本文基于数据库-ElasticSearch入门(索引、文档、查询),假设读者已学会安装ES,使用Postman和某语言的包或模块来对索引和文档进行基本的增删改查。
基础概念
定义
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene基础之上。Elasticsearch 也是使用** Java** 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
特点
- 一个分布式的实时文档存储,每个字段可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
curl "http://localhost:9200/" { "name" : "DESKTOP-BT64DM0", "cluster_name" : "elasticsearch", "cluster_uuid" : "Xk7sJl7OSei9DIyrn1G-vg", "version" : { "number" : "7.10.0", "build_flavor" : "default", "build_type" : "zip", "build_hash" : "51e9d6f22758d0374a0f3f5c6e8f3a7997850f96", "build_date" : "2020-11-09T21:30:33.964949Z", "build_snapshot" : false, "lucene_version" : "8.7.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" }
启动后访问9200端口,可以看到ES版本,集群名称,lucence版本等内容。
两个 Java 客户端都是通过 9300 端口并使用 Elasticsearch 的原生传输协议和集群交互。集群中的节点通过端口 9300 彼此通信。如果这个端口没有打开,节点将无法形成一个集群。
索引(Index)
可以创建索引时,携带请求体body,设置分片,mapping等
分片(Shards)
类似分表,进行容量扩展。ES可以将一个索引的分片放到不同的节点上,这样可以进行快速的分布式搜索。总的来说,分片可以
- 允许水平分分割/扩展容量。
- 允许进行分布式、并行的操作,提高吞吐量/性能。
副本(Replicas)
在一些情况下,可能导致某个节点/分片处于离线状态,为了保证出现故障时不影响服务,提出了副本,进行容灾备份,提供高可用性。
分配(Allocation)
master节点完成分配主分片和副本的过程。
映射(Mapping)
mapping是处理数据的方式和规则的限制。如字段的数据类型、是否被索引、分析器等。
动态映射
为了对新手友好一些,可以直接创建index,不用指定字段及类型,ES自动添加。
显式映射
了解字段类型之后,给不同的字段自定义数据类型,创建索引时进行指定。
PUT my-index { "mappings": { "properties": { "city": { "type": "text", "fields": { "raw": { "type": "keyword" } } } } } }
properties添加字段,fields使一个字段在不同类型搜索时是否可分析
city字段全文检索
city.raw字段是city的keyword版本,可被用于排序和聚合操作。
接下来先了解字段等概念,之后再配合搜索对映射进行深入理解。
常见数据类型
- boolean:true、false
- Numeric:
- byte:8位有符号整数
- short:16位有符号整数
- integer:32位有符号整数
- long、unsigned_long:有(无)符号64位整数
- Keywords:
- keyword:用于结构化内容,例如 ID、电子邮件地址、主机名、状态代码、邮政编码或标签。
- constant_keyword:始终包含相同值的关键字字段。
