
✈UML基础
在软件开发流程中,一般应先对软件开发的过程进行建模,把要做什么功能、如何去实现、达到什么样的程度这些基本问题分析清楚了,才去写代码实现。建模是对现实按照一定规则进行简化,但应该体现出现实事物的特点。通过软件建模可以把现实世界中的问题转化到计算机世界进行分析和实现,软件建模的实现过程就是需求-建模-编码的一个过程。
UML统一建模语言,United Modeling Language,是一种面向对象的可视化建模语言,通过图形符号描述现实系统的组成,通过建立图形之间的关系来描述整个系统模型。
1. 类图
类图是面向对象系统建模中最常用的一种UML图,主要用来表示类与类之间的关系,包括泛化关系、关联关系、依赖关系和实现关系。
类图由三部分组成:类名、属性和方法。

- 表示private
+ 表示public
# 表示protected
点击选择类组件就可以进行设置,可以直接在组件上修改,也可以在右侧Editors修改。
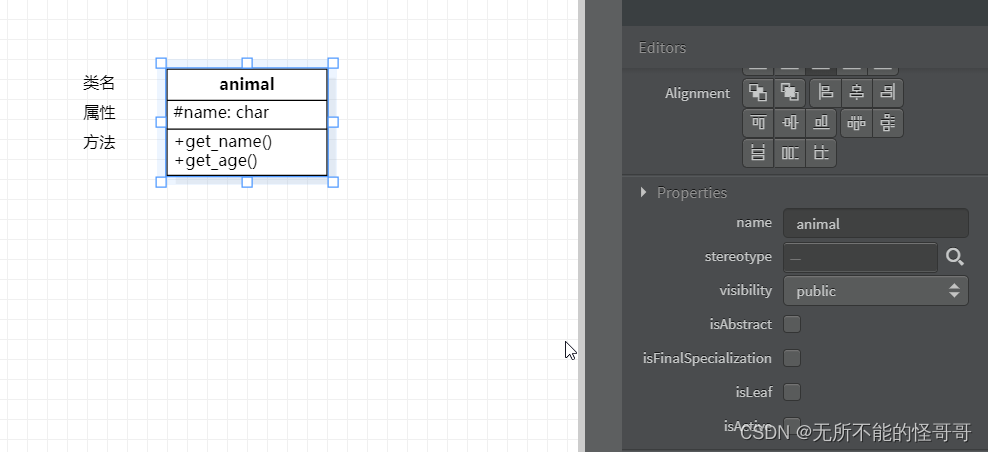
- 属性表示为 属性名:类型
- 方法表示为 方法名(参数类型):返回值类型
2. 类与类之间的关系
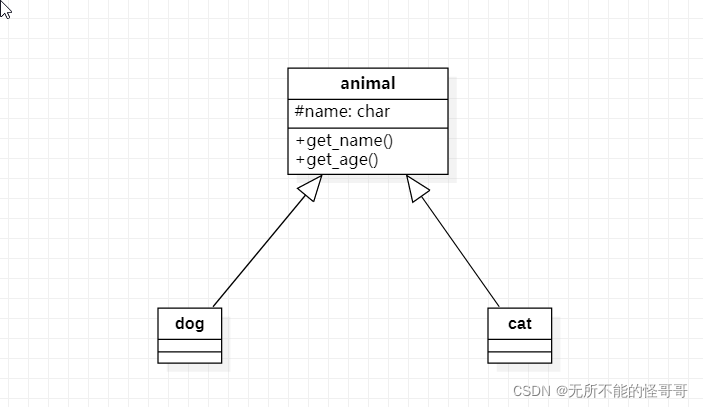
😀泛化关系
Generalization,用来表示类与类之间的继承关系,也叫做is a kind of关系,用三角形的箭头从子类指向父类。
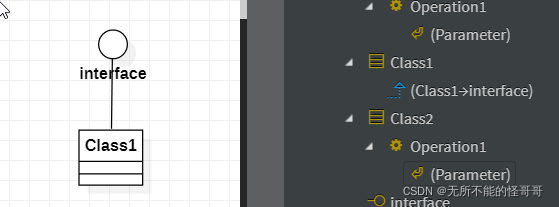
😀实现关系
Realization,实现关系就是类或接口的实现,由三角箭头虚线从实现类指向接口类,(比如C++中纯虚函数的实现)。可以在右侧查看类之间的关系。
😀依赖关系
Dependency,依赖关系是指在一个类中要用到另一个类的实例的一种关系,主要表现为一个类是另一个类的函数参数,或者一个类是另一个类的函数返回值的情况。在类图中的表现形式为一个虚线箭头从一个类指向被依赖的类。
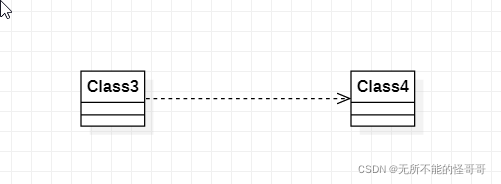
具体代码表现形式为
1. class Class4 {}; 2. class Class3 3. { 4. public: 5. void function(Class4 temp) //Class4类对象作为Class3的成员函数的函数参数 6. { 7. /**/ 8. } 9. };
😀关联关系
Association,关联关系是类和类之间对应的一种连结,是指两个独立的对象,一个对象的实例与另一个对象的一些特定实例存在固定的对应关系。关联关系可以是单向的也可以是双向的,通过关联使得一个类可以使用另一个类的属性和方法,在C++中具体的表现形式为,一个类的对象是另一个类的成员属性。在类图中,单向的是带箭头的实线,双向的是不带箭头的实线。
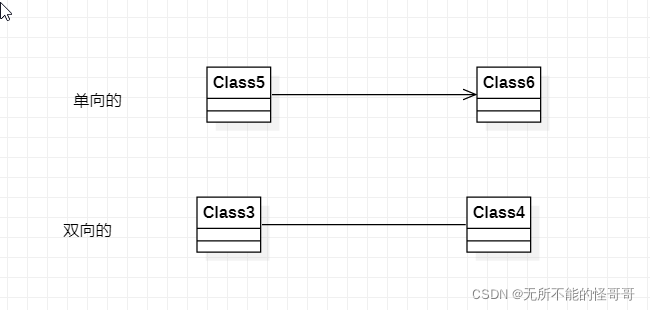
代码形式为
1. class Class6 {}; 2. class Class5 3. { 4. public: 5. void func() 6. { 7. c.func1(); //可以直接使用Class6的方法 8. } 9. private: 10. Class6 c; //Class6对象作为Class5类的成员属性 11. };
😀聚合关系
Aggregation,聚合关系表示整体和部分的关系,它是一种has-a的包含关系,而且整体和部分是可以分离的,即离开整体,部分也能存在。聚合关系是关联关系的一种,它是一种更强的关联关系。聚合关系在C++中的表现也是成员变量的方式,但是和关联关系不同的是,关联关系中的两个类是相互独立的,而聚合关系中的两个类是整体与部分的关系,一个类是另一个类的一部分。在类图中,空心菱形在代表整体的类那侧,另一侧为代表部分的类。
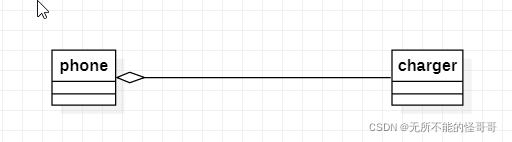
聚合关系的简单理解,比如手机和充电线,充电线是手机的一部分,手机就是整体,充电线是部分,但是没有手机了,充电线也可以单独存在。代码表现形式为:
1. class charger {}; 2. class phone 3. { 4. public: 5. void set_charger(charger m_c) 6. { 7. this->m_c = m_c; 8. } 9. public: 10. charger m_c; 11. };
在聚合关系中,我们在创建一个对象phone的时候可以不去管charger,因为在phone类中定义了set_charger方法用于构造charger,我们可以通过该方法在其它时机设置charger。
😀组合关系
Composite,也是关联关系的一种,是一种比聚合关系更强的关联关系。如果两个类是聚合关系(A是B的一部分),那么离开B之后,A就失去了存在的意义。组合关系是一种不可分离的关系。在类图中用实心菱形指在代表整体的类,另一侧为代表部分的类。
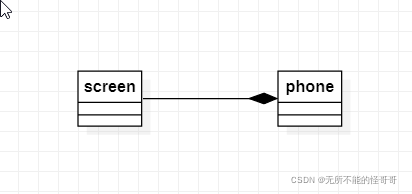
聚合关系的简单理解,屏幕screen是手机phone的一部分,并且屏幕screen离开手机phone之后就失去了存在的意义,这就是组合关系。代码表现形式为:
1. class screen {}; 2. class phone 3. { 4. public: 5. phone(screen m_s) 6. { 7. this->m_s = m_s; 8. } 9. public: 10. screen m_s; 11. };
在组合关系中,创建phone对象的时候就已经构造了属性m_s,也就是整体phone的生命周期也决定了部分screen的生命周期,一旦phone生命周期结束了,screen的生命周期也结束了。在聚合关系中,没有这种强的生命周期的关联。
😀小结
对6种类与类之间的关系进行总结对比:
- 泛化关系和实现关系的区别:泛化关系是指C++中的继承关系;而实现关系是指虚基类的继承,在子类中实现虚基类的纯虚函数。
- 泛化关系和实现关系可以看成依赖关系的一种,因为它们离开依赖的类都无法编译通过。
- 聚合关系和组合关系是关联强度逐渐增强的关联关系;关联关系双方是平等的,聚合关系和组合关系的双方是整体和部分的关系。
- 聚合关系的双方整体和部分可以分离单独存在,没有生命周期的强相关;组合关系双方,部分离开整体将失去意义,整体的生命周期代表了部分的生命周期。
3. 设计模式七大原则
😁开放封闭原则
