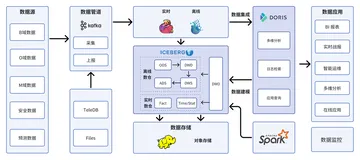
Apache Iceberg 是一种用于跟踪超大规模表的新格式,是专门为对象存储(如S3)而设计的。 本文将介绍为什么 Netflix 需要构建 Iceberg,Apache Iceberg 的高层次设计,并会介绍那些能够更好地解决查询性能问题的细节。
本文由 Ryan Blue 分享,他在 Netflix 从事开源数据项目,是 Apache Iceberg 的最初创建者之一,也是 Apache Spark, Parquet, 以及 Avro 贡献者。

Apache Iceberg 是由 Netflix 开发开源的,其于 2018年11月16日进入 Apache 孵化器,是 Netflix 公司数据仓库基础。在功能上和我们熟悉的 Delta Lake 或者 Apache Hudi 类似,但各有优缺点。
任何东西的诞生都是有其背后的原因,那么为什么 Netflix 需要开发 Apache Iceberg?

在 Netflix,他们希望有更智能的处理引擎,比如有 CBO 优化,更好的 Join 实现,缓存结果集以及物化视图等功能。同时,他们也希望减少人工维护数据。
Netflix 面临的问题包括:1、不安全的操作随处可见;2、和对象存储交互有时候会出现很大的问题;3、无休止的可扩展性挑战。
为了解决这些问题,Iceberg 诞生了。那么 Iceberg 是什么?

iceberg 是一种可伸缩的表存储格式,内置了许多最佳实践。

什么?是一种存储格式?可使我们已经有 Parquet,Avro 以及 ORC 这些格式了,为什么还要设计一种新格式?


iceberg 允许我们在一个文件里面修改或者过滤数据;当然多个文件也支持这些操作。为了展示这点,我们来看看一张 Hive 表。

Hive 表的核心思想是把数据组织成目录树,如上所述。

如果我们需要过滤数据,可以在 where 里面添加分区相关的信息。

带来的问题是如果一张表有很多分区,我们需要使用 HMS(Hive MetaStore)来记录这些分区,同时底层的文件系统(比如 HDFS)仍然需要在每个分区里面记录这些分区数据。

这就导致我们需要在 HMS 和 文件系统里面同时保存一些状态信息;因为缺乏锁机制,所以对上面两个系统进行修改也不能保证原子性。

当然 Hive 这样维护表也不是没有好处。这种设计使得很多引擎(Hive、Spark、Presto、Flink、Pig)都支持读写 Hive 表,同时支持很多第三方工具。简单和透明使得 Hive 表变得不可或缺的。


Iceberg 的目标包括:1、成为静态数据交换的开放规范,维护一个清晰的格式规范,支持多语言,支持跨项目的需求等。

2、提升扩展性和可靠性。能够在一个节点上运行,也能在集群上运行。所有的修改都是原子性的,串行化隔离。原生支持云对象存储,支持多并发写。

3、修复持续的可用性问题,比如模式演进,分区隐藏,支持时间旅行、回滚等。

Iceberg 主要设计思想:记录表在所有时间的所有文件,和 Delta Lake 或 Apache Hudi 一样,支持 snapshot,其是表在某个时刻的完整文件列表。每一次写操作都会生成一个新的快照。

读取数据的时候使用当前的快照,Iceberg 使用乐观锁机制来创建新的快照,然后提交。

Iceberg 这么设计的好处是:
- 所有的修改都是原子性的;
- 没有耗时的文件系统操作;
- 快照是索引好的,以便加速读取;
- CBO metrics 信息是可靠的;
- 更新支持版本,支持物化视图。


Iceberg 在 Netflix 生产环境维护着数十 PB 的数据,数百万个分区。对大表进行查询能够提供低延迟的响应。

生产环境中使用 Flink 管道在 3 个 AWS regions 写数据。Lift 服务将数据移到一个 region。Merge 服务对小文件进行合并。

可用性方面:回滚是家常便饭。

未来工作:1、支持 Spark 向量化以便实现快速的 bulk read,Presto 向量化已经支持。2、行级别的删除,支持 MERGE INTO 等。
推荐相关阅读:
[Data Lake 三剑客——Delta、Hudi、Iceberg 对比分析
](https://developer.aliyun.com/article/744920?spm=a2c6h.12873581.0.dArticle744920.592a3a183ThfM2&groupCode=apachespark)
本文转载自公众号:过往记忆大数据
原文链接:https://mp.weixin.qq.com/s/acWcoZ25zDXetA3ewypG2g
阿里巴巴开源大数据技术团队成立Apache Spark中国技术社区,定期推送精彩案例,技术专家直播,问答区近万人Spark技术同学在线提问答疑,只为营造纯粹的Spark氛围,欢迎钉钉扫码加入!
对开源大数据和感兴趣的同学可以加小编微信(下图二维码,备注“进群”)进入技术交流微信群。