
在本文中,188个国家基于这19个社会经济指标聚集在一起,使用Python实现的蒙特卡罗K-Means聚类算法。通过将类似国家分组在一起并对其进行概括,聚类可以帮助减少识别有吸引力的投资机会所需的工作量。
在讨论聚类国家和得出结论的结果之前,本文详细介绍了距离度量,聚类质量测量,聚类算法,K-Means聚类算法。
聚类理论 - 相似与距离的度量
聚类是将一组异构(不同)对象划分为同类(相似)对象的子集的过程。聚类分析的核心是假设给定任何两个对象,您可以量化这些对象之间的相似性或不相似性。在连续搜索空间中距离测量相似性。
下面我写了关于连续搜索空间的相似性度量。对于每个我都包含公式(给定两个向量, 和q)和Python代码。用于编写本文的所有Python代码都可用。
class Similarity: def __init__(self, minimum): self.e = minimum self.vector_operators = VectorOperations() def manhattan_distance(self, p_vec, q_vec): """ This method implements the manhattan distance metric :param p_vec: vector one :param q_vec: vector two :return: the manhattan distance between vector one and two """ return max(np.sum(np.fabs(p_vec - q_vec)), self.e) def square_euclidean_distance(self, p_vec, q_vec): """ This method implements the squared euclidean distance metric :param p_vec: vector one :param q_vec: vector two :return: the squared euclidean distance between vector one and two """ diff = p_vec - q_vec return max(np.sum(diff ** 2), self.e)
聚类理论 - 聚类算法类
聚类算法的两个主要类别是分层聚类和分区聚类。分层聚类通过将小聚类合并为较大的聚类或将较大的聚类分成较小的聚类来形成聚类。分区聚类通过将输入数据集划分为互斥的子集来形成聚类。
分层和分区聚类之间的差异主要与所需的输入有关。分层聚类仅需要相似性度量,而分区聚类可能需要许多额外的输入,最常见的是簇的数量。一般而言,分层聚类算法也更适合于分类数据。ķķ
分层聚类
有两种类型的层次聚类,即凝聚聚类和分裂聚类。凝聚聚类是一种自下而上的方法,涉及将较小的聚类(每个输入模式本身)合并为更大的聚类。分裂聚类是一种自上而下的方法,从一个大型集群(所有输入模式)开始,并将它们分成越来越小的集群,直到每个输入模式本身都在集群中。
分区聚类
在本文中,我们将重点介绍分区聚类算法。分区聚类算法的两个主要类别是 基于质心的聚类 和 基于密度的聚类。本文重点介绍基于质心的聚类; 特别是流行的K-means聚类算法。
聚类理论 - K-Means聚类算法
K-Means聚类算法是一种基于质心的分区聚类算法,它使用均值漂移启发式算法。K均值聚类算法包括三个步骤(初始化,分配和更新)。重复这些步骤,直到聚类已经收敛或已经超过迭代次数,即计算预算已用尽。
初始化
在搜索空间中随机初始化一组质心。这些质心必须与聚类的数据模式处于同一数量级。换句话说,如果数据模式中的值介于0到100之间,则初始化值介于0和1之间的随机向量是没有意义的。

注意:确保跨每个属性规范化数据,而不是每个模式
分配
一旦质心在空间中被随机初始化,我们迭代数据集中的每个模式并将其分配给最近的质心。尝试并行执行此步骤,尤其是在数据集中有大量模式的情况下。

更新
一旦将模式分配给它们的质心,就应用均值漂移启发式。此启发式替换每个质心中的每个值,并将该值的平均值替换为已分配给该质心的模式。这将质心移向属于它的图案的高维平均值。均值漂移启发式问题在于它对异常值敏感。为了克服这个问题,可以使用K-medoids聚类算法 ,也可以使用 标准化数据来抑制异常值的影响,

