









文本挖掘与可视化:生成个性化词云的Python实践【7个案例】
词云是文本数据可视化的工具,显示单词频率,直观、美观,适用于快速展示文本关键信息。 - 用途包括关键词展示、数据探索、报告演示、情感分析和教育。 - 使用`wordcloud`和`matplotlib`库生成词云,`wordcloud`负责生成,`matplotlib`负责显示。 - 示例代码展示了从简单词云到基于蒙版、颜色和关键词权重的复杂词云生成。 - 案例覆盖了中文分词(使用`jieba`库)、自定义颜色和关键词权重的词云。 - 代码示例包括读取文本、分词、设置词云参数、显示和保存图像。
Ubuntu 20.04 卸载与安装 MySQL 5.7 详细教程
该文档提供了在Ubuntu上卸载和安装MySQL 5.7的步骤。首先,通过`apt`命令卸载所有MySQL相关软件包及配置。然后,下载特定版本(5.7.32)的MySQL安装包,解压并安装所需依赖。接着,按照特定顺序安装解压后的deb包,并在安装过程中设置root用户的密码。安装完成后,启动MySQL服务,连接数据库并验证。最后,提到了开启GTID和二进制日志的配置方法。
Linux(CentOS7.5) 安装部署 Python3.6(超详细!包含 Yum 源配置!)
该指南介绍了在Linux系统中配置Yum源和安装Python3的步骤。首先,通过`yum install`和`wget`命令更新和备份Yum源,并从阿里云获取CentOS和EPEL的repo文件。接着,清理和更新Yum缓存。然后,下载Python3源代码包,推荐使用阿里云镜像加速。解压后,安装必要的依赖,如gcc。在配置和编译Python3时,可能需要解决缺少C编译器的问题。完成安装后,创建Python3和pip3的软链接,并更新环境变量。最后,验证Python3安装成功,并可选地升级pip和配置pip源以提高包下载速度。
数仓常用分层与维度建模
本文介绍了数据仓库的分层结构和维度建模。数仓通常分为ODS、DIM、DWD、DWS和ADS五层,各层负责不同的数据处理阶段。维度建模是数据组织方法,包括星型和雪花模型。星型模型简单直观,查询性能高,适合简单查询;雪花模型则通过规范化减少冗余,提高数据一致性和结构复杂性,但可能影响查询效率。选择模型需根据业务需求和数据复杂性来定。

Hive实战 —— 电商数据分析(全流程详解 真实数据)
