
DuHz

已加入开发者社区1294天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

初入江湖
初入江湖




粉丝







技术能力
兴趣领域
- 算法
- 物联网
- 边缘计算
- 传感器
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
暂无精选文章
暂无更多信息
2025年09月
-
09.13 22:16:18
 发表了文章
2025-09-13 22:16:18
发表了文章
2025-09-13 22:16:18
嵌入式AI领域关键技术的理论基础
本内容系统讲解嵌入式AI领域关键技术的数学理论基础,涵盖神经网络量化、剪枝、知识蒸馏与架构搜索的核心原理。深入探讨量化中的信息论与优化方法、稀疏网络的数学建模、蒸馏中的信息传递机制,以及神经架构搜索的优化框架,为在资源受限环境下实现高效AI推理提供理论支撑。 -
09.13 21:14:31发表了文章
2025-09-13 21:14:31
用于最近邻搜索的乘积量化——论文阅读
本文介绍了用于最近邻搜索的乘积量化方法,通过将高维向量划分为低维子空间并分别量化,实现高效近似欧氏距离计算。该方法结合非对称距离计算(ADC)与倒排文件系统(IVFADC),在保持高搜索精度的同时显著降低计算复杂度和内存占用。实验表明,乘积量化在SIFT和GIST描述符上的表现优于现有方法,适用于大规模图像检索等应用。
-
09.13 20:42:07发表了文章
2025-09-13 20:42:07
改进的激光方法与更快的矩阵乘法——论文阅读
Josh Alman与Virginia Vassilevska Williams在2021年提出改进的激光方法,将矩阵乘法指数ω的上界从2.37287降至2.37286。虽改进微小,但标志着自1986年以来核心技术的重要突破,展示了激光方法的潜力与优化空间。 -
09.13 20:22:01发表了文章
2025-09-13 20:22:01
论文阅读——使用分区截断奇异值分解滤波的近似卷积
本文提出了一种基于分区截断奇异值分解(PTSVD)的近似卷积方法,旨在降低大型卷积运算的计算复杂度与内存占用,适用于音频信号处理等实时应用场景。该方法通过将脉冲响应分段并进行奇异值分解,仅保留主要奇异值对应的向量进行重构,从而实现高效滤波。实验表明,该方法在保持高精度的同时显著降低了运算量和存储需求,尤其适用于长房间脉冲响应的处理。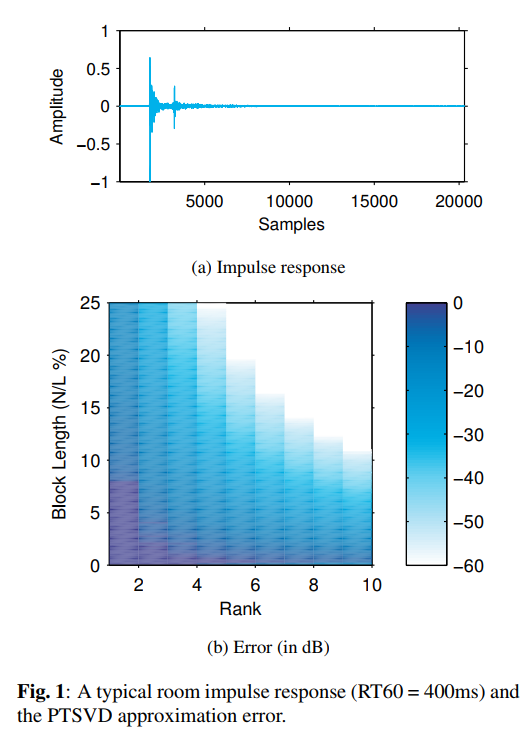
-
09.13 20:07:13发表了文章
2025-09-13 20:07:13
无乘法器的多常数乘法——论文简读
本文研究了无乘法器的多常数乘法(MCM)问题,旨在通过加法、减法和移位操作高效实现多个常数与变量的乘法,在降低硬件成本和功耗方面具有重要意义。
-
09.12 00:10:11发表了文章
2025-09-12 00:10:11
EdgeShard:通过协作边缘计算实现高效的大语言模型推理——论文解读
EdgeShard是一种基于协作边缘计算的大语言模型(LLM)推理框架,旨在解决LLM在云端部署面临的延迟高、带宽压力大和隐私泄露等问题。通过将LLM分片部署在多个边缘设备上,结合云边协同与设备间协作,EdgeShard实现了高效的模型推理。其核心创新包括:联合设备选择与模型划分优化、支持流水线并行与微批处理、提出EdgeShard-No-Bubbles策略以减少设备空闲时间,从而显著提升推理吞吐量并降低延迟。实验表明,EdgeShard在异构边缘设备上可实现高达50%的延迟降低和2倍的吞吐量提升,支持全精度模型推理而无精度损失,为资源受限的边缘环境提供了高效的LLM部署方案。 -
