面向高多普勒衰落信道的 OTFS 调制技术
K. R. Murali and A. Chockalingam, "On OTFS Modulation for High-Doppler Fading Channels," 2018 Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 2018, pp. 1-10, doi: 10.1109/ITA.2018.8503182.
正交时频空(Orthogonal Time Frequency Space, OTFS)调制是一种革命性的二维调制方案,其设计初衷是为了解决未来无线通信系统中的高速移动性挑战。随着 5G 及未来无线技术向毫米波(mmWave)频段扩展,以及在高速列车等场景下的应用需求增长,由于收发信机高速相对运动引起的多普勒频移变得异常严重,传统调制方案(如 OFDM)的性能会因此急剧下降甚至失效。OTFS 通过将信号与信道的操作从传统的时频(Time-Frequency)域转移到延迟-多普勒(Delay-Doppler)域,为这一难题提供了优雅的解决方案。
其核心优势在于,OTFS 能够将一个快速时变的双重色散(doubly-dispersive)信道,转化为一个在延迟-多普勒域中近乎准静态(quasi-static)且不衰落的信道。在这个新域中,整个数据帧内的所有信息符号都经历几乎完全相同的信道衰落,从而极大地提升了在高多普勒环境下的通信可靠性与性能。
本文旨在对 OTFS 技术进行一次全面的剖析,重点关注其信号检测与信道估计这两个关键环节。文中不仅详细介绍了系统的数学模型,还提出了一种基于马尔可夫链蒙特卡洛(MCMC)采样的低复杂度信号检测器,以及一种基于伪随机噪声(PN)导频的延迟-多普勒域信道估计算法。
无线信道在延迟-多普勒域的内在特性
移动无线信道的物理特性由多径传播和收发信机相对运动共同决定,这在信号处理中体现为时间色散(延迟扩展)和频率色散(多普勒扩展)。传统的信道表示方法,如时延域表示 \$h(t,\tau)\$ 或时频域表示 \$H(t,f)\$,其信道系数会随着时间快速变化,变化速率取决于移动速度和载波频率。这种快速变化给信道估计和均衡带来了巨大挑战。
OTFS 的突破点在于采用了延迟-多普勒域表示 \$h(\tau,\nu)\$。这种表示方法与无线信道的物理几何形态直接对应:信道中的每一个“径”(tap)代表了一组具有特定传播延迟 \$\tau\$(取决于反射体的相对距离)和特定多普勒频移 \$\nu\$(取决于反射体的相对速度)的物理反射体。由于在宏观环境中,主要的反射体集群数量是有限的,这使得 \$h(\tau,\nu)\$ 天然地具有稀疏性。更为关键的是,这些物理反射体的距离和速度在数毫秒的观测时间内基本保持恒定,这意味着延迟-多普勒域的信道响应比时频域响应要稳定得多、变化缓慢得多。
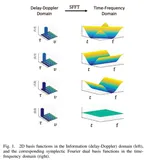
图 1 直观地展示了这一核心差异。该图对比了一个最大多普勒频移为 300 Hz 的 Jakes 信道模型在三个不同域的冲激响应幅度平方。

图 1 描述:此图展示了同一无线信道在三种不同数学表示下的形态。
- (a) 时频域表示:信道能量弥散在整个时频平面上,没有明显的结构。
- (b) 时延域表示:同样地,能量分布较为均匀,无法辨识出独立的路径。
- (c) 延迟-多普勒域表示:与之形成鲜明对比,信道能量集中在少数几个离散的、尖锐的峰值上。每一个峰值就对应一个具有特定延迟和多普勒的物理传播路径。这种“峰状”或“稀疏”的特性,正是 OTFS 技术能够实现高效信道估计和鲁棒通信的物理基础。
在延迟-多普勒域,接收信号 \$y(t)\$ 与发送信号 \$x(t)\$ 和信道 \$h(\tau,\nu)\$ 之间的关系可以用一个优雅的双重积分(也称为扭曲卷积)来描述:
$$ y(t) = \iint h(\tau,\nu)\, x(t-\tau)\, e^{j2\pi\nu(t-\tau)}\, d\tau\, d\nu . $$
OTFS 调制系统模型与核心变换
OTFS 的实现可以看作是在一个标准的多载波(如 OFDM)调制系统前后,分别增加了预处理和后处理模块。图 2 展示了这一系统架构。