关于基于小型数据的Hive数仓构建实战,目的是通过分析某零售企业的门店数据来进行业务洞察。内容涵盖了数据清洗、数据分析和Hive表的创建。项目需求包括客户画像、消费统计、资源利用率、特征人群定位和数据可视化。数据源包括Customer、Transaction、Store和Review四张表,涉及多个维度的聚合和分析,如按性别、国家统计客户、按时间段计算总收入等。项目执行需先下载数据和配置Zeppelin环境,然后通过Hive进行数据清洗、建表和分析。在建表过程中,涉及ODS、DWD、DWT、DWS和DM五层,每层都有其特定的任务和粒度。最后,通过Hive SQL进行各种业务指标的计算和分析。
Trying to access array offset on value of type null
你就可以避免在null值上尝试访问数组偏移量的错误。 总的来说,当你遇到这个错误时,你应该回顾你的代码,确保在尝试访问数组偏移量之前,相关的变量已经被正确地初始化为一个数组,并且不是null。
CamVid数据集(智能驾驶场景的语义分割)
CamVid 数据集是由剑桥大学公开发布的城市道路场景的数据集。CamVid全称:The Cambridge-driving Labeled Video Database,它是第一个具有目标类别语义标签的视频集合。 数据集包 括 700 多张精准标注的图片用于强监督学习,可分为训练集、验证集、测试集。同时, 在 CamVid 数据集中通常使用 11 种常用的类别来进行分割精度的评估,分别为:道路 (Road)、交通标志(Symbol)、汽车(Car)、天空(Sky)、行人道(Sidewalk)、电线杆 (Pole)、围墙(Fence)、行人(Pedestrian)、建筑物(Building)
云原生大数据架构实践与思考-DataFunTalk
导读: 作者:振策-阿里云计算平台-产品解决方案, 20230805 本文将分享当前云原生大数据架构的发展历程/架构定义/核心能力/应用场景及趋势思考。主要包括以下四个部分: - 从大数据上云看架构 - 云原生数据平台的核心能力 - Data+AI with Cloud-Native - 未来趋势与思考
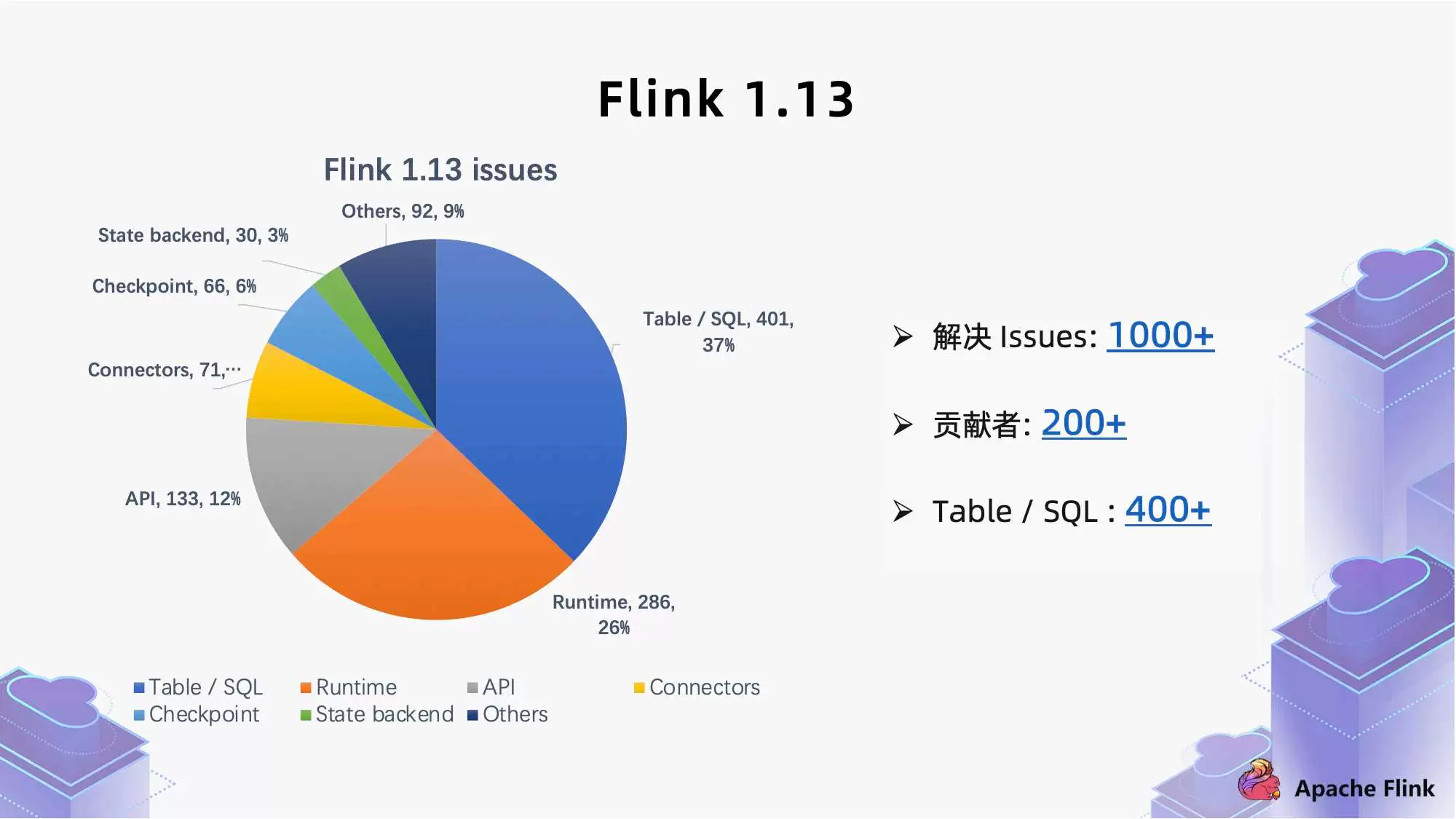
深入解读 Flink SQL 1.13
Apache Flink 社区 5 月 22 日北京站 Meetup 分享内容整理,深入解读 Flink SQL 1.13 中 5 个 FLIP 的实用更新和重要改进。

Hologres揭秘:高性能原生加速MaxCompute核心原理
Hologres技术揭秘系列持续更新中,本期我们将带来Hologres高性能原生加速查询MaxCompute的技术原理解析。
独家专访阿里集团副总裁贾扬清:我为什么选择加入阿里巴巴?