OCP,Open For Extension Closed For Modification Principle,简称开闭原则。开闭原则是指软件实体是可以扩展的,但是不可修改。也就是说,模块和函数是对扩展(提供方)开放的,对修改(使用方)关闭的,对于一个新的需求,对软件的改动应该是通过增加代码来实现的,而不是通过改动代码实现的。开闭原则是面向对象的核心,是最基础、最重要的设计原则,开发过程中,应该把可能会频繁变动的部分抽象出来,当需要变动时,只需要去实现抽象即可,也就是面向抽象编程。对于C++类来说,对类的改动是通过增加代码实现的,而不是修改代码实现的,通过虚基类的继承和虚函数的实现来完成一个类功能的扩充,这也是多态在设计模式中重要地位的体现。
举例来说,假如我们要创建一个迪迦奥特曼类,迪迦奥特曼有三种形态,最简单的方式就是在一个类中实现,每次都在类中增删查改
1. //第一层次:直接修改类来实现增加功能 2. class TigaUltraman1 3. { 4. public: 5. void RedForm() //红色形态 6. { 7. cout << "红色形态的迪迦奥特曼" << endl; 8. } 9. 10. void BlueForm() //蓝色形态 11. { 12. cout << "蓝色形态的迪迦奥特曼" << endl; 13. } 14. 15. void CompreForm() //综合形态 16. { 17. cout << "综合形态的迪迦奥特曼" << endl; 18. } 19. }; 20. 21. int main() 22. { 23. //1. 直接修改迪迦奥特曼类来增加不同形态 24. TigaUltraman1* u1 = new TigaUltraman1; 25. u1->RedForm(); 26. u1->BlueForm(); 27. u1->CompreForm(); 28. delete u1; 29. cout << endl; 30. }
那么这样的话显然不满足开闭原则,实际上应该定义一个抽象类,这个抽象类只提供一个统一的接口,当需要增加功能时只需要继承这个抽象类,并实现抽象方法即可。
1. //第二层次,创建一个抽象类,通过继承实现形态扩充 2. class TigaUltraman //迪迦奥特曼抽象类 3. { 4. public: 5. virtual void uForm() = 0; 6. }; 7. 8. class RedTigaUltraman : public TigaUltraman 9. { 10. public: 11. virtual void uForm() 12. { 13. cout << "红色形态的迪迦奥特曼" << endl; 14. } 15. }; 16. 17. class BlueTigaUltraman : public TigaUltraman 18. { 19. public: 20. virtual void uForm() 21. { 22. cout << "蓝色形态的迪迦奥特曼" << endl; 23. } 24. }; 25. 26. class CompreTigaUltraman : public TigaUltraman 27. { 28. public: 29. virtual void uForm() 30. { 31. cout << "综合形态的迪迦奥特曼" << endl; 32. } 33. }; 34. 35. int main() 36. { 37. //2. 使用继承 38. TigaUltraman* u2 = NULL; 39. u2 = new RedTigaUltraman; 40. u2->uForm(); 41. delete u2; 42. u2 = new BlueTigaUltraman; 43. u2->uForm(); 44. delete u2; 45. u2 = new CompreTigaUltraman; 46. u2->uForm(); 47. delete u2; 48. cout << endl; 49. }
更进一步,我们可以提供一个接口,直接调用接口,把各种实现类的对象传递给抽象类的指针并产生多态。即使是子类的子类也可以传给抽象类产生多态。
1. //第三层次:使用一个统一接口 2. void get_form(TigaUltraman* u) 3. { 4. u->uForm(); 5. } 6. 7. //增加功能,进化版的综合形态 8. class EvolutionCompreTigaUltraman : public CompreTigaUltraman 9. { 10. public: 11. virtual void uForm() 12. { 13. cout << "进化版的综合形态的迪迦奥特曼" << endl; 14. } 15. }; 16. 17. int main() 18. { 19. //3. 使用统一接口 20. u2 = new RedTigaUltraman; 21. get_form(u2); 22. delete u2; 23. BlueTigaUltraman* u3 = new BlueTigaUltraman; 24. get_form(u3); 25. delete u3; 26. CompreTigaUltraman u4; 27. get_form(&u4); 28. cout << endl; 29. 30. u2 = new EvolutionCompreTigaUltraman; 31. get_form(u2); 32. delete u2; 33. cout << endl; 34. }
😁单一职责原则
SRP,Single Responsibility Principle,单一职责原则。对类来说,类的职责应该是单一的,一个类只能对外提供一种功能。换句话说,变动这个类的理由或动机只能有一个,如果第二个改动类的理由,就不是单一职责。单一职责相当于降低了各种职责的耦合度,如果一个类负责多个职责,那么改动类的某一职责时,可能会影响到类行使其他职责的能力。
😁依赖倒置原则
DIP,Dependence Inversion Principle,依赖倒置原则。抽象不应该依赖于细节,细节应该依赖于抽象。换句话说,依赖于抽象接口,而不是依赖于具体的类的实现,也就是面向抽象接口编程。依赖倒置原则是面向对象编程的标志,在具体软件设计时,上层模块不应该依赖于底层模块,底层模块更不应该依赖上层模块,而是上层模块和底层模块都向中间靠拢,共同依赖于二者中间的抽象接口层。整个软件程序设计的依赖关系应该终止于抽象接口层,上层和底层互不关心,甚至使用什么编程语言都不关心。抽象接口层提供一个标准或者协议,它对上提供访问的接口,对下提供实现的标准,抽象接口层本身不执行任何操作,具体的功能由它的实现去完成。
