
开放搜索智能问答实验室——Elasticsearch 知识问答上线了,诚邀您免费体验Elasticsearch学习应用过程中的对话式答疑。

OpenSearch LLM 智能问答版是阿里云推出的一站式RAG解决方案,内置大语言模型,可基于业务数据搭建企业专属模型,支持丰富数据格式的快速导入,构建包括对话、链接、图片在内的多模态搜索服务,帮助开发者一站式快速搭建RAG系统。

本问答知识库来自千万级博客阅读量的资深 Elastic技术专家铭毅天下的新书《一本书讲透Elasticsearch》,包含Elasticsearch 基础知识、关联技术、核心能力及实践,覆盖检索系统、大数据可视化系统、日志系统等业务场景,融合全球数百家企业的近 2000 名Elastic爱好者的实战经验,旨在帮助开发者深入了解Elasticsearch的核心技术和应用场景。

看一下效果
问题1:如何系统学习 Elasticsearch?

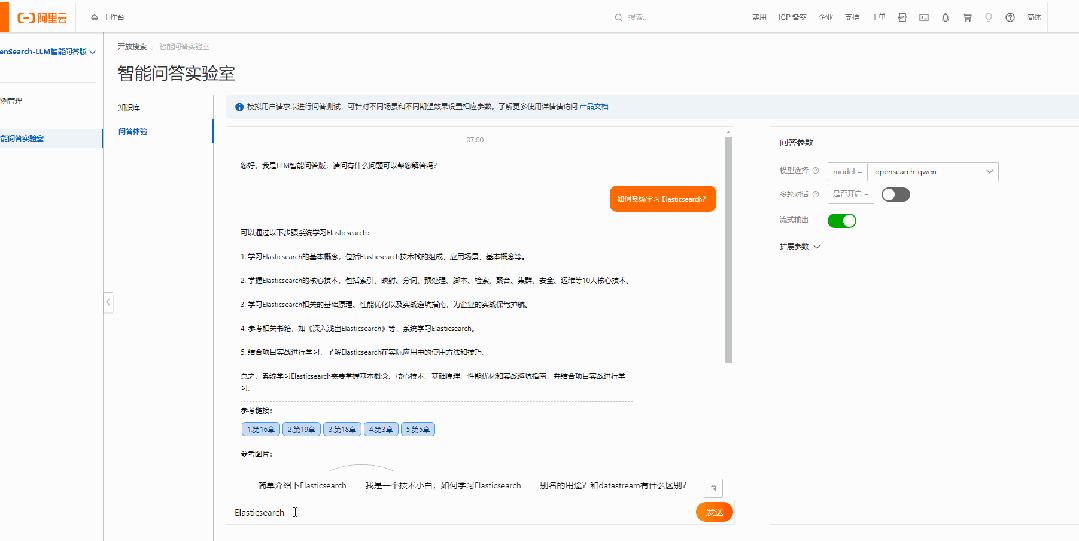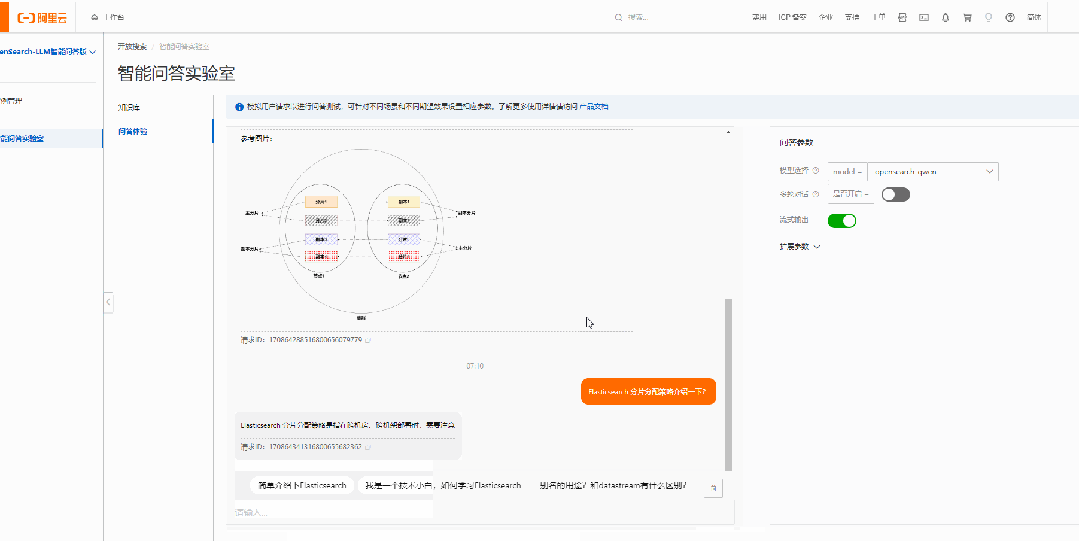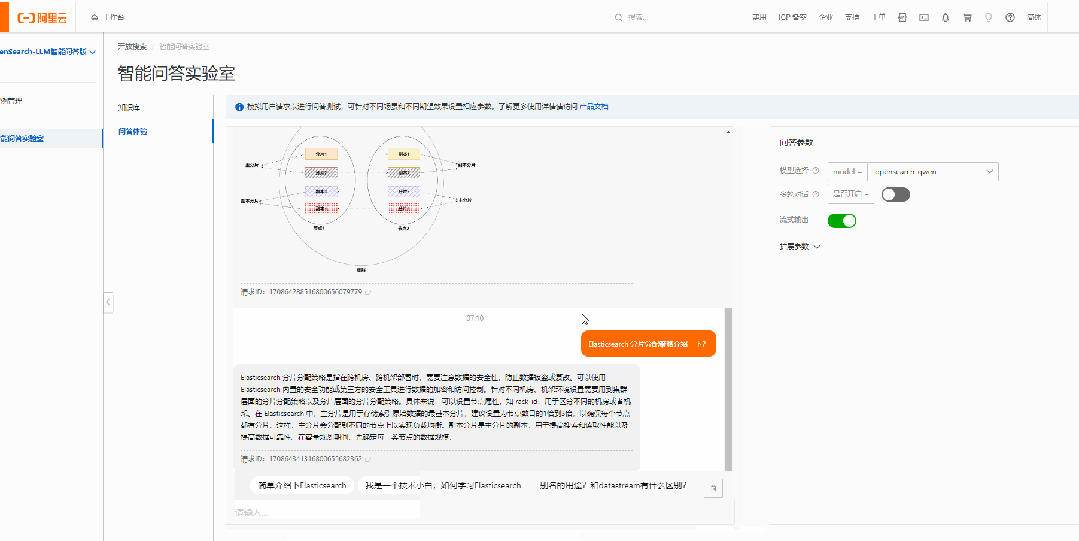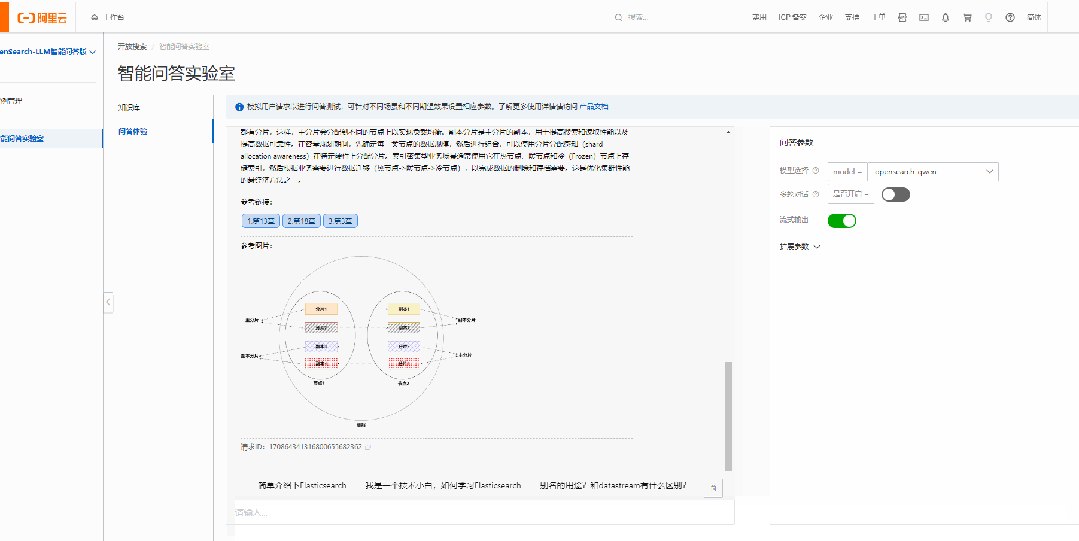
问题2:Elasticsearch分片分配策略?

