
计算机视觉
包含图像分类、图像生成、人体人脸识别、动作识别、目标分割、视频生成、卡通画、视觉评价、三维视觉等多个领域

See3D:智源研究院开源的无标注视频学习 3D 生成模型
See3D 是智源研究院推出的无标注视频学习 3D 生成模型,能够从大规模无标注的互联网视频中学习 3D 先验,实现从视频中生成 3D 内容。See3D 采用视觉条件技术,支持从文本、单视图和稀疏视图到 3D 的生成,并能进行 3D 编辑与高斯渲染。


TripoSG:3D生成新纪元!修正流模型秒出高保真网格,碾压传统建模
TripoSG 是 VAST AI 推出的基于大规模修正流模型的高保真 3D 形状合成技术,能够从单张图像生成细节丰富的 3D 网格模型,在工业设计、游戏开发等领域具有广泛应用前景。

谷歌DeepMind联手牛津推出Bolt3D:AI秒速3D建模革命!单GPU仅需6秒生成3D场景
牛津大学与谷歌联合推出的Bolt3D技术,能在单个GPU上仅用6.25秒从单张或多张图像生成高质量3D场景,基于高斯溅射和几何多视角扩散模型,为游戏、VR/AR等领域带来革命性突破。
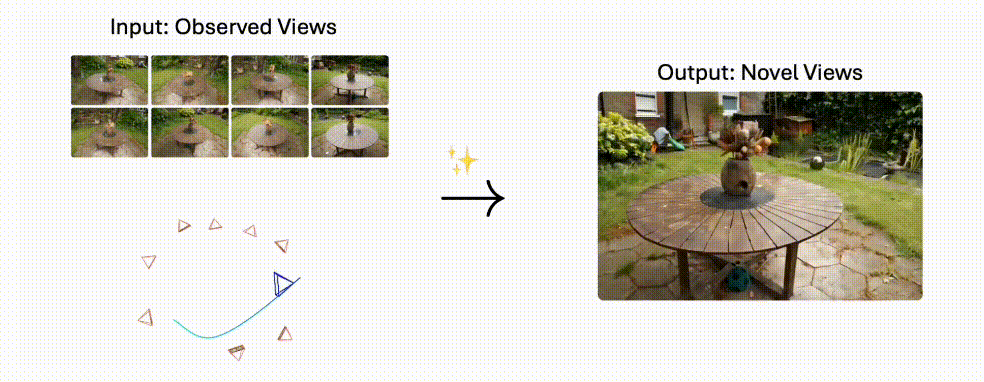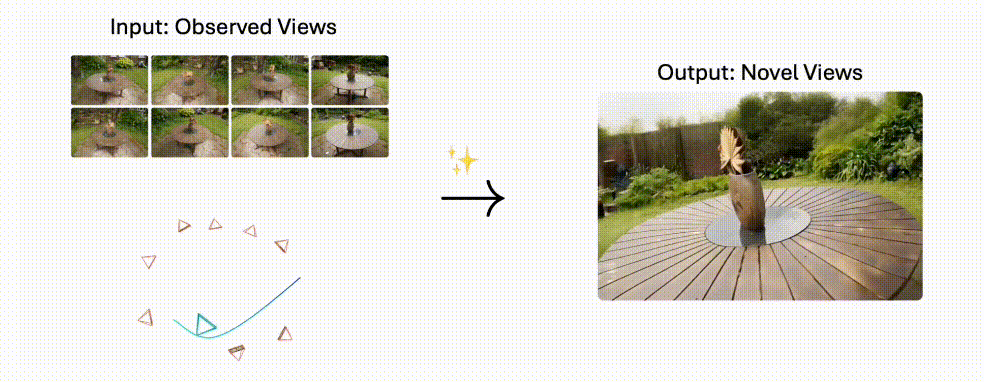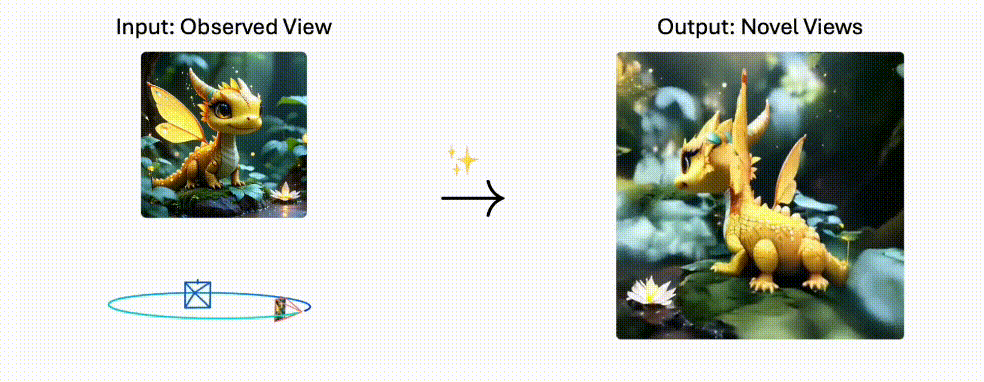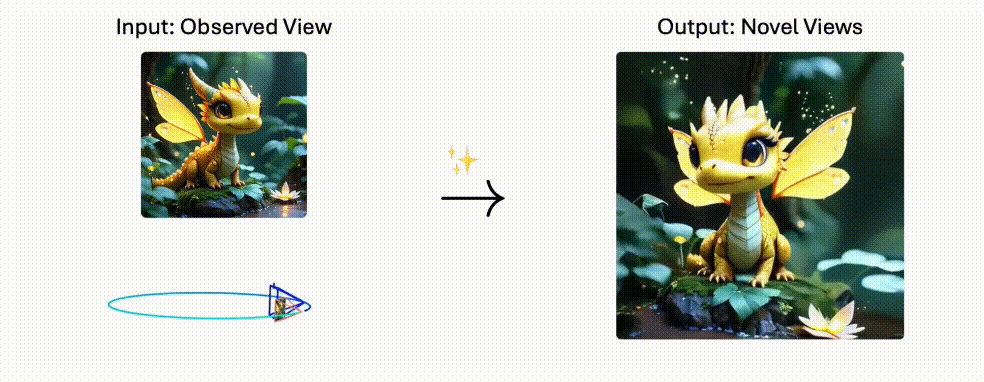
Stable Virtual Camera:2D秒变3D电影!Stability AI黑科技解锁无限运镜,自定义轨迹一键生成
Stable Virtual Camera 是 Stability AI 推出的 AI 模型,能够将 2D 图像转换为具有真实深度和透视感的 3D 视频,支持自定义相机轨迹和多种动态路径,生成高质量且时间平滑的视频。