迭代
重复这三个步骤进行多次迭代,直到聚类已经收敛于解决方案。一个非常好的GIF显示如下所示,
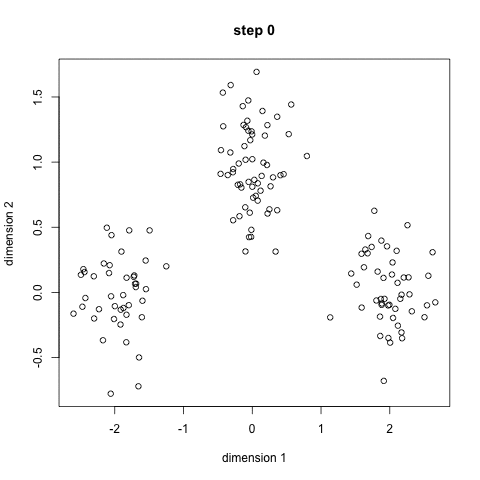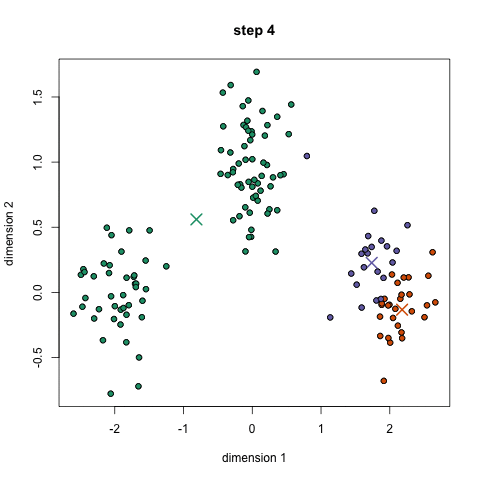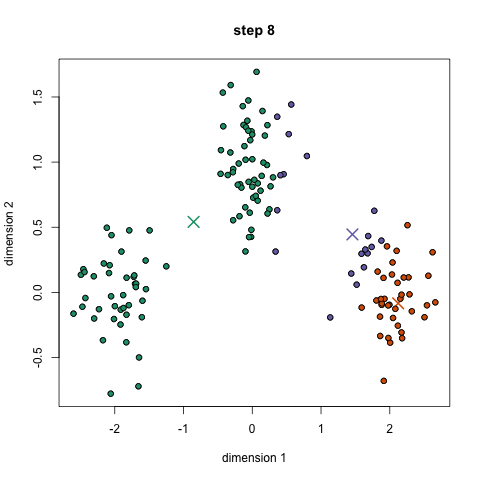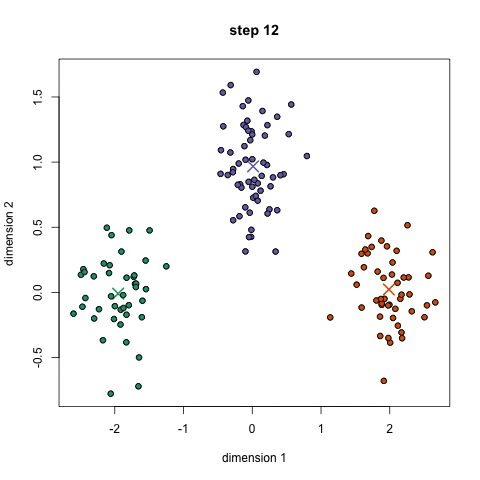
PYTHON代码 - 聚类类的补充
下面的Python方法是Clustering类的扩展,它允许它执行K-means聚类算法。这涉及使用均值漂移启发式更新质心。
聚类理论 - 聚类质量的度量
假设您有一定的相似度和数据聚类,您仍然需要一个目标函数来衡量该聚类的质量。大多数群集质量指标都尝试根据群集间和群集内距离来优化群集。简单地说,这些指标试图确保同一集群中的模式紧密相连,不同集群中的模式相距甚远。
量化误差
量化误差测量由量化引入的舍入误差,即将一组输入值映射到有限的较小集合。这基本上是我们通过将模式聚类到k个集群中所做的事情。

注意:图像还假设我们使用曼哈顿距离。
在量化误差的上述说明中,我们计算每个模式与其分配的质心之间的平方绝对距离之和。
戴维斯 - 布尔丁指数
戴维斯-尔丁标准是基于一个特定的聚类的簇内和簇间的距离比。

