
计算机视觉
包含图像分类、图像生成、人体人脸识别、动作识别、目标分割、视频生成、卡通画、视觉评价、三维视觉等多个领域
红外小目标检测新突破!异常感知检测头AA-YOLO:节俭又鲁棒,小样本也能精准识别
本文提出AA-YOLO:首个将统计异常检验嵌入YOLO检测头的方法,通过指数分布建模背景,显式识别小目标为统计异常,显著降低误报率;仅需10%数据即达90%全量性能,参数比EFLNet少6倍,轻量高效;在噪声、跨域、跨模态下鲁棒性强,且可无缝适配各类YOLO及实例分割网络。
基于YOLO11的交通违规检测系统(Python源码+数据集+Pyside6界面)
本文基于YOLO11构建交通违规检测系统,涵盖23类目标(车辆、信号灯、标志等),详解数据制作(ROI裁剪优化尺度)、模型改进(C3k2、C2PSA、轻量Detect头)及训练可视化全过程,并集成PySide6实现GUI应用,助力工业落地。

video-subtitle-remover(VSR)--开源AI去字幕方案深度解析
VSR(video-subtitle-remover)是一款开源AI视频去字幕工具,支持本地运行,无需上传数据。它融合STTN、LaMa、ProPainter三大前沿修复模型,可智能检测并擦除硬字幕/水印,保持原分辨率与画质。兼容CUDA/DirectML,适配NVIDIA/AMD/Intel显卡,兼顾隐私性、可控性与高性能。

NeurlPS 2025!多伦多大学TIRE助力3D/4D 生成精准保留主体身份
TIRE提出“追踪-补全-重投影”三阶段方法,实现主体驱动的3D/4D生成。通过视频跟踪识别缺失区域,定制2D模型补全纹理,并重投影至3D空间,提升生成一致性与质量,推动动态场景生成新进展。

【Github热门项目】DeepSeek-OCR项目上线即突破7k+星!突破10倍无损压缩,重新定义文本-视觉信息处理
DeepSeek-OCR开源即获7k+星,首创“上下文光学压缩”技术,仅用100视觉token超越传统OCR模型256token性能,压缩比达10-20倍,精度仍超97%。30亿参数实现单卡日处理20万页,显著降低大模型长文本输入成本,重新定义高效文档理解新范式。

漫画师福音!开源AI神器让线稿着色快如闪电!MagicColor:港科大开源多实例线稿着色框架,一键生成动画级彩图
MagicColor是香港科技大学推出的多实例线稿着色框架,基于扩散模型和自监督训练策略,实现单次前向传播完成多实例精准着色,大幅提升动画制作和数字艺术创作效率。

ACTalker:港科大联合腾讯清华推出,多模态驱动的说话人视频生成神器
ACTalker是由香港科技大学联合腾讯、清华大学研发的端到端视频扩散框架,采用并行Mamba结构和多信号控制技术,能生成高度逼真的说话人头部视频。

这个模型让AI角色会说话还会演!MoCha:Meta联手滑铁卢大学打造对话角色视频生成黑科技
MoCha是由Meta与滑铁卢大学联合开发的端到端对话角色视频生成模型,通过创新的语音-视频窗口注意力机制实现精准的唇语同步和全身动作生成。

WorldScore:斯坦福开源世界生成模型评估新标杆:3000样本+九维指标,视频/4D/3D模型一网打尽
WorldScore是斯坦福大学提出的首个统一评估世界生成模型的基准测试,通过基于相机轨迹的布局规范和3000个多样化样本,全面评测生成内容的可控性、质量与动态性。

EasyControl Ghibli:在线体验一键生成宫崎骏动画风,开源AI模型让你的照片秒变吉卜力
EasyControl Ghibli是基于扩散模型的AI工具,通过条件注入技术将普通照片转化为吉卜力动画风格,仅需100张训练样本即可精准还原标志性光影与色调特征。

DreamActor-M1:字节跳动推出AI动画黑科技,静态照片秒变生动视频
DreamActor-M1是字节跳动研发的AI图像动画框架,通过混合引导机制实现高保真人物动画生成,支持多语言语音驱动和形状自适应功能。

AI-ClothingTryOn:服装店老板连夜下架试衣间!基于Gemini开发的AI试衣应用,一键生成10种穿搭效果
AI-ClothingTryOn是基于Google Gemini技术的虚拟试衣应用,支持人物与服装照片智能合成,可生成多达10种试穿效果版本,并提供自定义提示词优化功能。