VideoGrain:零样本多粒度视频编辑神器,用AI完成换装改场景,精准控制每一帧!
VideoGrain 是悉尼科技大学和浙江大学推出的零样本多粒度视频编辑框架,基于调节时空交叉注意力和自注意力机制,实现类别级、实例级和部件级的精细视频修改,保持时间一致性,显著优于现有方法。

CogVideoX-Flash:智谱首个免费AI视频生成模型,支持文生视频、图生视频,分辨率最高可达4K
CogVideoX-Flash 是智谱推出的首个免费AI视频生成模型,支持文生视频、图生视频,最高支持4K分辨率,广泛应用于内容创作、教育、广告等领域。

SPAR3D:一张图片就能生成3D模型,每个物体的重建时间仅需0.7秒!
SPAR3D 是由 Stability AI 和伊利诺伊大学香槟分校推出的先进单图生成3D模型方法,支持快速推理与用户交互式编辑,适用于多种3D建模场景。

Inf-DiT:清华联合智谱AI推出超高分辨率图像生成模型,生成的空间复杂度从 O(N^2) 降低到 O(N)
Inf-DiT 是清华大学与智谱AI联合推出的基于扩散模型的图像上采样方法,能够生成超高分辨率图像,突破传统扩散模型的内存限制,适用于多种实际应用场景。

