近年来,人工智能领域的快速发展推动了大型语言模型的广泛应用,随之而来的是对其服务效率的迫切需求。论文《NanoFlow:Towards Optimal Large Language Model Serving Throughput》提出了一种突破性的新型服务框架,旨在提高大语言模型在实际应用中的服务吞吐量。这一研究不仅为优化计算资源的利用提供了新思路,也为我们团队在实际应用中面对的挑战提供了宝贵的借鉴。阿里云 PAI 团队开发了 BladeLLM ,旨在为用户提供高性能、高稳定、企业级的大模型推理能力。在日常工作中,我们经常需要处理大量的实时请求,确保用户体验的同时,降低系统的计算成本。正因如此,NanoFlow 中提出的一系列优化策略与我们目前的研究方向紧密相关,为我们探索更高效的模型服务方案提供了启示。本文将深入探讨 NanoFlow 的关键思路和核心技术,分析 NanoFlow 与 阿里云人工智能平台 PAI 在实际工作中应用的潜力。
NanoFlow 简介
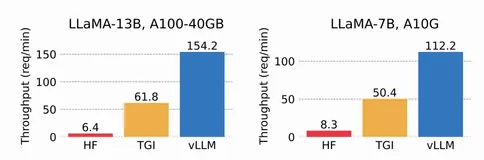
在 CPU 中, 当我们只调度一个执行流给 CPU 时, 如果 CPU 在执行某些指令时遇到了阻塞, 比如在执行 IO 指令时, 此时整个 CPU 将处于闲置状态, 其会等待 IO 指令执行完成才开始处理下一条指令,造成了浪费。为此 CPU 引入了超线程技术, 允许应用将两个执行流调度到一个 CPU 上, 这样当 CPU 执行一条执行流阻塞时会切换执行下一个执行流。与此同时乱序执行, 多流水线等各种技术都引入进来, 使得即使只调度了一个执行流给 CPU, CPU 也会想尽办法在执行指令 x 阻塞时调度其他不依赖 x 的指令执行。GPU 也面临着同样的问题, SM 在硬件层面调度多个 warp 并发执行,而 NanoFlow 就是尝试在软件层面解决这些问题。在 NanoFlow 之前,业界通过数据、张量和流水线等设备间并行方法来提升吞吐量,但这些方法均未能充分利用到单个设备内的资源。NanoFlow 提出了一个新型服务框架,利用设备内部的并行性,通过 NanoBatch 将请求分解,打破了推理中的顺序依赖,实现资源重叠使用。其主要技术创新包括基于操作的流水线和调度,将设备功能单元进行分区,实现不同操作的同时执行。评估结果显示,NanoFlow 在实验环境下,相较于最先进的服务系统提供了1.91倍的吞吐量提升,实现了59%至72%的最优吞吐量,具有良好的跨模型移植性。
具体技术实现
GPU 实现
NanoFlow 对于传统推理框架仅调度一条执行流到 GPU 导致单个 GPU 内资源未能充分利用的解决思路也很直观, 就像 CPU 超线程一样, 我们一次调度多个执行流给 GPU, 多个执行流中 operation 互相之间没有依赖关系, 可以最大程度地实现资源重叠使用。当然也不能无脑调度多个执行流, 就像 CPU 超线程中经常会遇到由于资源争抢, 导致调度到同一 CPU 的两个执行流执行速度都会变慢。为此 NanoFlow 针对 LLM 为单个 GPU 精心设计了一条执行流:


在完成如上流水线设计之后, 接下来一个问题就是对于一个给定的模型, 如何确定流水线中每个操作输入 NanoBatch 的大小,以及每个操作占用多少资源。毕竟稍有不慎,就会像 CPU 超线程那样造成了资源争抢两败俱伤。NanoFlow 这里解法是结合 offline profiling 以及贪心搜索来为每一个特定模型确定最优参数组合。
CPU 实现
即使是在 CPU 任务处理上,NanoFlow 也会尽最大努力不让 GPU 处于空闲状态。这主要体现在:
- async scheduler,NanoFlow 会在 iteration 在 GPU 执行期间,在 CPU 上运行调度逻辑确认组装下一个 iteration 的 batch, 以及分配对应的 kvcache 空间等准备工作。在 iteration 结束之后, NanoFlow 会根据这里组装好的 batch 立即发起下一个 iteration。在下一个 iteration 在 GPU 执行期间, NanoFlow 才会检测上一个 iteration 已经结束的请求。
- async kvcache offload,NanoFlow 支持 prompt cache,会在请求结束时将请求 kvcache 卸载保存到 SSD 上, 并采用 LRU 策略管理。考虑到将 kvcache offload ssd 对于 GPU 来说是个 memory bound 操作, NanoFlow 会在下一次迭代 UGD 期间调度 offload 任务, 来尽可能 overlap。为了提升 offload 吞吐, 在 offload 时, NanoFlow 会先将分布在各地的 kvcache page 聚合到一段连续空间中, 之后将这段连续空间中的内容卸载到 SSD, 在从 SSD 中加载 kvcache 到 GPU 中时也具有类似的过程。
NanoFlow 与 PAI 的结合
在《TAG:BladeLLM 的纯异步推理架构》中,我们介绍了 BladeLLM 的纯异步推理架构——TAG(Totally Asynchronous Generator)。TAG 架构下的各个模块全异步执行、互不阻塞,但模型前向过程仍然是一个不可分割的原子过程。NanoFlow 在 GPU 设备内部引入多级流水,则打开了更多的异步执行空间。后续,我们将进一步复现和评估 NanoFlow 的工作,结合 TAG 和 NanoFlow,探索全异步架构下的优化空间。
-----------------------------
招聘
阿里云人工智能平台 PAI 长期开放推理优化方向的研究型实习生、校招和社招岗位。团队致力于从模型和系统两方面对大语言模型推理进行协同优化,工作内容覆盖模型压缩、高性能算子、推理框架和运行时、分布式等工作。
欢迎投递简历:xiafei.qiuxf@alibaba-inc.com
论文信息
论文名称:NanoFlow:Towards Optimal Large Language Model Serving Throughput
论文pdf链接:https://arxiv.org/pdf/2408.12757