作者 | 张鹏(七器),阿里巴巴开发工程师
本篇内容将向大家介绍如何将实时计算 Flink 与其他系统打通。介绍内容包含四个部分,分别是:
1、Jar的存储与使用;
2、实时计算 Flink 如何与一些典型数据源进行交互;
3、如何将VVP平台上 Flink的指标打入Metrics外部系统;
4、如何将VVP平台上运行的 Flink作业日志打入到外部系统。
一、运行作业的Jar如何存储在OSS上
在VVP平台有两种方法可以上传作业的jar。
方法一,借助VVP提供的资源上传功能,可以直接使用这个功能对Jar进行上传目前该功能支持200兆以内的Jar包上传。使用时,直接在创建作业的时候选择上传的jar包就可以了,演示如下:
● 进入到VVP平台,点击左侧资源上传功能,然后在打开页面点击右上角的上传资源,选择要上传的Jar包,完成上传;
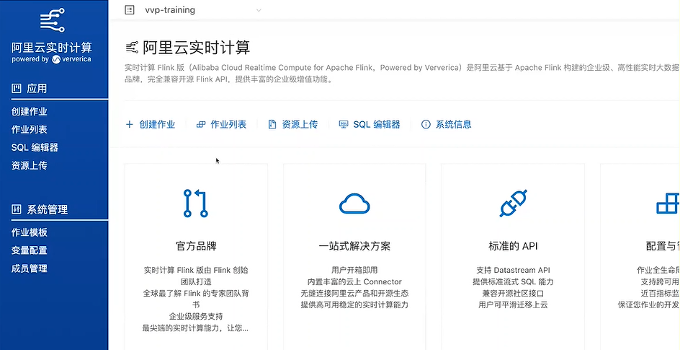
● 上传成功后,点击左侧创建作业,完善作业名等信息。在Jar URI栏,下拉选择刚刚上传的Jar包,点击确定完成创建作业,然后启动即可使用。
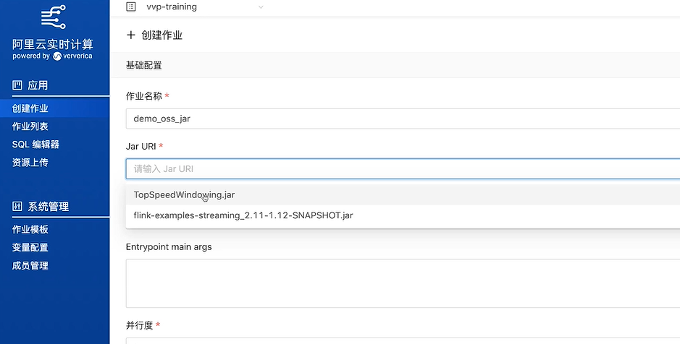
方法二,直接在OSS的控制台上面,将要使用的Jar上传上去,然后使用OSS是提供的Jar链接来行使用。使用的时候也比较简单,直接使用OSS提供的Jar链接,演示如下:
● 打开OSS控制台,选择在创建VVP时候使用的Bucket,再选择目录,点击上传文件,上传时可以将它的权限设置为公共读,点击上传文件即完成;
● 使用时,OSS控制台上点击已上传包右侧的“详情”,获取该Jar包的URL链接。
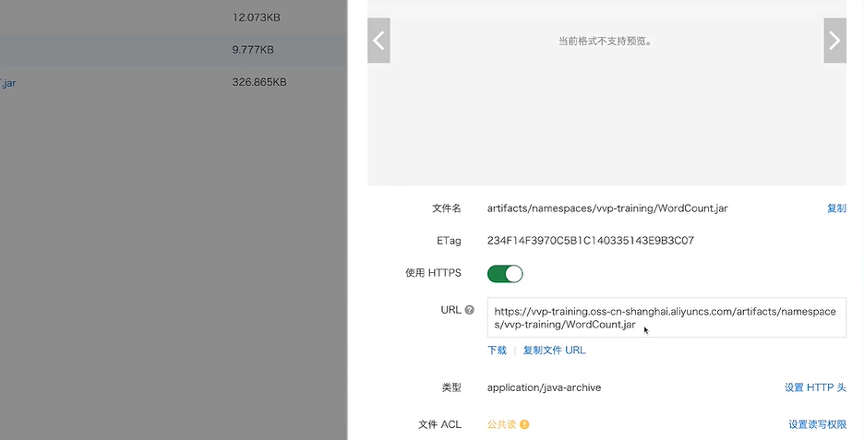
● 创建作业时,将jar包的URL的链接填入Jar URI,如下图所示:
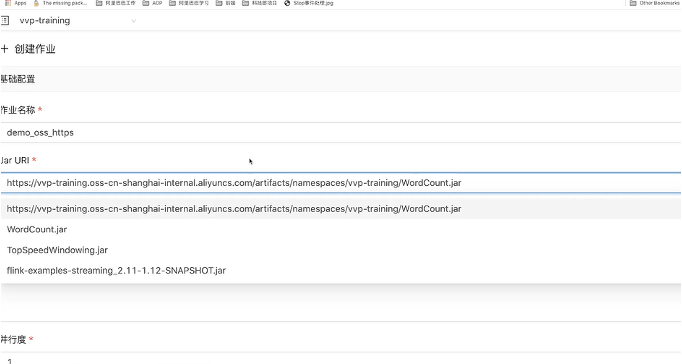
需要注意,OSS详情页面提供的链接是公网访问的,开通的VVP并不能直接访问公网,所以在创建作业使用HTTPS的时候,需要使用VPC访问的endpoint(例如:https://vvp-training.oss-cn-shanghai-internal.aliyuncs.com/artifacts/namespaces/vvp-training/WordCount.jar),这样才能正常的启动作业。