- 图 2 描述:此框图清晰地展示了 OTFS 的信号处理流程。信息符号 \$x[k,l]\$ 始于延迟-多普勒域。通过 OTFS 变换(预处理)进入时频域,变为 \$X[n,m]\$。然后,中间的方框代表一个标准的时频调制器(TF modulation),它通过海森堡变换将 \$X[n,m]\$ 转换为时域信号 \$x(t)\$ 进行传输。信号经过信道 \$h(\tau,\nu)\$ 后,接收机执行逆过程:维格纳变换将 \$y(t)\$ 转换回时频域得到 \$Y[n,m]\$,最后通过 OTFS 逆变换(后处理)将信号转换回延迟-多普勒域,得到估计符号 \$\hat{x}[k,l]\$。
整个过程涉及一系列精妙的数学变换:
信息承载:信息符号(例如 QAM 符号)\$x[k,l]\$ 被直接放置在一个二维的延迟-多普勒网格上 \$L_{\mathrm{DD}} = { (\tfrac{k}{NT},; \tfrac{l}{M\Delta f}) }\$,其中 \$k=0,\dots,N-1\$ 是多普勒索引,\$l=0,\dots,M-1\$ 是延迟索引。
OTFS 变换(预处理):该变换的核心是逆辛有限傅里叶变换(ISFFT),它将延迟-多普勒域的符号 \$x[k,l]\$ 映射到时频域网格 \$L = { (nT,; m\Delta f) }\$ 上的符号 \$X[n,m]\$。ISFFT 定义为:
$$ X[n,m] = \frac{1}{MN} \sum_{k=0}^{N-1} \sum_{l=0}^{M-1} x[k,l]\, e^{j2\pi\left(\frac{nk}{N} - \frac{ml}{M}\right)} . $$
注:通常还会应用一个发射窗函数 \$W_{\text{tx}}[n,m]\$。
- 海森堡变换(时频调制):将时频域的离散符号 \$X[n,m]\$ 转换为连续时间的信号 \$x(t)\$,以进行空中传输。其操作是使用一组经过时移和频移的正交基函数(脉冲成型函数 \$\varphi_{\text{tx}}(t)\$)来调制每一个 \$X[n,m]\$ 符号:
$$ x(t) = \sum_{n=0}^{N-1} \sum_{m=0}^{M-1} X[n,m]\, \varphi_{\text{tx}}(t-nT)\, e^{j2\pi m\Delta f\, (t-nT)} . $$
维格纳变换(时频解调):接收端采用与接收脉冲 \$\varphi_{\text{rx}}(t)\$ 的匹配滤波,将接收到的时域信号 \$y(t)\$ 转换回时频域的离散符号 \$Y[n,m]\$。
OTFS 逆变换(后处理):对 \$Y[n,m]\$(通常先乘以接收窗函数 \$W_{\text{rx}}[n,m]\$)执行辛有限傅里叶变换(SFFT),将其从时频域转回延迟-多普勒域,以恢复出原始信息符号的估计值 \$\hat{x}[k,l]\$:
$$ \hat{x}[k,l] = \sum_{n=0}^{N-1} \sum_{m=0}^{M-1} Y[n,m] \, e^{-j2\pi\left(\frac{nk}{N} - \frac{ml}{M}\right)} . $$
通过这一整套变换,可以推导出 OTFS 系统的端到端输入输出关系。接收符号 \$\hat{x}[k,l]\$ 是发送符号 \$x[n,m]\$ 与一个等效信道响应 \$h_w\$ 的二维循环卷积:
$$ \hat{x}[k,l] = \frac{1}{MN} \sum_{m=0}^{M-1} \sum_{n=0}^{N-1} x[n,m]\; h_w\!\left(\frac{k-n}{NT},\; \frac{l-m}{M\Delta f}\right) . $$
这里的 \$h_w\$ 是真实信道响应 \$h(\tau,\nu)\$ 与收发窗函数决定的系统函数 \$w(\tau,\nu)\$ 的卷积。OTFS 设计的核心目标是通过选择合适的窗函数,使得 \$h_w\$ 的能量尽可能集中在原点,即尽量满足:
$$ h_w\!\left(\frac{k-n}{NT},\; \frac{l-m}{M\Delta f}\right) \approx 0,\quad \forall\, (n,m)\neq(k,l). $$