Infinity:字节跳动开源高分辨率图像生成模型,生成 1024x1024 的图像仅需 0.8 秒
Infinity 是字节跳动推出的高分辨率图像生成模型,通过位级自回归建模和无限词汇量标记器,显著提升了图像生成的细节和质量。

GeneMAN:上海AI Lab联合北大等高校推出的3D人体模型创建框架
GeneMAN是由上海AI实验室、北京大学、南洋理工大学和上海交通大学联合推出的3D人体模型创建框架。该框架能够从单张图片中生成高保真度的3D人体模型,适用于多种应用场景,如虚拟试衣、游戏和娱乐、增强现实和虚拟现实等。

OminiControl:AI图像生成框架,实现图像主题控制和空间精确控制
OminiControl 是一个高度通用且参数高效的 AI 图像生成框架,专为扩散变换器模型设计,能够实现图像主题控制和空间精确控制。该框架通过引入极少量的额外参数(0.1%),支持主题驱动控制和空间对齐控制,适用于多种图像生成任务。

MVPaint:腾讯PCG联合多所高校共同推出的3D纹理生成框架
MVPaint是由腾讯PCG联合多所高校共同推出的3D纹理生成框架,基于同步多视角扩散技术,实现高分辨率、无缝且多视图一致的3D纹理生成。该框架包含三个核心模块:同步多视角生成、空间感知3D修补和UV细化,显著提升3D模型的纹理生成效果。
ModelScope模型使用与EAS部署调用
本文以魔搭数据的模型为例,演示在DSW实例中如何快速调用模型,然后通过Python SDK将模型部署到阿里云PAI EAS服务,并演示使用EAS SDK实现对服务的快速调用,重点针对官方关于EAS模型上线后示例代码无法正常调通部分进行了补充。


ACTalker:港科大联合腾讯清华推出,多模态驱动的说话人视频生成神器
ACTalker是由香港科技大学联合腾讯、清华大学研发的端到端视频扩散框架,采用并行Mamba结构和多信号控制技术,能生成高度逼真的说话人头部视频。

Reve Image:设计师失业警告!AI秒出海报级神图,排版自动搞定
Reve Image 是 Reve 推出的全新 AI 图像生成模型,专注于提升美学表现、精确的提示遵循能力以及出色的排版设计,能生成高质量的视觉作品。

MIDI-3D:单图秒变3D场景!40秒生成360度空间,多实例扩散黑科技
MIDI-3D 是一种先进的 AI 3D 场景生成技术,能够将单张图像快速转化为高保真度的 360 度 3D 场景,具有强大的全局感知能力和细节表现力,适用于游戏开发、虚拟现实、室内设计等多个领域。

MIT颠覆传统!分形生成模型效率暴涨4000倍,高分辨率图像秒级生成
Fractal Generative Models 是麻省理工学院与 Google DeepMind 团队推出的新型图像生成方法,基于分形思想,通过递归调用模块构建自相似架构,显著提升计算效率,适用于高分辨率图像生成、医学图像模拟等领域。
Sitcom-Crafter:动画师失业警告!AI黑科技自动生成3D角色动作,剧情脚本秒变动画
Sitcom-Crafter 是一款基于剧情驱动的 3D 动作生成系统,通过多模块协同工作,支持人类行走、场景交互和多人交互,适用于动画、游戏及虚拟现实等领域。
Sonic:自动对齐音频与唇部动作,一键合成配音动画!腾讯与浙大联合推出音频驱动肖像动画生成框架
Sonic 是由腾讯和浙江大学联合开发的音频驱动肖像动画框架,支持逼真的唇部同步、丰富的表情和头部动作、长时间稳定生成,并提供用户可调节性。

DiffSplat:输入文本或图像,2秒内生成3D建模!北大联合字节开源3D建模生成框架
DiffSplat 是由北京大学和字节跳动联合推出的一个高效 3D 生成框架,能够在 1-2 秒内从文本提示或单视图图像生成高质量的 3D 高斯点阵,并确保多视图下的一致性。

