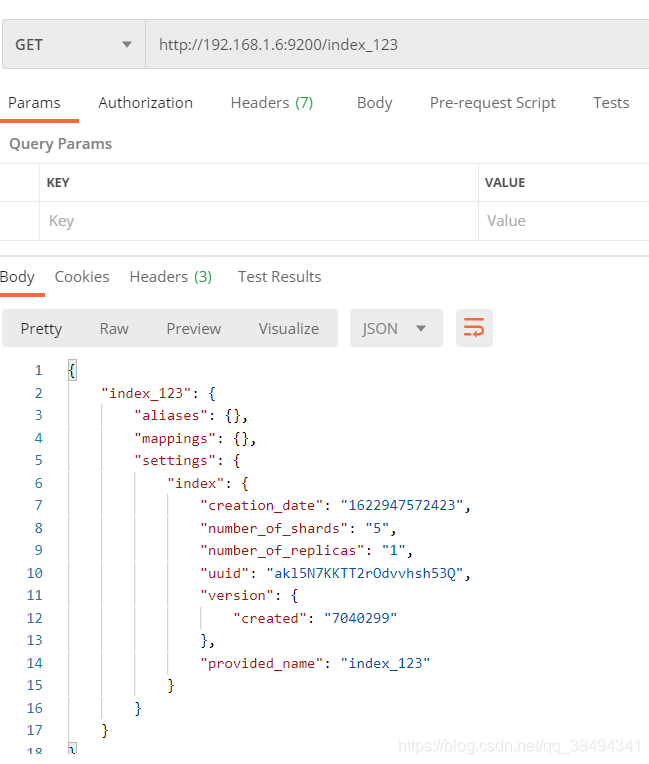
mapppings
映射,数据类型的设置,类似数据库的某个字段是什么类型的数据(varchar,int等)
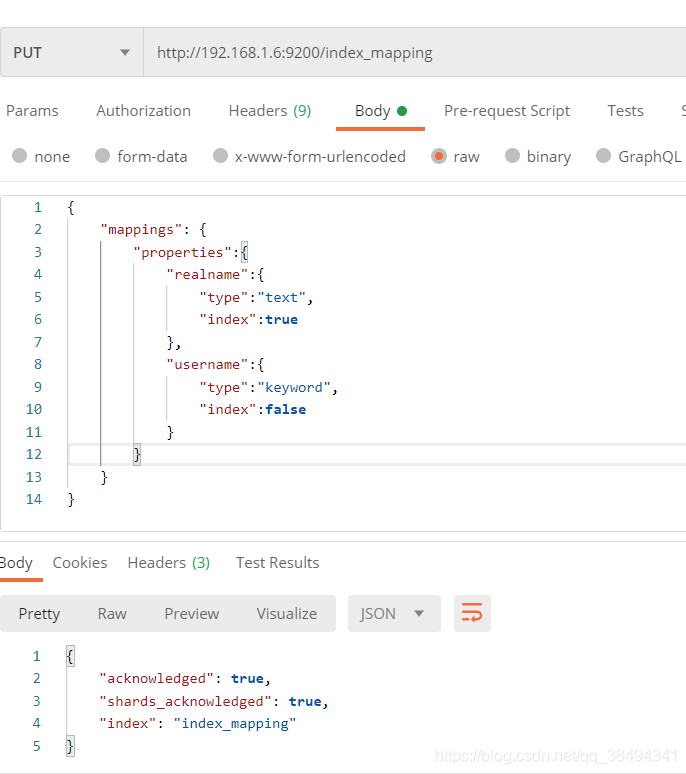
创建mapping
Put请求:http://{IP}:{port}/{索引名称}
{
"mappings": {
"properties":{
# 字段
"realname":{
# 字段类型
"type":"text",
# 是否被索引
"index":true
},
"username":{
"type":"keyword",
"index":false
}
}
}
}
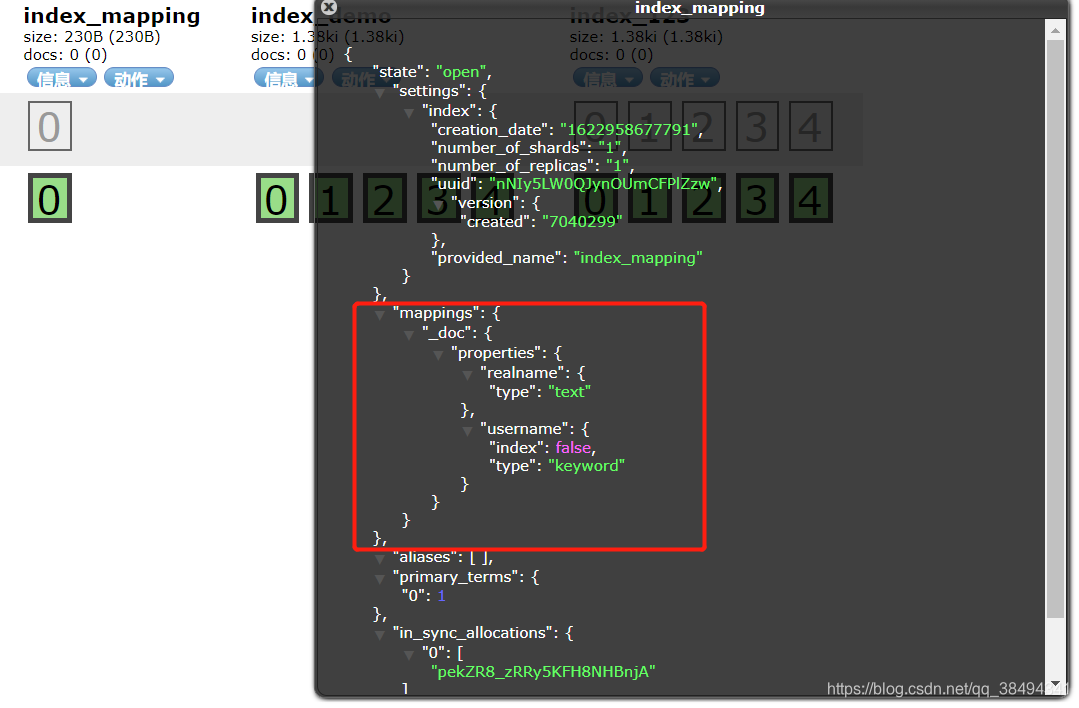
text类型是会被分词的,但是keyword是不会被分词,用来精确检索。这两者都是字符串,在老的版本中是string,后来把string拆分为了text和keyword。
当某个属性在ES中创建之后,是不支持修改的,只能删除重新创建!
