










PCA多变量离群点检测:Hotelling's T2与SPE方法原理及应用指南
主成分分析(PCA)是一种经典的无监督降维方法,广泛应用于多变量异常值检测。它通过压缩数据维度并保留主要信息,提升检测效率,同时支持可视化与可解释性分析。本文系统讲解基于PCA的异常检测原理,重点介绍霍特林T²统计量与SPE/DmodX方法,并结合葡萄酒与学生成绩数据集,演示连续变量与分类变量的实际建模过程。通过Python实现,展示如何识别并可视化异常样本,提升异常检测的准确性与理解深度。
Flink 2.1 SQL:解锁实时数据与AI集成,实现可扩展流处理
简介:本文整理自阿里云高级技术专家李麟在Flink Forward Asia 2025新加坡站的分享,介绍了Flink 2.1 SQL在实时数据处理与AI融合方面的关键进展,包括AI函数集成、Join优化及未来发展方向,助力构建高效实时AI管道。
2025最新版天猫图片搜索API全解析:从图像识别到商品匹配实战
天猫图片搜索API(拍立淘)基于深度学习与CNN技术,实现以图搜商品,支持图片URL或二进制上传,适用于比价、推荐等场景。2025版新增多模态搜索优化与相似度动态调整。接口支持POST/GET请求,返回商品详情及排序结果,示例代码提供Python请求方式。
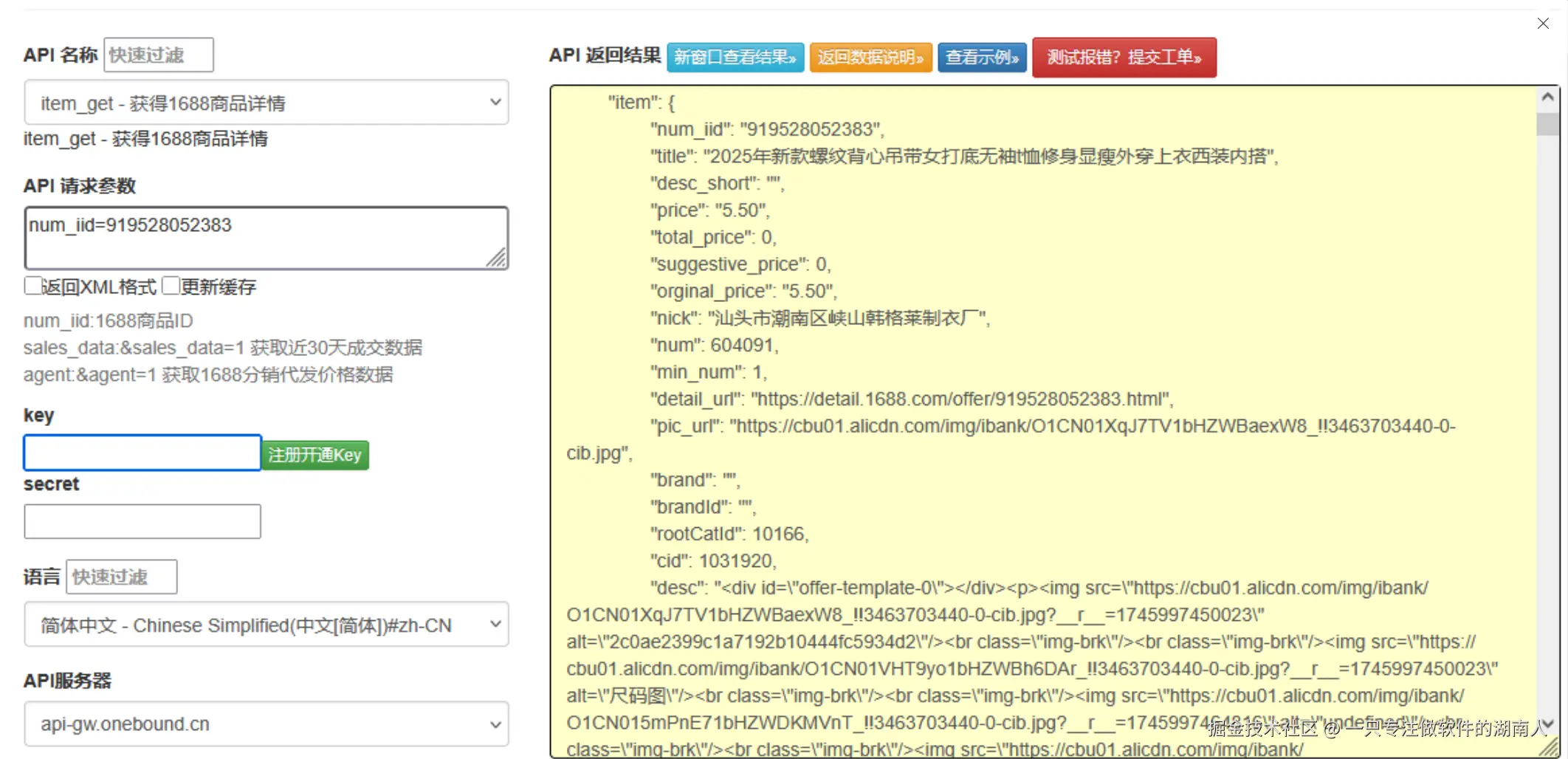
1688 商品详情接口开发实战:从平台特性到高可用实现
本文深入解析了1688平台商品详情接口的技术实现,涵盖参数设计、签名机制、数据解析等内容,并结合代码示例展示如何构建适用于B2B业务场景的接口调用系统。重点突出其批发属性、供应商信息、多规格支持及定制化能力等B2B特性,帮助开发者高效对接1688开放平台。