Runway Gen-4:AI视频生成新纪元!高保真特效一键生成影视级内容
Runway Gen-4是新一代AI视频生成模型,通过参考图和文字指令即可生成具有物理真实感、叙事连贯性的高质量视频内容,支持与实拍素材无缝融合。

Amodal3R:3D重建领域新突破!这个模型让残破文物完美还原,3D重建结果助力文物修复
Amodal3R是一种创新的条件式3D生成模型,通过掩码加权多头交叉注意力机制和遮挡感知层,能够从部分可见的2D图像中重建完整3D形态,仅用合成数据训练即可实现真实场景的高精度重建。

Hi3DGen:2D照片秒变高精度模型,毛孔级细节完爆Blender!港中文×字节×清华联手打造3D生成黑科技
Hi3DGen是由香港中文大学、字节跳动和清华大学联合研发的高保真3D几何生成框架,通过法线图中间表示实现细节丰富的3D模型生成,其双阶段生成流程显著提升了几何保真度。

ObjectMover:港大联合Adobe打造图像编辑黑科技,移动物体光影自动匹配
香港大学与Adobe联合研发的ObjectMover模型,通过视频生成先验迁移技术,实现图像中物体的自然移动、删除和插入,自动保持光影一致性。

PhysGen3D:清华等高校联合推出,单图秒变交互式3D场景
PhysGen3D是清华等高校联合开发的创新框架,通过单张图像重建3D场景并模拟物理行为,实现从静态图像到动态交互的突破性转换。

Vibe Draw:涂鸦秒变3D模型!开源AI建模神器解放创意生产力
Vibe Draw 是一款基于AI技术的开源3D建模工具,通过Next.js和FastAPI构建,能将用户绘制的2D草图智能转化为3D模型,并支持文本提示优化和场景构建。

ChatAnyone:阿里通义黑科技!实时风格化肖像视频生成框架震撼发布
阿里巴巴通义实验室推出的ChatAnyone框架,通过高效分层运动扩散模型和混合控制融合技术,实现高保真度、自然度的实时肖像视频生成。

TripoSG:3D生成新纪元!修正流模型秒出高保真网格,碾压传统建模
TripoSG 是 VAST AI 推出的基于大规模修正流模型的高保真 3D 形状合成技术,能够从单张图像生成细节丰富的 3D 网格模型,在工业设计、游戏开发等领域具有广泛应用前景。

TripoSR:开源3D生成闪电战!单图0.5秒建模,Stability AI颠覆设计流程
TripoSR是由Stability AI和VAST联合推出的开源3D生成模型,能在0.5秒内从单张2D图像快速生成高质量3D模型,支持游戏开发、影视制作等多领域应用。

TripoSF:3D建模内存暴降80%!VAST AI新一代模型细节狂飙82%
TripoSF 是 VAST AI 推出的新一代 3D 基础模型,采用创新的 SparseFlex 表示方法,支持 1024³ 高分辨率建模,内存占用降低 82%,在细节捕捉和复杂结构处理上表现优异。

Video-T1:视频生成实时手术刀!清华腾讯「帧树算法」终结闪烁抖动
清华大学与腾讯联合推出的Video-T1技术,通过测试时扩展(TTS)和Tree-of-Frames方法,显著提升视频生成的连贯性与文本匹配度,为影视制作、游戏开发等领域带来突破性解决方案。

谷歌DeepMind联手牛津推出Bolt3D:AI秒速3D建模革命!单GPU仅需6秒生成3D场景
牛津大学与谷歌联合推出的Bolt3D技术,能在单个GPU上仅用6.25秒从单张或多张图像生成高质量3D场景,基于高斯溅射和几何多视角扩散模型,为游戏、VR/AR等领域带来革命性突破。

RF-DETR:YOLO霸主地位不保?开源 SOTA 实时目标检测模型,比眨眼还快3倍!
RF-DETR是首个在COCO数据集上突破60 mAP的实时检测模型,结合Transformer架构与DINOv2主干网络,支持多分辨率灵活切换,为安防、自动驾驶等场景提供高精度实时检测方案。