- wildcard:非结构化,机器生成的长数据
- date:日期,可使用format自定义
- Range:
- integer_range:32位有字符整数,-231 ~ 231-1
- long_range:64位有符号整数
- double_range:64位IEEE754类型浮点数
- date_range:日期,可以使用format自定义格式
- ip_range:ipv4和ipv6均支持
- Text:
- text:全文,一般是会进行分析和分析,邮件正文,商品描述等
- match_only_text:空间优化,禁用评分,适合日志消息。
文档(document)
- _index:文档存放在的索引
- _type:文档表示的对象类别,之前与关系型数据库的table对应,现在不再强调这个
- _id:文档唯一标识
- _version:版本,更新文档时,该字段会改变
- _source:数据
领域特定语言 (DSL)
使用 JSON 构造了一个请求。包含了filter range过滤器。
分词器
在全文检索情况下,对text等类型分词,方便建立倒排索引。常见的分词器有
- ik分词器
- icu分词器
- smartcn分词器
- pinyin分词器
更多分词器见参考,es官方github上有一些。腾讯云可支持大部分插件,点击ES集群->插件列表。如下图所示。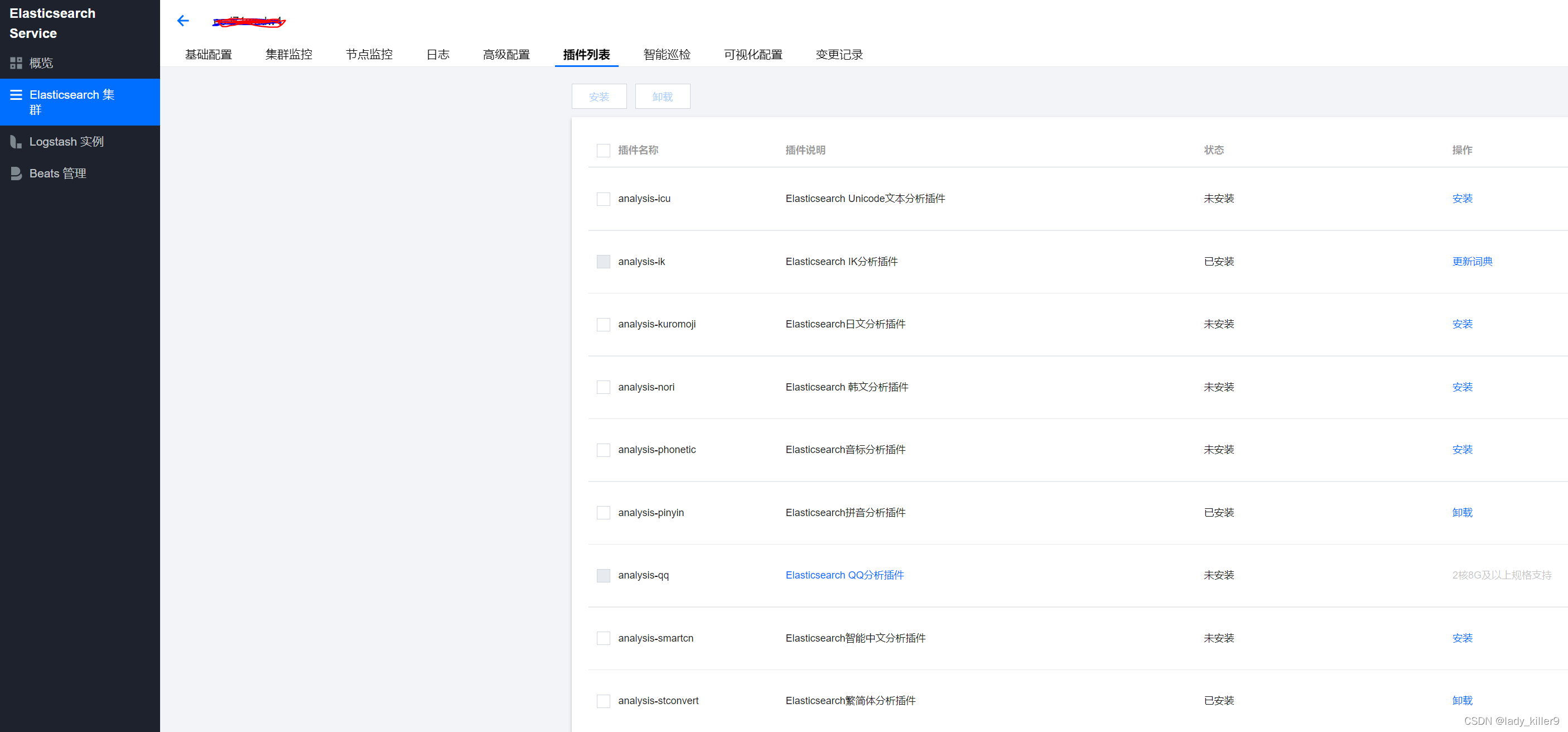
得分排序
按照相关性得分排序,一般使用TF-IDF算法(见参考,本文主要还是在ES实践方面,算法不赘述),通过_score返回得分
后台执行的操作
- 分配文档到不同的容器 或 分片 中,文档可以储存在一个或多个节点中
- 按集群节点来均衡分配这些分片,从而对索引和搜索过程进行负载均衡
- 复制每个分片以支持数据冗余,从而防止硬件故障导致的数据丢失
- 将集群中任一节点的请求路由到存有相关数据的节点
- 集群扩容时无缝整合新节点,重新分配分片以便从离群节点恢复
深入搜索(实践)
ES,you know, for search, 搜索才是重点!!!
数据添加
索引heros,字段及类型如下:
- name:keyword
- age:byte
- role:keyword
- birthday:date
- mail:text
- hobby:text
- sentence:text
数据如下:
| name | age | role | birthday | hobby | sentence | |
| 大乔 | 18 | 辅助 | 2003-11-10 | daqiao@163.com | 写诗 画画 | 诗是自由的载体 |
| 小乔 | 19 | 法师 | 2002-01-20 | xiaoqiao@sina.com | 画画 唱歌 | Whenever you need me, I’ll be here. |
| 孙策 | 25 | 坦克 | 1996-11-10 | sunce@163.com | 画画 唱歌 | 我向往诗和远方,也不会忘记她和故乡 |
| 周瑜 | 23 | 法师 | 1998-01-20 | zhouyu@sina.com | 写诗 画画 | Whenever you are in trouble,I’m always near. |
| 刘备 | 30 | 打野 | 1991-10-20 | liubei@qq.com | 兵法 武器 | Shi wo bu tai dong |
| 孙尚香 | 26 | 射手 | 1995-10-20 | 兵法 化妆 | 詩我不太懂 |
创建索引及文档
PUT /heros
这里使用的Kibana的DevTools,如果你看了ES系列第一篇文章,有白嫖腾讯云的ES集群,可以点击可视化配置,给Kibana配置公网白名单即可,由于我前面的文章还没有介绍Kibana的使用,你可以继续使用Postman、curl或elasticsearch-head插件来发起请求。
查看setting和mapping情况
GET /heros?pretty