京东商品详情接口开发实战:从数据结构到高可用调用全解析
本文系统解析京东商品详情接口的技术架构与开发流程,涵盖接口原理、参数设计、实战开发及优化策略,提供完整代码实现,助力开发者高效构建商品数据获取系统。
计算机相关的软硬件开发工具分类
本文系统梳理了现代开发工具图谱,涵盖软件、硬件、AI等六大领域。软件开发部分对比了传统工具(如IntelliJ IDEA、SpringBoot)与新兴工具(如AI代码助手Cursor、边缘计算框架Workers),并列出国产替代方案(华为CodeArts、阿里OpenSumi)。硬件开发突出开源EDA工具KiCad和物联网OS Zephyr。AI领域对比了TensorFlow与JAX框架,推荐本地LLM工具Ollama。文章特别设置工具选型指南,针对不同场景推荐方案,如国产化需求建议PaddlePaddle
Java 大视界 --Java 大数据在智慧农业农产品市场价格预测与种植决策支持中的应用(212)
本篇文章探讨了 Java 大数据在智慧农业中的关键应用,聚焦农产品市场价格预测与种植决策支持。通过多源数据采集、机器学习模型构建及动态预测预警,Java 大数据助力农户科学决策,提升收益并降低风险。结合山东寿光与黑龙江北大荒的实践案例,展示了技术在实际农业中的显著成效。
Java 大视界 --Java 大数据机器学习模型在金融风险压力测试中的应用与验证(211)
本文探讨了Java大数据与机器学习模型在金融风险压力测试中的创新应用。通过多源数据采集、模型构建与优化,结合随机森林、LSTM等算法,实现信用风险动态评估、市场极端场景模拟与操作风险预警。案例分析展示了花旗银行与蚂蚁集团的智能风控实践,验证了技术在提升风险识别效率与降低金融风险损失方面的显著成效。

从 Flink 到 Doris 的实时数据写入实践 —— 基于 Flink CDC 构建更实时高效的数据集成链路
本文将深入解析 Flink-Doris-Connector 三大典型场景中的设计与实现,并结合 Flink CDC 详细介绍了整库同步的解决方案,助力构建更加高效、稳定的实时数据处理体系。