TaoAvatar:手机拍出电影级虚拟人!阿里3D高斯黑科技让动捕设备下岗
阿里巴巴最新推出的TaoAvatar技术,通过3D高斯溅射实现照片级虚拟人实时渲染,支持多信号驱动与90FPS流畅运行,将彻底改变电商直播与远程会议体验。

LHM:单图生成3D动画人!阿里开源建模核弹,高斯点云重构服装纹理
阿里巴巴通义实验室开源的LHM模型,能够从单张图像快速重建高质量可动画化的3D人体模型,支持实时渲染和姿态控制,适用于AR/VR、游戏开发等多种场景。

Reve Image:设计师失业警告!AI秒出海报级神图,排版自动搞定
Reve Image 是 Reve 推出的全新 AI 图像生成模型,专注于提升美学表现、精确的提示遵循能力以及出色的排版设计,能生成高质量的视觉作品。

DeepMesh:3D建模革命!清华团队让AI自动优化拓扑,1秒生成工业级网格
DeepMesh 是由清华大学和南洋理工大学联合开发的 3D 网格生成框架,基于强化学习和自回归变换器,能够生成高质量的 3D 网格,适用于虚拟环境构建、动态内容生成、角色动画等多种场景。
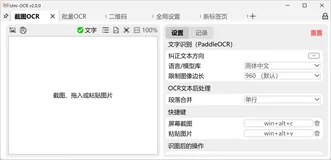
Umi-OCR:31K Star!离线OCR终结者!公式+二维码+多语种,开源免费吊打付费
Umi-OCR 是一款免费开源的离线 OCR 文字识别工具,支持截图、批量图片、PDF 扫描件的文字识别,内置多语言识别库,提供命令行和 HTTP 接口调用功能。