注意:图像假设我们使用曼哈顿距离。
在Davies-Bouldin指数的上图中,我们有三个由三个模式组成的集群。
剪影指数
该 剪影指数是衡量一个特定的聚类质量的最流行的方式之一。它衡量每个模式与其自身集群中的模式的相似程度,与其他集群中的模式进行比较。
def silhouette_index(self, index): # store the total distance to each cluster silhouette_totals = [] # store the number of patterns in each cluster silhouette_counts = [] # initialize the variables for i in range(self.solution.num_clusters): silhouette_totals.append(0.0) silhouette_counts.append(0.0) s = Similarity(self.e) for i in range(len(self.solution.patterns)): # for every pattern other than the one we are calculating now if i != index: # get the distance between pattern[index] and that pattern distance = s.fractional_distance(self.solution.patterns[i], self.solution.patterns[index]) # add that distance to the silhouette totals for the correct cluster silhouette_totals[self.solution.solution[i]] += distance # update the number of patterns in that cluster silhouette_counts[self.solution.solution[i]] += 1 # setup variable to find the cluster (not equal to the pattern[index]'s cluster) with the smallest distance smallest_silhouette = silhouette_totals[0] / max(1.0, silhouette_counts[0]) for i in range(len(silhouette_totals)): # calculate the average distance of each pattern in that cluster from pattern[index] silhouette = silhouette_totals[i] / max(1.0, silhouette_counts[i]) # if the average distance is lower and it isn't pattern[index] cluster update the value if silhouette < smallest_silhouette and i != self.solution.solution[index]: smallest_silhouette = silhouette # calculate the internal cluster distances for pattern[index] index_cluster = self.solution.solution[index] index_silhouette = self.e + silhouette_totals[index_cluster] / max(1.0, silhouette_counts[index_cluster]) # return the ratio between the smallest distance from pattern[index] to another cluster's patterns and # the patterns belong to the same cluster as pattern[index] return (smallest_silhouette - index_silhouette) / max(smallest_silhouette, index_silhouette)
高轮廓值表示žž 与其自己的簇很好地匹配,并且与相邻簇很不匹配。人们应该致力于为数据集中的每个模式最大化小号一世小号一世。

注意:图像还假设我们使用曼哈顿距离。
在使用这些指标过去几个月后,我得出的结论是,它们都不是完美的,
- 量化误差 - 该度量的计算复杂度最小,但是度量偏向大量群集,因为当您添加更多质心时,群集会变得更小(更紧凑),并且在极端情况下,您可能会为每个群集分配一个模式质心。在这种情况下,量化误差被最小化。使用这个指标The Good,结果是最可信 的。
- 戴维斯 - 布尔丁 - 随着你增加的值,ķķ每个质心之间的距离平均会自然减少。因为这个术语在分母中,所以对于较大的值,最终除以较小的数字ķķ。其结果是度量偏向于具有较少数量的簇的解决方案。
- Silhouette Index - 这个指标的计算复杂性是疯狂的。假设您计算从每个模式ž一世ž一世到每个其他模式的距离,以计算哪个簇最接近,并且您为每个模式执行此操作,则需要计算| Z | * | Z -1 ||ž|*|ž- 1|距离。在这个例子中,相当于35,156次计算。如果你完美地记忆,每次传球的计算次数减半。
以下对不同指标的分析很好地证明了这些偏差; 尽管事实上他们应该测量相同的东西,但他们几乎完全是负相关的。
| X | QE | D B | SI |
| QE | 1.0 | -0.965 | -0.894 |
| SB | -0.965 | 1.0 | 0.949 |
| SI | -0.894 | 0.949 | 1.0 |

PYTHON代码 - 聚类
在评估给定聚类的适应性之前,您需要实际聚类模式。Clustering类包含将模式分配给最近的质心的方法。
PYTHON代码 - 目标函数
ClusteringQuality类测量给定输入模式的聚类的质量。
聚类理论 - 聚类中的蒙特卡罗方法
K-Means聚类算法的两个最大问题是:
- 它对质心的随机初始化很敏感
- 初始化的质心数,ķķ
由于这些原因,K-means聚类算法经常重启多次。因为初始化(通常)是随机的,所以我们基本上对质心的随机高维起始位置进行采样,这也称为蒙特卡罗模拟。为了比较独立模拟的解决方案,我们需要衡量集群质量,例如前面讨论过的那些。
确定性初始化
我说初始化通常是随机的,因为K-Means聚类算法有确定性初始化技术。
随机初始化
不同之处在于伪随机序列中的下一个随机数与先前的随机数无关,而在准随机数序列中,下一个随机数取决于先前的随机数。相关随机数覆盖搜索空间的更大表面。