论文解读:单个标点符号如何欺骗LLM,攻破AI评判系统
可验证奖励强化学习(RLVR)通过规则函数或LLM评判器提供奖励信号,训练策略模型生成与参考答案一致的响应。研究发现,某些无意义模式(如标点或推理引导语)可误导评判器产生误判,称为“万能钥匙”攻击。为此,提出Master-RM模型,结合对抗训练有效抵御此类攻击,显著降低误报率,同时保持高性能与通用性。
【Axure原型】Ant Design Pro 原型后台项目-免费
Ant Design Pro 是基于 Ant Design 组件库构建的企业级中后台前端解决方案,提供丰富的页面模板、预设设计规范、路由配置及状态管理,支持快速搭建高质量应用。内置高阶组件如 ProTable、ProForm,提升开发效率,适用于复杂业务场景。
大数据AI产品月刊-2025年7月
大数据& AI 产品技术月刊【2025年7月】,涵盖7月技术速递、产品和功能发布、市场和客户应用实践等内容,帮助您快速了解阿里云大数据& AI 方面最新动态。
Python 有望超越 C 语言成为第一名
根据最新榜单,Python 与第一名 C 语言的差距持续缩小,TIOBE 预测 Python 有望超越 C 成为榜首。同时,Java 市场份额持续下滑,Perl、Swift 名次上升,Go 语言排名下降。
Robotics X实验室跑出的“轮滑小子”
Ollie是一款轮腿式机器人,结合轮式高效移动与腿部强地形适应能力,能跳跃、空翻并保持高动态平衡。它依靠腾讯Robotics X实验室的非线性控制、全身动力学控制和轨迹规划技术,具备出色运动性能,相关研究已入选机器人顶会ICRA。
淘宝图片搜索相似商品API响应数据解析
淘宝拍立淘API是基于深度学习的图像搜索接口,支持上传图片查找相似商品,适用于电商导购、比价、时尚搭配等场景。提供多格式支持、高精度搜索结果,返回JSON格式数据,附Python调用示例,便于快速集成。

如何像翻书一样,稳定地抓到你想要的分页数据?
本文分享了如何通过 Python 稳定抓取 51Job 等招聘网站的分页数据。使用 `requests` 和 `BeautifulSoup` 解析网页,结合代理服务与随机延迟策略,有效避免被限制请求,并将数据存入数据库进行后续分析。附完整代码与实战经验总结,适合有分页爬取需求的开发者参考。
全球首个 用代码画地球、日月的动态轨道模型
本文介绍了太阳、地球和月球之间的关系,并详细展示了如何利用WxGL绘制三者的动态轨道模型。内容涵盖天体的起源、大小、运行轨迹及关键数据,帮助读者直观理解四季变化、日月食等自然现象。通过代码实现,模型可演示天体运动规律,适合科普与教学应用。
面向 Java 开发者:2024 最新技术栈下 Java 与 AI/ML 融合的实操详尽指南
Java与AI/ML融合实践指南:2024技术栈实战 本文提供了Java与AI/ML融合的实操指南,基于2024年最新技术栈(Java 21、DJL 0.27.0、Spring Boot 3.2等)。主要内容包括: 环境配置:详细说明Java 21、Maven依赖和核心技术组件的安装步骤 图像分类服务:通过Spring Boot集成ResNet-50模型,实现REST接口图像分类功能 智能问答系统:展示基于RAG架构的文档处理与向量检索实现 性能优化:利用虚拟线程、GraalVM等新技术提升AI服务性能 文
IT老兵给新人程序员的建议
对于计算机专业学生而言,“进大厂”是热门职业选择。本文邀请58同城高级架构师彭飞,分享应届生进入大厂的必备指南。内容涵盖技术准备、软实力提升、简历优化及面试技巧等关键话题,帮助在校生明确发展方向,提升职场竞争力,实现从学生到优秀程序员的转变。
只需完成手画线稿,让AI算法帮你自动上色
本文介绍了如何利用图像处理技术生成手绘风格图像及自动上色的方法。内容涵盖图像灰度化、梯度调整、虚拟深度实现手绘效果,以及使用 Python 编程实现相关算法。此外,还介绍了 AI 工具 Style2Paints V4.5,其可为线稿自动上色并支持多种线稿类型,如插画和手绘铅笔稿,适用于艺术创作与图像处理领域。
自动驾驶还远吗?关键看“眼睛”
自动驾驶感知系统是智能车的“眼睛”,依赖摄像头、激光雷达、毫米波雷达等传感器实现环境感知。文章详解了感知架构、主流目标检测方法(如2D/3D检测、多传感器融合)、感知挑战(如极端天气、长尾问题)及发展趋势,并结合驭势科技实践,展示了数据闭环、BEV感知、全景分割等技术进展,推动自动驾驶向全天候、全无人目标迈进。
让 GPT-4 去解释 GPT-2 的行为
ChatGPT 引发 AI 革命,OpenAI 最新研究尝试用 GPT-4 解释 GPT-2 行为,探索 AI “黑盒”奥秘。尽管解释得分普遍不高,但为未来 AI 可解释性研究提供了新方向。
Java 大视界 -- 基于 Java 的大数据实时流处理在能源行业设备状态监测与故障预测中的应用(210)
本篇文章探讨了基于 Java 的大数据实时流处理技术在能源行业设备状态监测与故障预测中的应用。文章分析了传统能源设备运维的局限性,如人工巡检效率低、数据处理滞后等问题,并引入 Java 大数据技术作为解决方案。通过实时流处理引擎如 Apache Flink,实现多源异构数据的采集、清洗与异常检测,提升了设备监测的实时性与准确性。同时,文章还介绍了数字孪生、边缘计算等前沿技术的融合应用,并结合国家电网和海上风电场的实际案例,展示了 Java 大数据技术在提升运维效率、降低故障风险和节约成本方面的显著效果。
Java 大视界 --Java 大数据在智能教育学习效果评估与教学质量改进中的应用(209)
本文探讨了 Java 大数据在智能教育中的创新应用,涵盖学习效果评估、教学质量改进及个性化教学方案定制等内容,结合实战案例与代码解析,展现技术如何赋能教育智能化转型。
文生图关键问题探索
文生图(Text-to-Image Generation)是AIGC的重要方向,近年来模型效果显著提升,受到投资界与研究界高度关注。本文从评测体系、可控生成、个性化模型及高质量数据集四个角度探讨该领域面临的关键问题与研究进展。尽管生成模型如Diffusion Model和Stable Diffusion在效果与效率上突破显著,但在文本理解、生成控制、模型定制及数据质量等方面仍存在挑战。如何建立统一的评价标准、提升生成与文本的一致性、实现个性化定制及构建高质量多语言数据集,是未来研究与应用的关键方向。文生图的发展有望推动人机交互方式变革,成为人工智能迈向“人性化”的重要一步。
Java 17 采用率增长 430%
1995年,Sun Microsystems发布Java语言,推动现代多媒体应用发展。凭借“一次编写,到处运行”的优势,Java迅速成为主流编程语言。New Relic最新发布的《2023年Java生态系统现状》报告显示,Java 11以超56%的使用率稳居榜首,Java 8仍占近33%。尽管Oracle每半年更新一次Java版本,但开发者更倾向使用长期支持(LTS)版本。Java 17的采用率在过去一年增长430%,潜力巨大。此外,Amazon已成为最受欢迎的JDK供应商,市场份额达31%。容器化应用也已成为主流,70%的Java应用来自容器。