Step-Video-TI2V:开源视频生成核弹!300亿参数+102帧电影运镜
Step-Video-TI2V 是阶跃星辰推出的开源图生视频模型,支持根据文本和图像生成高质量视频,具备动态性调节和多种镜头运动控制功能,适用于动画制作、短视频创作等场景。
ReCamMaster:视频运镜AI革命!单镜头秒变多机位,AI重渲染颠覆创作
ReCamMaster 是由浙江大学与快手科技联合推出的视频重渲染框架,能够根据用户指定的相机轨迹重新生成视频内容,广泛应用于视频创作、后期制作、教育等领域,提升创作自由度和质量。
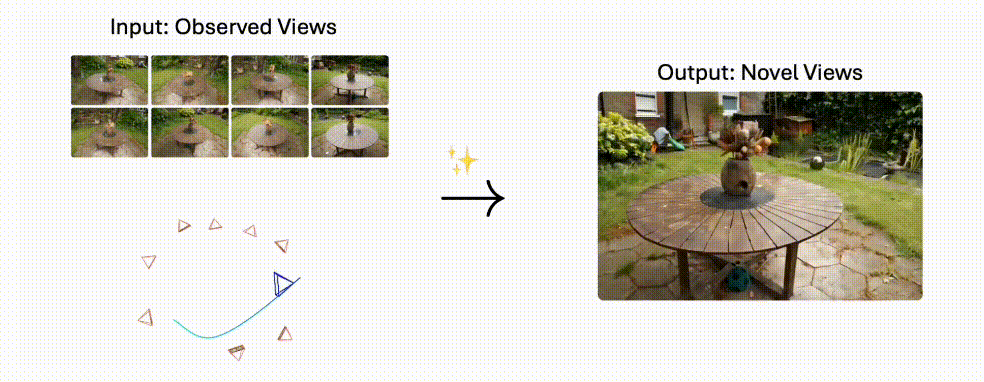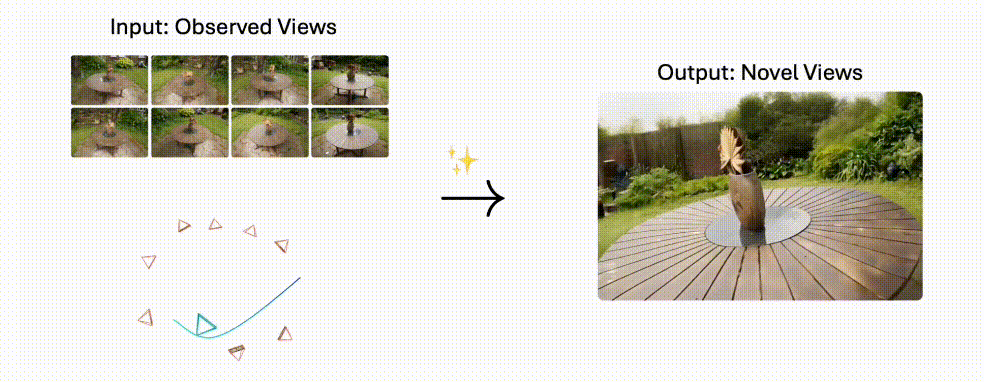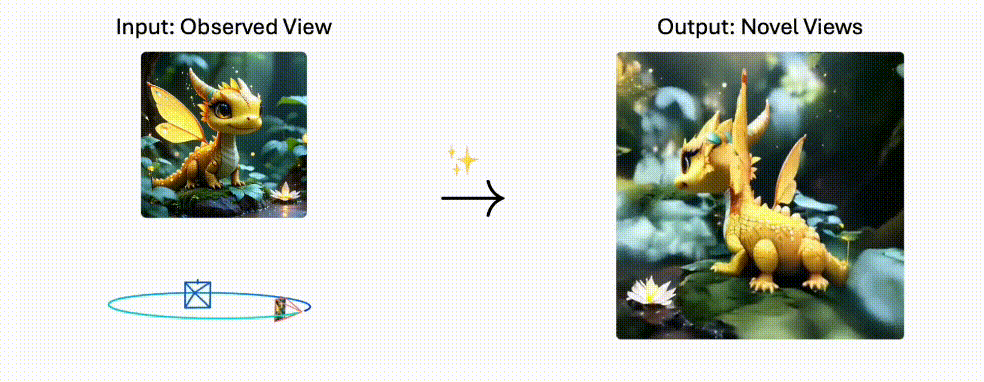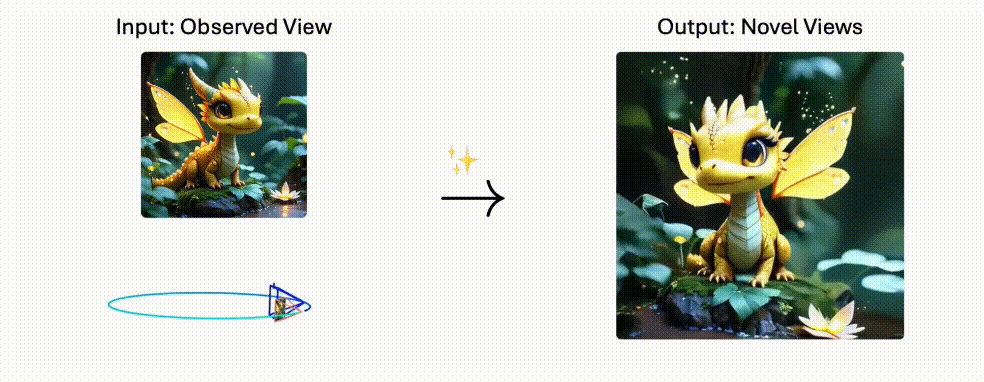
Stable Virtual Camera:2D秒变3D电影!Stability AI黑科技解锁无限运镜,自定义轨迹一键生成
Stable Virtual Camera 是 Stability AI 推出的 AI 模型,能够将 2D 图像转换为具有真实深度和透视感的 3D 视频,支持自定义相机轨迹和多种动态路径,生成高质量且时间平滑的视频。

I2V3D:微软+港城大黑科技!单图秒变3D动态视频,相机轨迹自由操控
I2V3D 是由香港城市大学和微软联合开发的图像到视频生成框架,支持将静态图像转换为动态视频,基于3D几何引导实现精确的动画控制,适用于动画制作、视频编辑和内容创作等领域。