分词测试
Get请求:http://{IP}:{port}/{索引名称}/_analyze
_analyze就是分词,分析的意思
使用text就会进行分词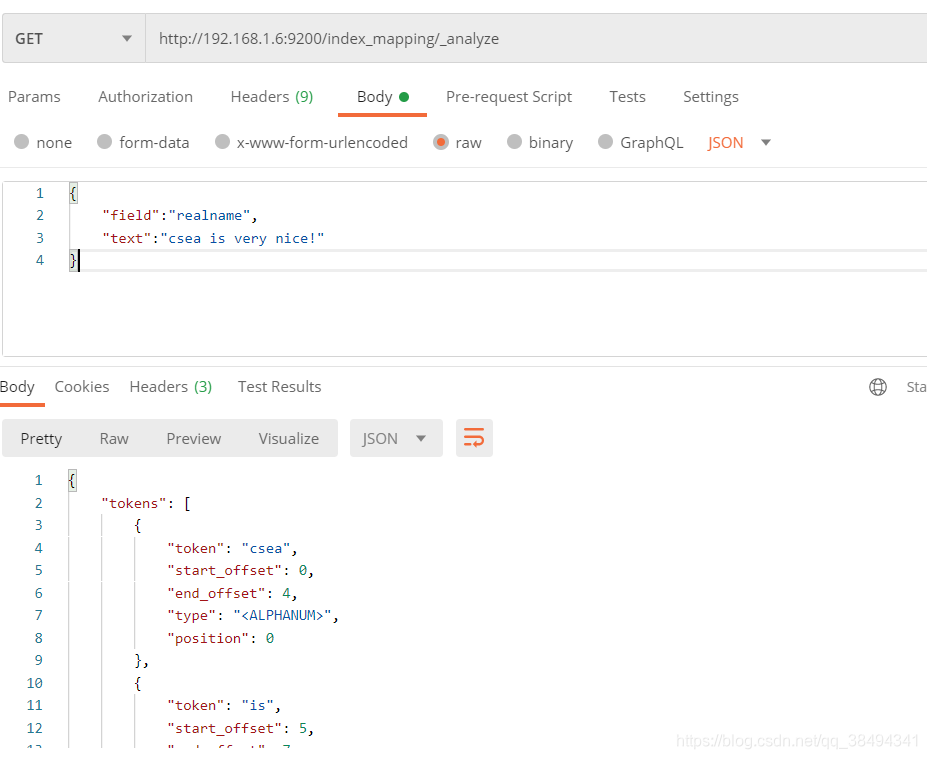
使用keyword就不会分词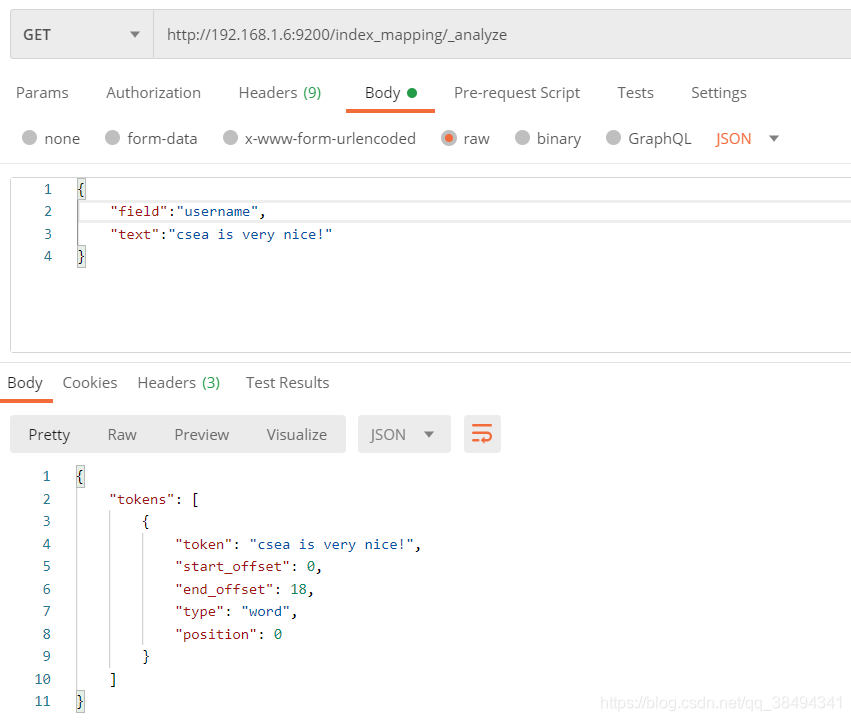
修改mappgings
Post请求:http://{IP}:{port}/{索引名称}/_mapping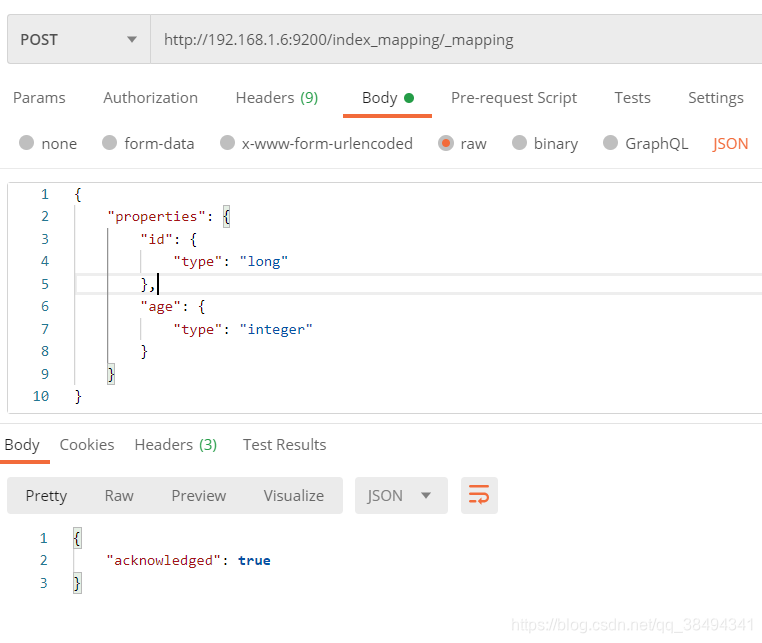
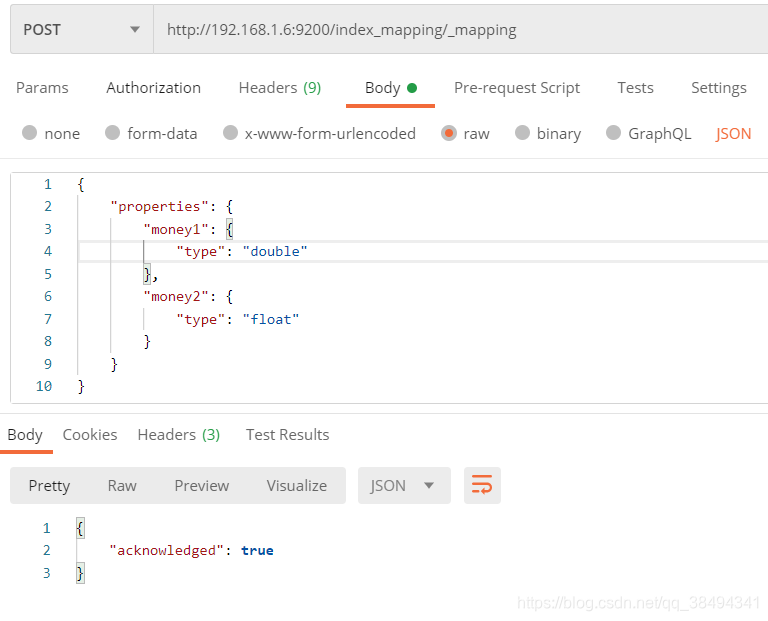
主要类型包括:
text、keyword
long、integer、short、byte
double、float
boolean、date、object
数组不能混,类型一致,比如都是字符串数组
操作文档
新增文档
Post请求:http://{IP}:{port}/{索引名称}/_doc/{文档id}
不主动添加文档ID,ES也会默认生成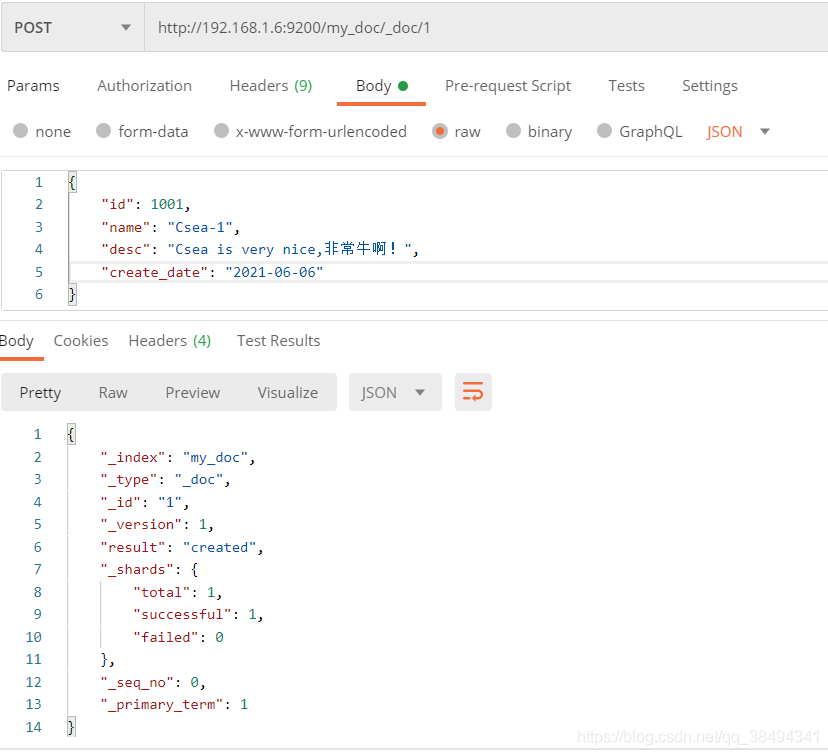
可以到数据浏览,选择对应的索引查看添加的数据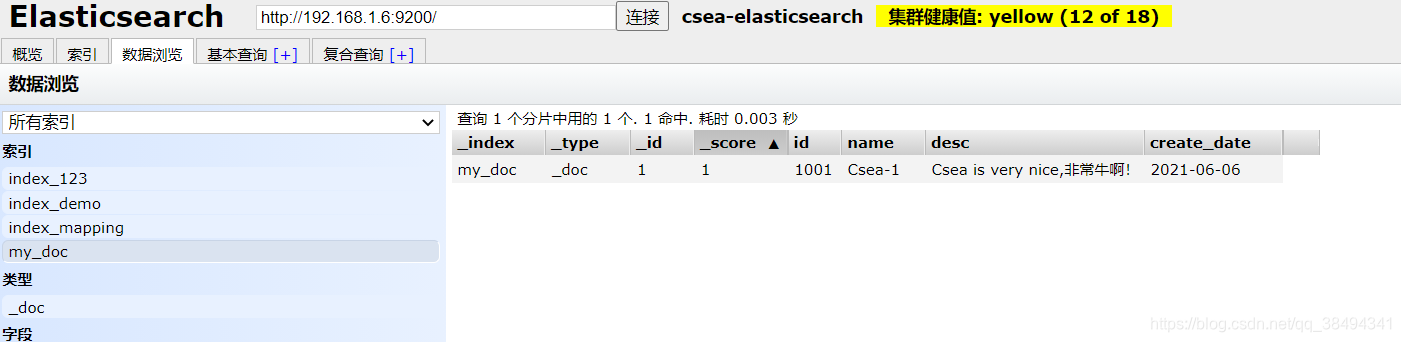
首先可以看到,mappings自动映射了,并且在name和desc两个字段下,包含了fields,也就是说针对这个字段可以启动多种的索引模式。