在这种理想情况下,输入输出关系简化为 \$\hat{x}[k,l] \approx h_w(0,0), x[k,l]\$,即每个符号经历的衰落都相同,从而消除了频率选择性衰落和多普勒扩展带来的负面影响。
向量化模型与低复杂度信号检测
为了设计实际的信号检测算法,我们需要将上述卷积关系转化为一个线性系统模型。假设信道由 \$P\$ 条稀疏路径构成,每条路径具有特定的延迟 \$\tau_i\$、多普勒 \$\nu_i\$ 和复衰落系数 \$h_i\$。在离散化后,这些参数对应于延迟索引 \$\alpha_i\$、整数多普勒索引 \$\beta_i\$ 和分数多普勒 \$\gamma_i\$。分数多普勒的存在会导致能量泄漏到相邻的多普勒单元,形成多普勒间干扰(Inter-Doppler Interference, IDI)。最终,离散的输入输出关系可以精确地表示为(详细推导见附录):
$$ y[k,l] = \sum_{i=1}^{P} \sum_{q=-E_i}^{E_i} H_{i,q}\, x\!\left[\big((k-\beta_i+q)\big)_N,\; \big((l-\alpha_i)\big)_M\right] + v[k,l] . $$
这个复杂的表达式可以写成一个简洁的线性向量形式:
$$ \mathbf{y} = \mathbf{H}\mathbf{x} + \mathbf{v} , $$
其中,\$\mathbf{x}\$ 和 \$\mathbf{y}\$ 是将二维符号网格按列堆叠后得到的 \$NM\times 1\$ 维发送和接收符号向量,\$\mathbf{v}\$ 是噪声向量,而 \$\mathbf{H}\$ 是一个 \$NM\times NM\$ 的等效信道矩阵。由于信道的稀疏性和分数多普勒的局部影响,矩阵 \$\mathbf{H}\$ 也是一个高度稀疏的矩阵。
最优的最大似然(ML)检测器需要穷举搜索所有可能的发送向量 \$\mathbf{x}\$,其计算复杂度为 \$|\mathbb{A}|^{NM}\$(\$\mathbb{A}\$ 是调制符号集),这在实际中是无法承受的。为此,本文提出一种基于马尔可夫链蒙特卡洛(MCMC)的低复杂度迭代检测算法,具体采用随机化吉布斯采样(Randomized Gibbs Sampling)。该算法从一个随机的初始解开始,在每次迭代中逐个更新向量 \$\mathbf{x}\$ 的元素。每个元素的更新值通过从其后验条件概率分布中进行随机采样得到。为了避免算法过早收敛到局部最优解(“停滞”问题),算法以一个很小的概率 \$r = 1/(NM)\$ 从均匀分布而不是后验分布中进行采样,从而引入随机扰动,帮助跳出局部极小值。
图 3 展示了采用该检测算法的 OTFS 系统在不同移动速度下的误码率(BER)性能。

- 图 3 描述:横轴为信噪比(SNR),纵轴为误码率(BER)。绘制了三条曲线,分别对应 100 Hz(27 km/h)、444.44 Hz(120 km/h)和 1851 Hz(500 km/h)三种不同的最大多普勒频移。三条性能曲线几乎完全重合,意味着即使移动速度从 27 km/h 飙升至 500 km/h,多普勒频移增加近 20 倍,OTFS 系统的性能也几乎没有受到影响。这与 OFDM 在高多普勒下性能崩溃形成鲜明对比,证明了 OTFS 在高速移动场景下的卓越鲁棒性。
延迟-多普勒域信道估计
上述检测算法的性能依赖于对信道矩阵 \$\mathbf{H}\$ 的精确已知。本文提出一种利用伪随机噪声(PN)序列作为导频的信道估计算法。该算法的目标是直接估计延迟-多普勒域中 \$P\$ 条路径的三个关键参数:离散延迟 \$\delta_i\$、离散多普勒 \$\omega_i\$ 和复衰落系数 \$\alpha_i\$。
该方法的核心是利用 PN 序列优良的、类似狄拉克冲激函数的自相关特性,将信道估计问题转化为一个时频偏移估计问题(time-frequency shift problem)。具体步骤是:发射一个已知的 PN 导频序列 \$S[n]\$,接收机接收到经过信道作用后的序列 \$R[n]\$。然后,接收机计算 \$R[n]\$ 与所有可能延迟-多普勒平移后的导频序列副本之间的相关性,从而构建一个二维的匹配滤波器矩阵 \$\mathcal{M}(R,S)[\delta,\omega]\$:
$$ \mathcal{M}(R,S)[\delta,\omega] = \left\langle R[n],\, e^{j2\pi \omega n}\, S[n-\delta] \right\rangle . $$
由于 PN 序列的特性,当且仅当平移参数 \$(\delta,\omega)\$ 与某条真实信道路径的参数 \$(\delta_i,\omega_i)\$ 相匹配时,该矩阵的对应位置会出现一个显著的峰值,而其他位置的值接近于零。峰值的位置即为延迟和多普勒的估计值,而峰值的复数值即为衰落系数的估计值。
以下 图 4、图 5、图 6 直观地展示了该估计方法的工作原理和效果。
- 图 4–6 描述:

- 图 4:最简单情况(单路径信道)。(a) 为理想 PN 序列的自相关函数,呈现一个尖峰;(b)(c) 为匹配滤波器矩阵的幅度图,在真实的延迟-多普勒坐标 (40, 90) 和 (80, 60) 处出现清晰、孤立的峰值,其余位置接近平坦噪声基底。
- 图 5:双路径信道(\$P=2\$),可见两个峰值,位置准确对应两条信道路径的延迟-多普勒坐标。
- 图 6:探讨 PN 序列长度 \$N_p\$ 对估计精度的影响。对比 (a)(\$N_p=127\$)与 (b)(\$N_p=1023\$),使用更长的序列时,噪声基底显著压低,使得路径峰值更加突出,与误差 \$\propto 1/\sqrt{N_p}\$ 的理论结论一致。
为量化估计性能,图 7 展示了估计误差(通过真实信道矩阵 \$\mathbf{H}\$ 与估计矩阵 \$\mathbf{H}_e\$ 之差的弗罗贝尼乌斯范数 \$\lVert \mathbf{H} - \mathbf{H}_e \rVert_F\$ 来衡量)与导频信噪比及 PN 序列长度的关系。
- 图 7 描述:

- (a) 在固定 \$N_p\$ 下,估计误差随导频 SNR 增加而降低;
- (b) 在固定 SNR 下,估计误差随 \$N_p\$ 增大(\$N_p = 2^r - 1\$)而减小。两者共同说明:增加导频功率或序列长度,可系统性提升信道估计准确性。
最后,图 8 对比了采用理想信道与估计信道时的端到端系统 BER 性能。

- 图 8 描述:以理想信道知识下的 BER 性能为基准(蓝色曲线)。当使用足够长的 PN 序列(如 \$N_p=1023\$,紫色曲线)进行信道估计时,OTFS 的性能曲线与理想情况下非常接近,性能损失可忽略;当 \$N_p\$ 缩短到 127 或 15 时,性能下降显著。实际系统需在估计精度(决定性能)与导频开销(决定频谱效率与复杂度)之间权衡。
结论
本文对新兴的 OTFS 调制技术进行了系统性研究,聚焦于信号检测和信道估计两大核心挑战。通过引入低复杂度的 MCMC 检测算法,使得 OTFS 在保持性能的同时具有实际部署的可行性;提出的基于 PN 导频的延迟-多普勒域信道估计算法,利用信道稀疏性实现了高效准确的信道参数获取。
性能评估结果有力展示了 OTFS 技术的核心优势:无论用户移动速度如何变化,其通信性能始终保持稳健,成功克服了高多普勒频移这一长期难题。这种内在鲁棒性,加上配套的高效信号处理方案,表明 OTFS 不仅是理论上优雅的调制方式,更是极具潜力的下一代物理层技术,有望为 5G 演进及未来 6G 无线系统提供坚实支撑。
附录:OTFS 离散输入输出关系的数学推导
出发点是 OTFS 的通用输入输出关系与在采用矩形窗函数及稀疏信道模型后的等效信道响应 \$h_w\$:
$$ h_w(\tau',\nu') = \sum_{i=1}^{P} h_i'\, \mathcal{G}(\nu',\nu_i)\, \mathcal{F}(\tau',\tau_i),\qquad h_i' = h_i e^{-j2\pi \nu_i \tau_i}, $$
其中