如果想用公网获取一个HTTPS的链接,怎么操作呢?可以首先对VVP进行公网打通,打通的操作流程可以参考阿里云帮助文档中的《Flink 全托管集群如何访问公网》(https://help.aliyun.com/document_detail/174840.html),简单来说步骤如下:
● 首先,创建一个NAT网关。创建时选择“组合购买ERP”,然后选择区域并补充名称等信息,然后绑定弹性公网IP,完成创建;
● 其次,创建SNAT条目。创建好NAT之后,点击“创建SNAT条目”,在弹窗选择交换机并补充名称信息,完成创建。
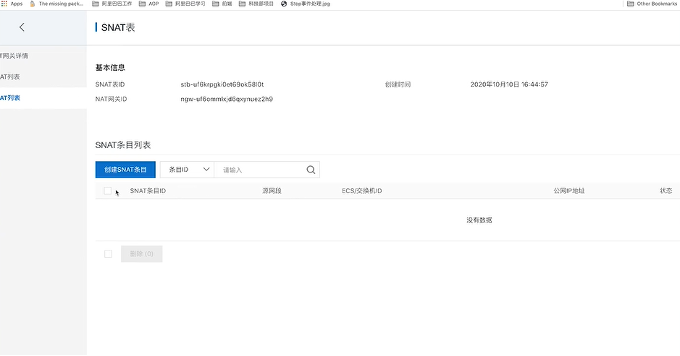
完成上述两个步骤,该VVP实例就已经打通公网,在创建Deployment时就可以直接使用https公网可访问的jar包了。
二、在VVP平台上 Flink 如何与典型数据源进行交互
这部介绍如何通过SQL以及connectors与外部的一些数据存储系统进行交互,以SLS,Kafka作为数据源读写数据为例。
(实操演示)点击SQL编辑器,创建一个Datagen Table,它是用于数据的随机生成的,然后点击运行。然后再点击生成一个SLS Table,补充所需参数信息,然后点击创建完成。
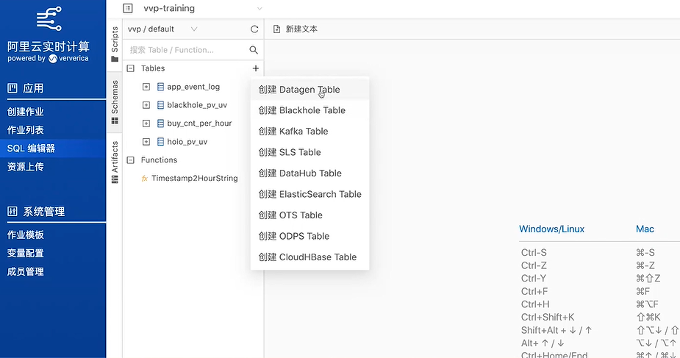
创建完成后,写入SQL语句,比如insert into sls select id, name from datagen,然后另存后点击运行,创建Deployment并启动。
当作业成功运行后,在SLS上查询数据。如下图所示,说明datagen已经生成数据并成功写入SLS。
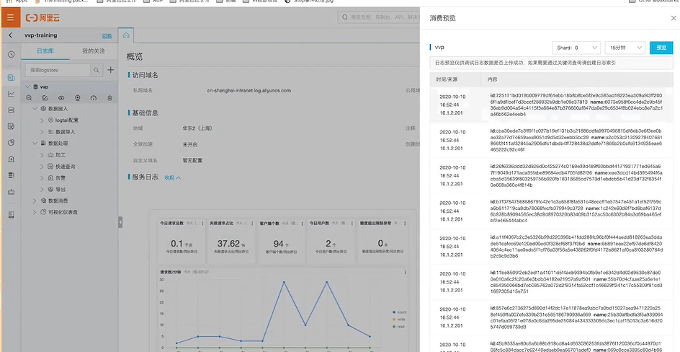
类似的,我们可以按照上面的步骤从SLS读数据然后写入Kafka:
● 在vvp的sql编辑器页面创建一个Kafka table
● 用SQL语法从SLS读取数据写入Kafka中并启动
● 作业运行成功后,即开始从SLS读数据写入Kafka中
三、如何将VVP平台上 Flink的指标打入外部Metrics系统
接下介绍如果想把运行作业的指标放入到一些系统当中去,并进行指标观测。VVP提供了两种方法:
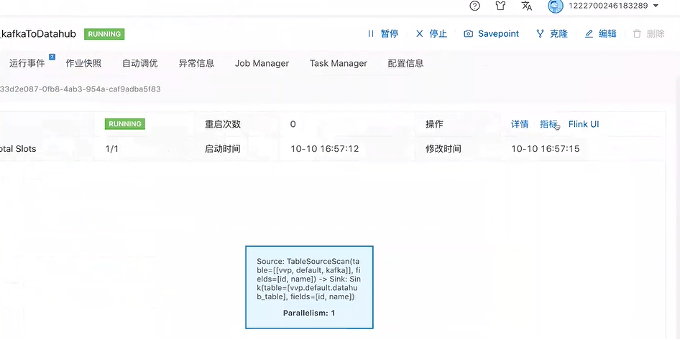
