❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🚀 "高效MoE通信新突破!DeepEP:DeepSeek开源专家并行库,低至163微秒推理解码延迟"
大家好,我是蚝油菜花。你是否也遇到过——
- 👉 大规模模型训练时,节点间通信成为瓶颈?
- 👉 推理任务中延迟过高,影响用户体验?
- 👉 传统通信库无法充分利用 NVLink 和 RDMA 硬件优势?
今天揭秘的 DeepEP 是 DeepSeek 开源的首个专为混合专家模型(MoE)设计的专家并行(EP)通信库。它通过高吞吐量、低延迟的全对全 GPU 内核,显著提升训练和推理效率,并针对 Hopper 架构进行了深度优化。无论是大规模模型训练还是延迟敏感的推理解码场景,DeepEP 都能带来卓越表现。
🚀 快速阅读
DeepEP 是 DeepSeek 开源的高效专家并行通信库。
- 核心功能:提供高吞吐量和低延迟的全对全 GPU 内核,支持 FP8 和 BF16 数据格式调度。
- 技术原理:基于 Hook 的通信-计算重叠方法,不占用 GPU 计算资源,优化 NVLink 和 RDMA 通信性能。
DeepEP 是什么

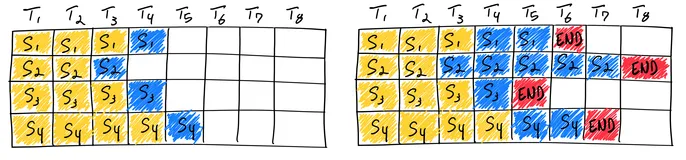
DeepEP 是 DeepSeek 开源的首个专为混合专家模型(MoE)训练和推理设计的专家并行(EP)通信库。它提供了高吞吐量和低延迟的全对全 GPU 内核,适用于分发(dispatch)和合并(combine)操作。DeepEP 特别针对 DeepSeek-V3 论文中的组限制门控算法进行了优化,支持 FP8 数据格式调度,并引入了基于 Hook 的通信-计算重叠方法,不占用 GPU 的流多处理器(SM)资源。
DeepEP 支持 NVLink 和 RDMA 通信,适用于 Hopper GPU 架构,能够显著降低推理解码阶段的延迟,最低可达 163 微秒。此外,它还支持灵活的 GPU 资源管理,允许用户控制 SM 的使用数量,以适应不同的工作负载需求。
DeepEP 的主要功能
- 高效通信内核:提供高吞吐量和低延迟的全对全 GPU 内核,适用于 MoE 的分发和合并操作。
- 低精度计算支持:支持 FP8 和 BF16 数据格式,显著提升计算效率并降低内存需求。
- 优化的通信机制:针对组限制门控算法优化,支持从 NVLink 到 RDMA 的非对称带宽转发,适用于训练和推理预填充任务。
- 低延迟推理解码:提供纯 RDMA 的低延迟内核,特别适合对延迟敏感的推理解码场景,延迟低至 163 微秒。
- 通信与计算重叠:引入基于 Hook 的通信-计算重叠方法,不占用 GPU 的流多处理器(SM)资源,最大化计算效率。
- 灵活的资源管理:支持灵活的 GPU 资源管理,允许用户控制 SM 的使用数量,适应不同的工作负载。
- 网络配置优化:支持通过虚拟通道(VL)实现流量隔离,防止不同类型流量之间的干扰。
DeepEP 的技术原理
- 高性能通信内核:通过 NVLink 和 RDMA 提供高吞吐量和低延迟的全对全通信,适用于 MoE 分发和合并操作。
- 低精度数据支持:支持 FP8 和 BF16 数据格式,减少内存占用并提升计算效率。
- 通信-计算重叠:基于 Hook 的方法实现通信与计算的重叠,避免占用 GPU 的流多处理器(SM)资源。
- RDMA 技术优化:利用纯 RDMA 技术实现低延迟推理解码,显著降低延迟。
- 流量隔离与自适应路由:通过虚拟通道(VL)实现流量隔离,支持自适应路由以优化网络负载。
如何运行 DeepEP
性能概览
DeepEP 的性能分为两类内核:普通内核和低延迟内核。
1. 普通内核(支持 NVLink 和 RDMA 转发)
普通内核在 H800 GPU 上测试,最大 NVLink 带宽为 160 GB/s,连接 CX7 InfiniBand 400 Gb/s RDMA 网络卡(最大带宽 50 GB/s)。测试场景遵循 DeepSeek-V3/R1 的预训练设置。
2. 低延迟内核(纯 RDMA)
低延迟内核同样在 H800 GPU 上测试,适用于 DeepSeek-V3/R1 的生产环境设置。
快速启动
1. 配置要求
- Hopper 架构的 GPU(未来可能支持更多架构或设备)
- Python 3.8 及以上版本
- CUDA 12.3 及以上版本
- PyTorch 2.1 及以上版本
- NVLink 用于节点内通信
- RDMA 网络用于节点间通信
2. 下载并安装 NVSHMEM 依赖
DeepEP 依赖于修改版的 NVSHMEM,请参考 NVSHMEM 安装指南 进行安装。
3. 开发环境设置
# 构建并创建 SO 文件的符号链接
NVSHMEM_DIR=/path/to/installed/nvshmem python setup.py build
# 根据你的平台修改特定的 SO 文件名
ln -s build/lib.linux-x86_64-cpython-38/deep_ep_cpp.cpython-38-x86_64-linux-gnu.so
# 运行测试用例
# 注意:根据你的集群设置修改 `tests/utils.py` 中的 `init_dist` 函数
python tests/test_intranode.py
python tests/test_internode.py
python tests/test_low_latency.py
4. 安装和使用
NVSHMEM_DIR=/path/to/installed/nvshmem python setup.py install
安装完成后,在你的 Python 项目中导入 deep_ep,即可开始使用。
网络配置
DeepEP 完全支持 InfiniBand 网络,并理论上兼容 RDMA over Converged Ethernet (RoCE)。
1. 流量隔离
InfiniBand 通过虚拟通道(Virtual Lanes, VL)支持流量隔离。建议将不同类型的工作负载分配到不同的虚拟通道中,例如:
- 使用普通内核的工作负载
- 使用低延迟内核的工作负载
- 其他工作负载
通过设置 NVSHMEM_IB_SL 环境变量,可以控制虚拟通道的分配。
2. 自适应路由
自适应路由是 InfiniBand 提供的一项高级路由功能,能够均匀分配流量到多个路径。目前,低延迟内核支持自适应路由,而普通内核不支持(未来可能会添加支持)。
建议在高网络负载环境下启用自适应路由,而在低负载环境下使用静态路由以获得最佳性能。
3. 拥塞控制
拥塞控制功能被禁用,因为生产环境中未观察到显著的拥塞问题。
示例代码
1. 模型训练或推理预填充的使用示例
普通内核适用于模型训练或推理预填充阶段。以下代码展示了如何使用这些内核。
import torch
import torch.distributed as dist
from typing import List, Tuple, Optional, Union
from deep_ep import Buffer, EventOverlap
# 通信缓冲区(运行时分配)
_buffer: Optional[Buffer] = None
# 设置使用的 SM 数量
Buffer.set_num_sms(24)
def get_buffer(group: dist.ProcessGroup, hidden_bytes: int) -> Buffer:
global _buffer
num_nvl_bytes, num_rdma_bytes = 0, 0
for config in (Buffer.get_dispatch_config(group.size()), Buffer.get_combine_config(group.size())):
num_nvl_bytes = max(config.get_nvl_buffer_size_hint(hidden_bytes, group.size()), num_nvl_bytes)
num_rdma_bytes = max(config.get_rdma_buffer_size_hint(hidden_bytes, group.size()), num_rdma_bytes)
if _buffer is None or _buffer.group != group or _buffer.num_nvl_bytes < num_nvl_bytes or _buffer.num_rdma_bytes < num_rdma_bytes:
_buffer = Buffer(group, num_nvl_bytes, num_rdma_bytes)
return _buffer
def dispatch_forward(x: Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]],
topk_idx: torch.Tensor, topk_weights: torch.Tensor,
num_experts: int, previous_event: Optional[EventOverlap] = None) -> \
Tuple[Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]], torch.Tensor, torch.Tensor, List, Tuple, EventOverlap]:
global _buffer
num_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, previous_event = \
_buffer.get_dispatch_layout(topk_idx, num_experts, previous_event=previous_event, async_finish=True)
recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event = \
_buffer.dispatch(x, topk_idx=topk_idx, topk_weights=topk_weights,
num_tokens_per_rank=num_tokens_per_rank, num_tokens_per_rdma_rank=num_tokens_per_rdma_rank,
is_token_in_rank=is_token_in_rank, num_tokens_per_expert=num_tokens_per_expert,
previous_event=previous_event, async_finish=True)
return recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event
def combine_forward(x: torch.Tensor, handle: Tuple, previous_event: Optional[EventOverlap] = None) -> \
Tuple[torch.Tensor, EventOverlap]:
global _buffer
combined_x, _, event = _buffer.combine(x, handle, async_finish=True, previous_event=previous_event)
return combined_x, event
2. 推理解码的使用示例
低延迟内核适用于推理解码阶段。以下代码展示了如何使用这些内核。
import torch
import torch.distributed as dist
from typing import Tuple, Optional
from deep_ep import Buffer
_buffer: Optional[Buffer] = None
def get_buffer(group: dist.ProcessGroup, num_max_dispatch_tokens_per_rank: int, hidden: int, num_experts: int) -> Buffer:
global _buffer
num_rdma_bytes = Buffer.get_low_latency_rdma_size_hint(num_max_dispatch_tokens_per_rank, hidden, group.size(), num_experts)
if _buffer is None or _buffer.group != group or not _buffer.low_latency_mode or _buffer.num_rdma_bytes < num_rdma_bytes:
assert num_experts % group.size() == 0
_buffer = Buffer(group, 0, num_rdma_bytes, low_latency_mode=True, num_qps_per_rank=num_experts // group.size())
return _buffer
def low_latency_dispatch(hidden_states: torch.Tensor, topk_idx: torch.Tensor, num_max_dispatch_tokens_per_rank: int, num_experts: int):
global _buffer
recv_hidden_states, recv_expert_count, handle, event, hook = \
_buffer.low_latency_dispatch(hidden_states, topk_idx, num_max_dispatch_tokens_per_rank, num_experts,
async_finish=False, return_recv_hook=True)
return recv_hidden_states, recv_expert_count, handle, event, hook
注意事项
- 为了极致性能,DeepEP 使用了超出文档描述的 PTX 指令
ld.global.nc.L1::no_allocate.L2::256B,这可能导致未定义行为,但已在 Hopper 架构上验证其正确性。 - 为了在你的集群上获得最佳性能,建议运行所有测试并使用自动调优的最佳配置。
资源
- GitHub 仓库:https://github.com/deepseek-ai/DeepEP
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