
在Python开发领域,GIL(Global Interpreter Lock)一直是一个广受关注的技术话题。在3.13已经默认将GIL去除,在详细介绍3.13的更亲前,我们先要留了解GIL的技术本质、其对Python程序性能的影响。本文将主要基于CPython(用C语言实现的Python解释器,也是目前应用最广泛的Python解释器)展开讨论。

GIL的技术定义
GIL(Global Interpreter Lock)是CPython解释器中的一个互斥锁(mutex)机制,其核心作用是保护Python对象的访问,防止多个本地线程同时执行Python字节码。从技术实现角度来看,GIL确保在任一时刻只有一个线程能在Python解释器中执行代码。
在实际运行过程中,假设程序创建了10个并发线程,在任一时刻检查CPU核心时,只能观察到一个线程在执行。每个线程在执行特定数量的字节码操作后,都会释放GIL并退出当前核心。在CPython的默认实现中,每个线程可以在释放GIL之前执行100个字节码指令。GIL释放后,其他等待线程中的一个将获得锁并开始执行。
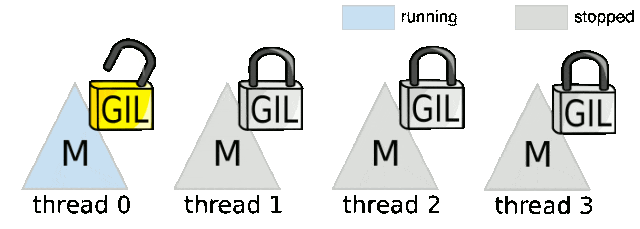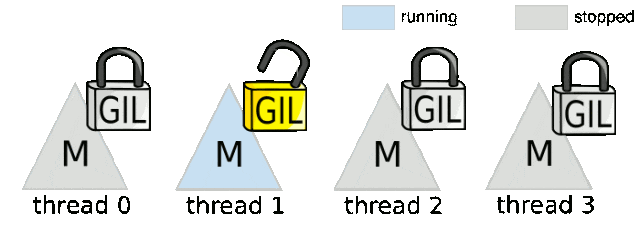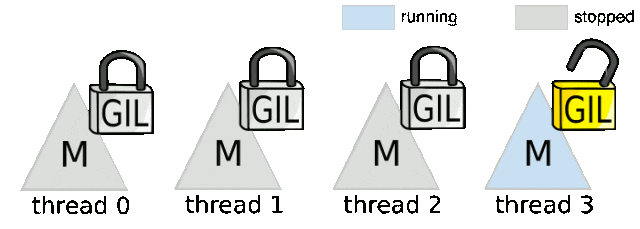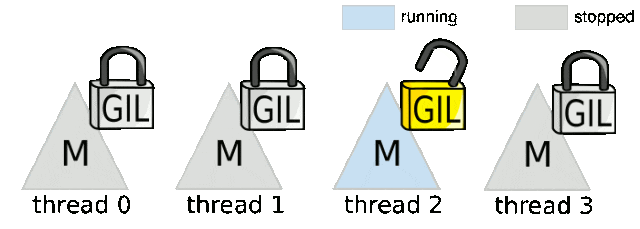
从实现机制来看,GIL可以被视为一个线程执行令牌,线程必须获取这个令牌才能执行字节码指令。
GIL的技术必要性
GIL的存在与CPython的内存管理机制密切相关。要理解GIL的必要性,需要先了解CPython的内存管理实现原理。
CPython采用引用计数(reference counting)作为其主要的内存管理机制。系统会为每个Python对象维护一个引用计数器,记录指向该对象的引用数量。当引用计数降至零时,对象占用的内存将被立即释放。