问题3:Elasticsearch分片大小?
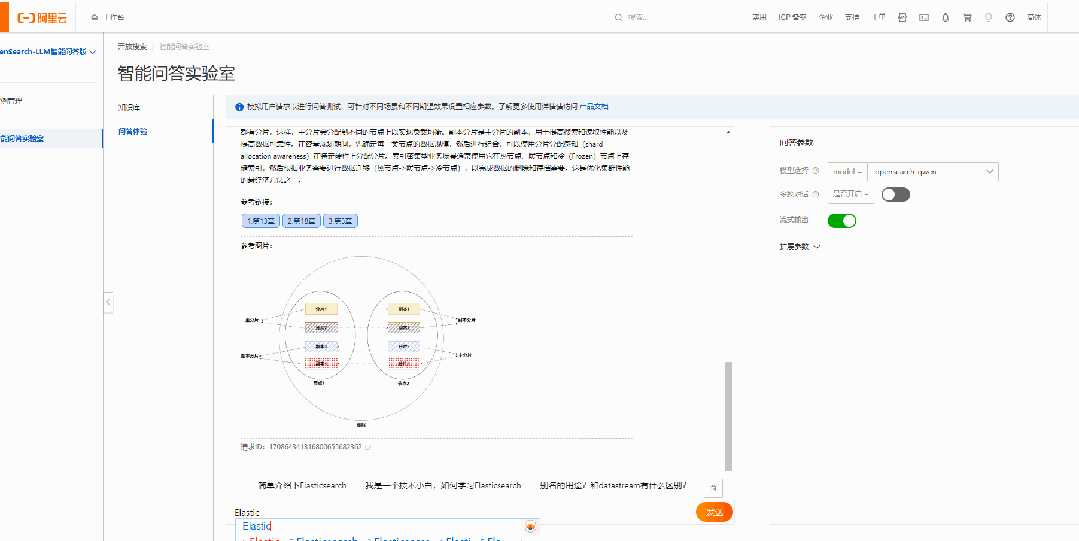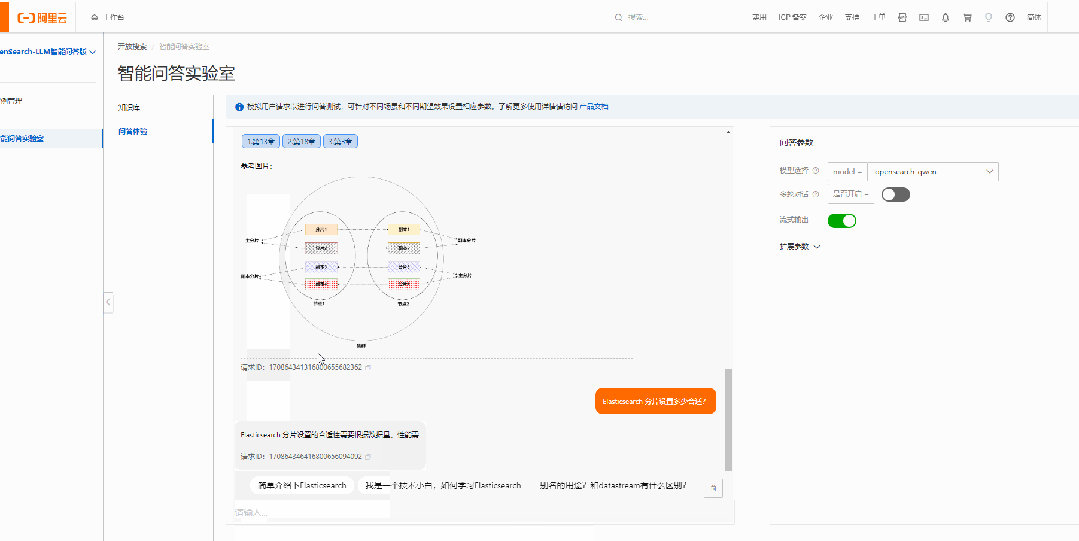