MIDI-3D:单图秒变3D场景!40秒生成360度空间,多实例扩散黑科技
MIDI-3D 是一种先进的 AI 3D 场景生成技术,能够将单张图像快速转化为高保真度的 360 度 3D 场景,具有强大的全局感知能力和细节表现力,适用于游戏开发、虚拟现实、室内设计等多个领域。
VideoPainter:开源视频修复神器!双分支架构一键修复,对象身份永久在线
VideoPainter 是由香港中文大学、腾讯ARC Lab等机构联合推出的视频修复和编辑框架,基于双分支架构和预训练扩散模型,支持任意长度视频的修复与编辑,具备背景保留、前景生成、文本指导编辑等功能,为视频处理领域带来新的突破。
TrajectoryCrafter:腾讯黑科技!单目视频运镜自由重构,4D生成效果媲美实拍
TrajectoryCrafter 是腾讯与香港中文大学联合推出的单目视频相机轨迹重定向技术,支持后期自由调整视频的相机位置和角度,生成高质量的新型轨迹视频,广泛应用于沉浸式娱乐、创意视频制作等领域。
IMAGPose:南理工突破性人体生成框架!多姿态适配+细节语义融合,刷新图像生成范式
IMAGPose 是南京理工大学推出的用于人体姿态引导图像生成的统一条件框架,解决了传统方法在姿态引导的人物图像生成中的局限性,支持多场景适应、细节与语义融合、灵活的图像与姿态对齐以及全局与局部一致性。
AVD2:清华联合复旦等机构推出的自动驾驶事故视频理解与生成框架
AVD2 是由清华大学联合多所高校推出的自动驾驶事故视频理解与生成框架,结合视频生成与事故分析,生成高质量的事故描述、原因分析和预防措施,显著提升自动驾驶系统的安全性和可靠性。

ART:匿名区域布局+多层透明图像生成技术,生成速度比全注意力方法快12倍以上
ART 是一种新型的多层透明图像生成技术,支持根据全局文本提示和匿名区域布局生成多个独立的透明图层,具有高效的生成机制和强大的透明度处理能力。

MIT颠覆传统!分形生成模型效率暴涨4000倍,高分辨率图像秒级生成
Fractal Generative Models 是麻省理工学院与 Google DeepMind 团队推出的新型图像生成方法,基于分形思想,通过递归调用模块构建自相似架构,显著提升计算效率,适用于高分辨率图像生成、医学图像模拟等领域。

VidSketch:手残党逆袭!浙大AI神器草图秒变4K动画,三连提示词玩转影视级特效
VidSketch 是浙江大学推出的创新视频生成框架,通过手绘草图和简单文本提示生成高质量视频动画,降低视频创作的技术门槛,满足多样化的艺术需求。

VideoGrain:零样本多粒度视频编辑神器,用AI完成换装改场景,精准控制每一帧!
VideoGrain 是悉尼科技大学和浙江大学推出的零样本多粒度视频编辑框架,基于调节时空交叉注意力和自注意力机制,实现类别级、实例级和部件级的精细视频修改,保持时间一致性,显著优于现有方法。
FacePoke:开源AI实时面部编辑神器!拖拽调整表情/头部朝向,4K画质一键生成
FacePoke是一款基于AI技术的开源实时面部编辑工具,支持通过拖拽操作调整头部朝向和面部表情,适用于多种场景。
Sitcom-Crafter:动画师失业警告!AI黑科技自动生成3D角色动作,剧情脚本秒变动画
Sitcom-Crafter 是一款基于剧情驱动的 3D 动作生成系统,通过多模块协同工作,支持人类行走、场景交互和多人交互,适用于动画、游戏及虚拟现实等领域。

Migician:清北华科联手放大招!多图像定位大模型问世:3秒锁定跨画面目标,安防监控迎来AI革命!
Migician 是北交大联合清华、华中科大推出的多模态视觉定位模型,支持自由形式的跨图像精确定位、灵活输入形式和多种复杂任务。
DynamicCity:上海AI Lab开源4D场景神器助力自动驾驶场景!128帧动态LiDAR生成,1:1还原城市早晚高峰
DynamicCity 是上海 AI Lab 推出的 4D 动态场景生成框架,专注于生成具有语义信息的大规模动态 LiDAR 场景,适用于自动驾驶、机器人导航和交通流量分析等多种应用场景。

SkyReels-V1:短剧AI革命来了!昆仑开源视频生成AI秒出影视级短剧,比Sora更懂表演!
SkyReels-V1是昆仑万维开源的首个面向AI短剧创作的视频生成模型,支持高质量影视级视频生成、33种细腻表情和400多种自然动作组合。
SkyReels-A1:解放动画师!昆仑开源「数字人制造机」:一张照片生成逼真虚拟主播,表情连眉毛颤动都可控
SkyReels-A1 是昆仑万维开源的首个 SOTA 级别表情动作可控的数字人生成模型,支持高保真肖像动画生成和精确的表情动作控制。