ignore_above是指的当前这个属性索引的长度,超过了这个长度就会被忽略, 不会去使用了。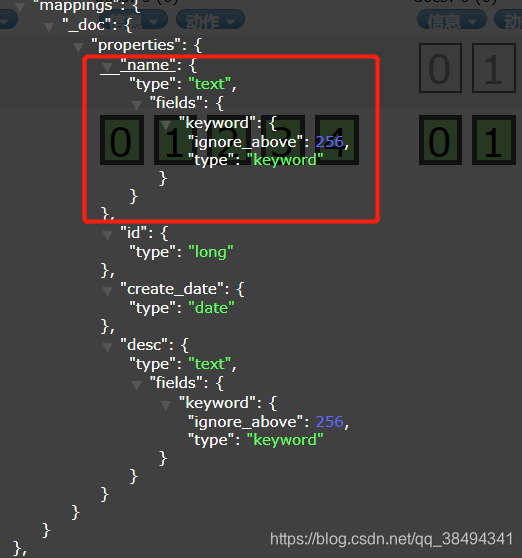
可以直接在可视化界面中搜索,他会根据分词过滤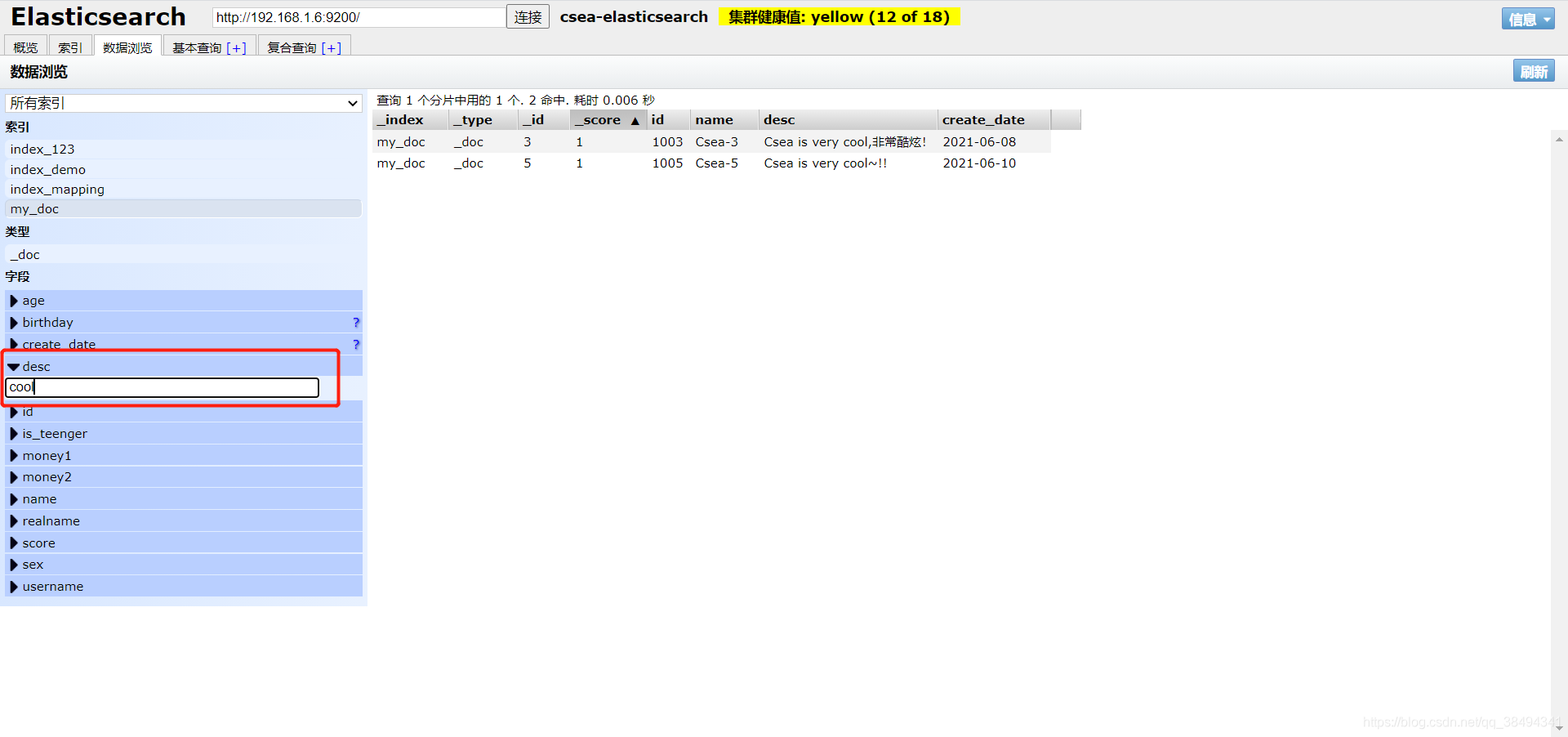
删除文档
Delete请求:http://{IP}:{port}/{索引名称}/_doc/{文档id}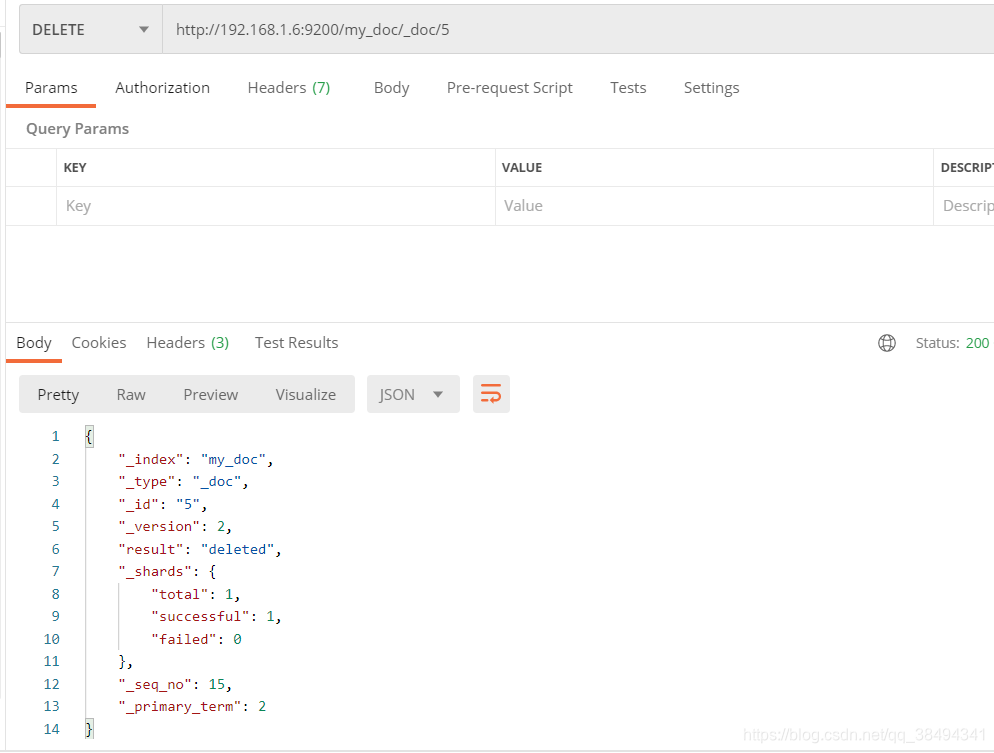
每一次的执行,version都是往上累加,也就是这并不是真正的物理删除,是逻辑删除,数据还是在磁盘中的,只有到磁盘中的文件越来越多了,才会去被动清理。
修改文档
方式一,增量修改:
Post请求:http://{IP}:{port}/{索引名称}/_doc/{文档id}/_update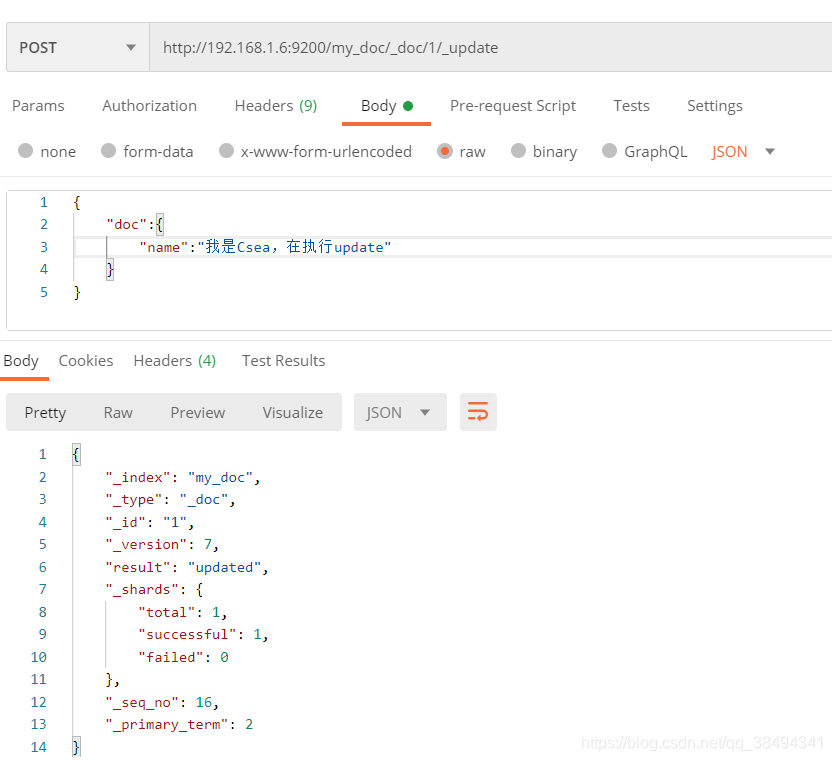
方式二,全量修改:
Put请求:http://{IP}:{port}/{索引名称}/_doc/{文档id}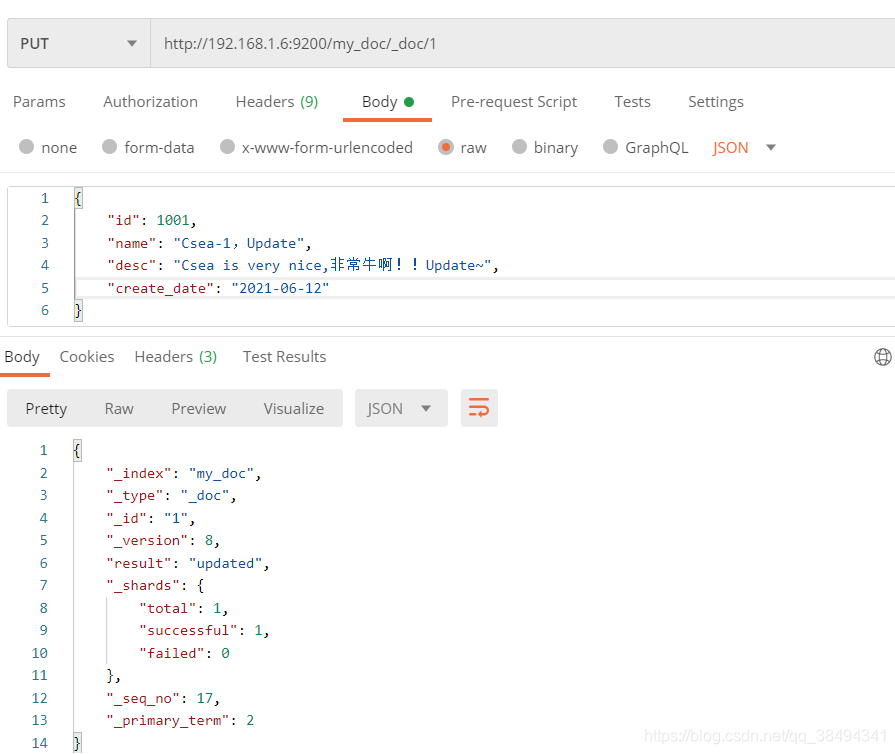
查询文档
根据ES主键查询:
Get请求:http://{IP}:{port}/{索引名称}/_doc/{文档id}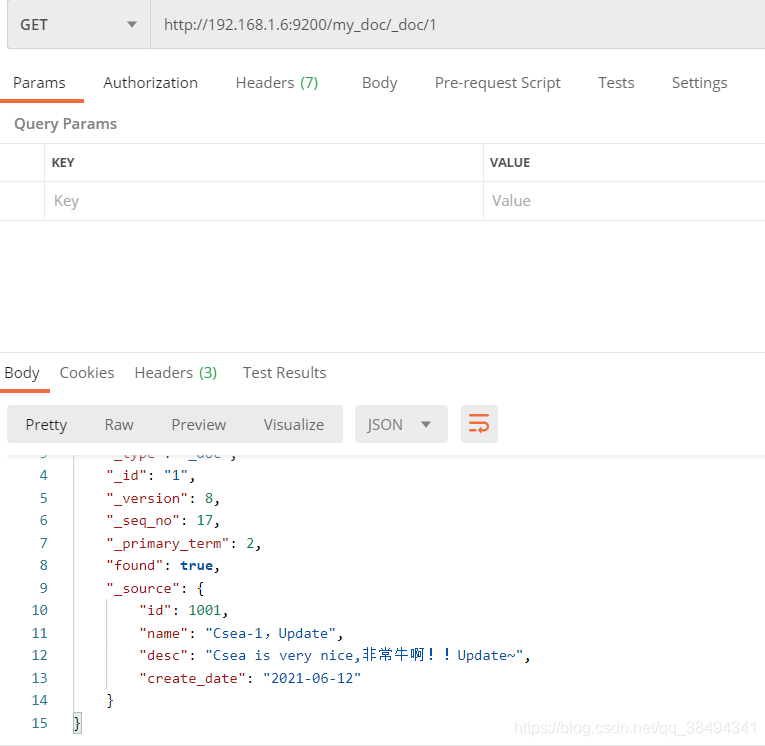
查询文档下的所有数据:
Get请求:http://{IP}:{port}/{索引名称}/_doc/_search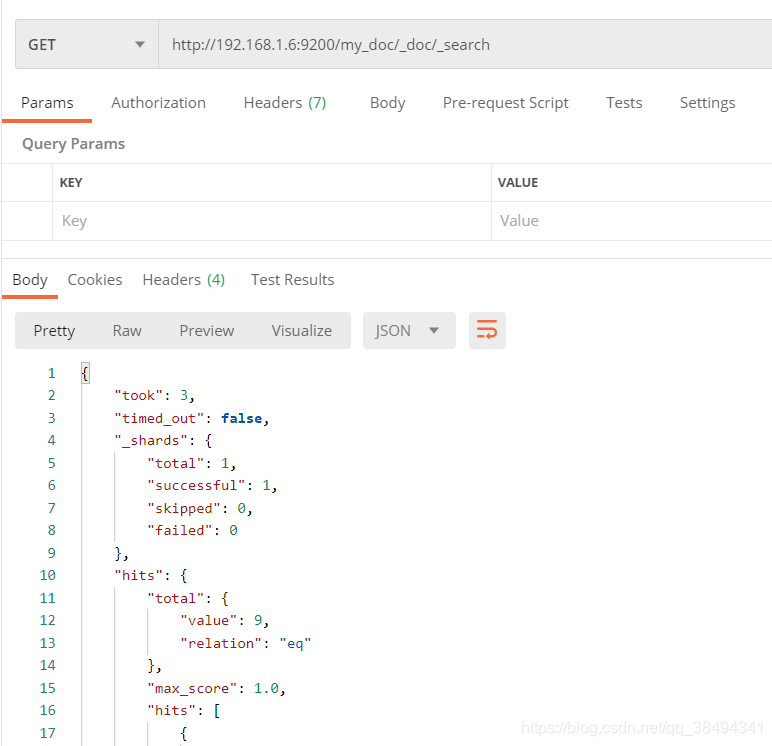
took:耗时
hits:命中记录数
max_socre:搜索匹配度
选择字段查询:
Get请求:http://{IP}:{port}/{索引名称}/_doc/{文档id}?_source={字段},{字段}
Get请求:http://{IP}:{port}/{索引名称}/_doc/_search?_source={字段},{字段}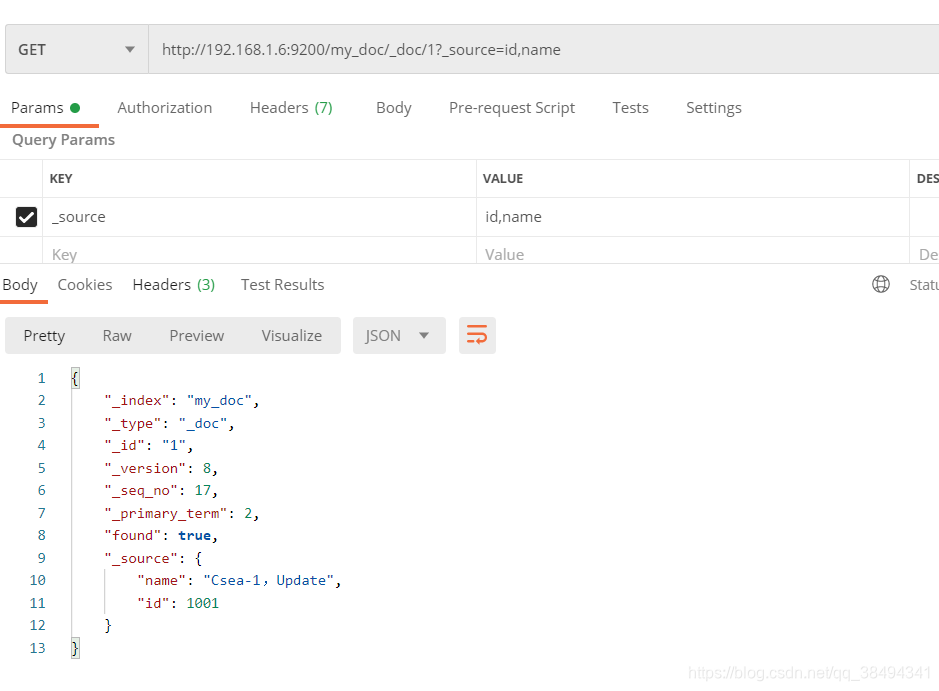
查询文档存不存在
推荐使用Head请求,因为使用Head请求时,如果文档存在,请求会返回200,如果不存在则返回404。
如果使用Get去请求也可以,但是返回的的数据体比较大,从下面两张图中可以看出,相差了几倍,如果数据量更大的时候就相差的更大。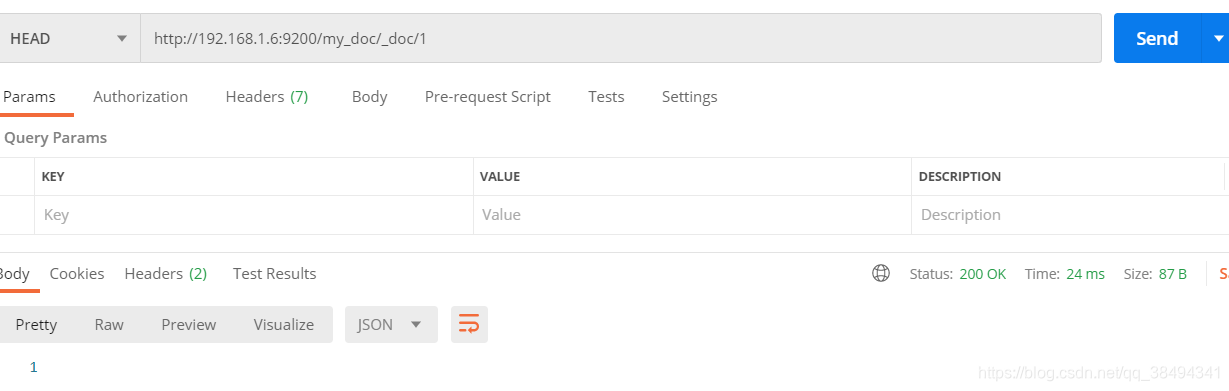
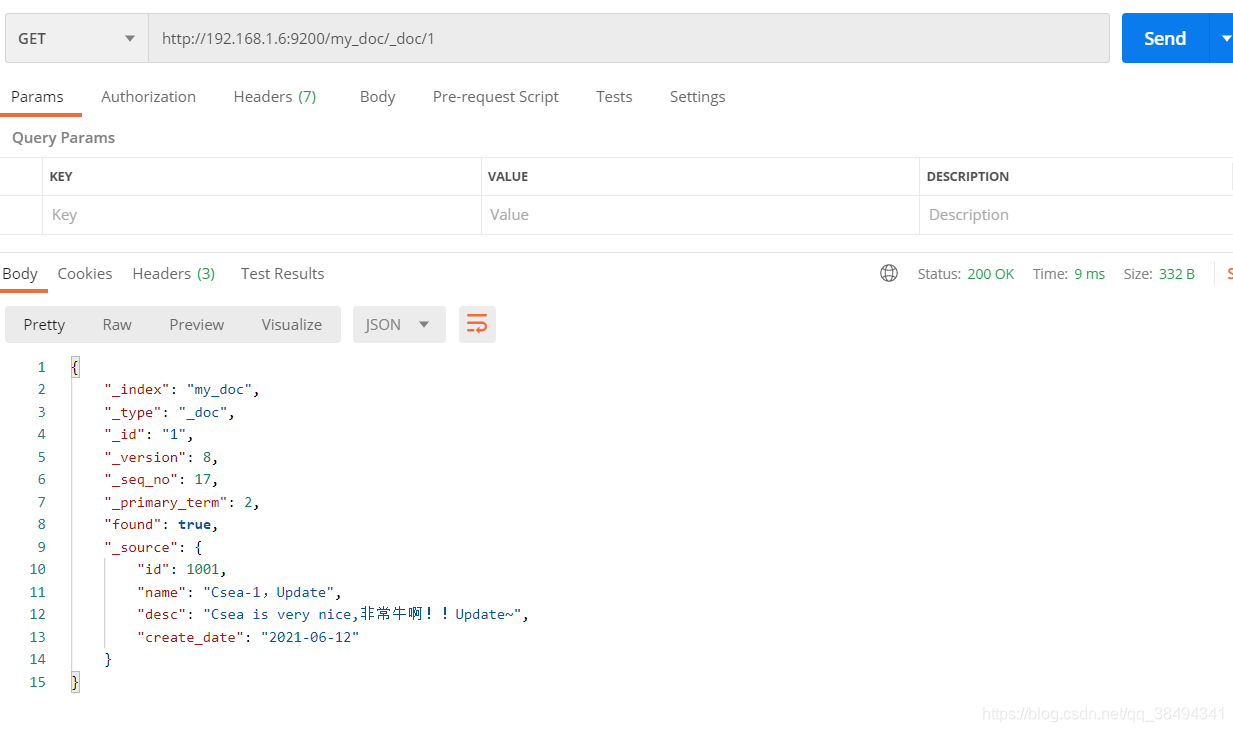
文档乐观锁
首先查看一下当前要修改文档的信息,注意 _seq_no 、_primary_term 两个值(这是新版本中的乐观锁控制,老版本中使用 version 进行控制)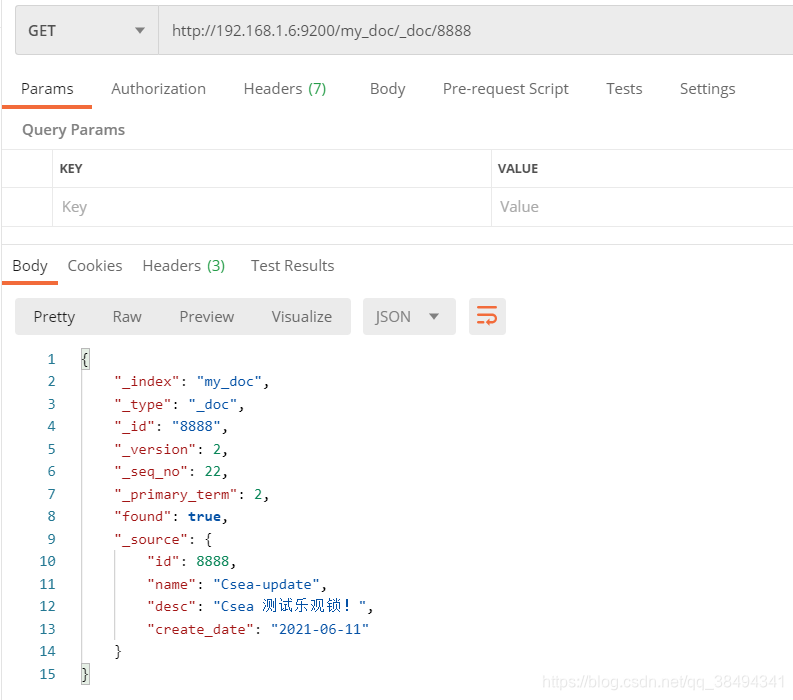
