
人工智能平台PAI
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。

Span抽取和元学习能碰撞出怎样的新火花,小样本实体识别来告诉你!
这是一种面向命名实体识别的小样本学习算法,采用两阶段的训练方法,检测文本中最有可能是命名实体的Span,并且准确判断其实体类型,在仅需要标注极少训练数据的情况下,提升预训练语言模型在命名实体识别任务上的精度。

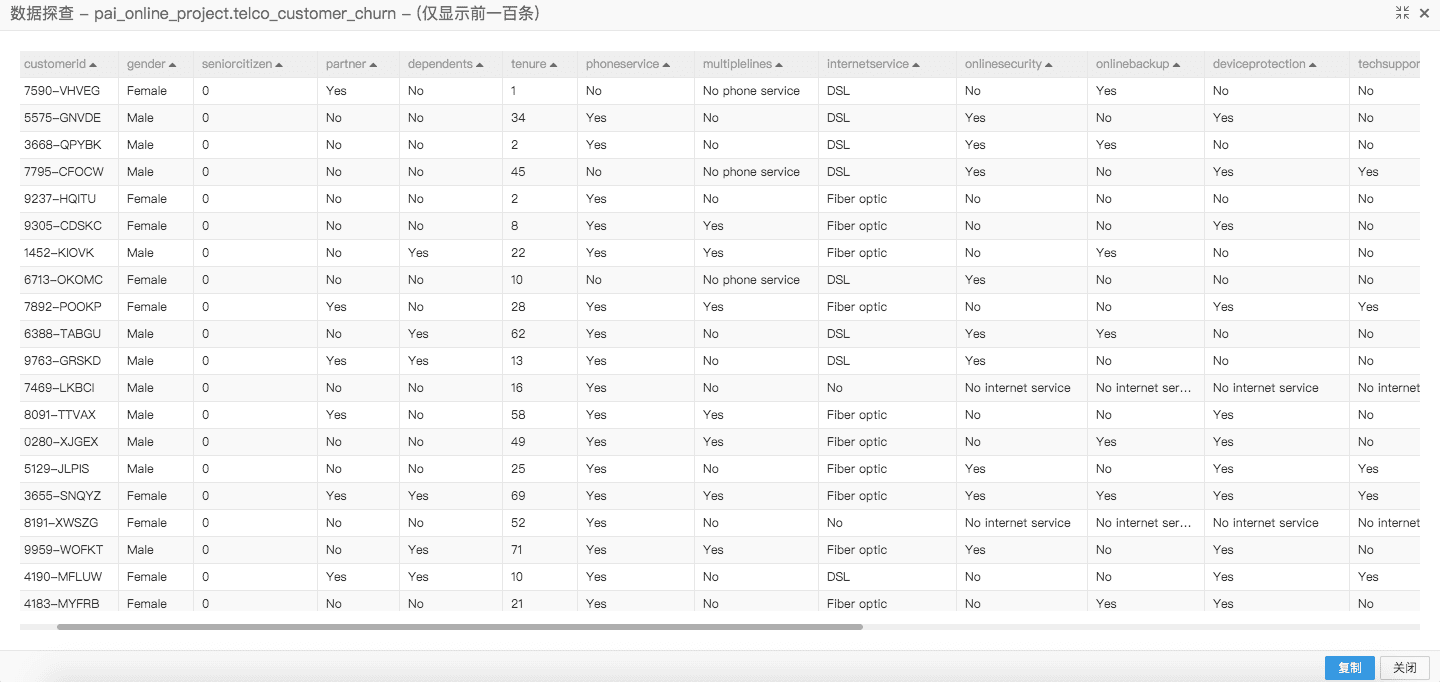
【DSW Gallery】使用 Alink 结合 TFDV 进行数据探索和验证
Alink 提供了对大规模数据的高效统计,能提供数量、缺失值、最大最小值、分位数、分布直方图等各种统计指标,用户可以探索数据特征,并为特征工程提供辅助。Alink 还能无缝结合 TensorFlow Data Validation,提供数据 schema 推断、数据偏移检测等功能。

【DSW Gallery】DSW Gallery
DSW Gallery提供了AI研发场景下丰富的案例和解决方案,内容涵盖如: Jupyter, 数据分析,机器学习,深度学习,PAI产品说明, SDK使用说明,以及行业解决方案),支持一键在DSW中启动和运行,帮助您快速了解云原生下AI研发流程,熟练使用PAI的各种工具,提升开发效率和质量。

【DSW Gallery】基于EasyNLP的序列标注(命名实体识别)
EasyNLP提供多种模型的训练及预测功能,旨在帮助自然语言开发者方便快捷地构建模型并应用于生产。本文以序列标注(命名实体识别)为例,为您介绍如何在PAI-DSW中使用EasyNLP。