$$ \mathcal{F}(\tau',\tau_i) = \sum_{d=0}^{M-1} e^{j2\pi(\tau' - \tau_i) d\Delta f},\qquad \mathcal{G}(\nu',\nu_i) = \sum_{c=0}^{N-1} e^{-j2\pi(\nu' - \nu_i) cT} . $$
在离散的 OTFS 网格中,需在特定采样点上对 \$h_w\$ 求值。根据采样关系,\$\tau' = \tfrac{l-m}{M\Delta f}\$,\$\nu' = \tfrac{k-n}{NT}\$;同时将物理延迟与多普勒离散化:\$\tau_i = \tfrac{\alpha_i}{M\Delta f}\$、\$\nu_i = \tfrac{\beta_i + \gamma_i}{NT}\$,其中 \$\alpha_i,\beta_i\$ 为整数索引,\$0\le \gamma_i < 1\$ 为分数多普勒。
步骤 1:分析延迟核函数 \$\mathcal{F}\$
代入可得
$$ \mathcal{F}\!\left(\tfrac{l-m}{M\Delta f},\, \tau_i\right) = \sum_{d=0}^{M-1} e^{j\frac{2\pi}{M}(l - m - \alpha_i)d} . $$
该几何级数仅在 \$(l - m - \alpha_i) \bmod M = 0\$ 时和为 \$M\$,其他情况下为 0。这意味着延迟维度的耦合很简单:位于延迟索引 \$l\$ 的接收符号只会受到位于 \$m = ((l - \alpha_i))_M\$ 的发送符号影响。
步骤 2:分析多普勒核函数 \$\mathcal{G}\$
同理可得
$$ \mathcal{G}\!\left(\tfrac{k-n}{NT},\, \nu_i\right) = \sum_{c=0}^{N-1} e^{-j\frac{2\pi}{N}(k - n - \beta_i - \gamma_i)c} = \frac{1 - e^{-j2\pi (k - n - \beta_i - \gamma_i)}}{1 - e^{-j\frac{2\pi}{N}(k - n - \beta_i - \gamma_i)}} . $$
由于分数多普勒 \$\gamma_i\$ 的存在,该表达式通常不为零,其能量以类似 sinc 的形式泄漏到 \$n\$ 的邻近值上。在实际中,仅考虑其影响最显著的 \$2E_i+1\$ 个邻近多普勒单元:\$n = ((k - \beta_i + q))_N\$,\$q \in {-E_i,\dots,E_i}\$。
步骤 3:合并结果
将上述结果代回,利用 \$\mathcal{F}\$ 的选择性,可消去对 \$m\$ 的求和,并将对 \$n\$ 的求和改写为对 \$q\$ 的求和,最终得到接收符号 \$y[k,l]\$:
$$ y[k,l] = \sum_{i=1}^{P} \sum_{q=-E_i}^{E_i} \left( h_i'\, \frac{1}{N}\, \mathcal{G}\!\left(\tfrac{((k - (k - \beta_i + q)))_N}{NT},\, \nu_i\right) \right) x\!\left[\big((k - \beta_i + q)\big)_N,\; \big((l - \alpha_i)\big)_M\right] + v[k,l] . $$
将 \$\mathcal{G}\$ 的闭式表达式代入并化简,即得:
$$ y[k,l] = \sum_{i=1}^{P} \sum_{q=-E_i}^{E_i} h_i' \left( \frac{1 - e^{-j2\pi(-q - \gamma_i)}}{N\big(1 - e^{-j\frac{2\pi}{N}(-q - \gamma_i)}\big)} \right) x\!\left[\big((k - \beta_i + q)\big)_N,\; \big((l - \alpha_i)\big)_M\right] + v[k,l] . $$
该式清晰描述了在稀疏信道下,一个 OTFS 接收符号如何由多条路径及其邻近多普勒单元的发送符号线性叠加而成,为后续的信号检测奠定了数学基础。