比较二维空间中的伪随机序列(左)和准随机序列(右)
选择正确的K
除了测试不同的初始化之外,我们还可以在蒙特卡罗框架中测试不同的值ķķ。目前,没有动态确定正确数量的聚类的最佳方式,尽管总是正在研究用于确定正确ķķ值的技术。我更愿意只是凭经验尝试不同的k值并比较结果,尽管这很费时,特别是在大型数据集上。
聚类结果 - 可视化和质心分析
下面提出的最终结果表示发现在范围最好聚类ķ = { 6 ,7 ,8 }ķ={6,7,8}超过1000独立每的每一个值的模拟ķķ。欧几里德距离和量化误差是蒙特卡罗K均值聚类中使用的距离和质量度量。用于产生结果的数据集是2014年的标准化时间点数据集,其中包括19个被确定为与实际GDP增长正相关的社会经济指标。
群集细分和质心分析
下面的每个标签都将集群分解为属于它的国家,并将质心与我们聚集的19个社会经济指标中的每一个的中心质心进行比较。

2014年该群组中的国家/地区



聚类结果 - 结论和进一步研究
量化不是风险管理,衍生品定价或算法交易; 它是关于挑战事情的方式,并通常使用统计和计算方法找到更好的方法。
2004年,美国是一个异常值,并且自己占据了一个集群。该集群的特点是PPP的汇率低,进口高,出口高,家庭支出高,工业生产高,政府收入相对较高,特别是在健康方面。在这个时间点,最大的差异仍然是中国发生的投资数量要大得多,而且人口(人口在15到64岁之间)人口更多(显然)更大。在工业生产方面,中国也超过了美国。这些在下面的并排比较中显示,


诸如东欧与西欧国家之类的俗语出现在地图上,并且(因为缺乏一个更好的词)正确。然而,诸如金砖四国(巴西,俄罗斯,印度,中国和南非)之类的口语显然更多地受到政治经济的驱动,而不是实际经济。以下是我对一些常见口语的看法,
- 东欧与西欧 - 第一组中的国家与第五组和第二组中的国家之间似乎有明显的区别。过去十年来,西班牙,爱尔兰,捷克共和国和其他附近国家发生了变化。这可能是主权债务危机的结果。
- 东西方国家 - 这是一种过度简化。大多数亚洲国家占据不同的集群,而美国和英国等传统的西方国家实际上并不占据同一集群。
- 金砖四国 - 巴西,俄罗斯,印度,中国和南非属于不同的集群。虽然他们可能已达成贸易协议,但这并不意味着这些国家具有相同的社会,人口和经济构成或未来实际GDP增长的相同潜力。
- 非洲增长故事 - 虽然资本市场在过去十年中表现良好,但这似乎并没有反映出非洲大陆的社会,人口和经济构成的重大变化。有趣的是,印度和巴基斯坦不再与中非和南非国家聚集在一起。
- 北非与南部非洲 - 北非国家(摩洛哥,阿尔及利亚,埃及,利比亚等)与非洲其他国家之间存在明显区别。令人惊讶的是,南非现在与这些国家聚集在一起。
- 新兴国家与发达国家 - 这似乎过于简化了。似乎有一些发展阶段将在下一节讨论。
还有更多的俗语,我为不评论所有这些而道歉,这六个只是我日常生活中经常遇到的那些。如果您发现其他有趣的关系,请评论。由于我们不知道每个社会经济指标的相对重要性,因此无法量化在一个集群与另一个集群中的有多好。在某些情况下,我们甚至无法确定大或小的价值是好还是坏。例如,如果政府效率低下,政府的大笔支出是否仍然有效?尽管如此,我还是试图构建一个粗略的度量标准来对每个集群进行排名:
排名=出口+家庭支出+进口+改善卫生+改善水+人口+ 15岁至64岁人口增长+总投资+城市百分比+手机订阅+政府收入+政府支出+医疗支出+工业生产+互联网用户 - PPP的汇率 - 失业率 - 年龄依赖率
根据此指标,每个群集的相对排名如下所示,
| 簇 | 排名值 | 秩 | 计数 |
6 |
10.238 | 1 | 2 |
8 |
5.191 | 2 | 22 |
1 |
5.146 | 3 | 20 |
5 |
3.827 | 4 | 20 |
2 |
3.825 | 5 | 45 |
4 |
3.111 | 6 | 32 |
3 |
3.078 | 7 | 4 |
7 |
1.799 | 8 | 43 |
这个排名并不完美,但它再次证实了我们的观点,即世界是一个不平等的地方。
那对投资者意味着什么呢?我认为这意味着应该在处于不同发展阶段的国家之间作出区分。这是因为虽然大多数欠发达国家代表的是具有最大回报潜力的投资,但它们的风险也更大,可能需要更长的时间才能获得回报。理想情况下,这些因素应相互权衡,并与投资者的风险回报偏好进行比较。