【DSW Gallery】基于EasyNLP的BERT英文机器阅读理解
EasyNLP提供多种模型的训练及预测功能,旨在帮助自然语言开发者方便快捷地构建模型并应用于生产。本文以机器阅读理解为例,为您介绍如何在PAI-DSW中基于EasyNLP快速使用BERT进行英文机器阅读理解模型的训练、推理。

【DSW Gallery】基于EasyNLP的BERT文本分类
EasyNLP提供多种模型的训练及预测功能,旨在帮助自然语言开发者方便快捷地构建模型并应用于生产。本文以文本分类为例,为您介绍如何在PAI-DSW中基于EasyNLP快速使用BERT进行文本分类模型的训练、推理。

【DSW Gallery】使用Numpy实现卷积神经网络
Numpy是数值计算中使用非常广泛的一个工具包,可以进行高纬度空间内部的矩阵运算。本文以CNN为例子,使用Numpy来实现CNN网络的前向传递和反向传递逻辑。对于了解CNN网络的细节以及学习如何使用Numpy都很有帮助。


直播回放含 PPT 下载 | 基于 Flink & DeepRec 构建 Online Deep Learning
基于 Flink & DeepRec 构建 Online Deep Learning专场的直播回放和PPT下载


预训练知识度量比赛夺冠!阿里云PAI发布知识预训练工具
阿里云计算平台PAI团队携手达摩院智能对话与服务技术团队,在CCIR Cup2021全国信息检索挑战杯的《预训练模型知识量度量》比赛中基于自研的融入知识预训练模型取得第一名。团队采用自研的知识预训练模型KGBERT和DKPLM为底座,采用多样化知识融入方法,形成强有力的蕴含丰富知识的预训练模型,在比赛数据上取得了非常好的效果。

持续探索行业新趋势,PAI平台获得联邦学习评测证书
2021 年 6 月 24 日,阿里云机器学习平台PAI获得“大数据产品能力评测”联邦学习项目基础能力专项评测证书,持续探索行业新趋势,不断在前沿的热门领域尝试AI应用落地。
农业贷款预测的回归算法实现_0
iip<br />数据源:撒地方<br />数据大小:6.62 KB<br />字段数量:10<br />使用组件:读数据表,线性回归(旧),SQL脚本,过滤与映射,合并列<br />
心脏病预测案例_3048
心脏病是人类健康的头号杀手。全世界1/3的人口死亡是因心脏病引起的,而我国,每年有几十万人死于心脏病。 所以,如果可以通过提取人体相关的体侧指标,通过数据挖掘的方式来分析不同特征对于心脏病的影响,对于预测和预防心脏病将起到至关重要的作用。本文将会通过真实的数据,通过阿里云机器学习平台搭建心脏病预测案例。<br />数据源:<br />数据大小:7.49 KB<br />字段数量:15<br />使用组件:读数据表,类型转换,SQL脚本,归一化,拆分,过滤式特征选择<br />
雾霾天气预测_1150
test<br />数据源:test<br />数据大小:37.3 KB<br />字段数量:7<br />使用组件:读数据表,类型转换,SQL脚本,归一化,拆分<br />
【评分卡】信用卡消费分析_230
测试测试<br />数据源:<br />数据大小:1.36 MB<br />字段数量:25<br />使用组件:分箱,读数据表,评分卡预测,评分卡训练,拆分,样本稳定指数(PSI)<br />
CTR 实验之二:GBDT 与LR 算法融合
通过GBDT生成的特征与原始特征进行merge,然后通过LR做回归。<br />数据源:<br />数据大小:770 KB<br />字段数量:20<br />使用组件:Table to KV,SQL脚本,拆分,读数据表,特征编码,增加序号列<br />
【推荐算法】商品推荐_2587
asdf<br />数据源:adsf<br />数据大小:328 KB<br />字段数量:4<br />使用组件:过滤与映射,SQL脚本,读数据表,JOIN<br />
【推荐算法】商品推荐_2587
asdf<br />数据源:asdf<br />数据大小:328 KB<br />字段数量:4<br />使用组件:Filter and Mapping,JOIN,Read ODPS table,SQL Script<br />
雾霾天气预测_604
管网压力预测<br />数据源:<br />数据大小:37.3 KB<br />字段数量:7<br />使用组件:归一化,拆分,SQL脚本,读数据表,类型转换<br />
【玩转数据系列十一】机器学习PAI眼中的《人民的名义》
最近热播的反腐神剧“人民的名义”掀起来一波社会舆论的高潮,这部电视剧之所能得到广泛的关注,除了老戏骨们精湛的演技,整部剧出色的剧本也起到了关键的作用。笔者在平日追剧之余,也尝试通过机器学习算法对人民的名义的部分剧集文本内容进行了文本分析,希望从数据的角度得到一些输入。
心脏病预测案例_1480
gawgew<br />数据源:<br />数据大小:7.49 KB<br />字段数量:15<br />使用组件:DNN训练,归一化,拆分,SQL脚本,读数据表,类型转换<br />
test_multiEvaluation
实验名称实验名称实验名称<br />数据源:实验名称<br />数据大小:779 KB<br />字段数量:42<br />使用组件:读数据表<br />
EasyRec和TorchEasyRec中FG NORMAL 和 FG DAG 的区别
TorchEasyRec提供两种特征生成模式:FG_NORMAL(Python逐特征处理,适合调试)与FG_DAG(C++ DAG引擎批量处理,性能更优、支持依赖、stub_type及自动侧识别)。推荐生产环境优先使用FG_DAG。
人工智能平台PAI产品使用合集之机器学习PAI中怎么拉到maven仓库的包
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。
人工智能平台PAI产品使用合集之ev必须在特定的scope下定义吗
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。
人工智能平台PAI产品使用合集之机器学习PAI EasyRec训练时,怎么去除没有意义的辅助任务的模型,用于部署
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。
人工智能平台PAI 操作报错合集之DSSM负采样时,输入数据不同,被哈希到同一个桶里,导致生成的embedding相同如何解决
阿里云人工智能平台PAI (Platform for Artificial Intelligence) 是阿里云推出的一套全面、易用的机器学习和深度学习平台,旨在帮助企业、开发者和数据科学家快速构建、训练、部署和管理人工智能模型。在使用阿里云人工智能平台PAI进行操作时,可能会遇到各种类型的错误。以下列举了一些常见的报错情况及其可能的原因和解决方法。
人工智能平台PAI 操作报错合集之机器学习PAI deeprec中的sok该怎么使用
阿里云人工智能平台PAI (Platform for Artificial Intelligence) 是阿里云推出的一套全面、易用的机器学习和深度学习平台,旨在帮助企业、开发者和数据科学家快速构建、训练、部署和管理人工智能模型。在使用阿里云人工智能平台PAI进行操作时,可能会遇到各种类型的错误。以下列举了一些常见的报错情况及其可能的原因和解决方法。
机器学习PAI常见问题之DLC的数据写入到另外一个阿里云主账号的OSS中如何解决
PAI(平台为智能,Platform for Artificial Intelligence)是阿里云提供的一个全面的人工智能开发平台,旨在为开发者提供机器学习、深度学习等人工智能技术的模型训练、优化和部署服务。以下是PAI平台使用中的一些常见问题及其答案汇总,帮助用户解决在使用过程中遇到的问题。
人工智能平台PAI产品使用合集之如何在CPU服务器上使用PAIEasyRec进行分布式训练
阿里云人工智能平台PAI是一个功能强大、易于使用的AI开发平台,旨在降低AI开发门槛,加速创新,助力企业和开发者高效构建、部署和管理人工智能应用。其中包含了一系列相互协同的产品与服务,共同构成一个完整的人工智能开发与应用生态系统。以下是对PAI产品使用合集的概述,涵盖数据处理、模型开发、训练加速、模型部署及管理等多个环节。