普通电脑也能跑AI:10个8GB内存的小型本地LLM模型推荐
随着模型量化技术的发展,大语言模型(LLM)如今可在低配置设备上高效运行。本文介绍本地部署LLM的核心技术、主流工具及十大轻量级模型,探讨如何在8GB内存环境下实现高性能AI推理,涵盖数据隐私、成本控制与部署灵活性等优势。
Go 语言中的单元测试
本文介绍了Go语言中单元测试的核心方法与实践技巧,涵盖测试文件与函数命名规范、使用`go test`命令执行测试、表格驱动测试优化多场景验证,以及性能测试与耗时测试管理,帮助开发者提升代码质量与项目稳定性。
17种RAG实现方法大揭秘
RAG(检索增强生成)通过结合外部知识库与LLM生成能力,有效解决大模型知识滞后与幻觉问题。本文详解三类策略、17种实现方案,涵盖文档分块、检索排序与反馈机制,并提供工程选型指南,助力构建高效智能系统。

Apache Flink:从实时数据分析到实时AI
Apache Flink 是实时数据处理领域的核心技术,历经十年发展,已从学术项目成长为实时计算的事实标准。它在现代数据架构中发挥着关键作用,支持实时数据分析、湖仓集成及实时 AI 应用。随着 Flink 2.0 的发布,其在流式湖仓、AI 驱动决策等方面展现出强大潜力,正推动企业迈向智能化、实时化的新阶段。
天猫商品详情API响应数据解析
天猫商品详情API是天猫开放平台的核心接口,通过商品ID可获取标题、价格、图片、库存等详细信息,广泛应用于价格监控、竞品分析等场景。支持HTTP请求,返回JSON格式数据,Python示例代码展示了如何高效调用该接口获取商品数据。
电脑进入bios关闭网卡的技巧
华硕电脑开机显示字符无法进入系统,提示“PXE-MOF:Exiting PXE ROM”,表明电脑正尝试从网卡启动。解决方法为进入BIOS关闭网卡启动功能。开机时连续按F2进入BIOS,切换至“Security”选项卡,找到“I/O Interface Security”设置,选择“LAN Network Interface”并设为“LOCKED”以禁用网卡启动,最后按F10保存退出即可。