添加一个文档
POST /heros/_doc/1001 { "name":"大乔", "age":18, "role":"辅助", "birthday":"2003-11-10", "mail":"daqiao@163.com", "hobby":"写诗 画画", "sentence":"诗是自由的载体" }
结果如下

再次查询mapping

可以看到ES自动添加了类型,但是与我们要求的不符合。有些不会自动分词,无法进行后序的搜索。
删除索引,再次添加
PUT /heros { "settings": { "number_of_shards": 1, "number_of_replicas": 1 }, "mappings": { "properties": { "name":{ "type": "keyword" }, "age":{ "type": "byte" }, "role":{ "type": "keyword" }, "mail":{ "type":"text" }, "birthday":{ "type":"date" }, "hobby":{ "type": "text" }, "sentence":{ "type":"text" } } } }

之后添加文档,其他英雄的放在附录了,最终的索引应该如下图所示:

结构化搜索
结构化搜索(Structured search) 是指有关探询那些具有内在结构数据的过程。比如日期、时间和数字都是结构化的:它们有精确的格式,我们可以对这些格式进行逻辑操作。
在结构化查询中,要么存于集合之中,要么存在集合之外。结构化查询不关心文件的相关度或评分;它简单的对文档包括或排除处理。
单一过滤器(term)
我们首先来看最为常用的 term 查询, 可以用它处理数字(numbers)、布尔值(Booleans)、日期(date)等。
注意:ES5.0后,已经没有string类型了
警告:尽量不要用于text类型字段
查询角色是“法师”的英雄
GET /heros/_search { "query":{ "term":{ "role":"法师" } } }
结果如下图所示

多个精确值terms
查询角色是“法师”或“射手”的英雄
GET /heros/_search { "query":{ "terms":{ "role":["法师","射手"] } } }
结果如图所示

可以看到,多了射手角色的英雄。
范围过滤器(range)
{ "range":{ "field_name":{ }, } }
对字段进行范围过滤,常用的如下
- gt: > 大于(greater than)
- lt: < 小于(less than)
- gte: >= 大于或等于(greater than or equal to)
- lte: <= 小于或等于(less than or equal to)
查询19<=age<25的英雄
GET /heros/_search { "query": { "range":{ "age":{ "gte":19, "lt":25 } } } }
结果如下图所示

组合过滤器(bool过滤器)
将多个过滤器进行组组合
{ "bool" : { "must" : [], "must_not" : [], "should" : [], "filter":[], } }
- must:所有语句必须匹配,相当于and
- must_not:所有语句不能匹配,相当于not
- should:至少有一个语句匹配,相当于or
查询角色是法师或辅助,年龄必须小于20,邮箱不能是新浪邮箱的英雄
GET /heros/_search { "query": { "bool": { "must": { "range":{ "age":{ "lt":20 } } }, "must_not": { "match":{"mail":"@sina.com"} }, "should": [ { "term": {"role": "法师"} }, { "term":{"role":"辅助"} } ] } } }
看前面的数据可以发现,就剩大乔了,结果如下图所示