举例来说,假如我们要组装一台电脑,现在要选择硬盘、内存、屏幕。那么电脑类要集成硬盘、内存、屏幕这些组件,但是我们希望电脑类和组件类之间不应该是相互依赖的关系,我们就可以直接给出一套接口,各个组件厂商只要实现这些抽象接口就可以装入我们的电脑中。
1. //各个组件的抽象类 2. class DiskInterface 3. { 4. public: 5. virtual void infomation() = 0; 6. }; 7. 8. class MemoryInterface 9. { 10. public: 11. virtual void infomation() = 0; 12. }; 13. 14. class ScreenInterface 15. { 16. public: 17. virtual void infomation() = 0; 18. };
电脑类定义如下
1. class Computer 2. { 3. public: 4. Computer(DiskInterface* disk, MemoryInterface* memory, ScreenInterface* screen) 5. { 6. this->disk = disk; 7. this->memory = memory; 8. this->screen = screen; 9. } 10. public: 11. void get_information() 12. { 13. this->disk->infomation(); 14. this->memory->infomation(); 15. this->screen->infomation(); 16. } 17. private: 18. DiskInterface* disk; //使用指针而不能使用变量 19. MemoryInterface* memory; 20. ScreenInterface* screen; 21. };
各个厂商根据组件的抽象类去实现,来入围电脑类
1. //各厂商直接继承抽象类,来实现 2. class InterDisk : public DiskInterface 3. { 4. public: 5. virtual void infomation() 6. { 7. cout << "因特尔硬盘" << endl; 8. } 9. }; 10. 11. class WDMemory : public MemoryInterface 12. { 13. public: 14. virtual void infomation() 15. { 16. cout << "西部数据的内存条" << endl; 17. } 18. }; 19. 20. class HPScreen : public ScreenInterface 21. { 22. public: 23. virtual void infomation() 24. { 25. cout << "惠普的屏幕" << endl; 26. } 27. };
这样组件类和电脑类都依赖于抽象接口层,两者都向接口层靠近,这就是面向接口编程,也就是我们的依赖倒置原则。我们直接把各个组件的实现类定义对象并传到电脑类中即可
1. { 2. InterDisk* idisk = new InterDisk; 3. WDMemory* wdmem = new WDMemory; 4. HPScreen* hpscr = new HPScreen; 5. SamScreen* samscr = new SamScreen; 6. 7. Computer* c1 = new Computer(idisk, wdmem, hpscr); //使用惠普的屏幕 8. c1->get_information(); 9. 10. delete c1; 11. delete samscr; 12. delete hpscr; 13. delete wdmem; 14. delete idisk; 15. }
假如后来,三星也想入围这个电脑,那么三星直接去实现屏幕的抽象类即可
1. class SamScreen : public ScreenInterface 2. { 3. public: 4. virtual void infomation() 5. { 6. cout << "三星的屏幕" << endl; 7. } 8. };
我们再直接把三星的屏幕传入电脑类即可
1. { 2. Computer* c2 = new Computer(idisk, wdmem, samscr); //使用三星屏幕 3. c2->get_information(); 4. }
这就是面向接口编程。
😁接口隔离原则
ISP,Interface Segegation Principle,接口隔离原则。一个接口对外只提供一种功能,不同功能应该通过不同的接口提供,而不是把多种功能都封装到一个接口中,否则的话,可能有的客户只需要功能A不需要功能B,但是提供A功能的接口内还封装了功能B,这就造成了客户被迫依赖某种他们不需要的功能。
😁里氏替换原则
LSP,Liskov Substitution Principle,里氏替换原则。任何地方出现的抽象类,都可以使用该抽象类的实现类来代替,这其实类似于C++中的类型兼容性原则,所有基类出现的地方都可以用子类对象来代替。实际上,继承增强了类与类之间的耦合性,在继承中应该尽量不要重写(覆盖)基类中的非抽象方法,子类可以有自己的方法,但是不能重新定义或修改基类的方法,否则如果基类中发生改变,所有的子类都可能受影响,应该尽量使用组合或者聚合而不是继承。其实,准确来说,应该是尽量不要继承可实例化的类(非抽象类),而应该是从抽象类中继承。
1. class parent 2. { 3. public: 4. virtual void function1() = 0; 5. void function2() 6. { 7. cout << "parent function 2" << endl; 8. } 9. }; 10. 11. class child1 : public parent 12. { 13. public: 14. virtual void function1() 15. { 16. cout << "function 1" << endl; 17. } 18. void function2() 19. { 20. cout << "child function 2" << endl; 21. } 22. };
举例来说,应该去实现function1()这样的抽象方法,而不能去覆盖基类的方法function2()。当子类覆盖或实现基类的方法时,方法的前置条件(形参)要比基类方法的输入参数宽松;当子类实现父类的抽象方法时,方法的后置条件(方法返回值)要比基类更严格。
😁合成复用原则
CARP,Composite/Aggregate Reuse Principle,优先使用对象组合而不是继承原则。使用继承的时候,基类的变化可能会影响到子类,而如果使用组合/聚合就可以降低这种依赖关系。组合/聚合降低了类与类之间的耦合性,一个类的变化对另一个类的影响相对较小,如果要使用继承,必须要遵守里氏替换原则。
😁迪米特法则
LOD,Law of Demeter,迪米特法则,也叫做最少知道原则(The Least Knowledge Principle)。一个类对于其它类知道的越少越好,只和朋友说话,不要和陌生人说话,这里的朋友是指作为成员变量、方法输入输出参数的类(朋友类),如果是出现在一个方法内部的类就不是朋友类。迪米特法则降低了耦合度,各个模块之间通过一个接口来实现调用,而模块之间不需要知道对方的内部实现逻辑,并且一个模块的内部改变也不会影响到另一个模块(黑盒原理)。如果两个类不直接通信,那么这两个类就不应当发生直接的相互作用。如果一个类需要调用另一个类的某个方法的话,可以通过第三个类转发这个调用。
朋友圈确定:
- 当前对象本身;
- 以参量形式传入到当前对象方法中的对象;
- 当前对象的实例变量直接引用的对象;
- 当前对象的实例变量如果是一个聚集,那么聚集中的元素都是朋友;
- 当前对象所创建的对象;
满足条件之一就是朋友,否则就是陌生人。
4. 什么是设计模式
模式就是解决问题的固定套路,设计模式(Design pattern)就是一套经过前人反复使用,总结出来的程序设计经验。设计模式总共分为三大类:
第一类是创建型模式 ,该模式通常和对象的创建有关,涉及到对象实例化的方式。包括:单例模式、工厂模式、抽象工厂模式、建造者模式、原型模式五种;
第二类是结构型模式,结构型模式描述的是如何组合类和对象来获得更大的结构。包括:代理模式、装饰者模式、适配器模式、桥接模式、组合模式、外观模式、享元模式共7种模式。
第三种是行为型模式,用来描述对类或对象怎样交互和怎样分配职责。共有:模板模式、命令模式、责任链模式、策略模式、中介者模式、观察者模式、备忘录模式、访问者模式、状态模式、解释器模式、迭代器模式11种模式。
🚀一、单例模式
1. 什么是单例模式
单例模式是创建型模式的一种,正常情况下,我们定义一个类是可以创建很多个对象的,而单例模式顾名思义就是指一个类只能创建一个实例对象,也就是说在整个程序空间中,这个类只有一个对象,并且对外提供一个全局访问点来访问这个唯一的实例对象。单例模式主要分为两类:
饿汉式单例模式:一开始就创建好了一个唯一的对象;
懒汉式单例模式:在使用实例对象的时候去创建该唯一的对象;
单例模式的结构图:
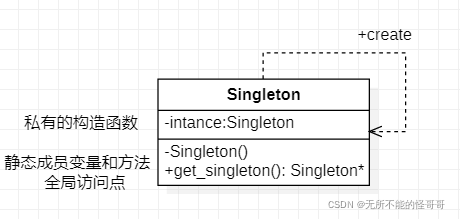
2. 单例模式的实现
2.1 懒汉式单例模式
😂如何保证只有一个实例对象
当我们在使用类来new创建一个对象的时候,会自动调用构造函数,每创建一个对象都会调用构造函数来构造一个新的对象
1. class classA{}; 2. 3. void func() 4. { 5. classA* a1 = new classA; //调用构造函数 6. classA* a2 = new classA; //调用构造函数 7. if (a1 != a2) 8. { 9. cout << "a1和a2是两个不同的对象" << endl; 10. } 11. }
在上面程序中,我们new了两个对象,会调用两次构造函数,并创建出两个不同的对象,我们可以直接通过判断来测试一下

既然我们希望这个类只有一个实例对象,那么就应该禁止类的外部访问构造函数,因为每次在类的外部调用构造函数都会构造出一个新的实例对象。解决办法就是把构造函数设置为私有属性,在类的内部完成实例化对象的创建,这样就对外隐藏了创建对象的方法。但是类的出现就是要定义对象的,我们要使用类创建的对象,所以还需要提供一个全局访问点来获取类内部创建好的对象
1. class SingletonPattern 2. { 3. private: 4. SingletonPattern() 5. { 6. cout << "私有的构造函数" << endl; 7. } 8. public: //构造函数被私有化了,所以应该提供一个对外访问的方法,来创建对象 9. static SingletonPattern* get_single() 10. { 11. if (single == NULL) //为保证单例,只new一次 12. { //如果不加这个判断,每次创建对象都会new一个single,这就不是单例了 13. single = new SingletonPattern; 14. } 15. //return this->single; 16. return single; //静态成员属于整个类,没有this指针 17. } 18. private: //static 成员,类定义的所有对象共有static成员 19. static SingletonPattern* single; //指针,不能是变量,否则编译器不知道如何分配内存 20. }; 21. 22. SingletonPattern* SingletonPattern::single = NULL; //告诉编译器分配内存
上面程序所示的就是一个懒汉式单例模式的实现。这里面有几点要注意的:
(1)为了让这个类所定义的所有对象共享属性,应该把属性设置为static类型,因为static类型的属性属于整个类而不是属于某个对象。
(2)为了保证单例模式,应该在全局访问点get_single()函数中加一个判断,如果对象已经被创建了,那么就直接返回这个对象,如果对象还没有被创建,那么久new创建一个对象,并返回该对象。
(3)因为是在使用到对象的时候,才去创建对象(single初始化为NULL,在全局访问点get_single被调用的时候才去创建对象),有点偷懒的感觉,所以称之为懒汉式单例模式。
我们再来测试一下,是不是真正的实现了单例
1. { 2. SingletonPattern* s1 = SingletonPattern::get_single(); //在get_single中会new一个对象 3. SingletonPattern* s2 = SingletonPattern::get_single(); 4. if (s1 == s2) 5. { 6. cout << "单例" << endl; 7. } 8. else 9. { 10. cout << "不是单例" << endl; 11. } 12. }
运行测试程序,看打印结果
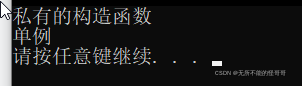
通过打印结果可以看到,创建的两个对象s1和s2是相等的,也就是说我们实现了单例,通过全局访问点获取的实例对象是同一个。