SHMT:体验 AI 虚拟化妆!阿里巴巴达摩院推出自监督化妆转移技术
SHMT 是阿里达摩院与武汉理工等机构联合研发的自监督化妆转移技术,支持高效妆容迁移与动态对齐,适用于图像处理、虚拟试妆等多个领域。

Edicho:多图像一致性编辑,支持即插即用无需训练,快速实现风格转换
Edicho 是蚂蚁集团联合港科大等高校推出的多图像一致性编辑方法,基于扩散模型,支持即插即用,无需额外训练,适用于多种图像编辑任务。

VITRON:开源像素级视觉大模型,同时满足图像与视频理解、生成、分割和编辑等视觉任务
VITRON 是由 Skywork AI、新加坡国立大学和南洋理工大学联合推出的像素级视觉大模型,支持图像与视频的理解、生成、分割和编辑,适用于多种视觉任务。

VideoPhy:UCLA 和谷歌联合推出评估视频生成模型物理模拟能力的评估工具,衡量模型生成的视频是否遵循现实世界的物理规则
VideoPhy 是 UCLA 和谷歌联合推出的首个评估视频生成模型物理常识能力的基准测试,旨在衡量模型生成的视频是否遵循现实世界的物理规则。

Diff-Instruct:指导任意生成模型训练的通用框架,无需额外训练数据即可提升生成质量
Diff-Instruct 是一种从预训练扩散模型中迁移知识的通用框架,通过最小化积分Kullback-Leibler散度,指导其他生成模型的训练,提升生成性能。

VisionFM:通用眼科 AI 大模型,具备眼科疾病诊断能力,展现出专家级别的准确性
VisionFM 是一个多模态多任务的视觉基础模型,专为通用眼科人工智能设计。通过预训练大量眼科图像,模型能够处理多种眼科成像模态,并在多种眼科任务中展现出专家级别的智能性和准确性。

Ruyi:图森未来推出的图生视频大模型,支持多分辨率、多时长视频生成,具备运动幅度和镜头控制等功能
Ruyi是图森未来推出的图生视频大模型,专为消费级显卡设计,支持多分辨率、多时长视频生成,具备首帧、首尾帧控制、运动幅度控制和镜头控制等特性。Ruyi基于DiT架构,能够降低动漫和游戏内容的开发周期和成本,是ACG爱好者和创作者的理想工具。

Aurora:xAI 为 Grok AI 推出新的图像生成模型,xAI Premium 用户可无限制访问
Aurora是xAI为Grok AI助手推出的新图像生成模型,专注于生成高逼真度的图像,特别是在人物和风景图像方面。该模型支持文本到图像的生成,并能处理包括公共人物和版权形象在内的多种图像生成请求。Aurora的可用性因用户等级而异,免费用户每天能生成三张图像,而Premium用户则可享受无限制访问。

Make-It-Animatable:中科大联合腾讯推出的自动生成即时动画准备资产
Make-It-Animatable是由中国科学技术大学和腾讯联合推出的数据驱动框架,能够在不到一秒内将任何3D人形模型转换为可用于动画的状态。该框架支持多种3D数据格式,并采用从粗到细的表示策略和结构感知建模,显著提升了动画准备的质量和速度。

AI给你送年画啦!每一张都是独一无二
阿里云开发者社区携手阿里达摩院、魔搭社区共同推出AI年画娃娃活动,为大家提供了最新的、可体验的生成式AI技术,希望为兔年春节增添一份科技氛围,让年味更加多彩丰富。


NeurlPS 2025!多伦多大学TIRE助力3D/4D 生成精准保留主体身份
TIRE提出“追踪-补全-重投影”三阶段方法,实现主体驱动的3D/4D生成。通过视频跟踪识别缺失区域,定制2D模型补全纹理,并重投影至3D空间,提升生成一致性与质量,推动动态场景生成新进展。
TrajectoryCrafter:腾讯黑科技!单目视频运镜自由重构,4D生成效果媲美实拍
TrajectoryCrafter 是腾讯与香港中文大学联合推出的单目视频相机轨迹重定向技术,支持后期自由调整视频的相机位置和角度,生成高质量的新型轨迹视频,广泛应用于沉浸式娱乐、创意视频制作等领域。