09.11 23:40:31发表了文章
2025-09-11 23:40:31
论文阅读——Agile-Quant:面向大语言模型边缘端更快推理的激活引导量化框架
Agile-Quant是一种针对大语言模型(LLMs)在边缘设备上高效推理的激活引导量化框架。它通过分析激活特性,提出了一种结合激活引导量化与token剪枝的优化策略,有效缓解了激活量化中的异常值问题,并提升了模型在边缘设备上的推理速度。该方法在LLaMA、OPT和BLOOM等主流LLMs上验证,实现了高达2.5倍的实际加速,同时保持了优异的模型性能。 -
09.10 22:24:52发表了文章
2025-09-10 22:24:52
Mixture of Experts架构的简要解析
Mixture of Experts(MoE)架构起源于1991年,其核心思想是通过多个专门化的“专家”网络处理输入的不同部分,并由门控网络动态组合输出。这种架构实现了稀疏激活,仅激活部分专家,从而在模型规模与计算成本之间取得平衡。MoE的关键在于门控机制的设计,如线性门控、噪声Top-K门控等,确保模型能根据输入特征自适应选择专家。 -
09.10 22:03:25发表了文章
2025-09-10 22:03:25
Transformer架构的简要解析
Transformer架构自2017年提出以来,彻底革新了人工智能领域,广泛应用于自然语言处理、语音识别等任务。其核心创新在于自注意力机制,通过计算序列中任意两个位置的相关性,打破了传统循环神经网络的序列依赖限制,实现了高效并行化与长距离依赖建模。该架构由编码器和解码器组成,结合多头注意力、位置编码、前馈网络等模块,大幅提升了模型表达能力与训练效率。从BERT到GPT系列,几乎所有现代大语言模型均基于Transformer构建,成为深度学习时代的关键技术突破之一。 -
09.10 21:27:24发表了文章
2025-09-10 21:27:24
大语言模型的核心算法——简要解析
大语言模型的核心算法基于Transformer架构,以自注意力机制为核心,通过Q、K、V矩阵动态捕捉序列内部关系。多头注意力增强模型表达能力,位置编码(如RoPE)解决顺序信息问题。Flash Attention优化计算效率,GQA平衡性能与资源消耗。训练上,DPO替代RLHF提升效率,MoE架构实现参数扩展,Constitutional AI实现自监督对齐。整体技术推动模型在长序列、低资源下的性能突破。 -
09.08 23:03:41发表了文章
2025-09-08 23:03:41
ProxylessNAS:直接在目标任务和硬件上进行神经架构搜索——论文解读
ProxylessNAS是一种直接在目标任务和硬件上进行神经架构搜索的方法,有效降低了传统NAS的计算成本。通过路径二值化和两路径采样策略,减少内存占用并提升搜索效率。相比代理任务方法,ProxylessNAS在ImageNet等大规模任务中展现出更优性能,兼顾准确率与延迟,支持针对不同硬件(如GPU、CPU、移动端)定制高效网络架构。
-
09.07 13:12:41发表了文章
2025-09-07 13:12:41
MINUN: 微控制器上的精确机器学习推理——论文阅读
MINUN是一个专为微控制器设计的高效机器学习推理框架,能精确解决TinyML中的三大挑战:数字表示参数化、位宽分配优化和内存碎片管理。它支持如Arduino和STM32等低功耗设备,显著减少内存占用,同时保持模型精度。 -
09.07 02:16:01发表了文章
2025-09-07 02:16:01
μNAS:面向微控制器的约束神经架构搜索——论文解读