通过上面的分析,我们可以得到实现单例模式的步骤
1. 构造函数私有化;
2. 提供全局访问点;
3. 内部定义一个static静态指针指向当前类定义的对象;
😂懒汉式单例模式的缺陷
通过懒汉式单例模式,我们实现了一个类只创建一个实例对象,且只有在用到实例对象的时候,才会通过全局访问点去new创建这个对象,节省了资源。但是,懒汉式单例模式有一个致命的缺点,就是在C++的构造函数中,不能保证线程安全。什么意思呢,也就是说,在多个线程都去创建对象,调用全局访问点get_single()的时候,会面临资源竞争问题,假如在类的构造函数中增加一个延迟函数,我们第一个线程调用get_single()的时候,会进入构造函数,这时,因为延时的存在,第一个线程可能会在这里卡顿一会,假如正好这时候第二个线程也调用get_single()去创建实例对象,而第一个线程还在构造函数中延时,这样在get_single()函数中(single == NULL)这个判断条件依然成立,第二个线程也会进入构造函数。这样,两个线程创建的对象就不再是同一个对象了,也就不是单例模式了。下面,我们就详细分析多线程与懒汉式。
2.2 懒汉式单例模式与多线程(DCL与饿汉式)
😂多线程构造对象
首先,我们把类改造一下,在构造函数中加一个延时,并在类中加一个计数器来记录构造函数的调用次数
1. class SingletonPattern 2. { 3. private: 4. SingletonPattern() 5. { 6. count++; 7. Sleep(1000); //第一个线程在new的时候,如果延时还没结束 8. //第二个线程又过来new一个对象,这时候因为第一个对象还没有new出来 9. //所以single还是NULL,这样又会进入构造函数,最后总共new了两个对象 10. //这样返回的两个对象是两次new出来的,就不是单例模式了 11. printf("私有的构造函数\n"); 12. } 13. public: 14. static int get_count() 15. { 16. return count; 17. } 18. public: //构造函数被私有化了,所以应该提供一个对外访问的方法,来创建对象 19. static SingletonPattern* get_single() //只有在调用该函数的时候才会new一个对象 20. { 21. if (single == NULL) 22. { 23. single = new SingletonPattern; 24. } 25. return single; 26. } 27. private: //static 成员,类定义的所有对象共有static成员 28. static SingletonPattern* single; 29. static int count; 30. }; 31. 32. SingletonPattern* SingletonPattern::single = NULL; 33. int SingletonPattern::count = 0;
这样,一个类就定义好了。接下来,我们要在main进程中创建三个线程,每个线程都去创建一个对象,在Windows下多线程编程应包含头文件<process.h>,并且会用到线程创建函数_beginthread(),对于_beginthread()函数的使用可以直接转到源码查看函数原型
1. typedef void (__cdecl* _beginthread_proc_type )(void*); 2. typedef unsigned (__stdcall* _beginthreadex_proc_type)(void*); 3. 4. _ACRTIMP uintptr_t __cdecl _beginthread( 5. _In_ _beginthread_proc_type _StartAddress, 6. _In_ unsigned _StackSize, 7. _In_opt_ void* _ArgList 8. );
该函数包含三个参数,分别代表如下含义:
第一个参数是_beginthread_proc_type,通过上面的typedef可知,它是一个回调函数(函数指针),指向新开辟的线程的起始地址;
第二个参数_StackSize是新线程的堆栈大小,可以直接给个0,表示和主线程共用堆栈;
第三个参数_ArgList是一个参数列表,它表示要传递给新开辟线程的参数,新线程没有参数的话可以传入NULL;
函数返回值可以理解为创建好的线程的句柄。
首先搭建测试程序如下
1. { 2. int i = 0, ThreadNum = 3; 3. HANDLE h_thread[3]; 4. 5. for (i = 0; i < ThreadNum; i++) 6. { 7. h_thread[i] = (HANDLE)_beginthread(_cbThreadFunc, 0, NULL); 8. } 9. 10. for (i = 0; i < ThreadNum; i++) 11. { 12. WaitForSingleObject(h_thread[i], INFINITE); //windows 下的等待 13. //thread_join //Linux 下的等待函数 14. //等待子线程结束,如果不等待子线程结束主进程就死掉的话,子线程也会随之死掉,所以主进程挂起等待 15. } 16. 17. cout << "子线程已结束" << endl; 18. }
这里用到了一个函数WaitForSingleObject(),它用于等待子线程结束。因为子线程是依附于主线程存在的(共用堆栈、内存四区),如果子线程还没结束主线程就结束了,那么子线程也将不复存在,所以需要等待子线程结束后,主线程才能结束。该函数类似于Linux中的thread_join函数。
搭建好测试程序后,在定义一个线程函数
1. void _cbThreadFunc(void* arc) 2. { 3. DWORD id = GetCurrentThreadId(); //获取当前线程ID 4. 5. int num = SingletonPattern::get_single()->get_count(); //创建对象 6. 7. printf("\n构造函数调用次数:%d\n", num); //调用了3次构造函数 --- 不是单例 8. printf("当前线程是:%d\n", id); 9. //cout << "当前线程是:" << id << endl; //会有问题 10. }
编译运行测试函数
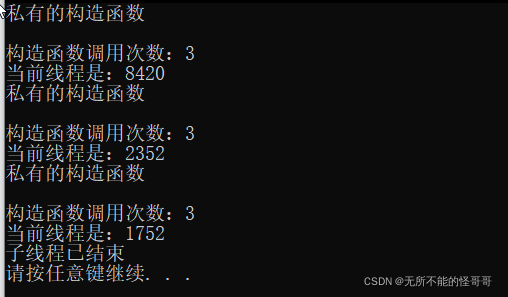