基于模型蒸馏的大模型文案生成最佳实践
本文介绍了基于模型蒸馏技术优化大语言模型在文案生成中的应用。针对大模型资源消耗高、部署困难的问题,采用EasyDistill算法框架与PAI产品,通过SFT和DPO算法将知识从大型教师模型迁移至轻量级学生模型,在保证生成质量的同时显著降低计算成本。内容涵盖教师模型部署、训练数据构建及学生模型蒸馏优化全过程,助力企业在资源受限场景下实现高效文案生成,提升用户体验与业务增长。
训练效率提升100%!阿里云后训练全栈解决方案发布实录
阿里云大数据AI平台推出大模型后训练解决方案,通过全栈AI能力提供从算力到平台的一体化支撑,提升训练效率100%,适配多行业需求,打通大模型落地“最后一公里”。
淘宝商品评论API响应数据解析
淘宝商品评论API是淘宝开放平台的重要接口,支持获取商品用户评价信息,助力电商数据分析与商品优化。提供分页查询、评分筛选、时间过滤等功能,数据格式为JSON,适用于Python等语言调用,便于开发者灵活集成。
北京百思可瑞教育:模拟天气这件事,量子计算机轻松实现模拟天气气候
本文探讨了气候预测的复杂性及量子计算在该领域的潜力。传统超级计算机难以应对气候模型的庞大计算量,而量子计算凭借其并行性和量子纠缠特性,有望大幅提升气候模拟的效率与精度。文章介绍了量子计算的基本原理、相关实验进展,以及其在碳捕捉、城市微气候预测等方面的应用前景,展望了未来量子技术在气候科学中的深远影响。
Java 大视界 --Java 大数据在智慧交通公交车辆调度与乘客需求匹配中的应用创新(206)
本文章聚焦Java大数据在智慧交通公交调度与乘客需求匹配中的创新应用。通过动态实时调度、乘客需求精准预测及智能服务生态构建,Java与大数据技术助力公交系统实现高效、绿色、智能化升级,显著提升准点率与乘客满意度,推动城市交通智慧化转型。
Java 大视界 -- Java 大数据机器学习模型在自然语言处理中的对抗训练与鲁棒性提升(205)
本文探讨Java大数据与机器学习在自然语言处理中的对抗训练与鲁棒性提升,分析对抗攻击原理,结合Java技术构建对抗样本、优化训练策略,并通过智能客服等案例展示实际应用效果。

使用 BAML 模糊解析改进 LangChain 知识图谱提取:成功率从25%提升到99%
在构建基于知识图谱的检索增强生成(RAG)系统时,从非结构化数据中准确提取节点和关系是一大挑战,尤其在使用小型本地量化模型时表现更差。本文对比了传统 LangChain 提取框架的严格 JSON 解析限制,提出采用 BAML 的模糊解析策略,显著提升知识图谱提取成功率。实验表明,在相同条件下,BAML 将成功率从约 25% 提升至 99% 以上,为构建高效、稳定的 RAG 系统提供了有效解决方案。

【新模型速递】PAI-Model Gallery云上一键部署Kimi K2模型
月之暗面发布开源模型Kimi K2,采用MoE架构,参数达1T,激活参数32B,具备强代码能力及Agent任务处理优势。在编程、工具调用、数学推理测试中表现优异。阿里云PAI-Model Gallery已支持云端部署,提供企业级方案。
WebAssembly 与 Java 结合的跨语言协作方案及性能提升策略研究
本文深入探讨了WebAssembly与Java的结合方式,介绍了编译Java为Wasm模块、在Java中运行Wasm、云原生集成等技术方案,并通过金融分析系统的应用实例展示了其高性能、低延迟、跨平台等优势。结合TeaVM、JWebAssembly、GraalVM、Wasmer Java等工具,帮助开发者提升应用性能与开发效率,适用于Web前端、服务器端及边缘计算等场景。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。