在多线程环境下对同一Python对象的访问在多线程场景下,考虑如下情况:假设有3个线程同时持有对同一Python对象的引用,此时该对象的引用计数为3。当一个线程释放对该对象的引用时,计数值降为2。
这里存在一个关键的技术问题:如果两个线程同时释放对该对象的引用,会出现竞争条件(race condition)。在这种情况下,引用计数可能只会减少一次而不是预期的两次,导致最终引用计数为2而不是1。这将导致对象永远保持非零引用计数,使得垃圾回收器无法回收该对象,最终造成内存泄漏。
GIL的设计正是为了解决这个问题。通过确保同一时刻只有一个线程在执行,GIL有效防止了多线程环境下的引用计数竞争问题。这种机制保证了对Python对象的访问是串行的,从而维护了解释器内部状态的一致性。
GIL的技术局限性
GIL虽然解决了内存管理的并发问题,但同时也带来了性能方面的技术挑战。
最主要的性能开销来自于线程执行时频繁的GIL获取和释放操作。这种额外的同步开销导致了多线程程序在某些场景下的性能反而低于单线程程序。
以下是具体的性能测试示例。首先是单线程实现:
importtime
defmyfunc():
"""
执行5亿次迭代的高精度计时测试
"""
before_time=time.perf_counter()
for_inrange(500000000):
pass
after_time=time.perf_counter()
elapsed_time=after_time-before_time
print(f"Time taken in total: {elapsed_time:.6f} seconds")
if__name__=="__main__":
myfunc()

单线程执行结果显示耗时约8.426秒
对比使用两个线程的实现:
importtime
importthreading
defworker(iterations, thread_id):
"""
执行指定迭代次数的工作线程函数
参数:
iterations (int): 迭代执行次数
thread_id (int): 线程标识号
"""
print(f"Thread {thread_id} starting.")
for_inrange(iterations):
pass
print(f"Thread {thread_id} finished.")
defmyfunc():
"""
将5亿次迭代平均分配给两个线程执行的性能测试
"""
total_iterations=500000000
half_iterations=total_iterations//2
thread1=threading.Thread(target=worker, args=(half_iterations, 1))
thread2=threading.Thread(target=worker, args=(half_iterations, 2))
print("Starting threads...")
before_time=time.perf_counter()
thread1.start()
thread2.start()
thread1.join()
thread2.join()
after_time=time.perf_counter()
elapsed_time=after_time-before_time
print(f"Time taken in total: {elapsed_time:.6f} seconds")
if__name__=="__main__":
myfunc()

多线程执行结果显示耗时约11.256秒
这个性能测试清晰地展示了GIL对Python多线程执行效率的影响,同时也说明了Python在实现真正的线程级并行计算时所面临的技术限制。
3.13 前的技术解决方案
针对GIL带来的限制,目前有多种技术解决方案,但每种方案都有其特定的应用场景和局限性:
多进程方案: 通过Python的
multiprocessing
模块,可以创建多个独立的Python解释器进程,每个进程都拥有独立的GIL和内存空间,从而实现真正的并行计算。
异步编程: 对于I/O密集型应用,可以使用异步编程模型(如asyncio)实现并发,这种方式可以在单线程环境下高效处理并发任务,降低GIL的影响。
替代性Python实现: 一些Python的其他实现(如Jython、IronPython、PyPy)采用了不同的内存管理机制,不依赖GIL。这些实现通过不同的技术方案避免了GIL的限制,但可能会带来其他方面的权衡。
总结
GIL是CPython实现中的一个核心设计决策,它在保证内存管理安全性的同时也带来了并行计算效率的限制。在实际开发中,需要根据具体的应用场景选择合适的技术方案来规避或降低GIL的影响。理解GIL的技术本质和局限性,对于设计高性能的Python应用系统具有重要意义。
PEP 703 提出的移除 GIL 的设计,不仅解决了 GIL 带来的多线程性能瓶颈,还通过细粒度锁、乐观锁、RCU 和 STW 等多种机制,在性能和线程安全之间实现了巧妙的平衡。但是根据 Python 路线图显示,至少要到 2028 年,GIL 才会被默认禁用。所以目前来看的话了解GIL还是十分有必要的。
https://avoid.overfit.cn/post/3545a1aabf5a4452861804a1c5340ac0
作者:Sambhu Nampoothiri G