Migician:清北华科联手放大招!多图像定位大模型问世:3秒锁定跨画面目标,安防监控迎来AI革命!
Migician 是北交大联合清华、华中科大推出的多模态视觉定位模型,支持自由形式的跨图像精确定位、灵活输入形式和多种复杂任务。
DynamicCity:上海AI Lab开源4D场景神器助力自动驾驶场景!128帧动态LiDAR生成,1:1还原城市早晚高峰
DynamicCity 是上海 AI Lab 推出的 4D 动态场景生成框架,专注于生成具有语义信息的大规模动态 LiDAR 场景,适用于自动驾驶、机器人导航和交通流量分析等多种应用场景。

CreatiLayout:复旦与字节联合推出布局到图像生成技术,支持高质量图像生成与布局优化
CreatiLayout 是复旦大学与字节跳动联合推出的创新布局到图像生成技术,通过大规模数据集和孪生多模态扩散变换器,实现高质量图像生成与布局优化。

PersonaMagic:人像与风格融合!快速生成个性化的头像
PersonaMagic 是一种创新的高保真人脸定制技术,通过阶段调节的文本条件策略和动态嵌入学习,能够根据单张图像生成个性化角色,广泛应用于娱乐、游戏、影视等领域。

HelloMeme:开源的面部表情与姿态迁移框架,将视频中的人物表情迁移到静态图像中生成动态视频
HelloMeme 是一个基于 Stable Diffusion 1.5 模型的面部表情与姿态迁移框架,通过集成空间编织注意力机制,实现了自然且物理合理的表情包视频生成。该框架具有强大的泛化能力和扩展性,适用于多种应用场景。

SNOOPI:创新 AI 文本到图像生成框架,提升单步扩散模型的效率和性能
SNOOPI是一个创新的AI文本到图像生成框架,通过增强单步扩散模型的指导,显著提升模型性能和控制力。该框架包括PG-SB和NASA两种技术,分别用于增强训练稳定性和整合负面提示。SNOOPI在多个评估指标上超越基线模型,尤其在HPSv2得分达到31.08,成为单步扩散模型的新标杆。
modelscope调用的模型如何指定在特定gpu上运行?排除使用CUDA_VISIBLE_DEVICES环境变量
由于个人需要,家里有多张卡,但是我只想通过输入device号的方式,在单卡上运行模型。如果设置环境变量的话我的其他服务将会受影响。

DreamActor-M1:字节跳动推出AI动画黑科技,静态照片秒变生动视频
DreamActor-M1是字节跳动研发的AI图像动画框架,通过混合引导机制实现高保真人物动画生成,支持多语言语音驱动和形状自适应功能。

ObjectMover:港大联合Adobe打造图像编辑黑科技,移动物体光影自动匹配
香港大学与Adobe联合研发的ObjectMover模型,通过视频生成先验迁移技术,实现图像中物体的自然移动、删除和插入,自动保持光影一致性。
IMAGPose:南理工突破性人体生成框架!多姿态适配+细节语义融合,刷新图像生成范式
IMAGPose 是南京理工大学推出的用于人体姿态引导图像生成的统一条件框架,解决了传统方法在姿态引导的人物图像生成中的局限性,支持多场景适应、细节与语义融合、灵活的图像与姿态对齐以及全局与局部一致性。

VidSketch:手残党逆袭!浙大AI神器草图秒变4K动画,三连提示词玩转影视级特效
VidSketch 是浙江大学推出的创新视频生成框架,通过手绘草图和简单文本提示生成高质量视频动画,降低视频创作的技术门槛,满足多样化的艺术需求。

SmartEraser:中科大推出图像对象移除技术,轻松移除照片中的不想要元素,保留完美瞬间
SmartEraser 是由中科大与微软亚洲研究院联合开发的图像编辑技术,能够精准移除图像中的指定对象,同时保留周围环境的细节和结构,适用于复杂场景的图像处理。