方法一,VVP默认的将 Flink 作业指标打入到arms,不需要额外的处理,直接运行作业之后,就能通过指标按钮看到,如下图所示:
方法二,如果自己有指标系统,想把 Flink 的作业指标打入到自己的系统里,主要有两点:首先保证VVP上作业与自己指标系统网络的连通性;其次在 Flink conf 中配置好相应的metrics reporter。如下图所示,在创建作业过程中,进行metric配置(metrics reporters配置参考:https://ci.apache.org/projects/flink/flink-docs-release-1.11/monitoring/metrics.html):
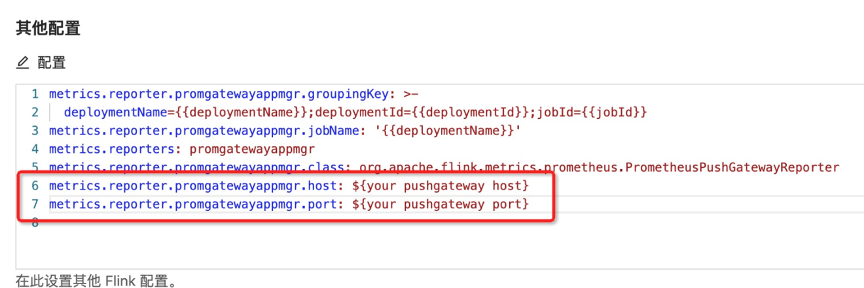
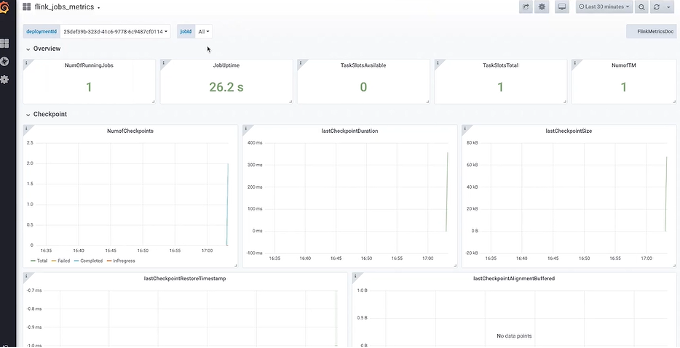
例:使用premetheus的pushGateway方式,所以reporter class就选择org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter。按上图所示配置pushGateway的port和host,Metric reporter就配置完成了。作业启动成功后在配置好的grafana大盘上查看指标,如下例所示。
四、如何将Flink作业日志打入到外部系统
如果在作业运行中,突然运行失败,我们想要查看运行失败作业的日志,就需要把 Flink 作业的日志保存下来。在VVP平台为这个目的提供了两种方案,将Logs写入OSS中或SLS中,简单来说,在创建作业的时候, 在Log配置项里面配置一些Log参数。

配置参考文档:https://help.aliyun.com/document_detail/173646.html
方法一,将日志写入OSS中。在创建作业的时候,在高级配置中的Log配置里,选择使用用户自定义,然后将(帮助文档)里面的配置放在自定义的配置中去,再将一些参数换成OSS的必要参数就可以了。
需要查看日志时,可以通过帮助文档的指导,找到日志存放的文件,然后点击下载查看。
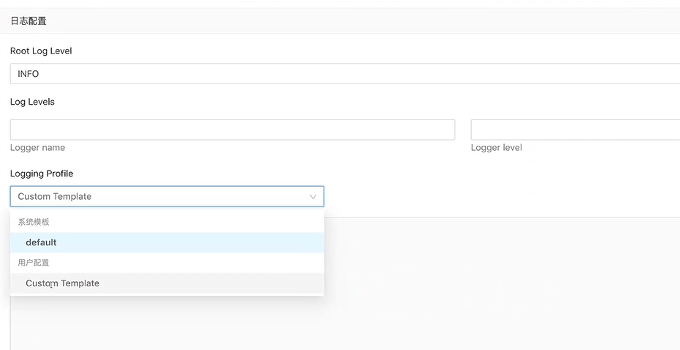

方法二,将日志写入SLS中。与方法一类似,只是LOG配置项稍有差异;下载和查看方法与方法一一致。