使用乐观锁进行更新操作,如下需要带上 _seq_no 、_primary_term两个值,当操作成功之后,_seq_no是一直会累加(类似于version)。
Post请求:http://{IP}:{port}/{索引名称}/_doc/{文档id}/_update?if_seq_no={_seq_no}&if_primary_term={_primary_term}
老版本中就是使用?version进行控制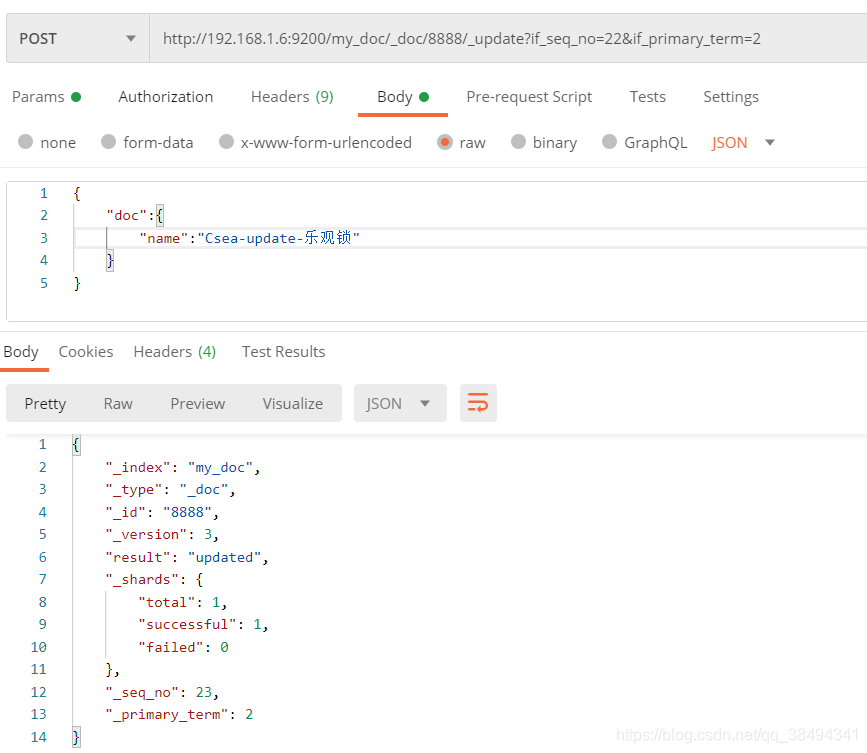
如果没有按照最新的 _seq_no 、_primary_term 值进行请求,进出出现如下提示: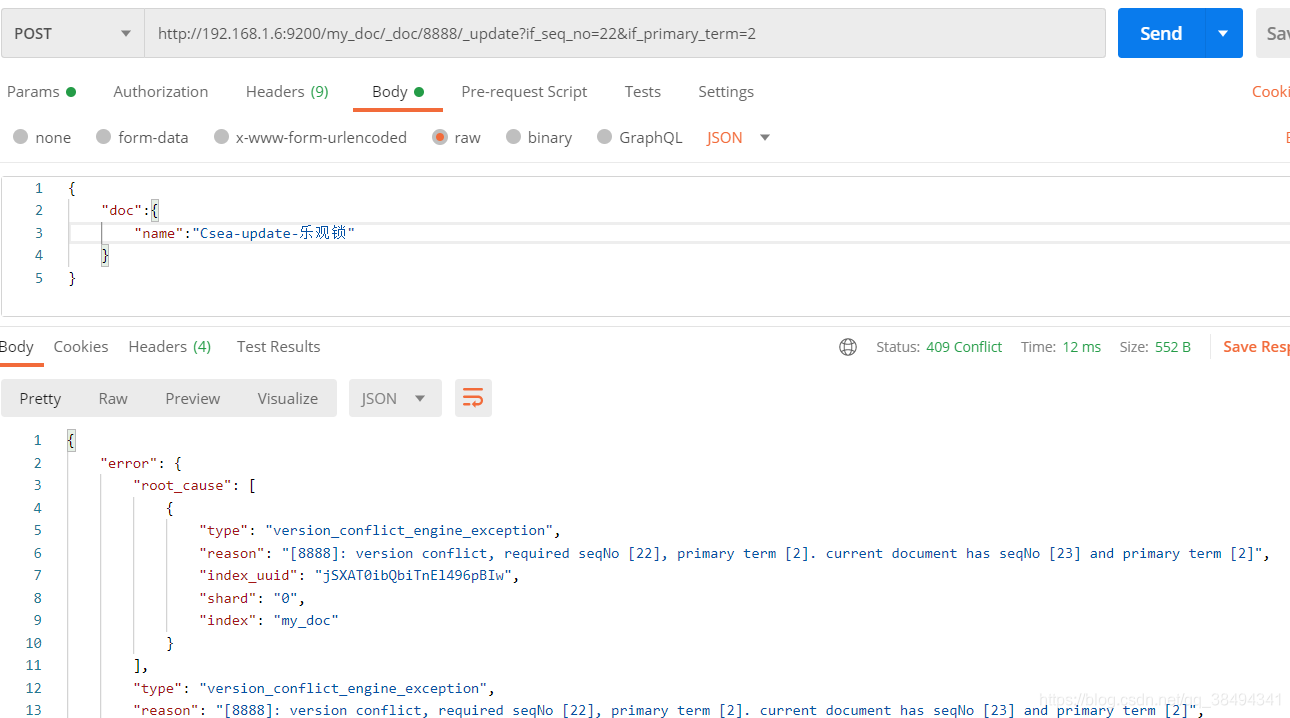
分词
测试分词
Get请求:http://{IP}:{port}/_analyze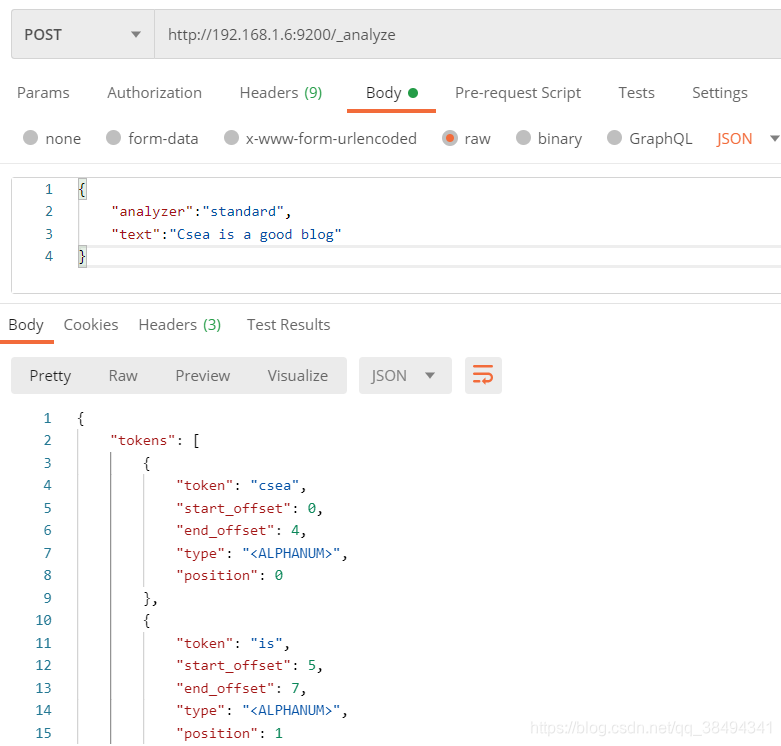
{
# standard是默认的标准分词器
"analyzer":"standard",
"text":"Csea is a good blog"
}结果:
{
"tokens": [
{
"token": "csea",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "is",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "a",