在这次访谈中,贾扬清向我们透露了他加入阿里的原因,并对他目前在阿里主要负责的工作做了详细说明,他不仅回顾了过去 6 年 AI 框架领域发生的变化,也分享了自己对于 AI 领域现状的观察和对未来发展的思考。结合自己的经验,贾扬清也给出了一些针对 AI 方向选择和个人职业发展的建议,对于 AI 从业者来
阐述:淘宝 API 商品列表数据采集实战经验
本文分享淘宝商品列表API(taobao.items.search)合规采集实战经验,涵盖接口要点、签名加密避坑、限流应对及数据清洗技巧,强调“技术守规、艺术筛数、算术控本”,助力高效低成本获取高质量商品数据。(239字)

企业RPA规模化落地的隐形门槛:如何构建团队协作的自动化资产体系
阿里云RPA规模化落地时,流程资产混乱、协作低效成瓶颈。本文剖析“个人脚本”向“团队工程”升级路径,提出协同开发、资产分类(按部门归集)、发布审批三大工程化实践,并结合云效、钉钉、OSS等云原生服务构建可治理、可审计、可复用的自动化管理体系。(239字)
五年数据开发复盘:从数仓建设到 AI 产品化的阶段性思考
五年数据开发复盘:从数仓建设到AI产品化。作者深耕BI、SaaS数仓、数据血缘与建模,提出“以数仓为根基、实体建模为核心、工程稳定性为底座”,强调业务理解重于工具使用。面对AI浪潮,主张聚焦提示词工程、RAG、实体识别等AI工程化落地,而非算法底层——数据开发正演进为连接业务、数据、工程与AI的复合型角色。
PAI-FeatureStore特征平台的相关问答
本栏目解答FeatureStore常见问题:实时视图时间戳支持BIGINT/TIMESTAMP;ODPS同步需字段完全匹配;Item特征表由关联视图确定;离线视图禁止写入;实时数据查询延迟通常仅数秒。(238字)
让 AI 帮你搞定文献阅读
OpenClaw + arxiv-reader技能,让你用手机聊天式阅读arXiv论文:秒获纯文本(自动展开LaTeX)、先看目录再决定是否精读、多文摘要对比筛选、精准定位章节解析——无需下载PDF、不用开电脑、零部署门槛,科研效率翻倍!
LitBuy模式反向海淘系统(欧美淘宝/1688代购)搭建指南
LitBuy是面向海外用户的中国商品代购集运平台,支持粘贴淘宝/1688链接一键下单,提供多语言、多支付、智能合箱与全程物流追踪。核心盈利来自物流差价、代购服务费及增值服务,技术架构基于Next.js+Java/Node.js微服务,部署于AWS/阿里云国际节点。(239字)
C语言深度解析:未定义行为(UB)—— 90%玄学bug的根源
C语言因极致性能与硬件控制力成为系统开发首选,但其“自由”伴生未定义行为(UB):语法合法却结果不可控,是“调试正常、上线崩溃”的元凶。UB包括数组越界、有符号溢出、空指针解引用、序列点违规、重复释放等,编译器可任意优化或崩溃。规避需严守边界、开启高警告、判空置空、拆分表达式、预检溢出。(239字)
不会选数据,别说你会AI:一份给新手的极简数据集实战手册
数据集是AI模型的“基石”,决定其性能上限。本文以通俗语言解析数据集的核心概念、获取途径、质量评估与实战步骤,手把手教你打造高质量数据,助力AI项目成功,堪称新手入门与实践的必备指南。
Opus 4.5、GPT-5.2 与 Gemini 3 Pro:企业级场景下的大模型工程表现对比
本文从工程与生产视角,对比Opus 4.5、GPT-5.2、Gemini 3 Pro三款大模型在输出一致性、可控性、长上下文、接口确定性等维度的表现,强调企业级AI选型应重稳定性与系统友好度,而非单纯比拼能力。
【赵渝强老师】基于Hudi的大数据湖仓一体架构
Apache Hudi(Hadoop Upserts Delete and Incremental)是开源的流式数据湖平台,支持事务、高效upsert/delete、增量处理、多引擎SQL读写(Spark/Flink/Trino等),自动管理小文件与压缩,兼容云存储,助力构建湖仓一体架构。
智能体来了从 0 到 1:为什么一开始必须划清智能体的任务边界?
智能体开发切忌“全能幻想”!本文指出:任务边界(输入范围、工具权限、决策规则)是智能体从Demo走向落地的生命线——它不设限能力,而是将LLM的概率输出转化为可控、稳定、可评估的工程系统。边界清晰,方能降幻觉、控成本、提准确率。
为什么 ES 的搜索结果只到 10,000?强制“数清楚”的代价有多大
Elasticsearch 7.x后默认返回10,000总数,实为Block-Max WAND算法的性能优化——跳过低分文档块以提升查询速度。强行开启`track_total_hits:true`将禁用该优化,导致CPU飙升、延迟激增。本文深入Lucene底层,解析其原理、陷阱与治理方案。
大模型微调完全指南:原理、实践与平台选择,让AI真正为你所用
微调是让通用大模型成为垂直领域“专家”的关键路径:通过小规模、高质量数据定向优化模型参数,实现专业适配。相比提示词工程的临时性,微调能内化知识、提升准确性与风格一致性。LoRA等高效微调技术大幅降低门槛,百条数据+单卡即可完成,兼顾效果与成本。(239字)
第六章 SpringMVC框架
Spring MVC核心组件包括DispatcherServlet、HandlerMapping、HandlerAdapter、Handler和ViewResolver,协同完成请求分发、处理与响应。其流程为:请求经DispatcherServlet分发,通过HandlerMapping定位处理器,由HandlerAdapter执行Handler,再经ViewResolver解析视图并渲染返回。此外,可通过拦截器实现登录校验等操作,结合@RestControllerAdvice和@ExceptionHandler统一处理异常,并使用@RequestMapping等注解简化开发。
OOM排查之路:一次曲折的线上故障复盘
本文记录了一次Paimon数据湖与RocksDB集成服务中反复出现的内存溢出(OOM)问题排查全过程。通过MAT、NMT、async-profiler等工具,结合监控分析与专家协作,最终定位到RocksDB通过JNI申请的堆外内存未释放是根因,并分享了转向Flink写入Paimon的解决方案及排查思路,为类似技术栈提供借鉴。(239字)
报错解决:Selenium报错“Message: session not created: probably user data directory is already in use” 等
本文详解Selenium操作Edge浏览器时常见的“版本不匹配”和“进程冲突”问题,分析报错根源,并提供手动替换驱动与webdriver-manager自动管理两种解决方案,助你高效稳定实现浏览器自动化。
