

💡 作者: 韩信子@ ShowMeAI
📘 数据分析实战系列: https://www.showmeai.tech/tutorials/40
📘 本文地址: https://www.showmeai.tech/article-detail/411
📢 声明:版权所有,转载请联系平台与作者并注明出处
📢 收藏 ShowMeAI查看更多精彩内容
💡 引言

可视化是EDA的基础。当面对一个新的、未知的数据集时,视觉检查使我们能够了解可用的信息,绘制一些有关数据的模式,并诊断出我们可能需要解决的几个问题。在这方面,📘Pandas Profiling 一直是每个数据科学家工具箱中不可或缺的瑞士刀,可以帮助我们快速生成数据摘要报告,包括数据概览、变量属性、数据分布、重复值和其他指标。它能够在可视化中呈现这些信息,以便我们更好地理解数据集。但如果我们能够比较两个数据集呢,有没有快速的方式可以实现?

在本篇博客文章中,ShowMeAI将介绍如何利用 Pandas Profiling 的比较报告功能来提升数据探索分析 (EDA) 流程。我们会介绍到如何使用 Pandas Profiling 比较报告功能来比较两个不同的数据集,这可以帮助我们更快地对比分析数据,获取分布差异,为后续做准备。
我们本次用到的数据集是 🏆Kaggle 的 HCC 数据集,大家可以通过 ShowMeAI 的百度网盘地址下载。
🏆 实战数据集下载(百度网盘):公众号『ShowMeAI研究中心』回复『实战』,或者点击 这里 获取本文 [[42]Pandas Profiling:使用高级EDA工具对比分析2个数据集](https://www.showmeai.tech/article-detail/411) 『HCC 数据集』
⭐ ShowMeAI官方GitHub:https://github.com/ShowMeAI-Hub

关于更多数据自动化探索工具,可以参考ShowMeAI过往文章 📘自动化数据分析 (EDA) 工具库大全。
💡 全自动数据EDA工具 Pandas Profiling 功能回顾
我们回顾一下 Pandas Profiling 的安装与使用方式:
# 通过pip安装
pip install pandas-profiling==3.5.0如果我们需要对 hcc 数据集进行分析,参考代码如下:
import pandas as pd
from pandas_profiling import ProfileReport
# Read the HCC Dataset
df = pd.read_csv("hcc.csv")
# Produce the data profiling report
original_report = ProfileReport(df, title='Original Data')
original_report.to_file("original_report.html")我们会得到非常清晰的数据分析结果报告,如下是报告的头部信息:

Alerts部分对数据进行分析后,给出了4种主要类型的潜在分析结果,包含可能有的风险和处理方式:
Duplicates:数据中有 4 个重复行;Constant:'O2'是常量字段,求职999;High Correlation:有强相关性的几个特征;Missing:“Ferritin”字段存在缺失值。
💡 数据处理
这对这些问题我们可以做一些处理。
💦 删除重复行
在数据集中,有些特征非常具体,涉及到个人的生物测量值,比如血红蛋白、MCV、白蛋白等。所以,很难有多个患者报告所有特征的相同精确值。因此,我们可以从数据中删除这些重复项。
# Drop duplicate rows
df_transformed = df.copy()
df_transformed = df_transformed.drop_duplicates()💦 删除不相关的特征
在数据分析过程中,有些特征可能不具有太多价值,比如 O2 常数值。删除这些特征将有助于模型的开发。
# Remove O2
df_transformed = df_transformed.drop(columns='O2')💦 缺失数据插补
数据插补是用于处理缺失数据的方法。它允许我们在不删除观察值的情况下填补缺失值。均值插补是最常见和最简单的统计插补技术,它使用特征的均值来填充缺失值。我们将使用均值插补来处理 HCC 数据集中的缺失数据。
# Impute Missing Values
from sklearn.impute import SimpleImputer
mean_imputer = SimpleImputer(strategy="mean")
df_transformed['Ferritin'] = mean_imputer.fit_transform(df_transformed['Ferritin'].values.reshape(-1,1))💡 数据并行对比分析
下面我们就进入高级功能部分了!我们在对1份数据分析后,如果希望有另外一份数据能够比对分析,怎么做呢。下面我们以处理前后的数据为例,来讲解这个分析的实现方式:
transformed_report = ProfileReport(df_transformed, title="Transformed Data")
comparison_report = original_report.compare(transformed_report)
comparison_report.to_file("original_vs_transformed.html") 最后的对比报告如下:

|
我们可以从数据集概述中立即了解什么?
- 转换后的数据集包含更少的分类特征("O2"已被删除)
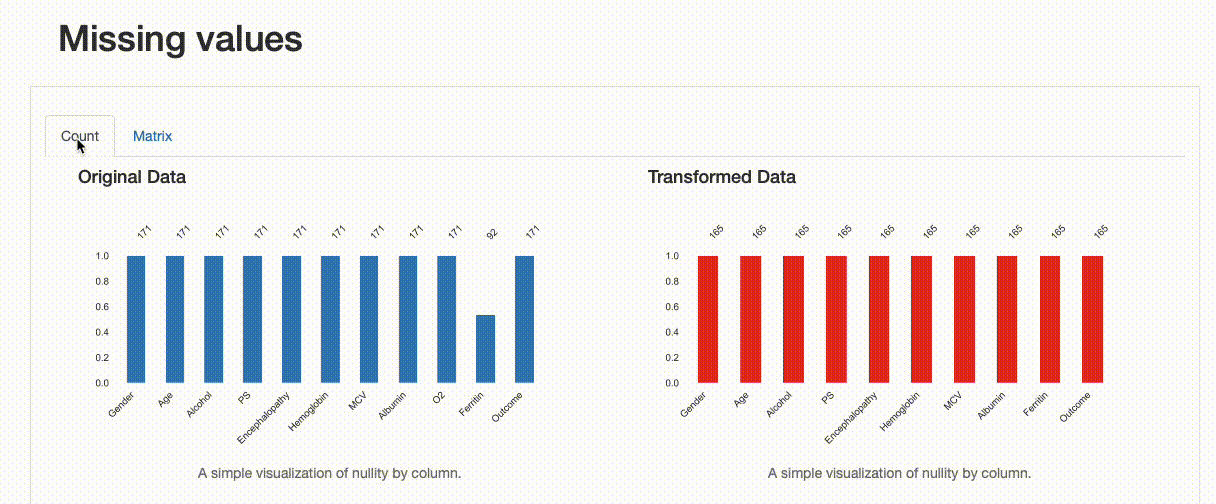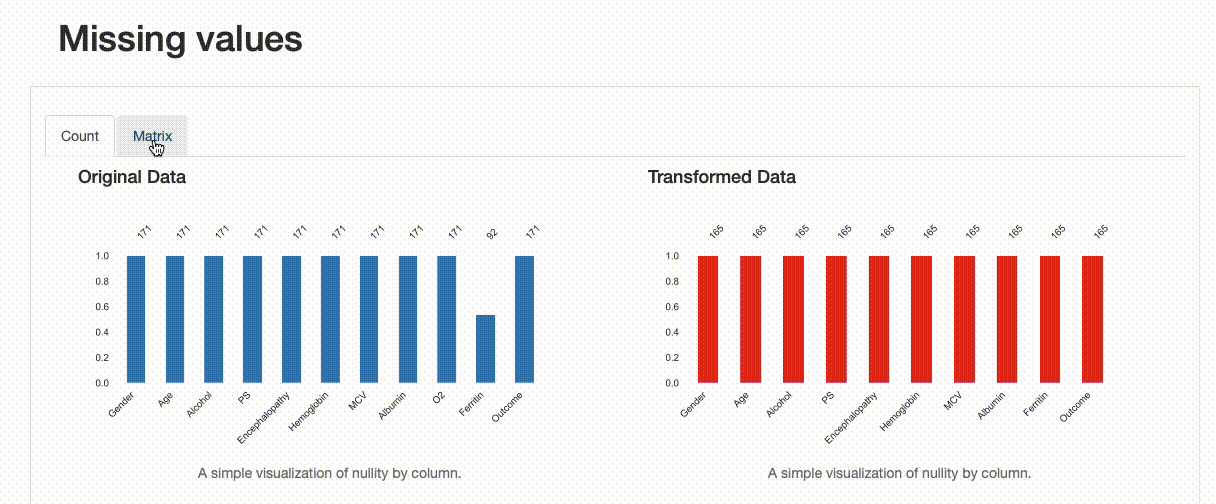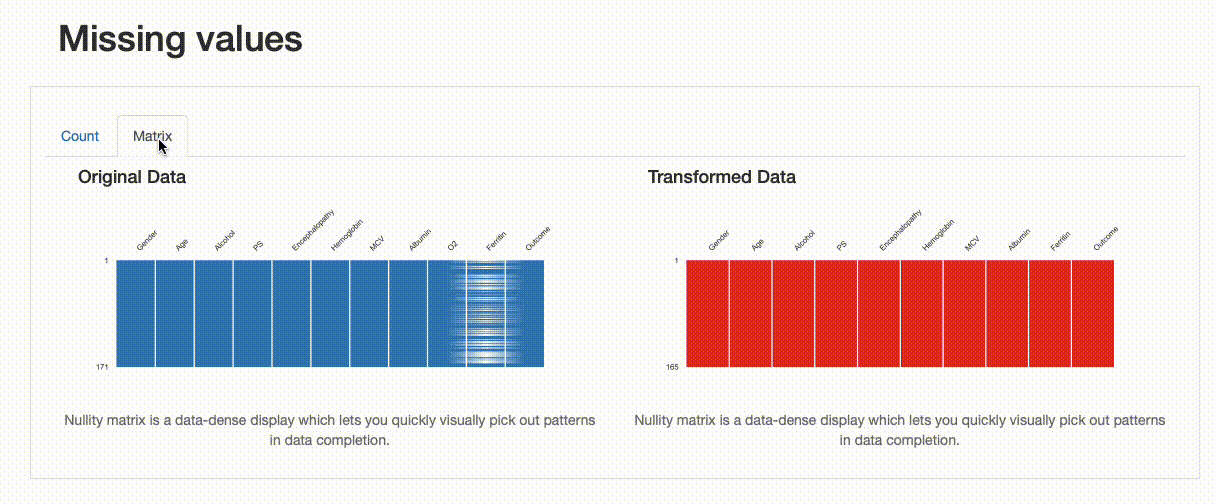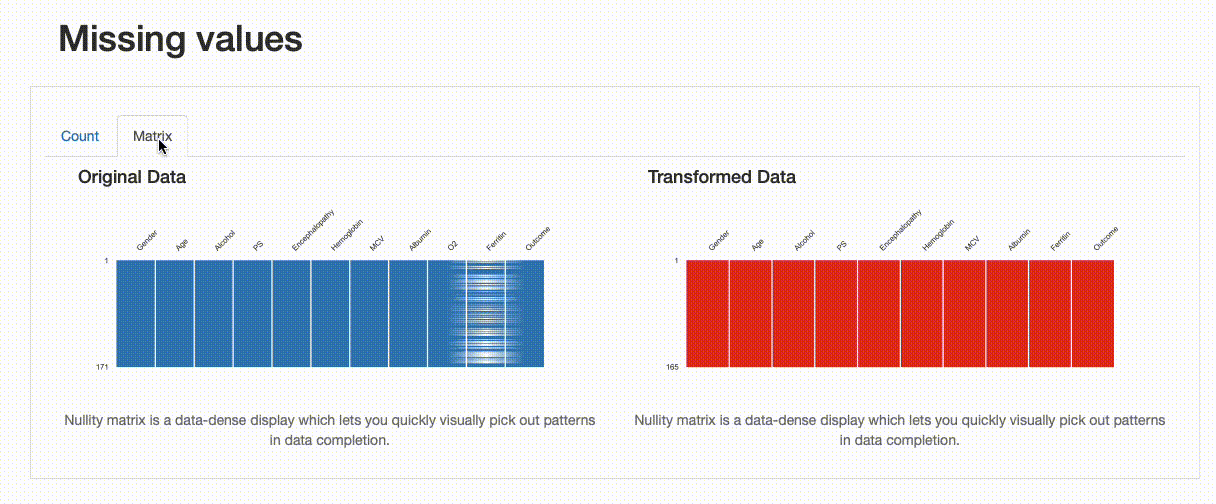
- 165个观察值(而原来的171个包括重复项)
- 没有缺失值(与原始数据集中的79个缺失观察值形成对比)
这种转变如何影响我们的数据质量?这些决定是否很好?我们发现在删除重复记录方面,没有特别的影响,数据缺失和数据分布有一些变化,如下图所示:
|
从上述图解中,可以看出一些信息,比如对于“铁蛋白”字段,插补数据的均值估算值导致原始数据分布被扭曲。这样处理可能是有问题的,我们应该避免使用均值估算来替换缺失值。在这种情况下,应该使用其他方法来处理缺失值,例如删除缺失值或使用其他统计方法来估算缺失值。

也可以通过相互作用和相关性的可视化来观察到这一点,在“铁蛋白”与其他特征之间的关系中,会出现不一致的相互作用模式和更高的相关值。

上图为铁蛋白与年龄之间的相互作用,估算值显示在对应于平均值的垂直线上。

上图为相关性情况对比,铁蛋白相关值似乎在数据插补后增加。
💡 总结
在本篇内容中,ShowMeAI讲解了 pandas-profiling 工具对不同数据进行对比分析的方法,我们用处理前后的数据做了一个简单的讲解,实际这个方法也可以用到训练集和测试集的对比中,用于发现数据漂移等问题。

关于数据漂移,可以参考ShowMeAI的文章 📘机器学习数据漂移问题与解决方案。
参考资料
- 📘 Pandas Profiling
- 📘 自动化数据分析 (EDA) 工具库大全:https://showmeai.tech/article-detail/284
- 📘 机器学习数据漂移问题与解决方案:https://showmeai.tech/article-detail/331
推荐阅读
🌍 数据分析实战系列:https://www.showmeai.tech/tutorials/40
🌍 机器学习数据分析实战系列:https://www.showmeai.tech/tutorials/41
🌍 深度学习数据分析实战系列:https://www.showmeai.tech/tutorials/42
🌍 TensorFlow数据分析实战系列:https://www.showmeai.tech/tutorials/43
🌍 PyTorch数据分析实战系列:https://www.showmeai.tech/tutorials/44
🌍 NLP实战数据分析实战系列:https://www.showmeai.tech/tutorials/45
🌍 CV实战数据分析实战系列:https://www.showmeai.tech/tutorials/46
🌍 AI 面试题库系列:https://www.showmeai.tech/tutorials/48