"start_offset": 8,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "good",
"start_offset": 10,
"end_offset": 14,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "blog",
"start_offset": 15,
"end_offset": 19,
"type": "<ALPHANUM>",
"position": 4
}
]
}ES中默认对于中文的分词是一个字一个字进行拆分的,需要扩展安装中午分词器
指定索引分词
Get请求:http://{IP}:{port}/{索引名称}/_analyze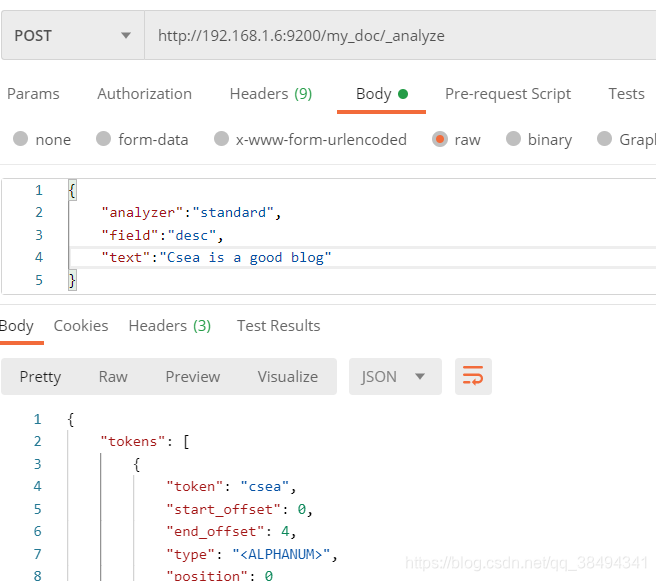
standard
ES的默认分词器
- 所有的大写字母会转为小写
- 内容中出现数字也会进行分词
simple
- 会按照非字母进行拆分,比如don't会拆分为don 和t
- 所有的大写字母也会转为小写,如Csea转为csea
- 内容中如果包含1、2、3的数字,他会进行去除,不会进行分词
whitespace
- 按照空格进行分词,如 Csea,I 这样就是一个分词
- 大写字母不会转为小写
stop
- 会去除取用的助词,如 a,the等
keyword
- 整一段内容就是一个分词,如My name is Csea. 这就是一个分词