和PAI一起,每周玩转AI【第五期】
【和PAI一起,每周玩转AI】系列活动上线了!人工智能平台PAI提供近万元免费云上资源,助力开发者们体验AIGC能力。参与每周 AIGC 主题活动,有机会赢取小米手环8、小米充电宝等多重好礼!

【DSW Gallery】Gbdt-FM模型
GBDT+FM 模型是由 Gbdt+LR 延伸出来的模型。该模型利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当做 FM 模型的输入,来产生最后的预测结果。该模型能够综合利用用户、物品和上下文等多种不同的特征,生成较为全面的推荐,在CTR点击率预估场景下使用较为广泛。

【DSW Gallery】基于EasyNLP的英文文本摘要
EasyNLP提供多种模型的训练及预测功能,旨在帮助自然语言开发者方便快捷地构建模型并应用于生产。本文以英文文本摘要为例,为您介绍如何在PAI-DSW中使用EasyNLP。
预约直播 | 深度学习编译器技术趋势与阿里云BladeDISC的编译器实践
阿里云AI技术分享会第二期《深度学习编译器技术趋势与阿里云BladeDISC的编译器实践》将在2022年08月17日晚18:00-18:30直播,精彩不容错过!
PAI-STUDIO通过Tensorflow处理MaxCompute表数据
PAI-STUDIO在支持OSS数据源的基础上,增加了对MaxCompute表的数据支持。用户可以直接使用PAI-STUDIO的Tensorflow组件读写MaxCompute数据,本教程将提供完整数据和代码供大家测试。
农业贷款预测的回归算法实现_0
ljkkjjk<br />数据源:<br />数据大小:6.62 KB<br />字段数量:10<br />使用组件:读数据表,线性回归(旧),SQL脚本,过滤与映射,合并列<br />
asd【文本分析】新闻分类aaa_2493
流控流控流控流控<br />数据源:<br />数据大小:261 KB<br />字段数量:3<br />使用组件:读数据表,类型转换,过滤与映射,增加序号列,合并列<br />