可以看到,构造函数调用了三次,每个线程都创建了一个新的对象,已经不再是单例模式了。对于这个问题的解决主要有两种,下面分别介绍。
😂饿汉式单例模式
第一种解决方法就是在类中定义static SingletonPattern*指针的时候就创建一个对象,在全局访问点get_single()直接返回创建好的对象,因为对象早就提前创建好了,这样即使多个线程调用创建对象所得到的也是同一个对象。因为对象还没使用就创建好了,所以叫做饿汉式单例模式。
上面的测试程序不用修改,我们只需要修改类即可
1. class SingletonPattern 2. { 3. private: 4. SingletonPattern() 5. { 6. count++; 7. Sleep(1000); 8. printf("私有的构造函数\n"); 9. } 10. public: 11. static int get_count() 12. { 13. return count; 14. } 15. public: 16. static SingletonPattern* get_single() 17. { 18. return single; 19. } 20. private: 21. static SingletonPattern* single; 22. static int count; 23. }; 24. 25. //SingletonPattern* SingletonPattern::single = NULL; 26. SingletonPattern* SingletonPattern::single = new SingletonPattern; //饿汉式单例,一开始就new了一个对象 27. int SingletonPattern::count = 0;
再次运行前面的测试函数,看打印结果

从打印结果可以看到,三个不同的线程只调用了一次类的构造函数,得到的是同一个对象。
😂DCL(double-checked locking)
既然多个线程会竞争资源,那么如何才能防止多个线程之间的竞争呢?最简单的方法就是对临界区资源加一个锁🔒,当一个线程持有锁的时候,其他线程挂起等待锁的释放,只有持有锁的线程才能进入临界资源,这就解决了多线程资源竞争的问题(此处涉及到多线程同步问题)。这里还有一个问题,当我们第一次判断(single == NULL)后,如果之前没有创建对象,那么就进入下面的临界区
1. if (single == NULL) 2. { 3. cs.Lock(); 4. single = new SingletonPattern; 5. cs.Unlock(); 6. }
当第一个线程创建完对象后释放了锁,第二个线程进入临界区又创建了一个对象,这也违反了单例原则。所以应该加入一个二次检查,如果第一个线程已经创建了对象(指针不为NULL),那么第二个线程即使获取了锁,也不再创建新的对象,而是直接使用第一个线程创建的对象,这就是二次检测的原因。
1. static SingletonPattern* get_single() 2. { 3. if (single == NULL) //double check 4. { //因为在这之前并没有保护机制,所以三个线程都有可能执行到这一步 5. cs.Lock(); 6. if (single == NULL) //所以需要二次检查,进入临界区后再一次判断 7. { 8. single = new SingletonPattern; 9. } 10. cs.Unlock(); 11. } 12. return single; //静态成员属于整个类,没有this指针 13. }
对全局访问点get_single()修改过后,再次运行测试函数

3. 总结
单例模式主要有懒汉式和饿汉式两种实现,饿汉式不会有线程安全的问题,但是提前构造对象占用了一定的资源,如果对内存要求较低的场景可以使用饿汉式实现;懒汉式应使用DCL机制来避免多线程竞争资源的问题,并且懒汉式可以在需要使用对象的时候才去创建对象,节省了资源。
🚀二、工厂模式
1. 简单工厂模式
1.1 什么是简单工厂模式
Simple Factory Pattern,简单工厂模式,也叫做静态工厂方法模式(Static Factory Method Pattern)。属于类的创建型设计模式的一种,通过一个专门的类(工厂)来负责创建其他类的实例(具体产品),这些类都有一个共同的抽象类作为基类(抽象产品)。
简单工厂模式中的三个角色
- 工厂角色:Creator,用于创建所有的具体产品实例,是简单工厂模式的核心。工厂类直接被外部调用,并提供一个静态方法,根据传入的参数不同来创建不同产品类的实例。
- 抽象产品角色:Product,它是工厂类所创建的所有实例的类的共同基类,用于描述产品的公共接口。它和工厂类是依赖的关系(作为工厂类静态方法的返回值)。
- 具体产品角色:Concrete Product,它是抽象产品类的子类,也是工厂类要创建的目标类。

1.2 简单工厂模式实例
假设我们要生产一个手机,由苹果手机,小米手机,首先我们应该定义一个抽象产品类PhoneInterface
1. //抽象产品类 2. class PhoneInterface 3. { 4. public: 5. virtual void print_brand() = 0; 6. };
然后根据抽象产品类来实现具体的产品类,假设我们有苹果手机和小米手机
1. //具体产品类 2. class apple : public PhoneInterface 3. { 4. public: 5. virtual void print_brand() 6. { 7. cout << "苹果手机" << endl; 8. } 9. }; 10. 11. 12. class XiaoMi : public PhoneInterface 13. { 14. public: 15. virtual void print_brand() 16. { 17. cout << "小米手机" << endl; 18. } 19. };
接下来就应该创建一个工厂类,在工厂类中定义了创建所有产品类实例的逻辑,以及选择创建哪个产品类实例的判断。
1. //工厂类 2. class Factory 3. { 4. public: 5. PhoneInterface* production_phone(int flag) 6. { 7. PhoneInterface* pTemp = NULL; 8. switch (flag) //所有的生产都集中在一个工厂中,每次修改都要在类中修改,不符合开闭原则 9. { 10. case 1: 11. pTemp = new apple; 12. break; 13. case 2: 14. pTemp = new XiaoMi; 15. break; 16. default: 17. pTemp = NULL; 18. break; 19. } 20. return pTemp; 21. } 22. };