NULL值处理(exists)
查询有邮箱的英雄
GET /heros/_search { "query": { "exists": { "field": "mail" } } }
结果如下图所示

那么,如何查询不存在邮箱的英雄呢?之前有missing,现在不支持了,可以使用must_not进行嵌套
GET /heros/_search { "query": { "bool": { "must_not": { "exists":{ "field": "mail" } } } } }
结果如下图所示

全文搜索
基于词项与基于全文
如 term 或 fuzzy 这样的底层查询不需要分析阶段,它们对单个词项进行操作。
像 match 或 query_string 这样的查询是高层查询,它们了解字段映射的信息
匹配搜索(match)与操作符(operator)
查询sentence中含诗的英雄
GET /heros/_search { "query": { "match": { "sentence": "诗" } } }
结果如下图所示

可以看到,评分语句更短的评分更高
多词搜索情况下
查询sentence中含“我 诗”的英雄
GET /heros/_search { "query": { "match": { "sentence": "我 诗" } } }
结果如下图所示

可以看到有些只包含我或诗的内容也出来了,虽然排名落后,如何做到且呢,前面使用了must,这里使用operator实现
GET /heros/_search { "query": { "match": { "sentence": { "query": "我 诗", "operator": "and" } } } }
结果如下图所示

权重提升(boost)
查询sentence中必须包含"Whenever",有"in"或者"be"的英雄
GET /heros/_search { "query": { "bool": { "must": [ {"match": { "sentence": "Whenever" }} ], "should": [ { "match": { "sentence": "in" } }, { "match": { "sentence": "be" }} ] } } }
结果如下图所示

现要求含in的权重更高,也就是提高_score来提高搜索排名
boost默认为1,通过增加in的boost来提高in的排名
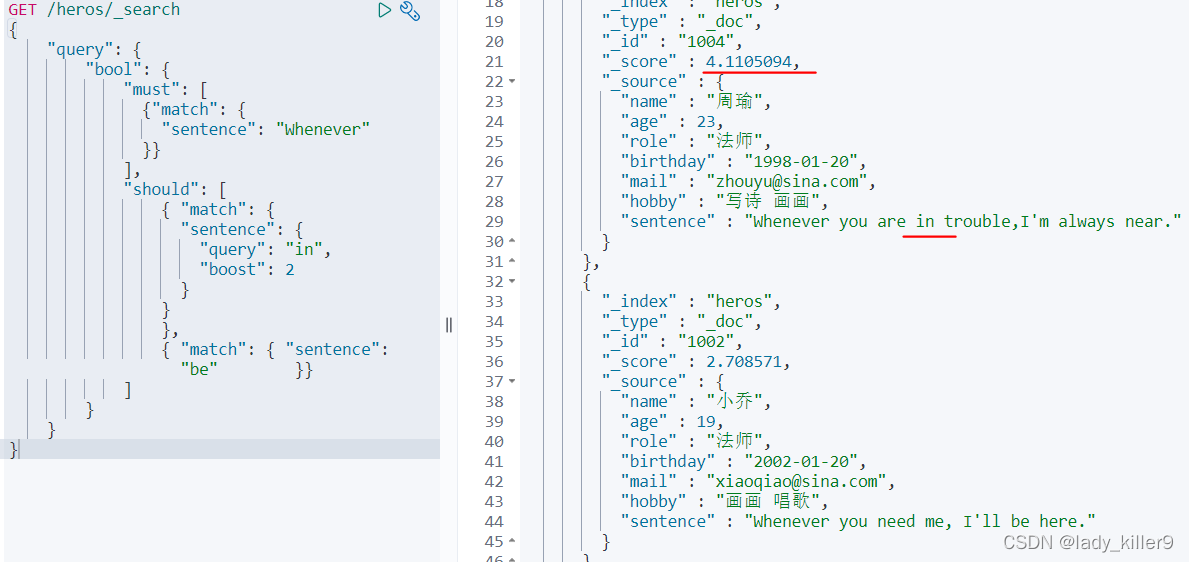
GET /heros/_search { "query": { "bool": { "must": [ {"match": { "sentence": "Whenever" }} ], "should": [ { "match": { "sentence": { "query": "in", "boost": 2 } } }, { "match": { "sentence": "be" }} ] } } }
结果如下图所示
多字段搜索
前面已经进行了简单的多字符串搜索,不过,还有一些多字段时复杂的搜索情况。
最佳字段查询(dis_max与tie_breaker)
查询爱好有诗,sentence(随便起的名字,可以理解为个性签名或一句话介绍)中有诗或她的英雄
GET /heros/_search { "query": { "bool": { "should": [ { "match": { "hobby": "诗" }}, { "match": { "sentence": "诗 她" }} ] } } }
结果如下图所示