μNAS是一种专为微控制器设计的神经架构搜索方法,旨在解决物联网设备中资源受限的挑战。通过多目标优化框架,μNAS能够在有限的内存和计算能力下,自动搜索出高效的神经网络结构。该方法结合了老化进化算法与贝叶斯优化,并引入结构化剪枝技术,实现模型压缩。实验表明,μNAS在多个数据集上均取得了优异的精度与资源使用平衡,显著优于现有方法,为边缘计算设备的智能化提供了可行路径。 -
09.06 21:29:15发表了文章
2025-09-06 21:29:15
TensorFlow Lite Micro:嵌入式TinyML系统上的机器学习推理框架——论文深度解析
TensorFlow Lite Micro(TFLM)是专为嵌入式系统设计的轻量级机器学习推理框架,适用于仅有几十KB内存的微控制器。它通过极简架构、模块化设计和内存优化策略,在资源受限设备上高效运行TinyML模型,广泛应用于关键词检测、传感器分析、预测性维护等领域。TFLM支持跨平台部署,并允许硬件厂商提供定制优化,兼顾灵活性与性能。 -
09.06 21:26:07发表了文章
2025-09-06 21:26:07
256KB内存约束下的设备端训练:算法与系统协同设计——论文解读
MIT与MIT-IBM Watson AI Lab团队提出一种创新方法,在仅256KB SRAM和1MB Flash的微控制器上实现深度神经网络训练。该研究通过量化感知缩放(QAS)、稀疏层/张量更新及算子重排序等技术,将内存占用降至141KB,较传统框架减少2300倍,首次突破设备端训练的内存瓶颈,推动边缘智能发展。
-
发表了文章
2025-10-06
面向多目标探测汽车雷达应用的77 GHz多频移键控(MFSK)调制波形发生器——论文阅读
-
发表了文章
2025-10-06
用于连续波雷达的二进制频移键控——论文阅读
-
发表了文章
2025-10-06
一种基于连续相位频移键控的高效频谱利用新型雷达信号——论文阅读
-
发表了文章
2025-10-06
正交时频空间调制:离散Zak变换方法——论文阅读笔记
-
发表了文章
2025-10-06
面向高多普勒衰落信道的 OTFS 调制技术
-
发表了文章
2025-10-06
基于信息论的OTFS雷达波形设计——论文阅读
-
发表了文章
2025-10-06
正交时频空间调制(OTFS)技术详解:基础原理与未来挑战
-
发表了文章
2025-10-06
正交时频空间(OTFS)调制技术:理论基础与性能分析
-
发表了文章
2025-10-06
6G时代的新型延迟多普勒通信范式:正交时频空间(OTFS)综述
-
发表了文章
2025-10-06
OTFS调制技术:通往6G的时延-多普勒域革命
-
发表了文章
2025-10-06
双选择性信道下正交啁啾分复用(OCDM)的低复杂度均衡算法研究——论文阅读
-
发表了文章
2025-10-03
基于OCDM雷达系统的离散Fresnel域信道估计——论文阅读
-
发表了文章
2025-10-03
双选择性信道中的广义正交啁啾分复用——论文阅读
-
发表了文章
2025-10-03
基于多载波宽带OCDM的太赫兹汽车雷达——论文阅读
-
发表了文章
2025-10-03
正交啁啾分复用技术:基于菲涅尔变换的通信系统设计——论文阅读
-
发表了文章
2025-10-03
PMCW雷达技术的理解与FMCW对比
-
发表了文章
2025-10-03
相位编码调频连续波雷达:融合传统与创新的智能感知技术
-
发表了文章
2025-10-03
正交啁啾分复用雷达技术(OCDM雷达):下一代传感系统技术
-
发表了文章
2025-10-03
Fresnel变换的详解
-
发表了文章
2025-10-03
面向边缘通用智能的多大语言模型系统:架构、信任与编排——论文阅读
滑动查看更多
暂无更多信息
暂无更多信息