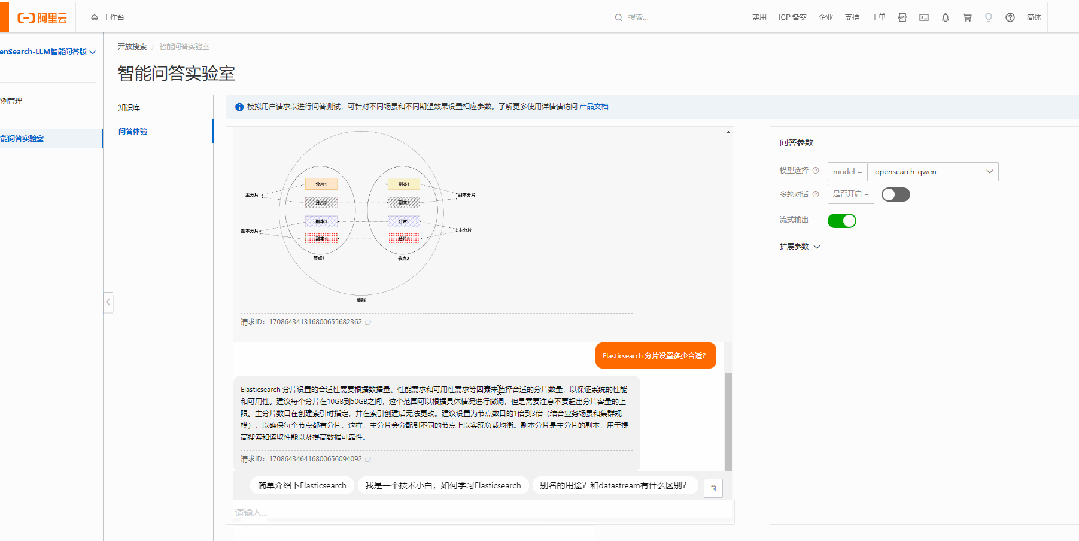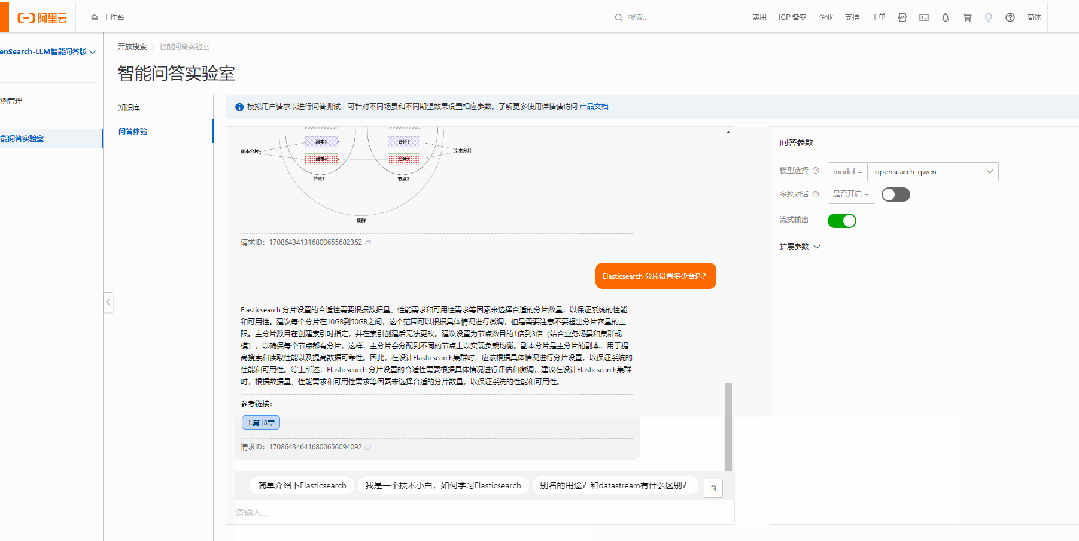
问题4:Elasticsearch 应用场景?

问题5:介绍一下索引声明周期管理?

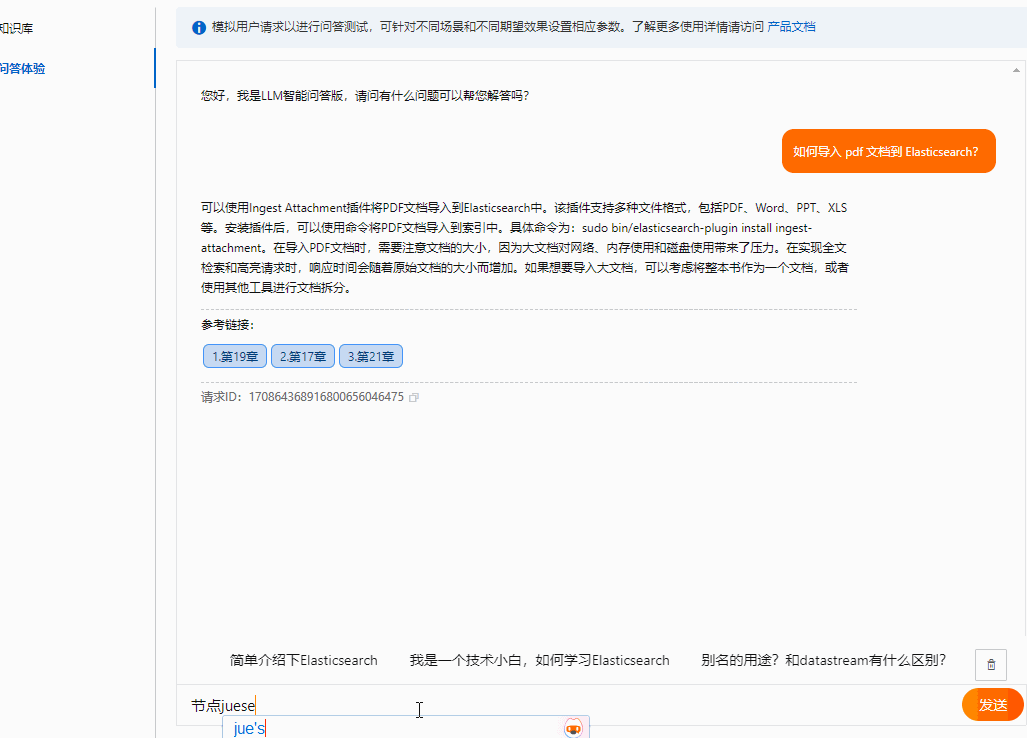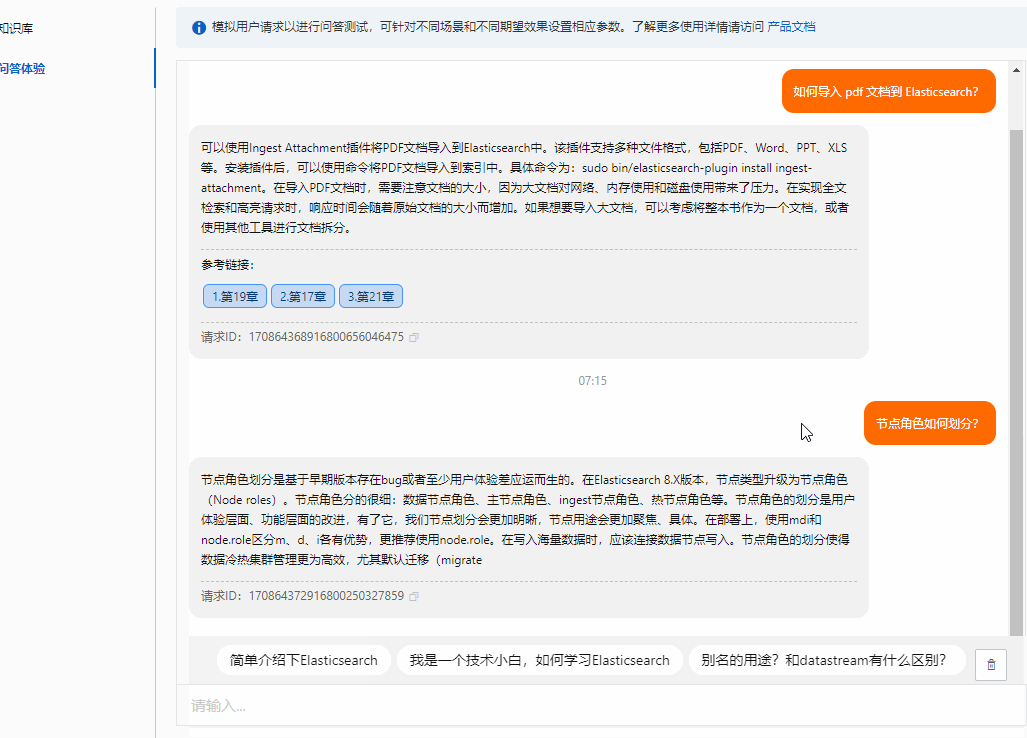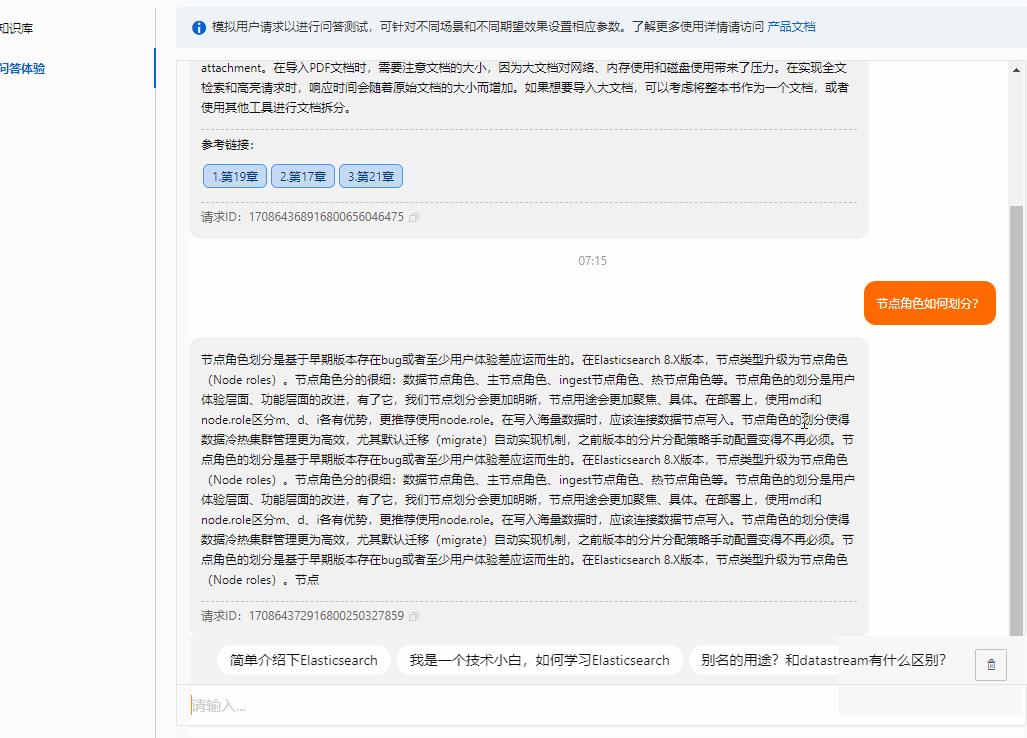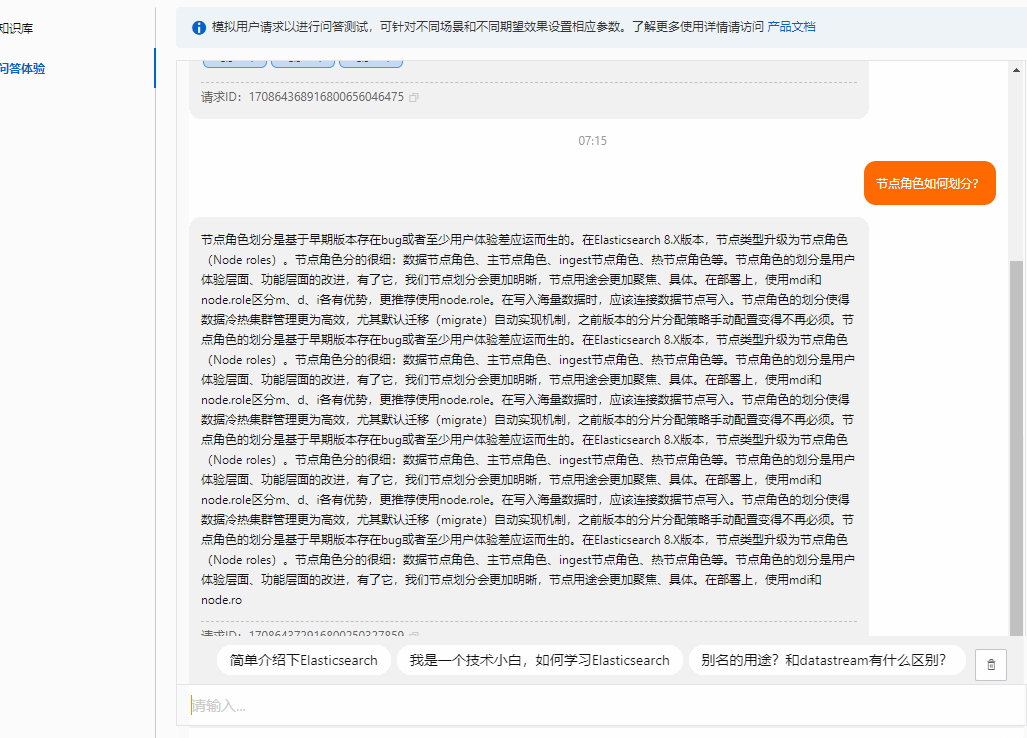
问题6:如何导入pdf 文档?
问题7:节点角色如何划分?

问题8:脚本使用注意事项?

咱们再通俗的解释一下“RAG”:
RAG(Retrieval-Augmented Generation)检索增强生成是一种自然语言处理技术,用于结合检索(Retrieval)和生成(Generation)能力来改进文本生成任务的性能。简单来说,RAG在生成文本之前,先从一个大型的文档数据库中检索出相关信息,然后将这些信息作为生成过程的一部分,以此来提高生成文本的相关性、准确性和多样性。

可以把RAG想象成一个两步过程的系统:
- 检索(Retrieval):
当系统收到一个问题或者提示时,它首先搜索一个预设的、包含大量文本的数据库,寻找与这个问题相关的信息。这一步骤类似于你在网上搜索信息时使用的搜索引擎,但是它是自动完成的。
- 生成(Generation):
找到相关信息后,系统使用这些信息来生成一个回答或者文本。这一步利用了先进的文本生成模型,如GPT系列,不仅仅基于检索到的信息,还结合了模型本身对语言的理解能力,来构建一个通顺、合适的回答。
RAG模型的一个关键优势是它结合了检索的高度相关性和生成模型的创造性,能够在许多任务上提供更加准确和详细的回答。例如,在问答系统、文章写作、内容创作等领域,RAG可以帮助生成更加丰富、准确的内容。RAG模型显著提高了文本生成任务的质量和准确性,有效避免了生成不准确或无关信息的问题。从而避免了“胡说八道”的情况。
Elasticsearch 知识问答地址:
https://opensearch.console.aliyun.com/cn-shanghai/openknowledge/lab/base
欢迎留言交流......