GEO优化:AI时代的流量新密码
生成式引擎优化(GEO)是针对AI驱动的搜索引擎(如ChatGPT、DeepSeek、Perplexity等)进行内容优化的策略,旨在提升品牌在AI生成回答中的可见性。 一、 GEO优化的核心框架:SEO + RAG GEO优化主要围绕两个核心环节展开,因为AI搜索通常分为“检索”和“生成”两步。 1. SEO (S…
ADAMS 科研仿真,新版本来袭,附安装包
ADAMS是领先的多体动力学仿真软件,支持复杂机械系统建模与运动分析,集成有限元与控制软件,实现多物理场协同仿真,助力工程师优化设计、降低成本。

氛围编程陷阱:为什么AI生成代码正在制造大量"伪开发者"
AI兴起催生“氛围编程”——用自然语言生成代码,看似高效实则陷阱。它让人跳过编程基本功,沦为只会提示、不懂原理的“中间商”。真实案例显示,此类项目易崩溃、难维护,安全漏洞频出。AI是技能倍增器,非替代品;真正强大的开发者,永远是那些基础扎实、能独立解决问题的人。
二、Sqoop 详细安装部署教程
在大数据开发实战中,Sqoop 是数据库与 Hadoop 生态之间不可或缺的数据传输工具。这篇文章将以 Sqoop 1.4.7 为例,结合官方站点截图,详细讲解 Sqoop 的下载路径、安装步骤、环境配置,以及常见 JDBC 驱动的准备过程,帮你一步步搭建出能正常运行的 Sqoop 环境,并通过 list-databases 命令验证安装是否成功。如果你正打算学习 Sqoop,或者在搭建大数据平台过程中遇到安装配置问题,本文将是非常实用的参考指南。
香烟品牌识别和规格识别设计思路
基于YOLOv8实现香烟品牌与规格(条装/单盒装)识别,采用“品牌+规格”组合为60类的复合类别方案,结合充足标注数据(每类300-500张)、数据增强与反例优化,进行端到端联合训练,提升模型在复杂场景下的检测与分类精度。

RAG系统嵌入模型怎么选?选型策略和踩坑指南
嵌入是RAG系统的核心,直接影响检索质量。本文详解嵌入原理,解析稠密/稀疏、长上下文、多向量等类型,梳理选型关键:领域匹配、上下文长度、维度与成本,并结合MTEB基准给出实用建议,助你为业务挑选高效稳健的嵌入方案。

Flink基于Paimon的实时湖仓解决方案的演进
本文源自Apache CommunityOverCode Asia 2025,阿里云专家苏轩楠分享Flink与Paimon构建实时湖仓的演进实践。深度解析Variant数据类型、Lookup Join优化等关键技术,提升半结构化数据处理效率与系统可扩展性,推动实时湖仓在生产环境的高效落地。
【逆向】Python 调用 JS 代码实战:使用 pyexecjs 与 Node.js 无缝衔接
本文介绍了如何使用 Python 的轻量级库 `pyexecjs` 调用 JavaScript 代码,并结合 Node.js 实现完整的执行流程。内容涵盖环境搭建、基本使用、常见问题解决方案及爬虫逆向分析中的实战技巧,帮助开发者在 Python 中高效处理 JS 逻辑。
孔夫子旧书网 API 实战:古籍与二手书数据获取及接口调用方案
孔夫子旧书网作为国内知名古籍与二手书交易平台,其数据对图书收藏、学术研究及电商系统具有重要价值。本文详解其API调用方法,涵盖认证机制、搜索参数、数据解析及反爬策略,并提供可直接使用的Python代码,助力开发者合规获取数据。
Java 大视界 -- Java 大数据在智能家居能源消耗模式分析与节能策略制定中的应用(198)
简介:本文探讨Java大数据技术在智能家居能源消耗分析与节能策略中的应用。通过数据采集、存储与智能分析,构建能耗模型,挖掘用电模式,制定设备调度策略,实现节能目标。结合实际案例,展示Java大数据在智能家居节能中的关键作用。

信息检索重排序技术深度解析:Cross-Encoders、ColBERT与大语言模型方法的实践对比
本文将深入分析三种主流的重排序技术:Cross-Encoders(交叉编码器)、ColBERT以及基于大语言模型的重排序器,并详细阐述各方案在实际应用中的性能表现、成本考量以及适用场景。
开源AI BI可视化工具-WrenAI
Wren AI 是一款开源的 SQL AI 代理,支持数据、产品及业务团队通过聊天、直观界面和与 Excel、Google Sheets 的集成获取洞察。它结合大型语言模型(LLM)与检索增强生成(RAG)技术,助力用户高效处理复杂数据分析任务。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。