中文分词器-ik
在Release里下载对应的版本,我这里是7.4.2
# 解压到指定目录下
unzip elasticsearch-analysis-ik-7.4.2.zip -d /usr/local/elasticsearch-7.4.2/plugins/ik重启es即可生效
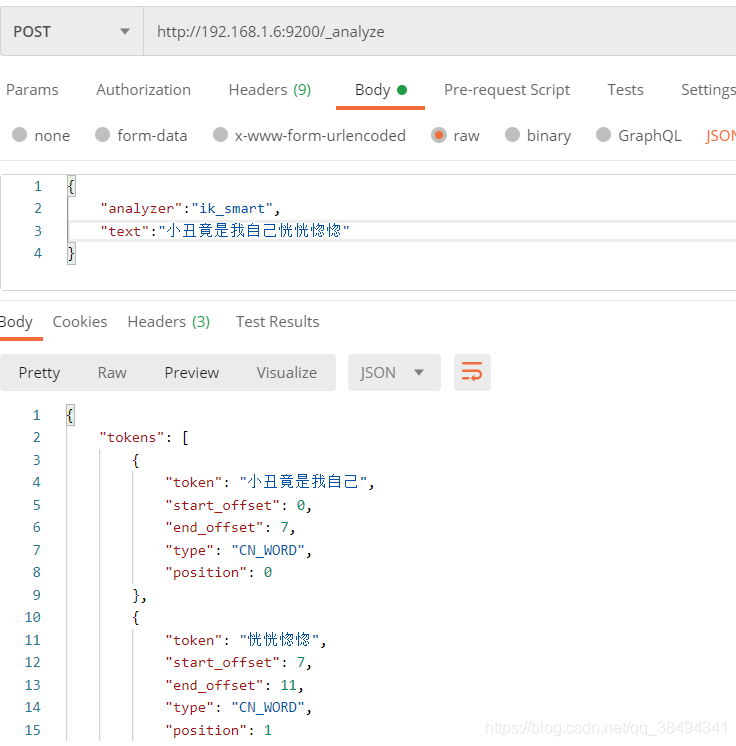
ik_max_word
会将文本做最细粒度的拆分,会穷尽各种可能的组合。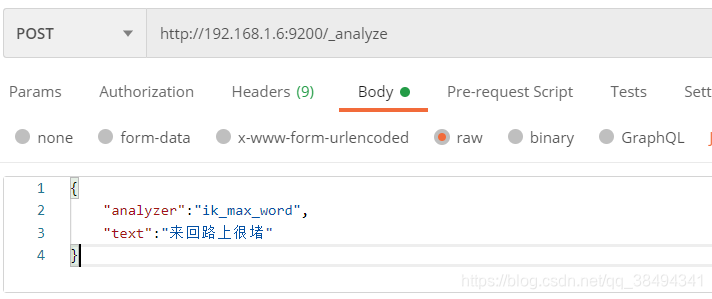
分词结果
{
"tokens": [
{
"token": "来回",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "回路",
"start_offset": 1,
"end_offset": 3,
"type": "CN_WORD",
"position": 1
},
{
"token": "路上",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 2
},
{
"token": "很",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 3
},
{
"token": "堵",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 4