这样,客户就可以通过工厂类来生产客户所需要的手机,并可以成功完成手机型号的生产。
1. int main() 2. { 3. Factory* pF = NULL; 4. PhoneInterface* pPhone = NULL; 5. 6. pF = new Factory; 7. pPhone = pF->production_phone(1); 8. pPhone->print_brand(); 9. delete pPhone; 10. 11. pPhone = pF->production_phone(2); 12. pPhone->print_brand(); 13. delete pF; 14. delete pPhone; 15. 16. system("pause"); 17. return 0; 18. }

1.3 简单工厂模式的优缺点
优点:工厂类是整个简单工厂模式的核心,通过工厂类对外隐藏了创建实例的具体细节,用户直接使用工厂类去创建自己需要的实例,而不必关心实例是如何创建出来的,也不必关心内部结构是怎么组织的。
缺点:正所谓成也萧何,败也萧何,简单工厂模式的优点来源于工厂类,其缺点也来源于工厂类,因为所有实例的创建逻辑都集中在工厂类中,一旦工厂出现问题,所有实例的创建都将无法进行,并且增删产品都要去修改工厂类来实现,不符合开闭原则。因为简单工厂模式不符合开闭原则,所以它不是标准的设计模式。
2. 工厂模式
2.1 什么是工厂模式
factory pattern,工厂模式同样属于类的创建型模式,也成为多态工厂模式。工厂模式对简单工厂模式不遵守开闭原则这一缺点做了修正,工厂模式多出了一个抽象工厂角色作为接口,实际的生产工作在具体工厂类中实现,这样进一步的抽象化使得工厂方法模式可以使系统在不修改具体工厂角色的情况下引进新的产品。简单来说,就是把简单工厂中的工厂细分为不同产品的工厂,每个工厂生产一种产品。
- 抽象工厂角色(Creator),所有具体工厂都要实现这个接口;
- 具体工厂(Concrete Creator),负责实例化具体产品对象;
- 抽象角色(Product),和简单工厂模式一样,它是工厂类所创建的所有实例的类的共同基类,用于描述产品的公共接口。
- 具体产品角色(Concrete Product),具体工厂类所要实例化的对象。

2.2 工厂模式实例
抽象产品类和具体产品类不变
1. //抽象产品类 2. class PhoneInterface 3. { 4. public: 5. virtual void print_brand() = 0; 6. }; 7. 8. //苹果手机产品实现 9. class apple : public PhoneInterface 10. { 11. public: 12. virtual void print_brand() 13. { 14. cout << "苹果手机" << endl; 15. } 16. }; 17. 18. //小米手机产品实现 19. class XiaoMi : public PhoneInterface 20. { 21. public: 22. virtual void print_brand() 23. { 24. cout << "小米手机" << endl; 25. } 26. };
首先定义一个抽象的工厂类,来定义具体工厂的统一接口
1. //抽象工厂类 2. class FactoryInterface 3. { 4. public: 5. virtual PhoneInterface* production_phone() = 0; 6. };
然后定义一个苹果手机工厂,用于生产苹果手机,再定义一个小米手机工厂,用于生产苹果手机,那么这两个工厂就是具体工厂角色
1. //苹果手机工厂 2. class AppleFactory : public FactoryInterface 3. { 4. public: 5. virtual PhoneInterface* production_phone() 6. { 7. return new apple; 8. } 9. }; 10. 11. //小米手机工厂 12. class XiaomiFactory : public FactoryInterface 13. { 14. public: 15. virtual PhoneInterface* production_phone() 16. { 17. return new XiaoMi; 18. } 19. };
当我们需要生产手机产品的时候,直接使用苹果手机工厂去创建苹果手机对象,用小米手机工厂去创建小米手机对象即可。假如,我们增加需求,需要华为手机,这时只要增加一个华为工厂和华为手机的实现类即可,工厂的抽象类和手机的抽象类都不用动,符合开闭原则。
1. int main() 2. { 3. FactoryInterface* pFactory = NULL; 4. PhoneInterface* pPhone = NULL; 5. 6. //要生产一台苹果手机 7. //先创建一个苹果手机工厂 8. pFactory = new AppleFactory; 9. pPhone = pFactory->production_phone(); 10. pPhone->print_brand(); 11. delete pPhone; 12. delete pFactory; 13. 14. //生产一个小米手机 15. pFactory = new XiaomiFactory; 16. pPhone = pFactory->production_phone(); 17. pPhone->print_brand(); 18. delete pPhone; 19. delete pFactory; 20. 21. system("pause"); 22. return 0; 23. }

2.3 简单工厂与工厂模式对比
简单工厂模式把所有的创建逻辑都放在了一个工厂类中,而工厂模式则是提供了一个抽象的工厂接口,由具体工厂去创建产品实例,极大的方便了增加产品,删除产品等操作,且很好的符合了开闭原则,简单工厂模式每次增删产品都要直接修改工厂类,而工厂模式只需要增加一个具体工厂类和一个具体产品类就可以完成功能的扩充。
在简单工厂模式中,客户端是面向具体工厂编程,增加产品要在工厂类中修改代码;而工厂模式是面向抽象工厂编程,增加产品只要创建一个新的具体工厂就可以了,这就是面向抽象类编程。