可以看到,第二个结果是我们更想得到的。bool会打两次分,再除以语句总数2,第一个结果hobby和sentence都有诗,导致第一个结果就靠前了,由于hobby和sentence的竞争关系,所以需要找到最佳匹配字段。
使用dis_max来得到想要的结果
GET /heros/_search { "query": { "dis_max": { "queries": [ { "match": { "hobby": "诗" }}, { "match": { "sentence": "诗 她" }} ] } } }
结果如下图所示

tips:想要在bool和dis_max之间,可以使用tie_breaker参数,请读者自行深入了解。
多字段进行相同搜索(multi_match)
查询hobby或sentence中含诗的英雄,也就是对hobby sentence做同一搜索,如果写多个match会比较繁琐,可以采用multi_match,字段使用列表的方式填写多个即可。
GET /heros/_search { "query": { "multi_match": { "query": "诗", "fields": ["hobby","sentence"] } } }
结果如下图所示

hobby和sentence都含诗的会排名靠前
部分匹配
即只输入一部分,也能匹配到,最经典的就是边输入边搜索,也。
输入即搜索(match_phrase_prefix)
现在很多搜索引擎都有用户边输入边提示的功能,不必等用户Enter,提高了用户体验
用户查询sentence,输入了when,查询此时的下拉框的结果
GET /heros/_search { "query": { "match_phrase_prefix": { "sentence": { "query": "When" } } } }
结果如下图所示

通配符搜索(wildcard)
包含两个通配符"?“和”*",? 匹配任意字符, * 匹配 0 或多个字符
搜索姓孙的英雄
GET /heros/_search { "query": { "wildcard": { "name": "孙*" } } }
结果如下图所示

正则表达式搜索(regexp)
正则表达式更加的丰富,包含数字、特殊字符等
搜索邮箱含s、n,s在n前面的英雄
GET /heros/_search { "query": { "regexp": { "mail": "s.*n.*" } } }
结果如下图所示

sunce符合,新浪邮箱也符合。
总结
本文讲了一些基础概念,深入研究了一些搜索(抛转引玉,官网还有很多搜索方式),本来想写集群的,白嫖腾讯云的只能固定三个节点,没法演示扩容之类的,下篇文章再说一下集群。
练习
查询角色是“坦克”的英雄?
查询年龄>18的“法师”英雄?
查询姓"孙"的且名字是两个字的英雄?
附录
POST /heros/_doc/1002 { "name":"小乔", "age":19, "role":"法师", "birthday":"2002-01-20", "mail":"xiaoqiao@sina.com", "hobby":"画画 唱歌", "sentence":"Whenever you need me, I'll be here." }
POST /heros/_doc/1003 { "name":"孙策", "age":25, "role":"坦克", "birthday":"1996-11-10", "mail":"sunce@163.com", "hobby":"画画 唱歌", "sentence":"我向往诗和远方,也不会忘记她和故乡" }
POST /heros/_doc/1004 { "name":"周瑜", "age":23, "role":"法师", "birthday":"1998-01-20", "mail":"zhouyu@sina.com", "hobby":"写诗 画画", "sentence":"Whenever you are in trouble,I'm always near." }
POST /heros/_doc/1005 { "name":"刘备", "age":30, "role":"打野", "birthday":"1991-10-20", "mail":"liubei@qq.com", "hobby":"兵法 武器", "sentence":"Shi wo bu tai dong" }
POST /heros/_doc/1006 { "name":"孙尚香", "age":26, "role":"射手", "birthday":"1995-10-20", "hobby":"兵法 化妆", "sentence":"詩我不太懂" }
参考
更多ELK相关内容:数据库-ElasticSearch学习笔记_lady_killer9的博客-CSDN博客
喜欢本文的请动动小手点个赞,收藏一下,有问题请下方评论,转载请注明出处,并附有原文链接,谢谢!
如有侵权,请及时联系。如果您感觉有所收获,自愿打赏,可选择支付宝18833895206(小于),您的支持是我不断更新的动力。