}
]
}ik_smart
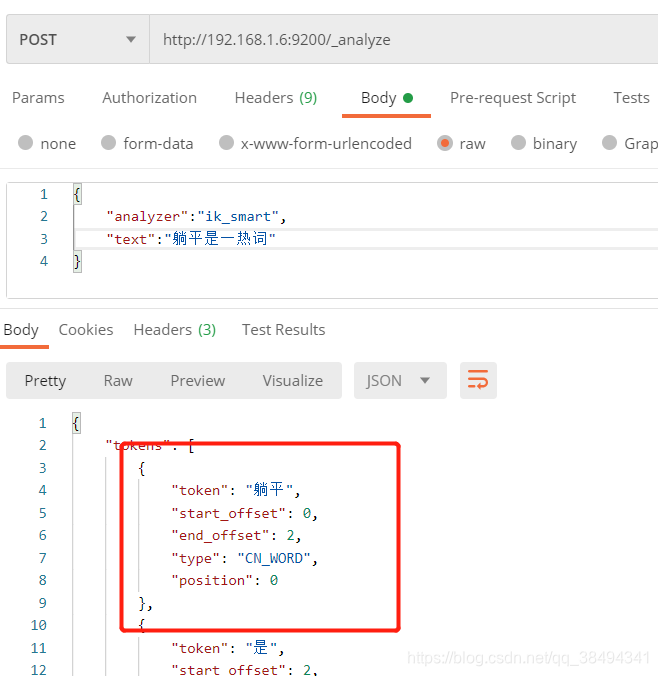
会做最粗粒度的拆分
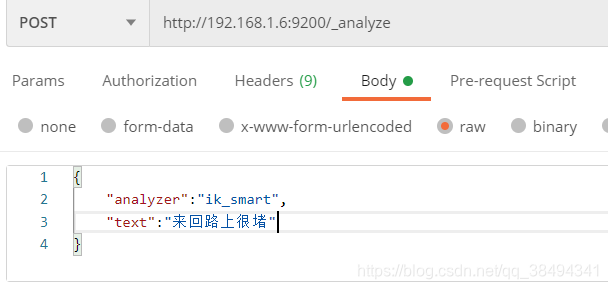
分词结果
{
"tokens": [
{
"token": "来回",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "路上",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "很",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 2
},
{
"token": "堵",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 3
}
]
}自定义中文词库
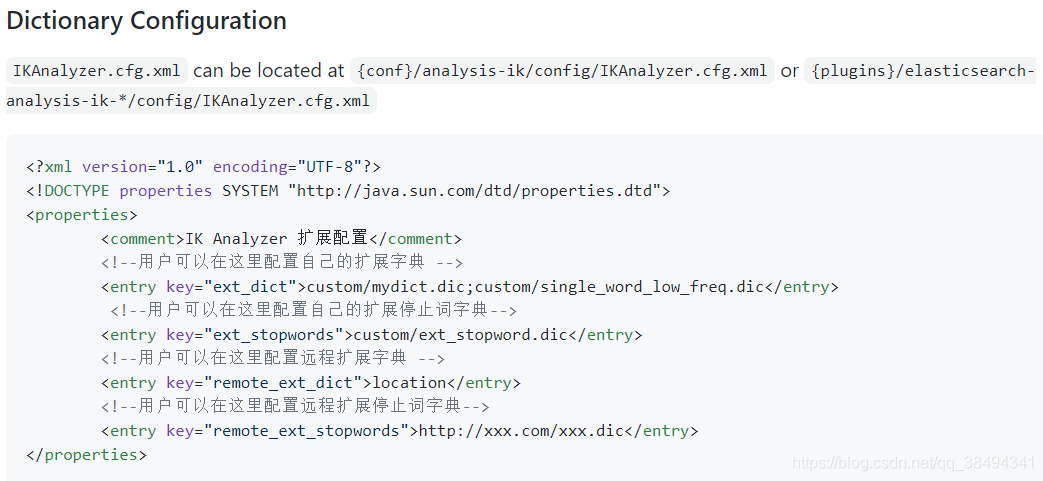
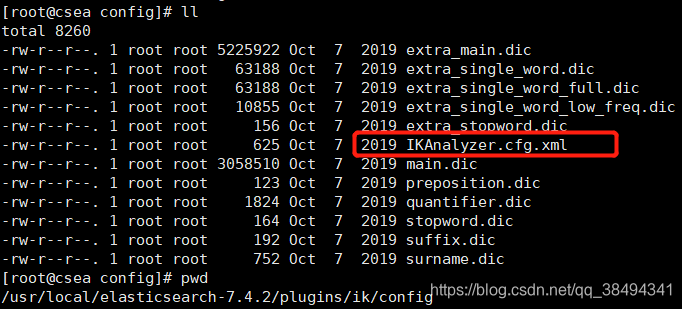
vim IKAnalyzer.cfg.xml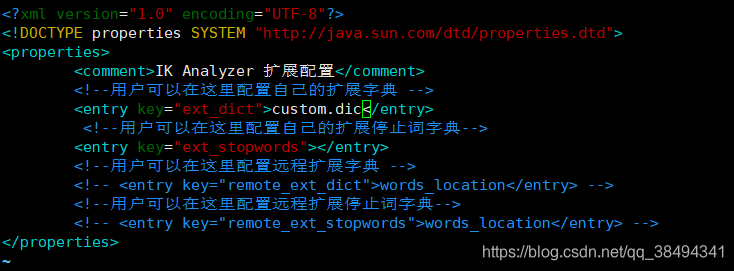
# 编辑自定义字典
vim custom.dic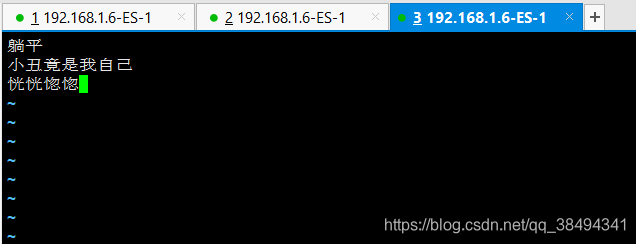
重启ES生效
再次请求分词可以发现,自定义的分词已经生效