🚀三、抽象工厂模式
1. 什么是抽象工厂模式
Abstract Factory Pattern,抽象工厂模式。假设在前面的工厂模式下,我们对产品线提出了进一步的要求,因为手机既要在国内销售,又要在国外销售,所以同一品牌手机增加了大陆版、美版、港版等产品线。如果使用工厂模式,每一个品牌的手机,每一个版本的手机都要单独一个具体工厂来创建,很不方便‘这时候,就有了抽象工厂模式,抽象工厂模式可以创建一个产品族(包含多条产品线)。抽象工厂模式用官方语言描述就是,一种为访问类提供一个创建一组相关或相互依赖对象的接口,且访问类无须指定所要产品的具体类就能得到同族的不同等级的产品的模式结构。 她也有四种角色,和工厂模式一样。
- 抽象工厂角色(Creator),所有具体工厂都要实现这个接口,可以创建多个不同等级的产品(多条产品线);
- 具体工厂(Concrete Creator),负责实例化具体产品对象,多条产品线;
- 抽象角色(Product),和简单工厂模式一样,它是工厂类所创建的所有实例的类的共同基类,用于描述产品的公共接口。
- 具体产品角色(Concrete Product),具体工厂类所要实例化的对象。

2. 抽象工厂模式实例
首先创建一个抽象手机类
1. //抽象产品 2. class PhoneInterface 3. { 4. public: 5. virtual void print_brand() = 0; 6. };
根据抽象手机类定义大陆版苹果手机类,美版苹果手机类,大陆版小米手机类,美版小米手机类
1. //美版的苹果手机 2. class UsApple : public PhoneInterface 3. { 4. public: 5. virtual void print_brand() 6. { 7. cout << "美版的苹果手机" << endl; 8. } 9. }; 10. 11. //大陆版小米手机 12. class ChinaXiaomi : public PhoneInterface 13. { 14. public: 15. virtual void print_brand() 16. { 17. cout << "大陆版本的小米手机" << endl; 18. } 19. }; 20. 21. //美版的小米手机 22. class UsXiaomi : public PhoneInterface 23. { 24. public: 25. virtual void print_brand() 26. { 27. cout << "美版的小米手机" << endl; 28. } 29. };
接下来定义一个抽象工厂类,该抽象工厂类中包含两个接口,一个是苹果手机生产线,一个是小米手机生产线
1. //抽象工厂 2. class FactoryInterface 3. { 4. public: 5. //产品线1:苹果手机 6. virtual PhoneInterface* production_apple() = 0; 7. //产品线2:小米手机 8. virtual PhoneInterface* production_xiaomi() = 0; 9. };
根据抽象工厂来定义两个具体工厂,一个是大陆版手机工厂,一个是美版手机工厂
1. //生产大陆版本手机的工厂 2. class ChinaFactory : public FactoryInterface 3. { 4. public: 5. //产品线1:苹果手机 6. virtual PhoneInterface* production_apple() 7. { 8. return new ChinaApple; 9. } 10. //产品线2:小米手机 11. virtual PhoneInterface* production_xiaomi() 12. { 13. return new ChinaXiaomi; 14. } 15. }; 16. 17. //生产美版手机的工厂 18. class UsFactory : public FactoryInterface 19. { 20. public: 21. //产品线1:苹果手机 22. virtual PhoneInterface* production_apple() 23. { 24. return new UsApple; 25. } 26. //产品线2:小米手机 27. virtual PhoneInterface* production_xiaomi() 28. { 29. return new UsXiaomi; 30. } 31. };
客户可以直接使用两个具体工厂去生产大陆版苹果/小米手机或美版苹果/小米手机
1. int main() 2. { 3. FactoryInterface* pFactory = NULL; 4. PhoneInterface* pPhone = NULL; 5. 6. //使用大陆版手机的工厂 7. cout << "======大陆版手机工厂======" << endl; 8. pFactory = new ChinaFactory; 9. //生产大陆版苹果手机 10. pPhone = pFactory->production_apple(); 11. pPhone->print_brand(); 12. delete pPhone; 13. //生产大陆版小米手机 14. pPhone = pFactory->production_xiaomi(); 15. pPhone->print_brand(); 16. delete pPhone; 17. delete pFactory; 18. 19. //使用美版手机的工厂 20. cout << "======美版手机工厂======" << endl; 21. pFactory = new UsFactory; 22. pPhone = pFactory->production_apple(); 23. pPhone->print_brand(); 24. delete pPhone; 25. pPhone = pFactory->production_xiaomi(); 26. pPhone->print_brand(); 27. delete pPhone; 28. delete pFactory; 29. 30. system("pause"); 31. return 0; 32. }

3. 抽象工厂类总结
当增加一个新的产品族时,只需要增加一个新的具体工厂即可,如果整个产品族只有一个等级的产品,比如只有一条生产线,抽象工厂就和工厂模式一样了。




