问题一:Flink sqlclient在提交的时候是不是就没指定这几个日志文件啊?
Flink 发行版在 conf 目录中附带了以下 log4j 配置文件,如果启用了 Log4j 2,则会自动使用如下文件:
log4j-cli.properties:Flink 命令行使用(例如 flink run);
log4j-session.properties:Flink 命令行在启动基于 Kubernetes/Yarn 的 Session 集群时使用(例如 kubernetes-session.sh/yarn-session.sh);
log4j-console.properties:Job-/TaskManagers 在前台模式运行时使用(例如 Kubernetes);
log4j.properties: Job-/TaskManagers 默认使用的日志配置。sqlclient在提交的时候是不是就没指定这几个日志文件啊?
参考答案:
楼主你好,Flink SQL Client在提交时没有指定上述几个日志文件。Flink SQL Client在提交作业时,使用的是默认的日志配置,默认的日志配置可以在Flink的安装目录下的conf/log4j.properties文件中找到。在Flink中,作业的日志输出是通过JobManager和TaskManager的日志来完成的。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/582468
问题二:Flink这个状态是全局的还是 每个并行度一份呀?
Flink这个状态是全局的还是 每个并行度一份呀? 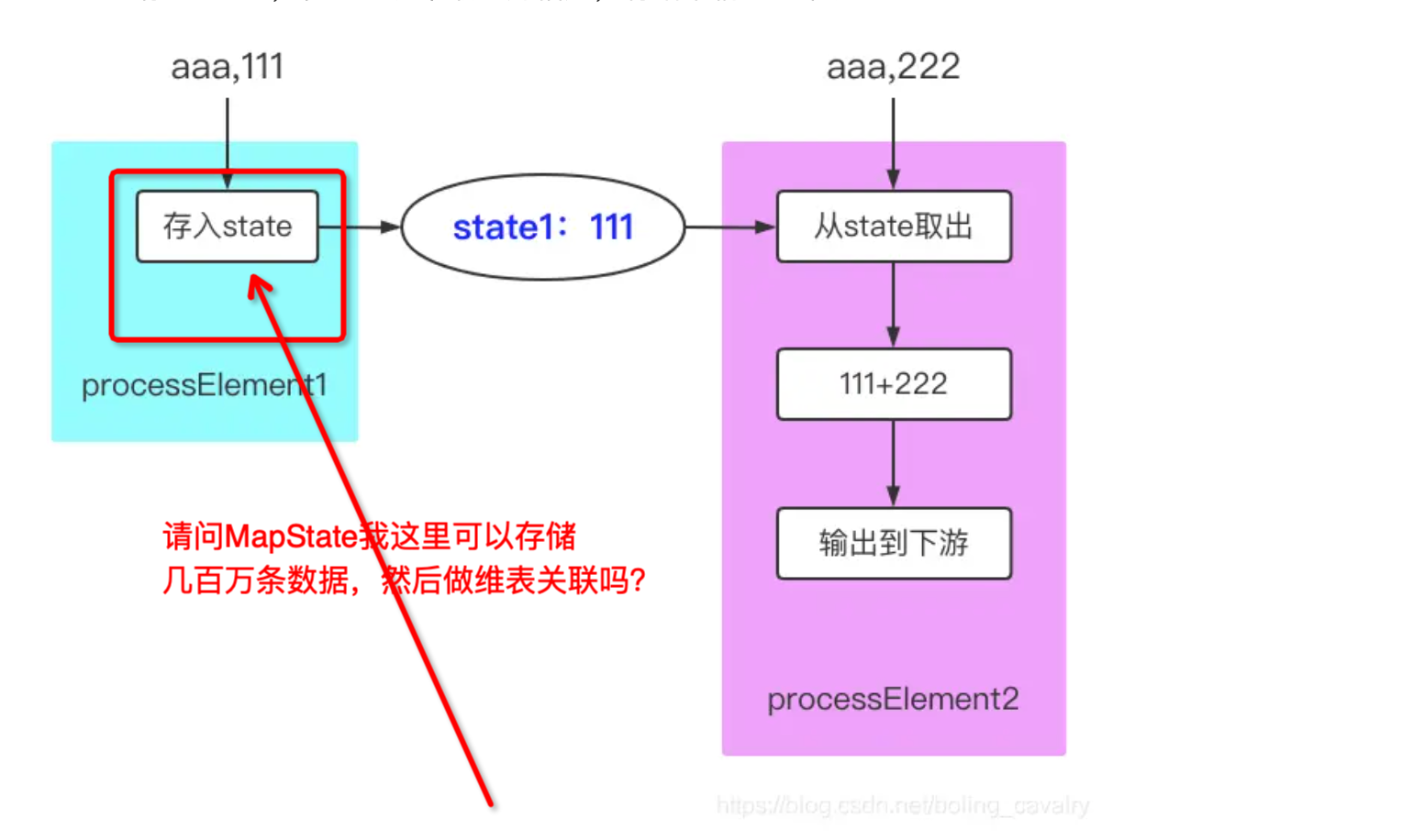
参考答案:
楼主你好,据我所知,在阿里云Flink中,存储在状态中的数据可以是全局的或者每个并行度一份,这取决于你在程序中如何定义和使用状态。
对于MapState,它是一种键值对的状态数据结构,可以存储大量的数据。在使用MapState存储几百万条数据进行维表关联时,可以考虑对数据进行预聚合或者压缩,以减少状态的大小,还有就是调整并行度和资源分配,确保每个TaskManager有足够的内存来存储MapState。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/582467
问题三:Flink有没有就是用sqlclient提交到yarnperjob模式后。有没有人遇到这个问题?
Flink有没有就是用sqlclient提交到yarnperjob模式后。web界面上拿不到日志,有没有人遇到这个问题,求大佬解决? 
参考答案:
是这样的,Flink 的 SQL Client 目前不支持提交 Flink 作业到 Yarn Per-Job 模式。
如果你需要提交 Flink 作业到 Yarn Per-Job 模式,可以使用 Flink 的 REST API 或 CLI。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/582466
问题四:请问Flink中SupportsDeletePushDown和SupportsRowL的区别是什么?
请问Flink中SupportsDeletePushDown和SupportsRowLevelDelete的区别是什么?
参考答案:
楼主你好,在阿里云 Flink 中,SupportsDeletePushDown 和 SupportsRowLevelDelete 是用于处理删除操作的接口,它们的区别如下:
- SupportsDeletePushDown:
- SupportsDeletePushDown 是 TableSource 接口中定义的方法,用于在数据源级别支持删除操作的下推。
- 通过实现 SupportsDeletePushDown 接口,可以提供在数据源层面执行删除操作的能力,例如将删除操作下推到底层存储系统执行,从而提高删除操作的效率。
- 对于支持删除操作下推的数据源,Flink 可以通过 optimize() 方法将删除操作下推到数据源端进行处理。
- SupportsRowLevelDelete:
- SupportsRowLevelDelete 是 TableSink 接口中定义的方法,用于在数据接收端支持行级别的删除操作。
- 通过实现 SupportsRowLevelDelete 接口,可以在数据接收端(通常是目标数据库)支持对行级别的数据进行删除操作。这样,当 Flink 处理删除操作时,可以将删除的行信息发送到数据接收端进行删除操作,以保持数据一致性。
- 支持 SupportsRowLevelDelete 接口的 TableSink 在接收到删除操作时,会将删除的行信息应用到目标数据库中。
SupportsDeletePushDown 是在数据源级别支持删除操作下推,而 SupportsRowLevelDelete 是在数据接收端支持行级别删除操作。它们都提供了对删除操作的支持,但是在不同的层面进行处理。
注意:本回答参考了阿里云Flink官方文档。
关于本问题的更多回答可点击进行查看:
https://developer.aliyun.com/ask/582465
问题五:Flink 1.18 sql客户端启动异常,大家知道怎么处理吗?
Flink 1.18 sql客户端启动异常,大家知道怎么处理? 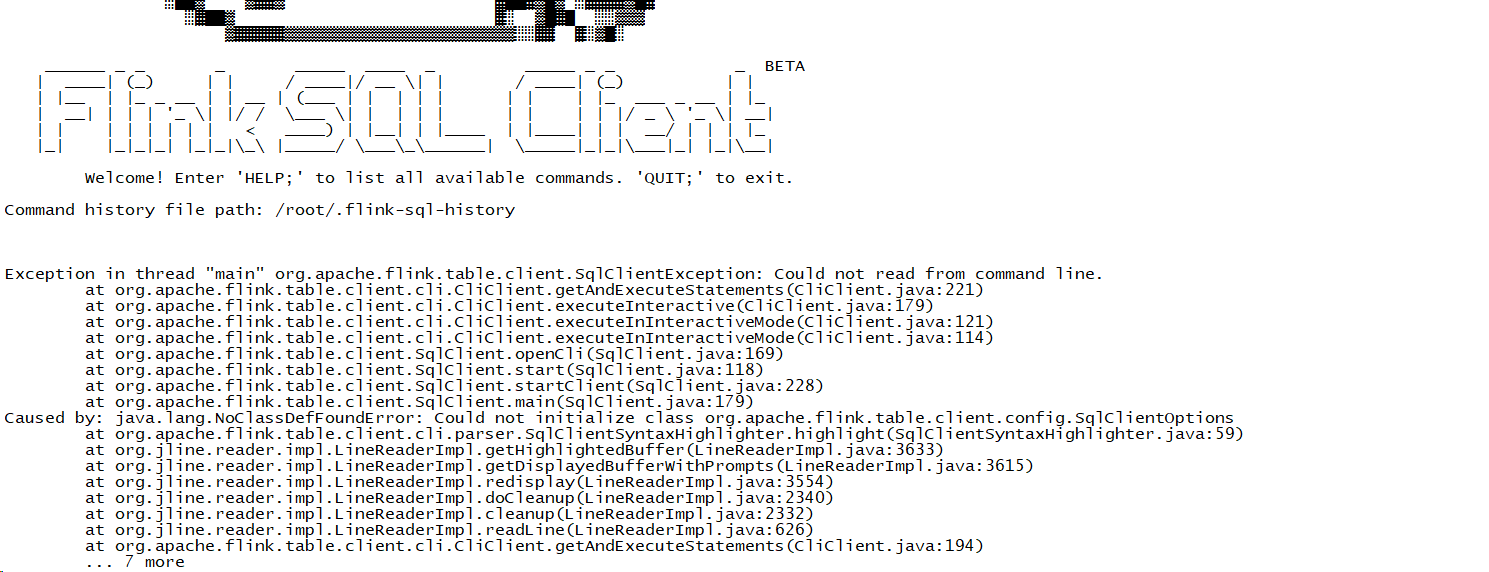
参考答案:
Flink SQL 客户端启动异常,可能有以下几个原因:
JDK 版本不兼容。Flink SQL 客户端要求 JDK 版本为 1.8 或以上。
Flink 版本不兼容。Flink SQL 客户端要求 Flink 版本为 1.18 或以上。
配置文件错误。请检查配置文件的正确性,尤其是 sql.client.jars 配置项。
其他错误。如果以上原因都排查过了,仍无法解决问题,请联系 Flink 官方支持寻求帮助。
关于本问题的更多回答可点击进行查看:
